源码分析
queue.py 
- 支持自定义 序列化类的传入,只要实现loads和dumps方法
- queue.py 中的Base基类 实现了对request对象序列化和反序列化的过程
- FifoQueue、PriorityQueue、LifoQueue继承于Base类
dupefilter.py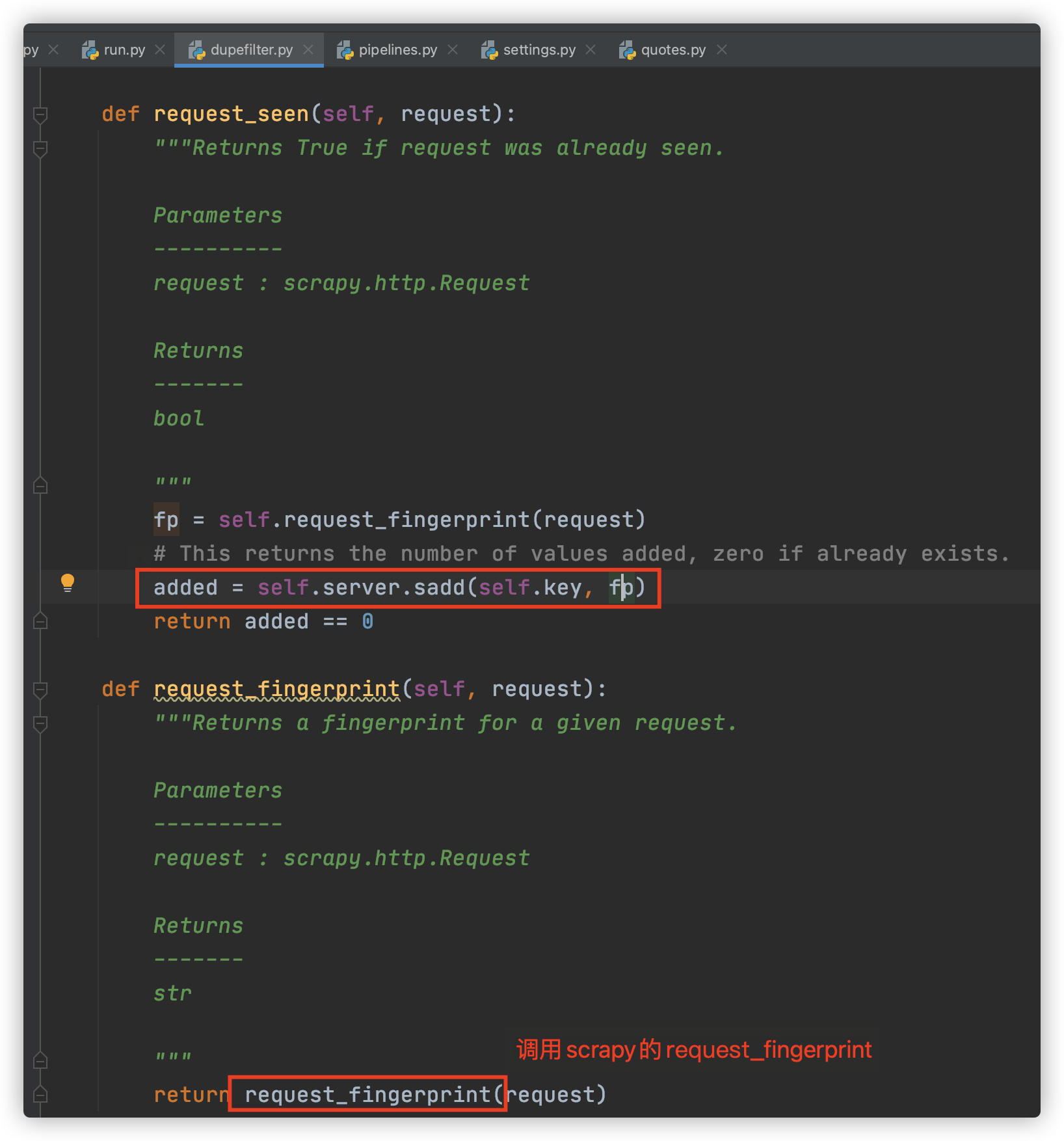
