一、Pushgateway 简介
- Pushgateway 是 Prometheus 生态中一个重要工具,使用它的原因主要是:
- Prometheus 采用 pull 模式,可能由于不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。
- 在监控业务数据的时候,需要将不同数据汇总, 由 Prometheus 统一收集。
- pushgateway一些弊端:
- 将多个节点数据汇总到 pushgateway, 如果 pushgateway 挂了,受影响比多个 target 大。
- Prometheus 拉取状态 up 只针对 pushgateway, 无法做到对每个节点有效。
- Pushgateway 可以持久化推送给它的所有监控数据。
- 即使你的监控已经下线,prometheus 还会拉取到旧的监控数据,需要手动清理 pushgateway 不要的数据。
- 拓扑图
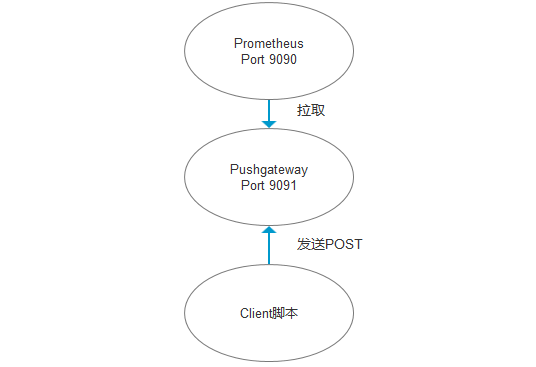
二、部署pushgetway
- 解压到/usr/local下
tar -zxvf pushgateway-1.2.0.linux-amd64.tar.gz
- 启动Blackbox Exporter
./pushgateway
- 访问服务器9091端口
三、与Prometheus集成
- 修改/etc/prometheus/prometheus.yml,将cAdvisor添加监控数据采集任务目标当中:

- 重新启动Prometheus服务:
- 在Prometheus UI中查看到当前所有的Target状态:

四、数据管理
- 向 {job=”some_job”} 添加单条数据:
- 客户端执行如下命令,将数据推送到pushgetway
echo “some_metric 3.14” | curl —data-binary @- http://127.0.0.1:9091/metrics/job/some_job
- —data-binary 表示发送二进制数据,它是使用POST方式发送的!
- pushgetway查看数据
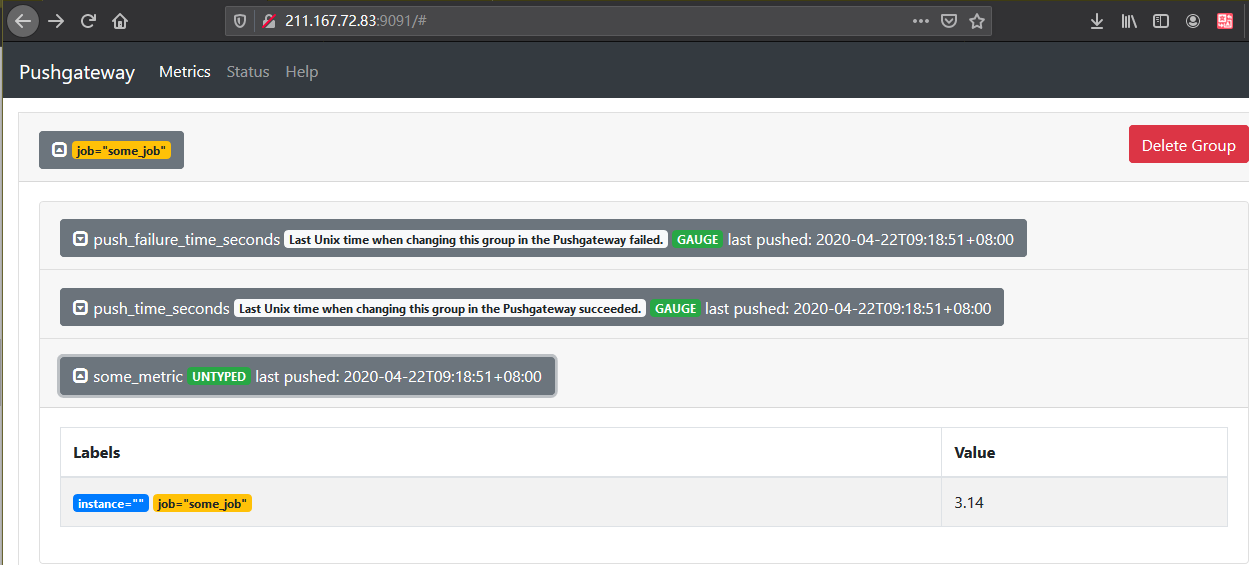
- 删除某个组下的某实例的所有数据:
