剪辑自:https://zhuanlan.zhihu.com/p/106662375
1. Attention Review
Attention的本质是根据事物之间的关系进行线性加权得到新的表示。类比而言,假如我们现在需要给一段文本进行评分,每个文本有一个对应的向量表示。现在我们有一个检索库  ,其中
,其中  是一对向量表示和评分,现在给定一个需要评分的文本
是一对向量表示和评分,现在给定一个需要评分的文本  ,该如何计算它对应的评分呢?
,该如何计算它对应的评分呢?
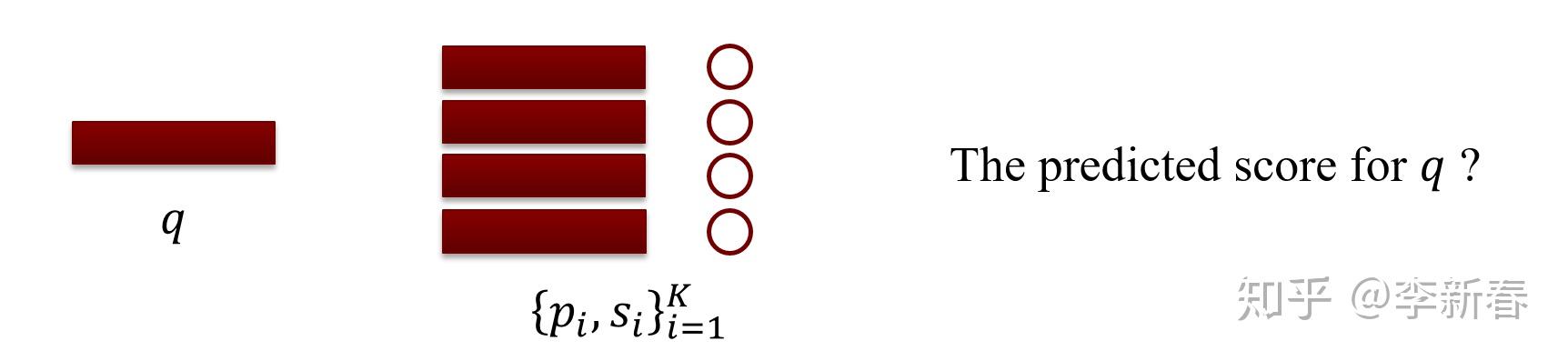
首先,我们需要计算查询文本 和每个检索库里面文本的相似度,即  ,然后根据相似度加权预测评分得到:
,然后根据相似度加权预测评分得到:  。
。
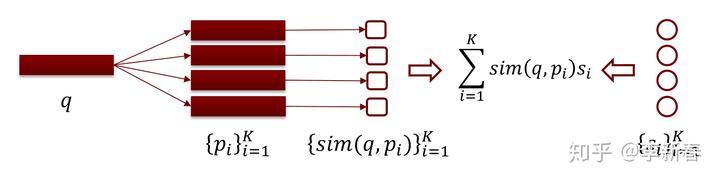
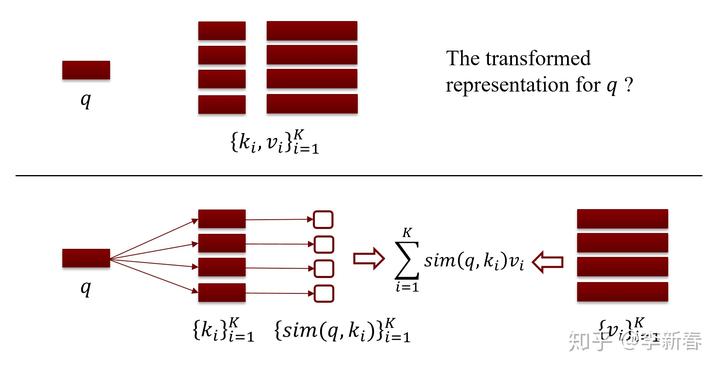
对应的,Attention则是给定一个查询的向量表示 以及对应的检索库  ,其中
,其中  是关键字
是关键字  对应的向量表示,那么为了将 和检索库里面的知识利用上,需要对 的表示加以转换为:
对应的向量表示,那么为了将 和检索库里面的知识利用上,需要对 的表示加以转换为:  。
。
根据相似度的计算方法,Attention有不同的种类,包括:内积相似度、余弦相似度和拼接相似度等等。
内积相似度:
余弦相似度:
拼接相似度:
其中拼接相似度是将两个向量拼接起来,然后利用一个可以学习的权重  求内积得到相似度,也称为Additive Attention,意思是指的
求内积得到相似度,也称为Additive Attention,意思是指的  。
。
最后可以根据相似度得到一组权值:  。有时候为了限制权值的大小,需要将权值进行归一化或者缩放,比如:
。有时候为了限制权值的大小,需要将权值进行归一化或者缩放,比如:
或者单独进行归一化:
总之,Attention就是利用事物之间的关系计算一组权值,然后进行加权表示得到新的表示,可以理解为是一种特征变换的方法。
2. Related Methods
下面介绍一下相关工作,Attention和很多术语有相似之处,比如Pooling,Aggregation,Gating,Squeeze-Excitation等等,下面分别介绍一下。
- Pooling
Pooling池化是神经网络卷积层之后经常用到的一层,目前为止有很多池化的方法,比如确定性(Deterministic)的池化方法:Sum pooling, Mean pooling, Max pooling, K-Max pooling, Chunk-Max pooling等。还有一类就是随机池化,Stochastic pooling。