- 实现了一个 request_seen 方法,和 Scrapy 中的 request_seen 方法实现极其类似。不过这里集合使用的是 server 对象的 sadd 操作,也就是集合不再是一个简单数据结构了,而是直接换成了数据库的存储方式。
- added 为1 则添加成功 request_seen为为False
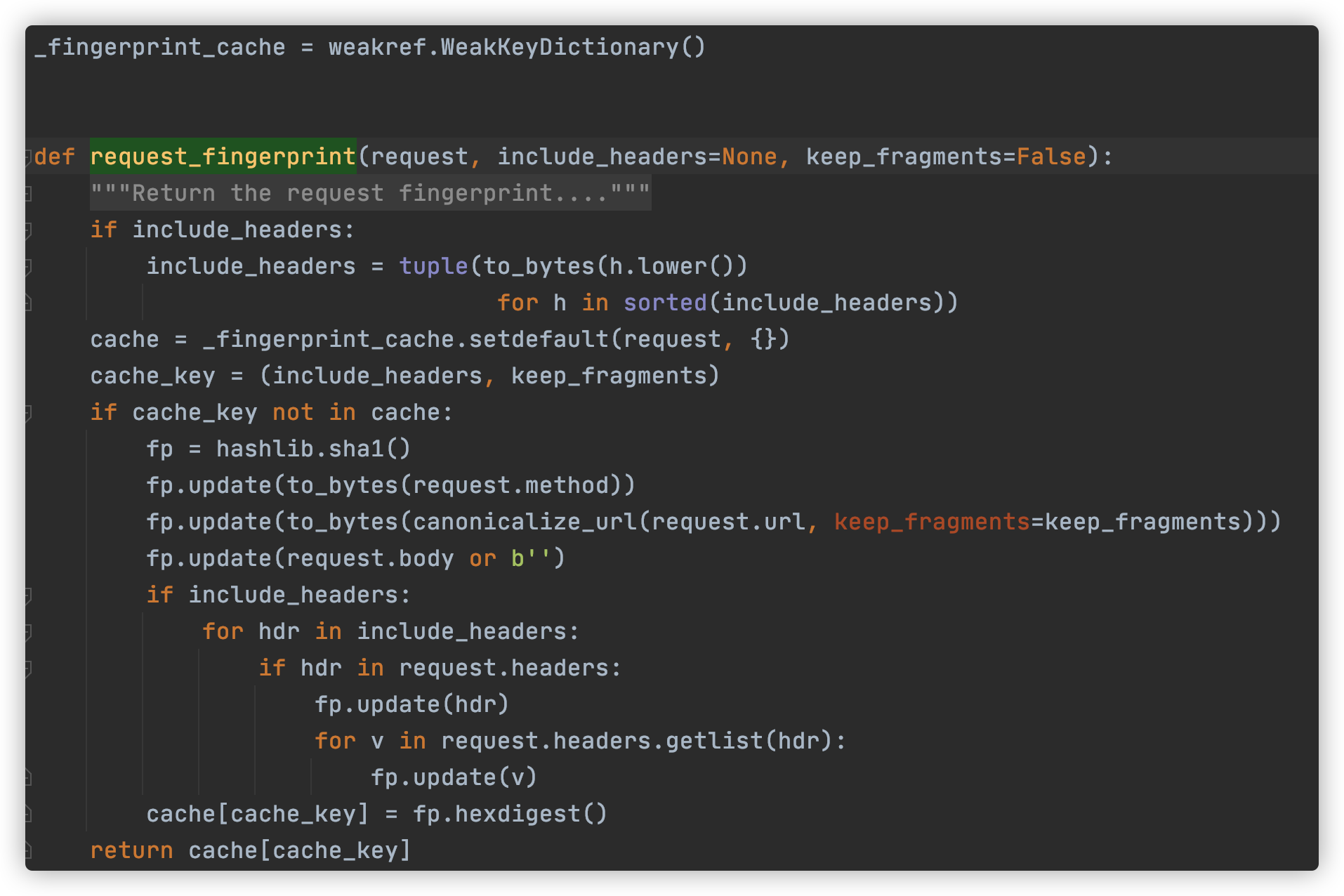
- scrapy.utils.request.request_fingerprint
