监督学习归类(个人总结)
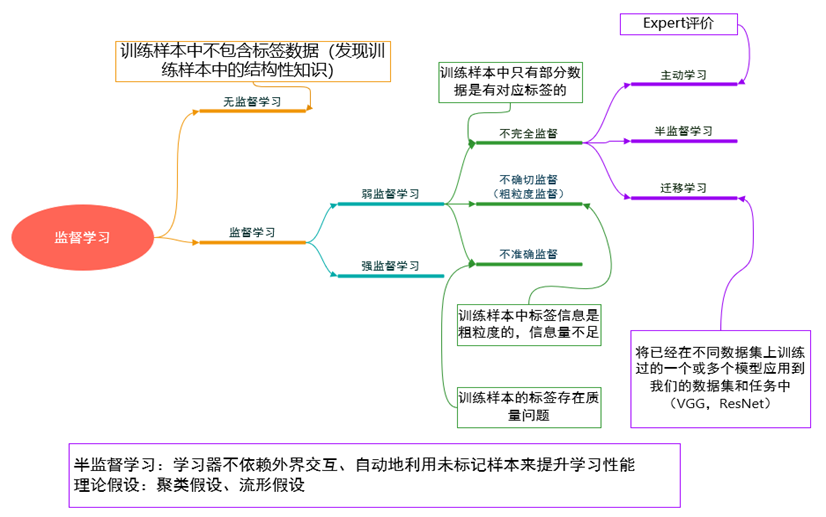
1. 监督学习
训练样本中的数据与其一一对应的标签,通过训练出一个智能算法,将输入数据映射到对应的标签。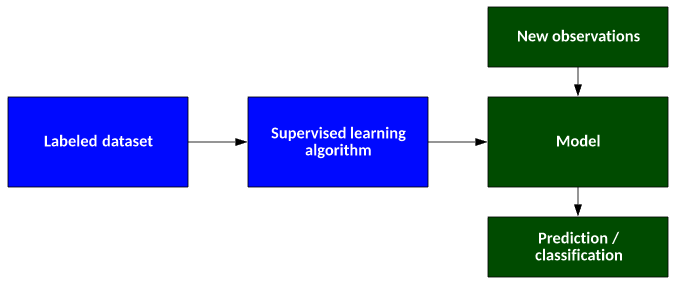
常见监督学习算法
- 支持向量机(SVM)
- KNN
- 决策树
- 朴素贝叶斯
- 逻辑回归
2. 无监督学习
训练样本中的数据不包含任何标签,而训练出的算法能够将数据映射到不同的对应标签。无监督学习的目标是发现训练样本中的结构性知识。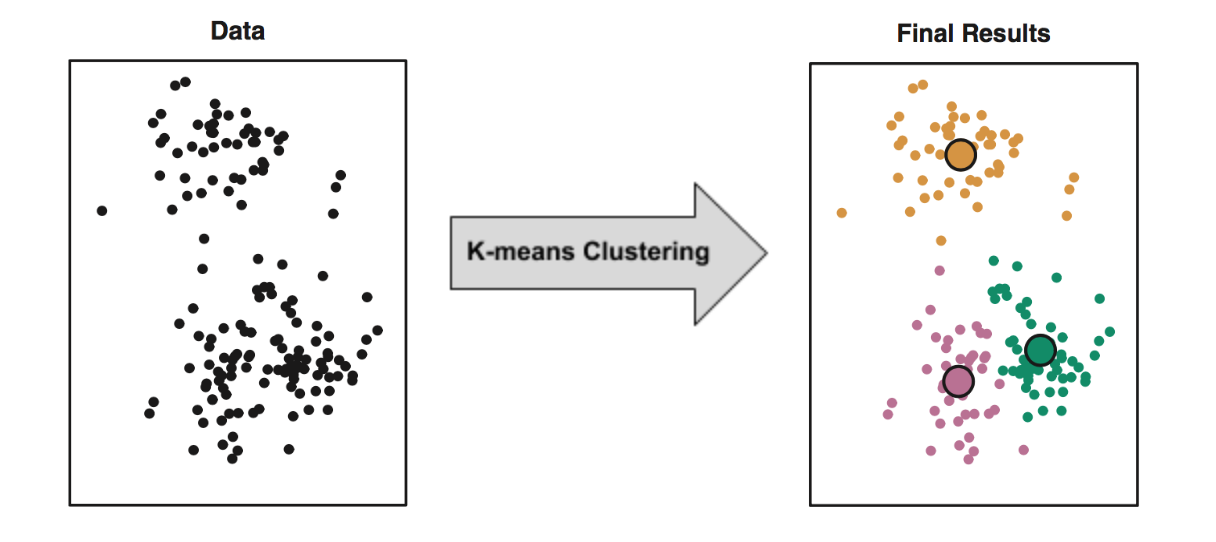
常见无监督学习算法
- 聚类
- PCA
- 生成对抗网络(GAN)
3. 弱监督学习
已知的训练样本中包含训练数据和其一一对应的弱标签,通过训练出的算法,将输入数据映射到一组更强的标签上。这里标签的强弱指的是标签中包含信息量,因此弱监督学习又可以分为三类:
不完全监督
训练数据中只有部分是带标签的,与此同时有大量的数据是无标签的。最常见的情况就是由于标注成本过高,无法对全部训练样本获得强监督信息的情况。
不完全监督的下的学习方法:
主动学习(active learning)
假设未标注数据的真值标签可以向人类专家进行查询,那么模型需要估计出最有价值的数据点让人类专家打上标签。在标准监督学习设置中,这意味着选择要标记的新数据点。而在衡量查询样本的价值时,有两个被最广泛使用的标准:信息量和代表性。信息量衡量的是一个未标注数据能够在多大程度上降低统计模型的不确定性,而代表性则衡量一个样本在多大程度上能代表模型的输入分布。