先简单介绍一下Deterministic Pooling的方法:其中如下图所示(按列Pooling),对应的Mean、Sum、Max是将多个向量的对应值的地方取平均、和、最大,K-Max是指的取前K个最大的拼接成一个向量,Chunk-Max是将向量分组然后分别取最大。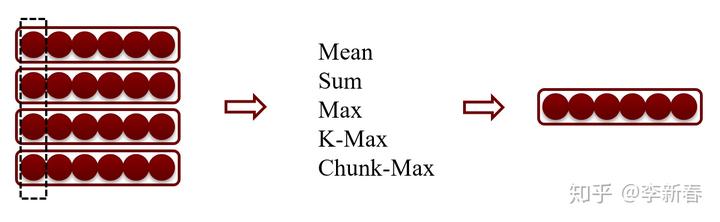
确定性Pooling的方法有很多好处:比如各种不变性(Invariant)。但是Mean Pooling会因为平均而降低某一个区域的激活值,Max Pooling会不稳定。
然后Stochastic Pooling是论文《Stochastic Pooling for Regularization of Deep Convolutional Neural Networks》里面提出的一种随机性池化方法,根据ReLU之后的激活值的大小进行按照Multinomial概率分布选择一个值,示意图如下:
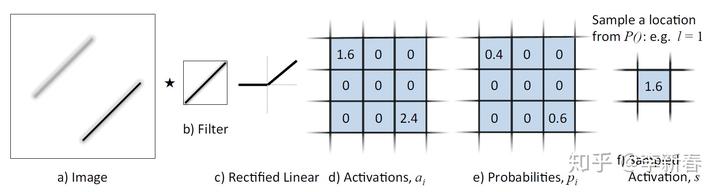
然后在测试过程中,根据概率值进行加权得到相应的Pooling值,类似于Dropout机制,也是充当了一个正则化的作用。
- Aggregation
有一些机器学习的任务需要做一些集合型数据集,即顺序不变性,比如统计人群数量、点云分类或者多实例数据集。一般用来做顺序无关的数据集有几种方法,包括:1)人工设定一个排序方式;2)使用多个排序来扩充训练数据集;3)使用单个函数对每个样本进行处理,然后使用一个顺序无关的函数来处理,比如Mean、Max、Sum等等。
在《Deep Sets》里面给出了一个定理:对于一个集合数据  施加一个函数
施加一个函数  ,当且仅当它可以被分解为
,当且仅当它可以被分解为  ,它就是一个合理的集合函数,即具有顺序不变性。这个结果告诉我们可以使用单独的变换函数
,它就是一个合理的集合函数,即具有顺序不变性。这个结果告诉我们可以使用单独的变换函数  对每个样本进行处理,然后使用聚合函数
对每个样本进行处理,然后使用聚合函数  对得到的表示进行处理,然后使用
对得到的表示进行处理,然后使用  进行分类或者回归。
进行分类或者回归。
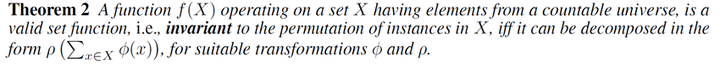
相应的应用可参考PointNet,见《PointNet:Deep Learning on Point Sets for 3D Classification and Segmentation》。
- Gating
