上一篇教程中讲到crawl命令最终会执行CrawlProcess的crawl和start方法。这一篇对CrawlProcess的源码进行详细分析,来了解一下是如何进行爬取任务的。
先看一下CrawlProcess的构造函数:
scrapy/crawler.py:
可以看到这个模块一共有3个类:Crawler,CrawlerRunner,CrawlerProcess。Crawler代表了一种爬取任务,里面使用一种spider,CrawlerProcess可以控制多个Crawler同时进行多种爬取任务。
CrawlerRunner是CrawlerProcess的父类,CrawlerProcess通过实现start方法来启动一个Twisted的reactor,并控制shutdown信号,比如crtl-C,它还配置顶层的logging模块。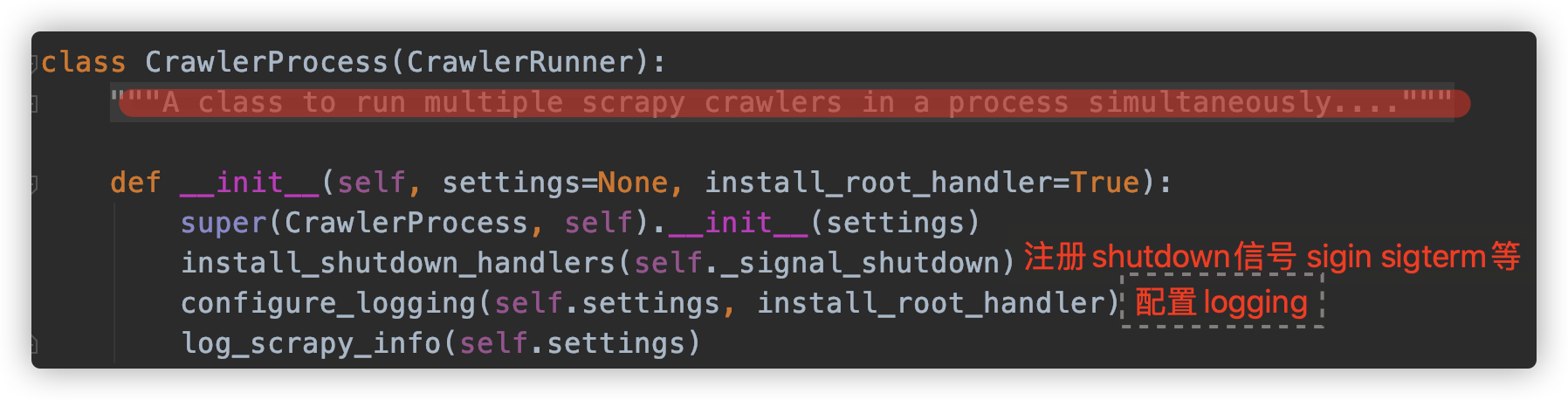
再分别来看crawl命令最终调用的crawl和start函数实现 :
def crawl(self, crawler_or_spidercls, *args, **kwargs):"""Run a crawler with the provided arguments.crawl方法会创建一个Crawler对象,然后调用Crawler的crawl方法开启一个爬取任务,同时Crawler的crawl方法会返回一个Deferred对象,CrawlerProcess会将这个Deferred对象加入一个_active集合,然后就可以在必要时结束Crawler,并通过向Deferred中添加_done callback来跟踪一个Crawler的结束。"""