半监督学习(semi-supervision learning)
参见下节。
迁移学习(transfer learning)
其内在思想是借鉴人类「举一反三」的能力,提高对数据的利用率。通俗地讲,迁移学习的目标是将已经在不同数据集上训练过的一个或多个模型应用到我们的数据集和任务中。例如,我们可能在身体的另一部分有一个大型肿瘤训练集,并且在这组训练的分类器,并希望将这些应用于我们的乳房摄影任务。
粗粒度监督
这里是对数据标签的信息粒度进行区分。例如针对一幅图片,训练数据中只有对整张图片的类别标注,对于图片中各个物体没有进行标注,那么在使用这个训练样本完成物体检测任务的过程就可以理解为不确切监督学习。
有误的监督
训练样本中标签的质量存在问题,例如标记错误,或者包含噪声。
4. 半监督学习
与主动学习不同,半监督学习是一种在没有人类专家参与的情况下对未标注数据加以分析、利用的学习范式,让学习器不依赖外界交互、自动地利用为标记样本来提升学习性能。通常,尽管未标注的样本没有明确的标签信息,但是其数据的分布特征与已标注样本的分布往往是相关的,这样的统计特性对于预测模型是十分有用的。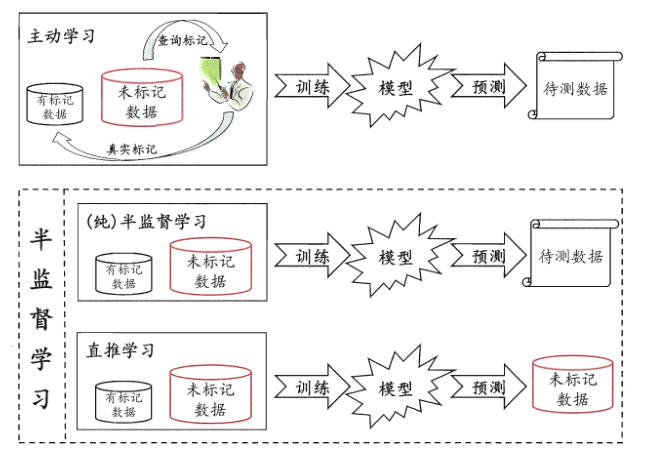
半监督学习模型
- 生成式方法
- 半监督SVM
- 图半监督学习
- 基于分歧的方法
- 半监督聚类
5. 其他有关名词
- 全监督(full supervision)
- 强监督(strong supervision)
参考材料

若有收获,就点个赞吧
0 人点赞