门技巧是LSTM里面最常用的一种方法,以GRU为例,参考文章《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》:
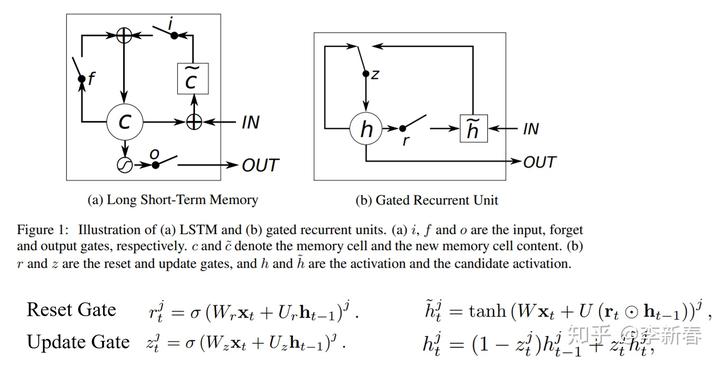
其中包括重置门和更新门,Reset Gate和Update Gate。重置门会计算一组经过Sigmoid激活函数对 
进行点乘,相当于加了权重;更新门会计算一组Sigmoid激活地函数来控制使用新的隐层或旧的隐层值。
- Squeeze-Excitation
这是CVPR2018 《Squeeze-and-Excitation Networks》提出的一种利用Channel信息的方法,示意图见下图:
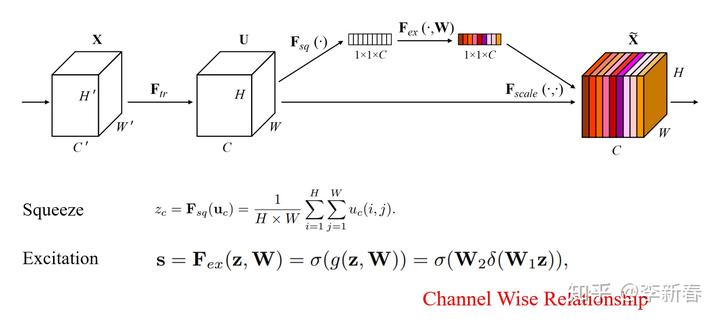
对于CNN里面图像的处理,得到的基本上都是一个“立方体”,大小为:  。其中
。其中  是通道,对于每一个通道,先做Squeeze,即Mean Pooling,然后使用带参数的激活函数进行Excitation,得到一组权值
是通道,对于每一个通道,先做Squeeze,即Mean Pooling,然后使用带参数的激活函数进行Excitation,得到一组权值  ,施加到对应的通道上。
,施加到对应的通道上。
3. Varieties of Attention
下面介绍一下Attention的变种,包括:Feed forward attention, Self attention, Co attention等等。
- Feed forward attentio**n**
最常用的Attention之一是Feed forward attention,其中查询Query被设置为是可以学习的参数  ,然后检索库里面的Key和Value被设置为一样的,即
,然后检索库里面的Key和Value被设置为一样的,即  。
。
然后得到的Attention机制为,实际实现过程可以使用一层神经网络来计算Attention权值:

最后为了使得Attention机制更加复杂,可以使用两层神经网络来计算Attention权值,即设置多个Query,类似下面: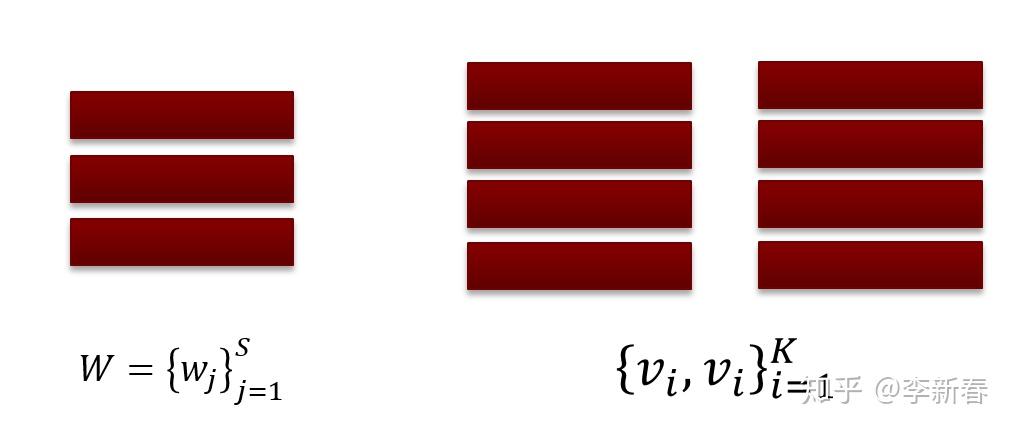
那么计算过程为:

其中  计算了 和 S 个Query的内积相似度,然后经过 tanh 激活函数得到 S 个相似度,然后 S 个相似度又会使用另外一组可以学习的参数
计算了 和 S 个Query的内积相似度,然后经过 tanh 激活函数得到 S 个相似度,然后 S 个相似度又会使用另外一组可以学习的参数  加权得到最终的相似度。
