主循环
ExecutionEngine是scrapy的核心模块之一,顾名思义是执行引擎。它驱动了整个爬取的开始,进行,关闭。
它又使用了如下几个主要模块来为其工作:
1.slot:它使用Twisted的主循环reactor来不断的调度执行Engine的”_next_request”方法,这个方法也是核心循环方法。下面的流程图用伪代码描述了它的工作流程,理解了它就理解了引擎的核心功能。另外slot也用于跟踪正在进行下载的request。
2.downloader:下载器。主要用于网页的实际下载
3.scraper:数据抓取器。主要用于从网页中抓取数据的处理。也就是ItemPipeLine的处理。
根据上面的分析可知,主要是_next_request在不断的进行工作,因此这个函数重点分析,流程图如下:
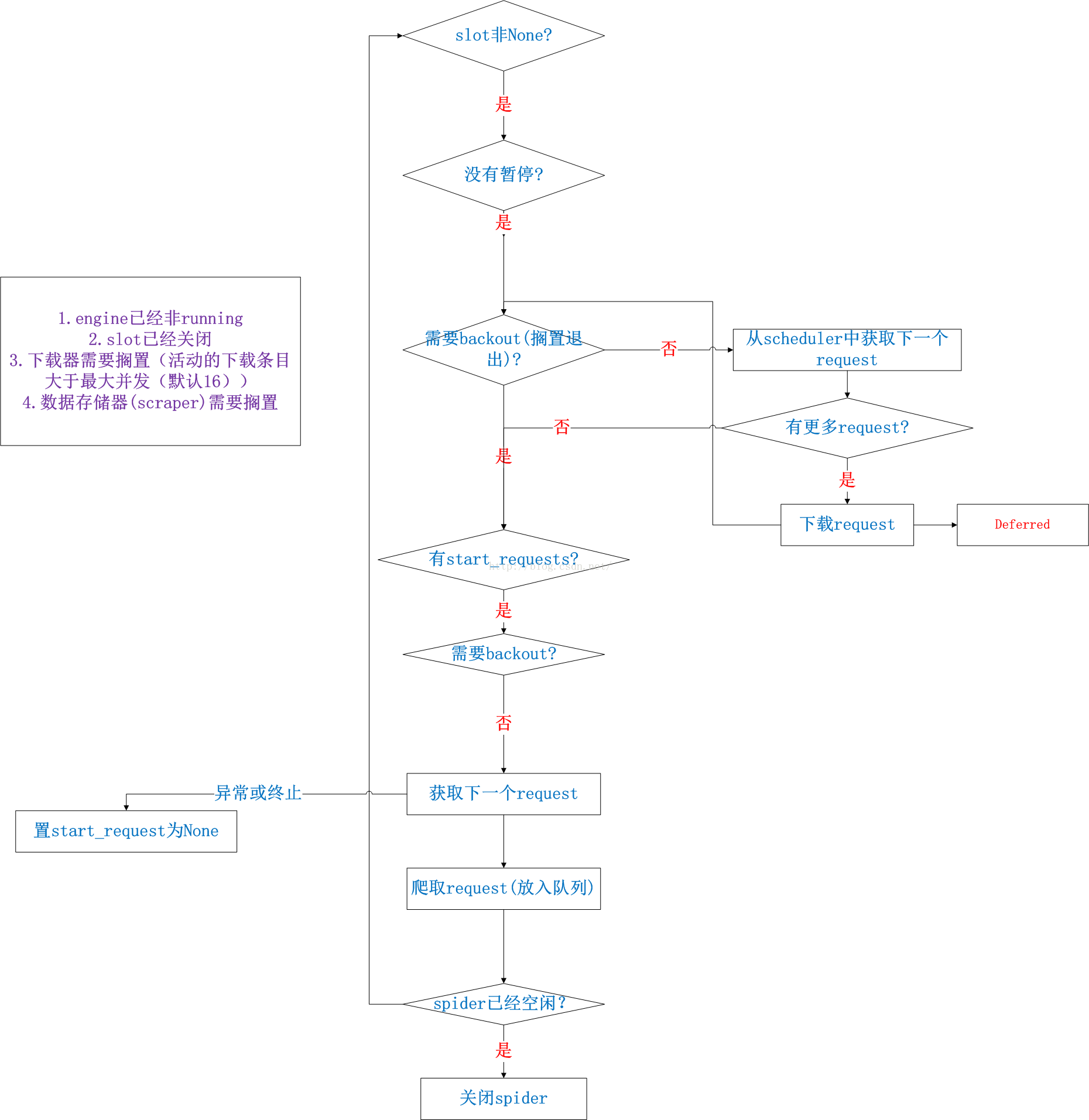
流程详解:
1.这个_next_request方法有2种调用途径,一种是通过reactor的5s心跳定时启动运行,另一种则是在流程中需要时主动调用。
2.如果没有暂停,则运行。判断是否需要搁置?这个判断条件如右边紫色框中讲的,有4种需要搁置的条件。如果不需要搁置,
则执行3;如果需要搁置,则执行4.