scheduler.py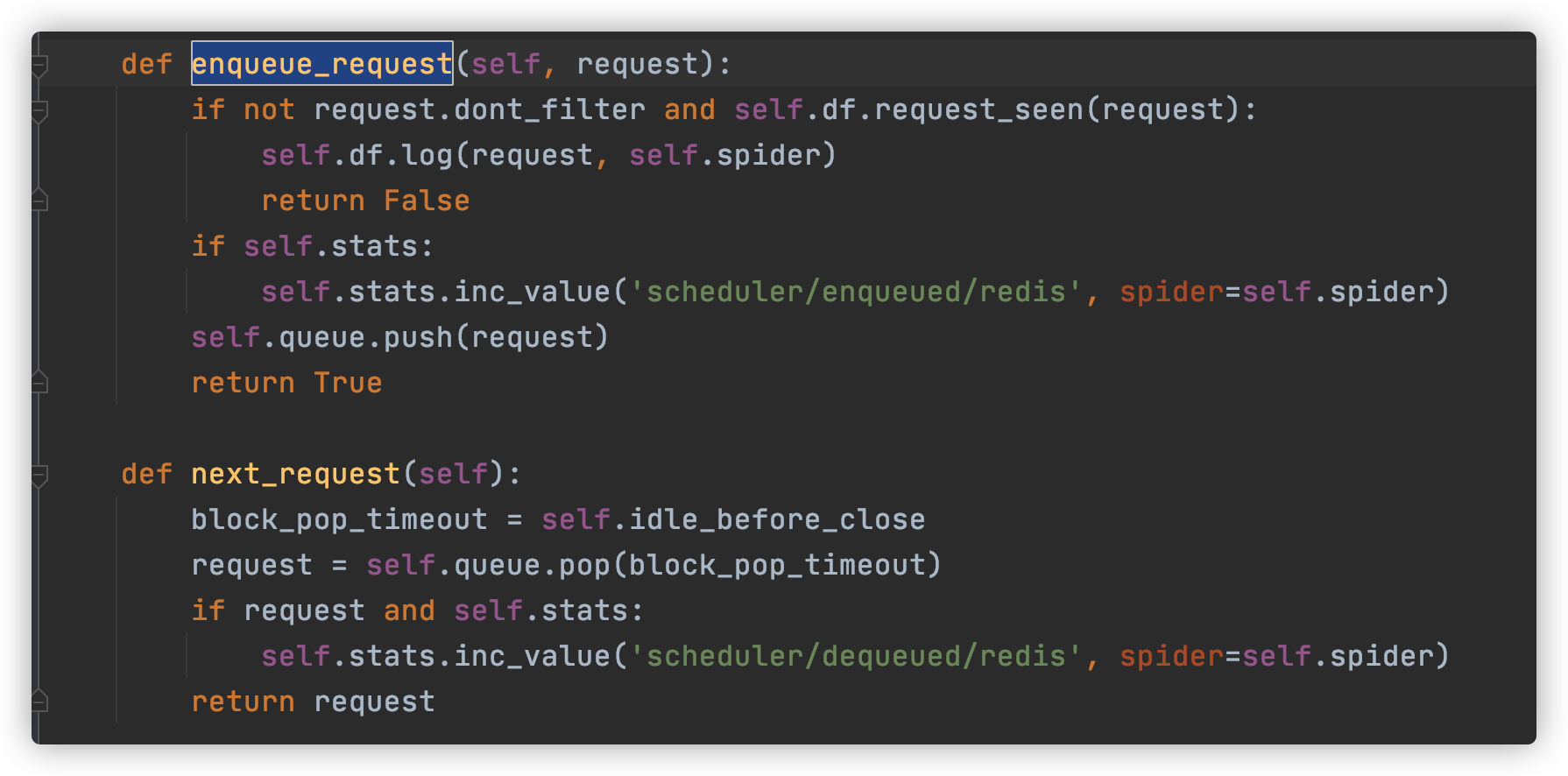
- enqueue_request 可以向队列中添加 Request,核心操作就是调用 Queue 的 push 操作,还有一些统计和日志操作。next_request 就是从队列中取 Request,核心操作就是调用 Queue 的 pop 操作,此时如果队列中还有 Request,则 