加权得到最终的相似度。
有时候为了增加  之间的差异性,会加入一个关于
之间的差异性,会加入一个关于  正则化项:
正则化项:

有个示意图如下: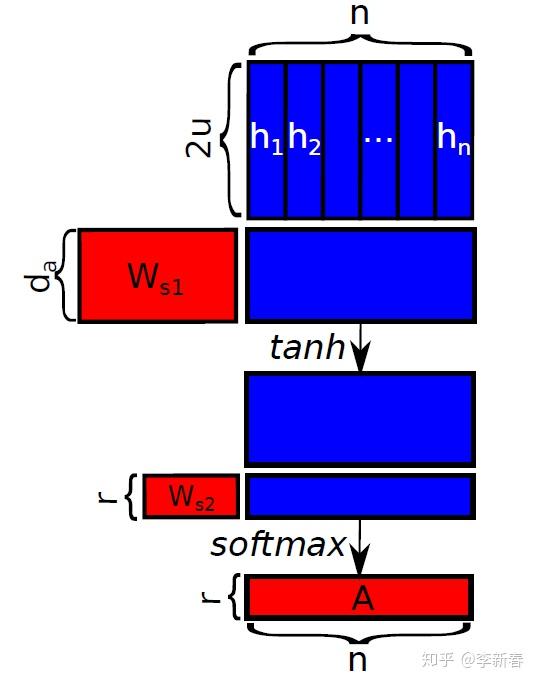
**
- Self Attention
Self attention会让Query, Key和Value一样,示意图如下:
对于第 j 个样本,计算其和所有其余样本的相似度,然后进行Softmax得到权值,加权得到新的表示:
对于每一个  都可以得到一个Self Attention的结果,那么对于所有的
都可以得到一个Self Attention的结果,那么对于所有的  ,得到的新的表示为:
,得到的新的表示为:

即先计算两两内积  ,然后根据行做Softmax得到权值,然后得到加权后的结果。
,然后根据行做Softmax得到权值,然后得到加权后的结果。
有时候,在一些序列有关的数据当中,会额外加入一些位置关系的先验,比如《Self-Attention with Relative Position Representations》中的一种方法:
然后,  是一系列需要学习的参数。
是一系列需要学习的参数。
- Multi Head Attention
在Transformer的提出文章《Attention Is All You Need》中,提出了Multi Head Attention,示意图如下: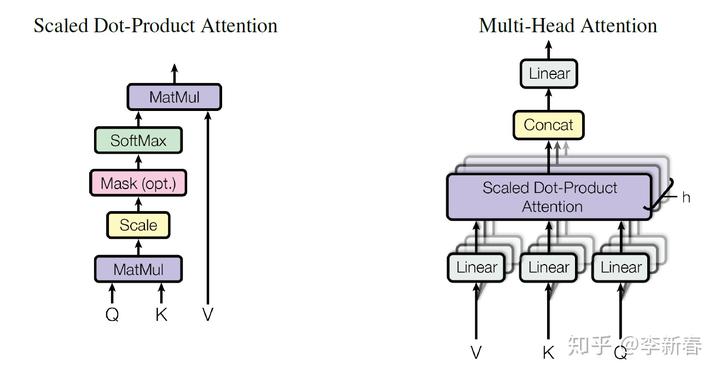
其中Scaled Dot Product Attention指的是:
然后Multi Head Attention就是使用多组Attention得到相应的结果并拼接:
然后ACL 2019有一篇文章《Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned》对多个Head进行了分析,其中有一些有意思的结论,多个Head的作用有大多数是冗余的,很多可以被砍掉,并且还对多个Head进行分类。
文中通过在多个数据集上跑实验,发现大部分Head可以分为以下几种:
- Positional Head:这个Head计算的权值通常指向临近的词,规则是这个Head在90%的情况下都会把最大的权值分配给左边或者右边的一个词。
- Syntactic Head:这个Head计算的权值通常会将词语之间的关系联系起来,比如名词和动词的指向关系。
- Rare Head:这个Head通常会把大的权值分配给稀有词。
然后文章还分析了如何去精简Heads,优化的方法如下(给各个Head加个权值,相当于门):

然后去优化  ,加入