crawler = self.create_crawler(crawler_or_spidercls)return self._crawl(crawler, *args, **kwargs)def _crawl(self, crawler, *args, **kwargs):self.crawlers.add(crawler)d = crawler.crawl(*args, **kwargs) # 调用Crawler的crawl方法self._active.add(d)def _done(result):"""向deferred添加一个callback,如果Crawler已经结束则从活动集合中移除一个Crawler"""self.crawlers.discard(crawler)self._active.discard(d)self.bootstrap_failed |= not getattr(crawler, 'spider', None)return resultreturn d.addBoth(_done)def create_crawler(self, crawler_or_spidercls):"""Return a :class:`~scrapy.crawler.Crawler` object."""if isinstance(crawler_or_spidercls, Spider):raise ValueError('The crawler_or_spidercls argument cannot be a spider object, ''it must be a spider class (or a Crawler object)')if isinstance(crawler_or_spidercls, Crawler): # 如果已经是一个Crawler实例则直接返回return crawler_or_spiderclsreturn self._create_crawler(crawler_or_spidercls)def _create_crawler(self, spidercls):if isinstance(spidercls, str):# 如果crawler_or_spidercls是一个字符串,则根据名称来查找对应的spider并创建一个Crawler实例spidercls = self.spider_loader.load(spidercls)return Crawler(spidercls, self.settings)
这里还需要再分析的就是Crawler对象的crawl方法:
crawl这个函数使用了Twisted的defer.inlineCallbacks装饰器,表明如果函数中有地方需要阻塞,则不会阻塞整个总流程,会让出执行权。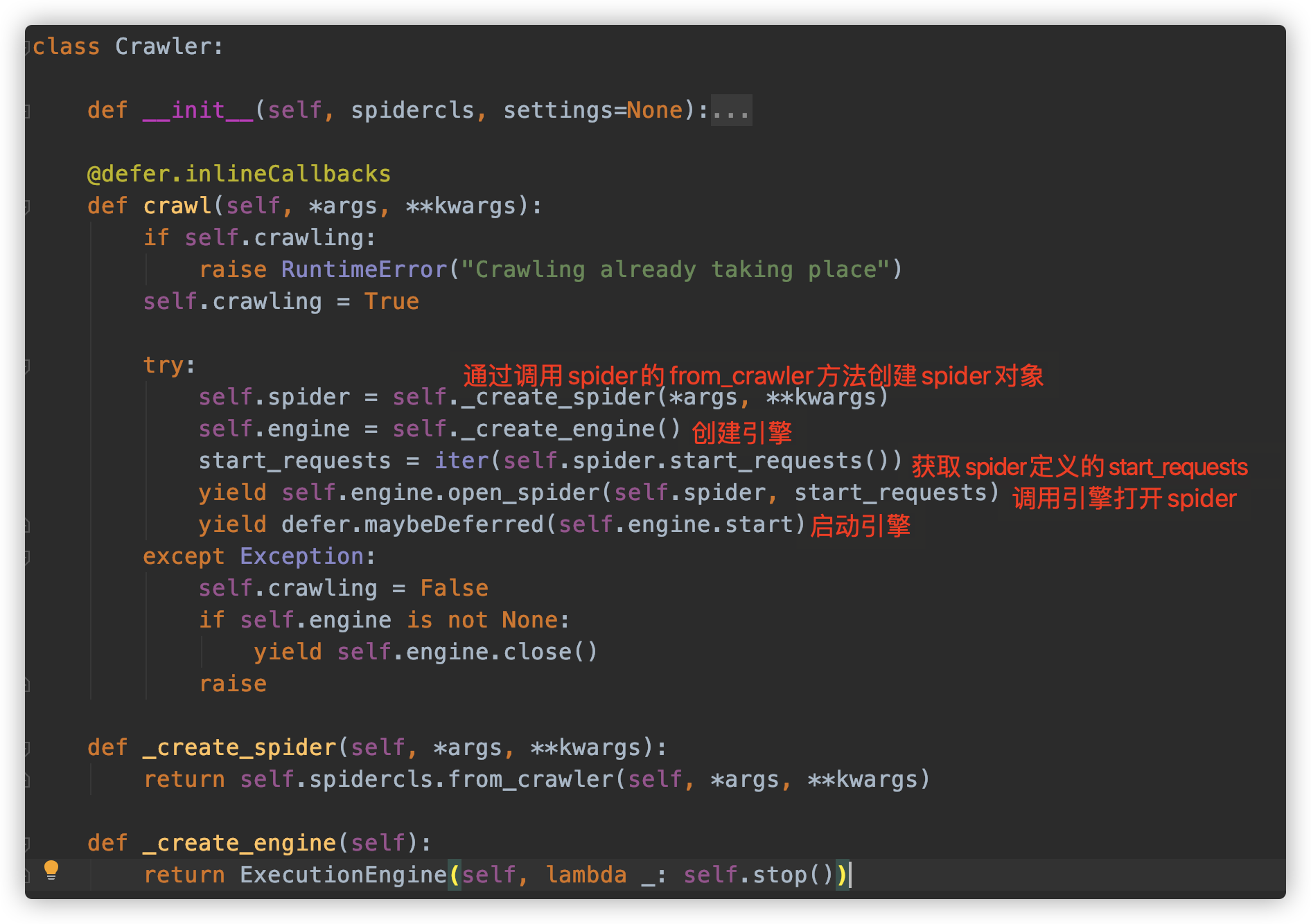
现在,还剩CrawlProcess的start函数,源码分析如下: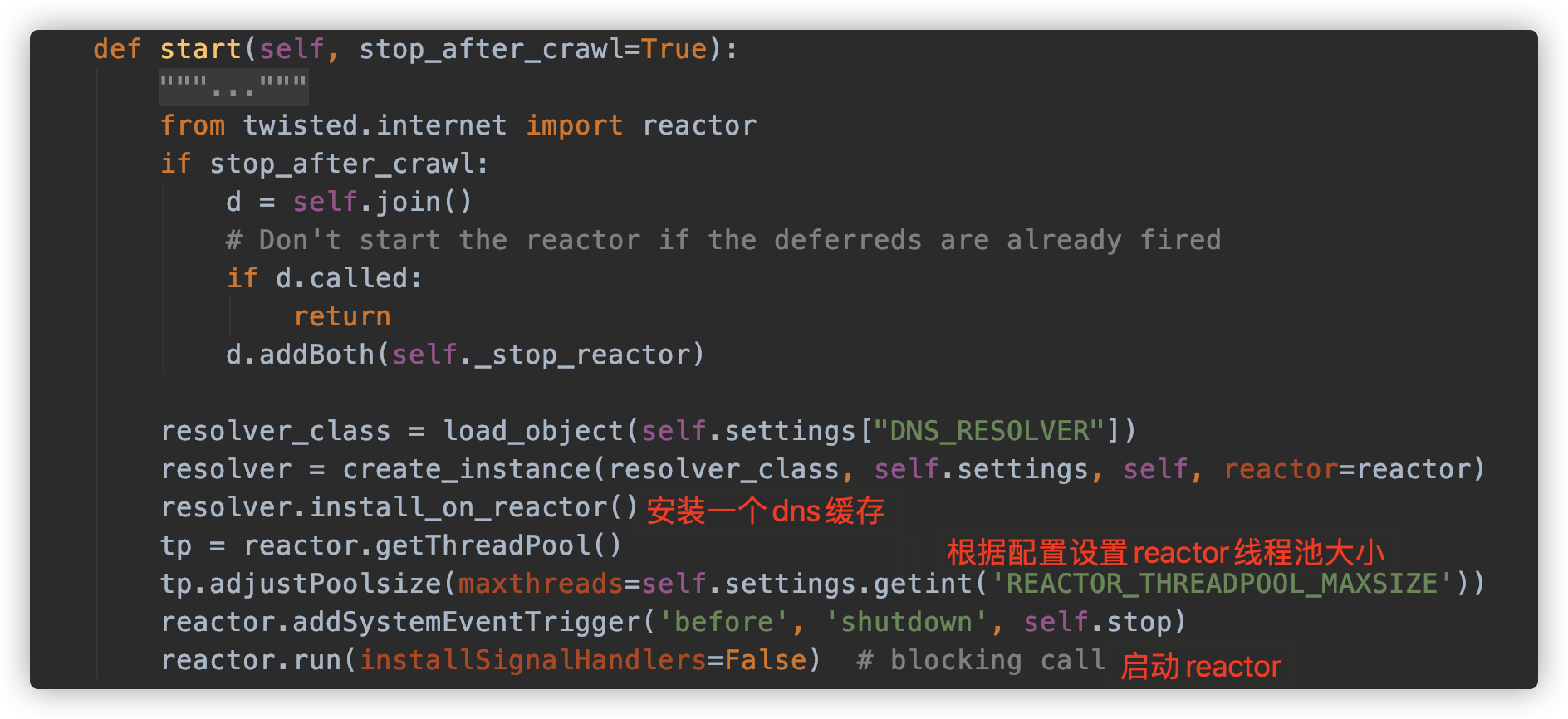
这个函数首先调用join函数来对前面所有Crawler的crawl方法返回的Deferred对象添加一个_stop_reactor方法,当所有Crawler对象都结束时用来关闭reactor。

若有收获,就点个赞吧
0 人点赞