Request 会直接取出来,爬取继续,否则如果队列为空,爬取则会重新开始。
- Queue可以为FifoQueue、PriorityQueue、LifoQueue,默认为PriorityQueue
- 调用队列的push方法前,会对request对象进行编码,及_encode_request(序列化过程)方法
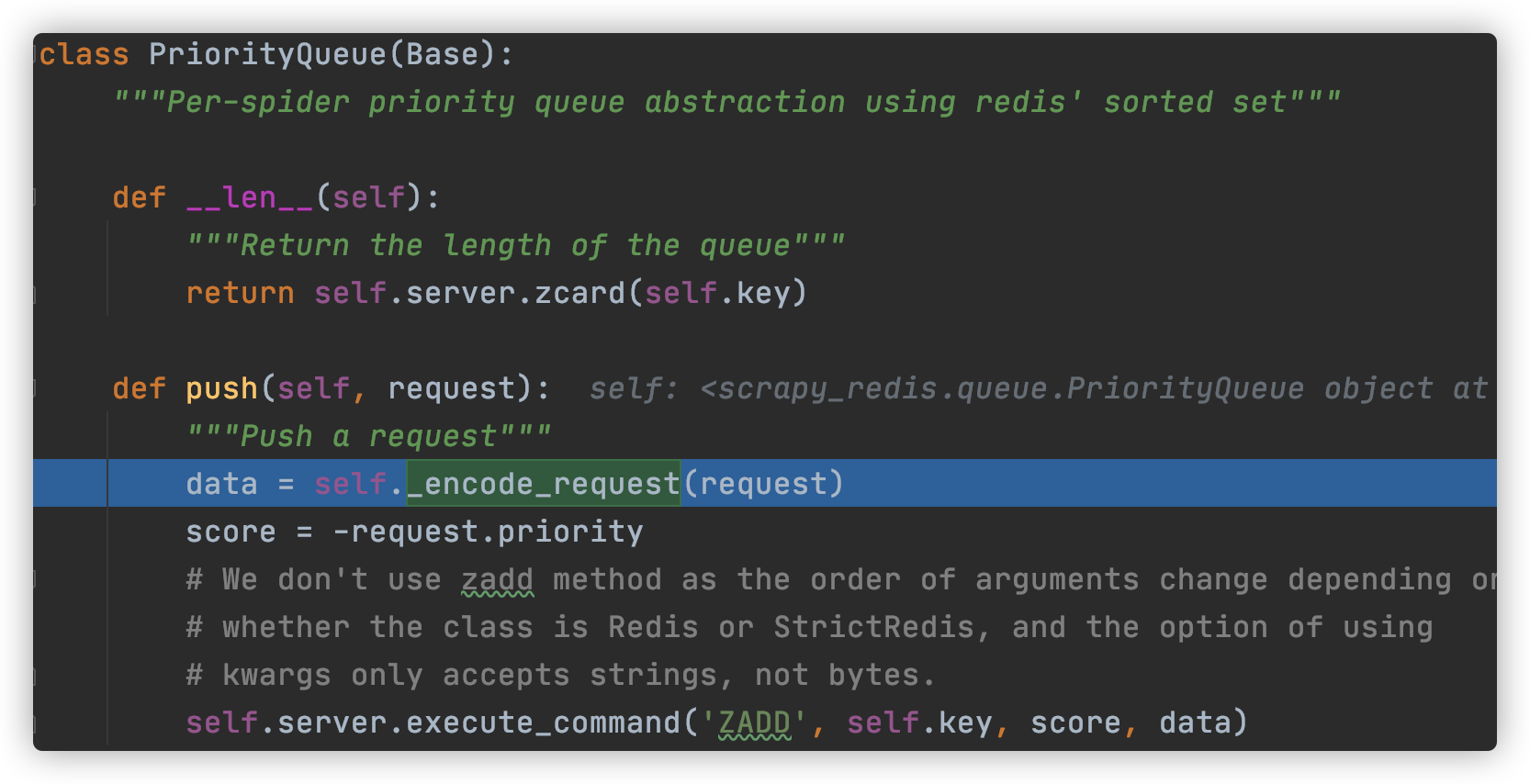