,加入  稀疏正则化损失:
稀疏正则化损失:
最后为了近似  ,其中
,其中  的优化可以采用Gumbel Softmax技巧,因此每次训练的时候相当于使用了Sampling的技巧从多个Head里面选出来一部分进行运算,而Sampling的依据(参数 )则可以通过Gumbel Reparametrization的技巧来实现。
的优化可以采用Gumbel Softmax技巧,因此每次训练的时候相当于使用了Sampling的技巧从多个Head里面选出来一部分进行运算,而Sampling的依据(参数 )则可以通过Gumbel Reparametrization的技巧来实现。
- Convolution Attention
在卷积神经网络里面Attention有了更多的变种,比如ECCV 2018 《CBAM: Convolutional Block Attention Module》提出的CBAM: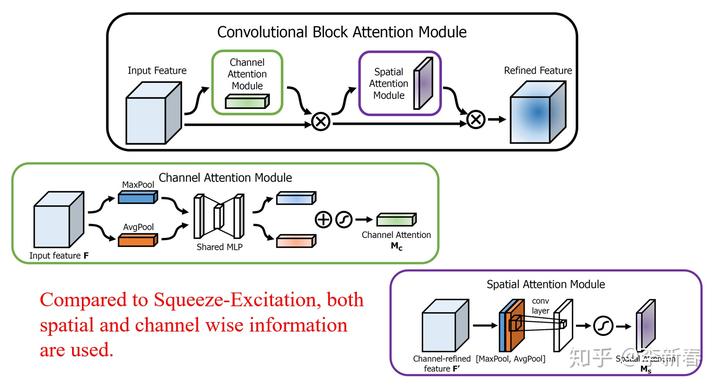
首先,经过Channel-wise计算每个Channel的权值,类似于Squeeze-Excitation,但是这个里面同时考虑了Global Max Pool和Global Average Pool。此外,又针对Spatial的信息进行了加权。
- Pyramid Attention
下面介绍一下Attention金字塔,源于Pyramid Pooling技巧。关于Pyramid Pooling,推荐大家阅读何凯明的《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,示意图如下:
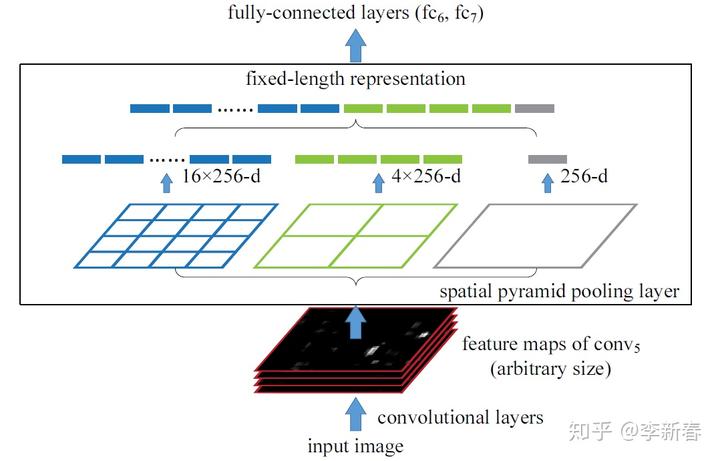
输入的图像经过卷积层得到Feature maps,然后经过Spatial Pyramid Pooling层得到不同大小的pooling结果。举例而言,上图最右边的pooling是对每个通道进行全局池化得到256个值(有256个通道),中间的是对每个特征层划分为四个区域进行Pooling,故而得到4 * 256个值,其余类似。然后将各个层次得到的pooling的结果拼接成一个向量。
关于Pyramid Attention,类似于Pyramid Pooling,可以使用多个层次的Attention,然后将向量拼接起来得到一个向量,比如ACM MM 2018提出的《Attention-based Pyramid Aggregation Network for Visual Place Recognition》: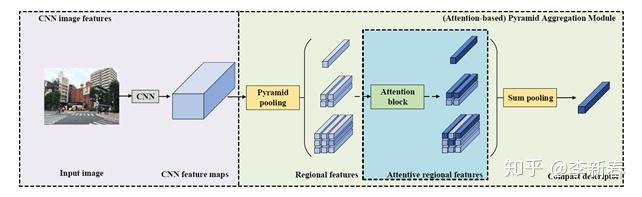