3.获取一个request,这个获取是从队列中获取。获取到则通过下载器下载(这个是Deferred实现的,因此是异步的)。如果
没有request了,则执行4;如果一直有,则不断的执行2.
4.判断start_requests如果有剩余且不需要搁置,则获取一个,并调用crawl方法,这个方法只是将request放入队列。这样,
3中就能获取到了;如果没有start_requests了或者需要搁置则执行5.
5.判断spider是否空闲,这里需要判断没有任何下载任务,没有任务数据处理任务,没有start_requests了,没有阻塞的requests了。
只有都满足才可能关闭并结束。
一个request的周期
下面就具体讲解下不需要搁置时,如何处理一个request,从下载页面到解析页面,最后到数据处理的整个流程。
几个核心的类介绍如下:
1.Scraper:刮取器。用于对下载后的结果进行处理,主要使用ItemPipelineManager对数据进行入数据库等操作。
2.Downloader:下载器。对同时下载网页的并发度进行控制,同时通过DownloaderMiddlewareManager来对request,response进行各个中间件的操作。并通过HTTP11DownloadHandler来使用twisted的连接池进行网页下载操作。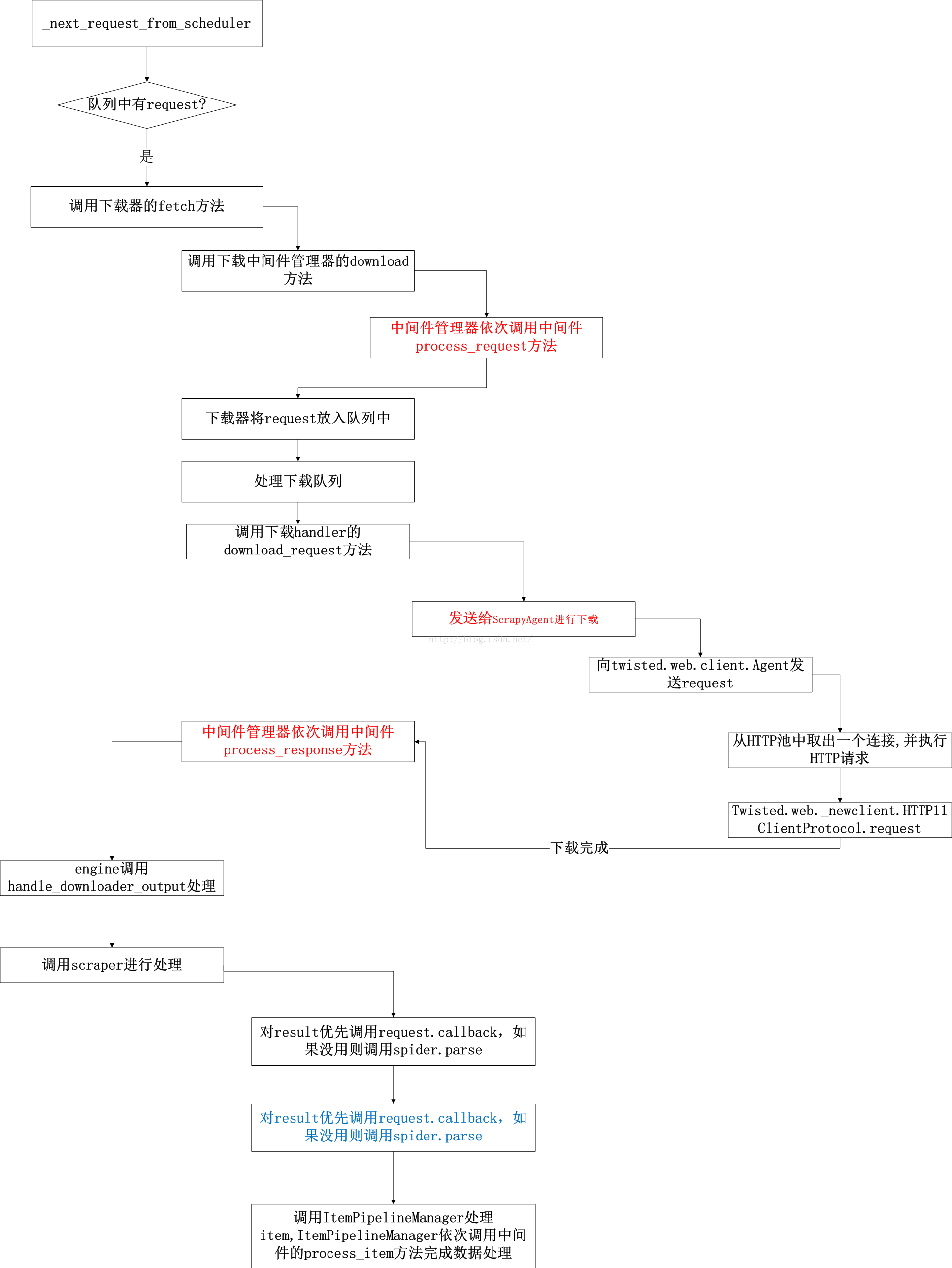

若有收获,就点个赞吧
0 人点赞