- 调用scrapy的request_to_dict,将request变成dict对象,然后再调用序列化类进行序列化,最后将序列化后的结果加入redis
settings.py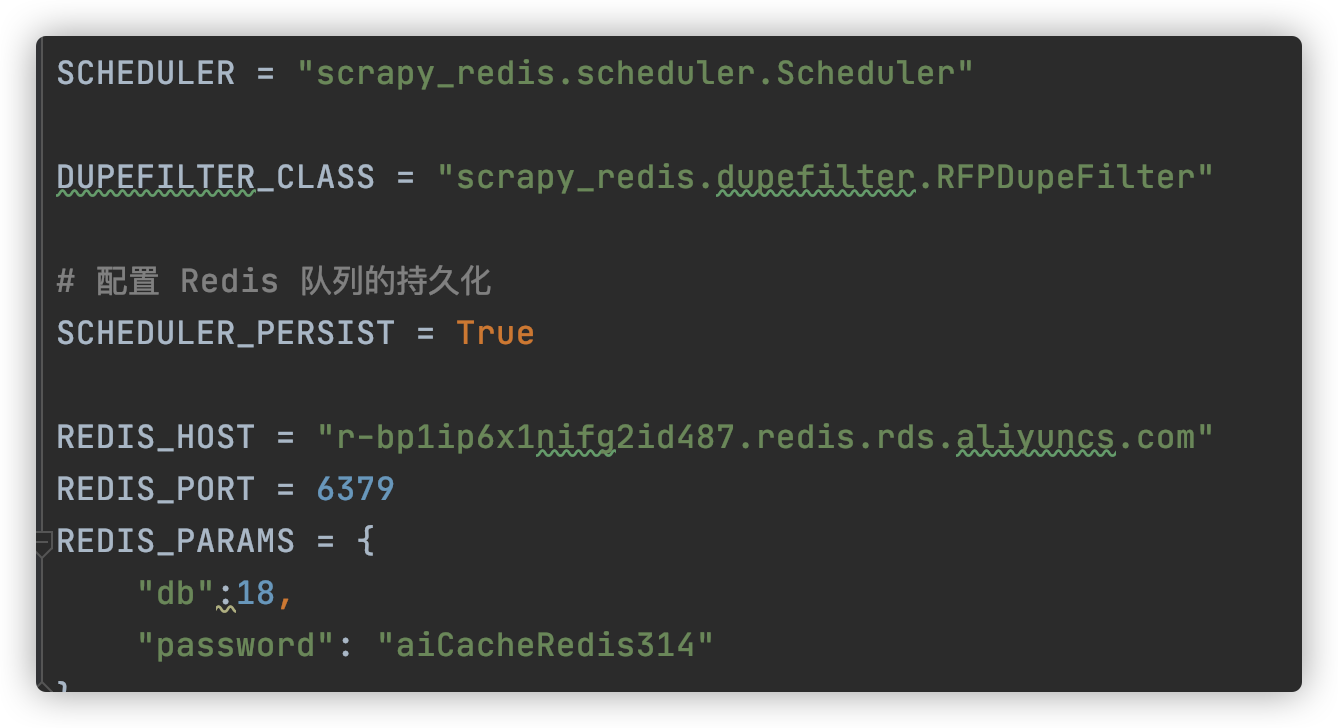
在redis中会出现 [spider_name]:duplefilter 和 [spider_name]:requests这两个key,默认使用优先队列

若有收获,就点个赞吧
0 人点赞