- Co Attention
在多种任务中,可能涉及到成对的输入,比如Video Object Segmentation或者Question Answering,每个输入经过网络会得到一组向量,然后两组向量互相Attend就是Co Attention。
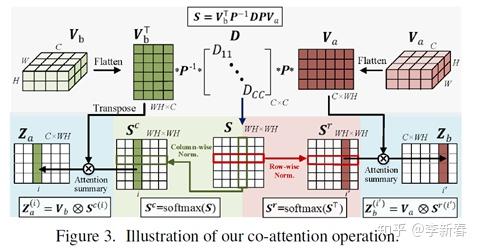
比如在CVPR 2019的文章《See More, Know More: Unsupervised Video Object Segmentation With Co-Attention Siamese Networks》里面,针对Video Segmentation任务,对两帧图片经过Siamese Networks进行处理得到相应的多个通道的表示  ,然后两者互相Attend得到:
,然后两者互相Attend得到:

然后根据行和列分别做Softmax得到权值,接下来把Attention的结果和原有特征拼接,即是CoAttention的框架: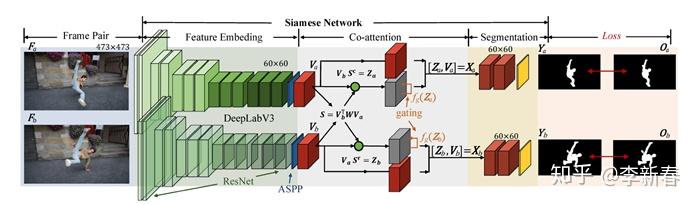
- Cross Attention
Cross Attention类似于Co Attention,比如最近的NeurIPS 2019的《Cross Attention Network for Few-shot Classification》:
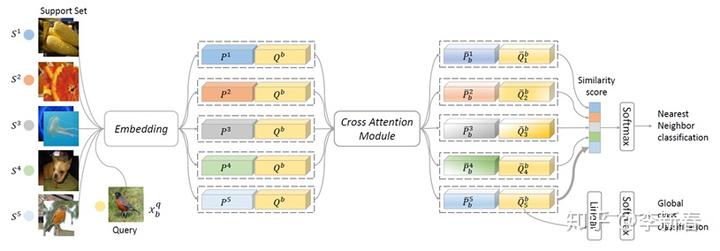
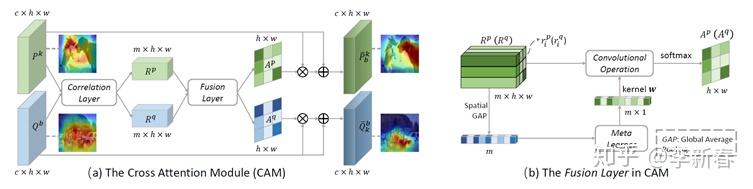
其中Query和Support Set里面的每一张图像都经过一个网络提取特征,得到相应的 
的特征,然后互相Attend得到重组的特征,再计算相似度进行Meta Train。
- Soft vs. Hard Attention
正如上面所述,Attention是基于一组权值进行加权的过程。一般情况下,权值都是基于Softmax之后的连续值,即Soft Attention;但是,为了更好地排除一些不必要的干扰,可以使用基于更为稀疏甚至One-Hot的权值进行加权,即Hard Attention。
关于Soft和Hard的区别在ICML 2015的《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》里面就有提到过。Hard Attention更难训练,因为优化过程涉及离散权值的优化,因此文章采用了强化学习的方法进行优化,即REINFORCE。
在Image Caption当中,输入是一张图片,输出是一句话。记图片特征为  ,生成的句子目标为
,生成的句子目标为  ,那么优化目标就是最大化似然
,那么优化目标就是最大化似然  ,这里的
,这里的  是一个序列。然后记 为隐变量,指的是Attend到的位置,比如
是一个序列。然后记 为隐变量,指的是Attend到的位置,比如  代表着生成第
代表着生成第  个词的时候Attend到的是第
个词的时候Attend到的是第  个位置。那么优化目标的推导为:
个位置。那么优化目标的推导为:

在训练过程 步中,根据图片特征 以及之前的 生成一个多项式概率分布的参数  ,记生成过程所需要的参数为
,记生成过程所需要的参数为  :
:
然后根据多项式分布进行采样:
根据生成的Attend的位置  ,结合对应的图像特征,生成句子,计算似然
,结合对应的图像特征,生成句子,计算似然  ,然后计算损失,注意这部分参数为
,然后计算损失,注意这部分参数为  。对优化目标求导可以得到(其中
。对优化目标求导可以得到(其中  ):
):

采用蒙特卡洛法估计可以得到梯度的估计值:

以上梯度包括两部分,第一部分是对多项式分布参数的优化,即 ,可以看出是REINFORCE进行优化的,这里的回报  ;第二部分优化的是生成句子的过程,参数为 ,和正常优化一样,使用的是似然函数的梯度。
;第二部分优化的是生成句子的过程,参数为 ,和正常优化一样,使用的是似然函数的梯度。
值得一提的是本文中的Hard的效果会比Soft略好: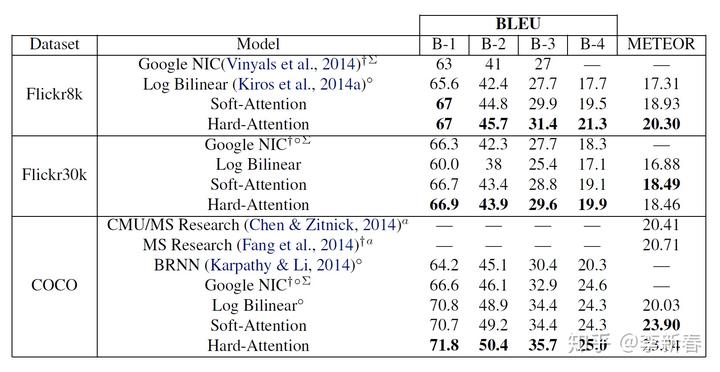
- Global vs. Local Attention
Global Attention是全局的Attention,利用的是所有的序列计算权重,但如果序列长度太长,那么基于Soft的权值会比较趋向于小的权值,所以此时需要Local Attention进行处理,即事先选择一个要计算Attention的区域,可以先得到一个指针,类似于Pointer Net。
Local Attention是介于Soft和Hard Attention的一种机制,在文章EMNLP 2015 《Effective Approaches to Attention-based Neural Machine Translation》中就有介绍到,其实很简单,关于Global和Local的Attention用下面两幅图可以很好地解释清楚: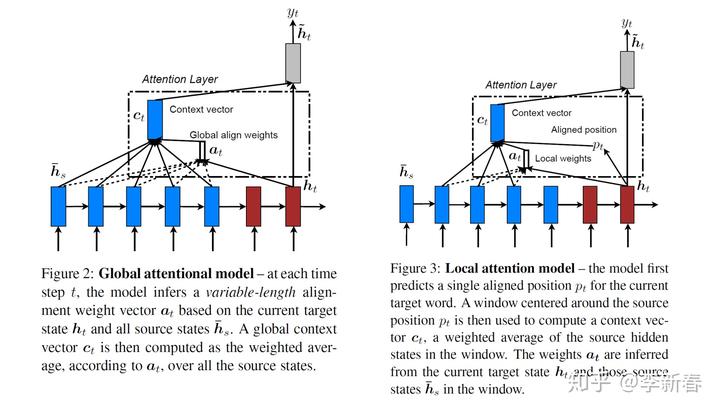
图中蓝色的是Encoder的序列,棕色的是Decoder的序列,左边是全局Attention,根据  和所有Encoder的序列计算权值
和所有Encoder的序列计算权值  ,然后进行加权得到
,然后进行加权得到  ;右边是Local Attention,则是先根据 生成一个Aligned position,然后选择部分(右图虚线选择了三个)进行加权。
;右边是Local Attention,则是先根据 生成一个Aligned position,然后选择部分(右图虚线选择了三个)进行加权。
- Compositional Attention
在NeurIPS 2019上,《Compositional De-Attention Networks》提出了下面的一种框架:
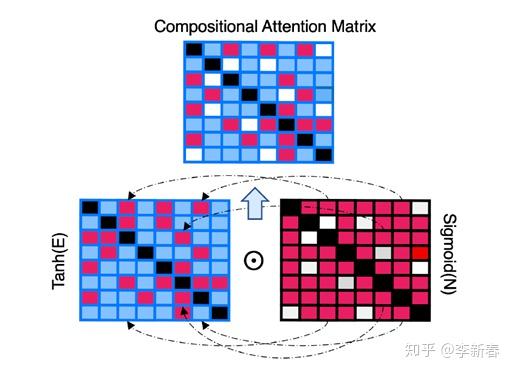
文章综合利用了两种相似度,分别是:Pairwise Affinity & Distance Dissimilarity。
Pairwise Affinity指的是  ,Distance Dissimilarity指的是
,Distance Dissimilarity指的是  ,其中
,其中  是Encoding的函数,
是Encoding的函数,  是缩放因子。然后最后的Attention计算方式为:
是缩放因子。然后最后的Attention计算方式为:
所以可以看出CoDA的核心就是在于构造相似度,采用了两种计算方法和两种不同的激活函数进行复合。
- Dual Attention
其实Compositional Attention的思想并不是在NeurIPS 2019才出现,很多之前的文章会采用多种形式的Attention来进行构造模型。比如Local Attention和Global Attention的结合,卷积网络里面Positional Attention和Channel Attention的结合等等。
比如文章CVPR 2019 的《Dual Attention Network for Scene Segmentation》: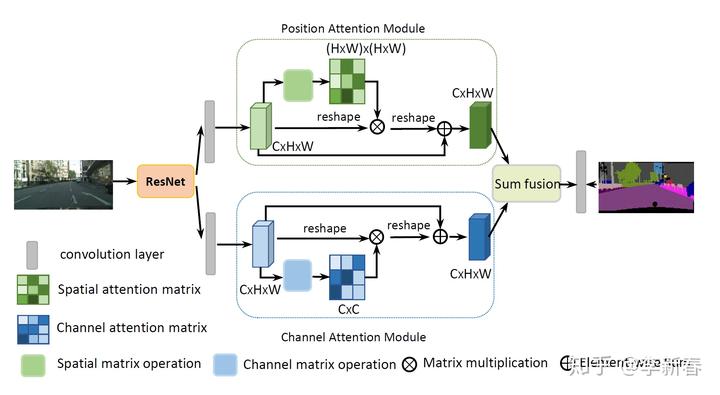
以及文章RecSys 2017 《Interpretable Convolutional Neural Networks with Dual Local and Global Attention for Review Rating Prediction》:
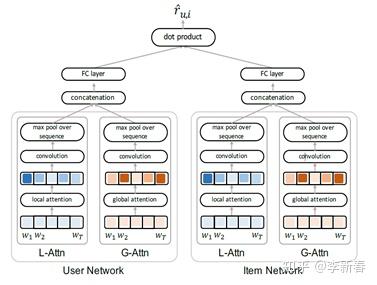
4. Conclusion
总结一下,Attention的本质就是加权,权值可以反应模型关注的点,随着各种技术的发展,Attention的变体越来越多,并且被逐渐应用到计算机视觉、自然语言处理、小样本学习、推荐系统等等多种任务上。

若有收获,就点个赞吧
0 人点赞