curl -X DELETE http://127.0.0.1:9091/metrics/job/some_job/instance/some_instance
- 删除某个组下的所有数据:
curl -X DELETE http://127.0.0.1:9091/metrics/job/some_job
- 注意事项:
- pushgateway 中的数据我们通常按照 job 和 instance 分组分类,所以这两个参数不可缺少。
- 在 prometheus 中配置 pushgateway 的时候,需要添加 honor_labels: true 参数, 从而避免收集数据本身的 job 和 instance 被覆盖。
- 注意,为了防止 pushgateway 重启或意外挂掉,导致数据丢失,我们可以通过 -persistence.file 和 -persistence.interval 参数将数据持久化下来。
五、shell脚本实例
- 实现线程总数监控
编写客户端shell脚本
#!/bin/bashinstance_name=`hostname -f | cut -d'.' -f1` #提取主机名保存到instance标签if [ $instance_name == "localhost" ];then #要求机器名不能是localhost,不然标签无法区分echo "Must FQDN hostname"exit 1filabel="count_thread_sum" # 定一个新的 keycount_thread_sum=`ps -efL | wc -l`#获取新key数值为netstat中wait 的数量echo "$label : $count_thread_sum"echo "$label $count_thread_sum" | curl --data-binary @- http://127.0.0.1:9091/metrics/job/pushgateway/instance/$instance_name
设置linux计划任务,每30秒执行一次
- sleep 30; /root/pushgateway-thread-sum.sh >> /var/log/pushgateway.log
- pushgetway查看数据
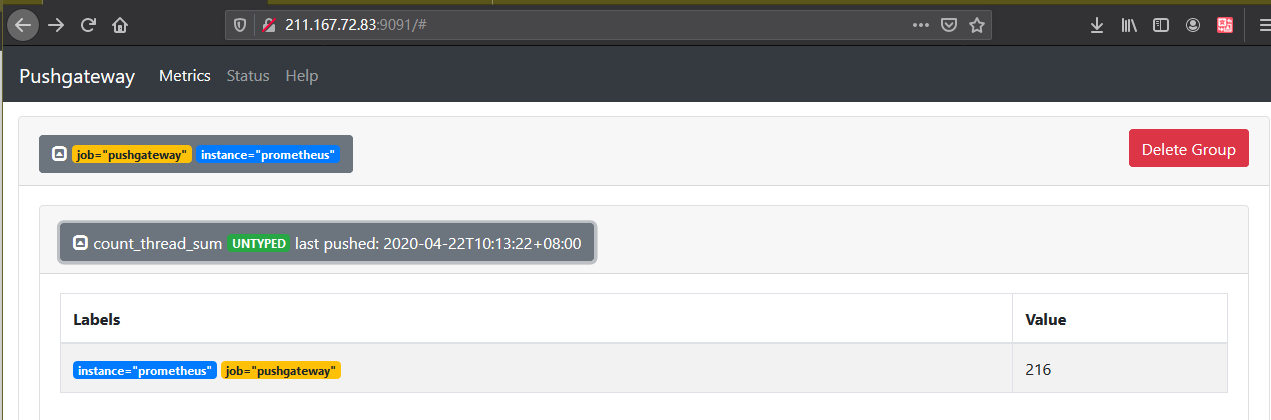
- 进入grafana页面,新建一个图表
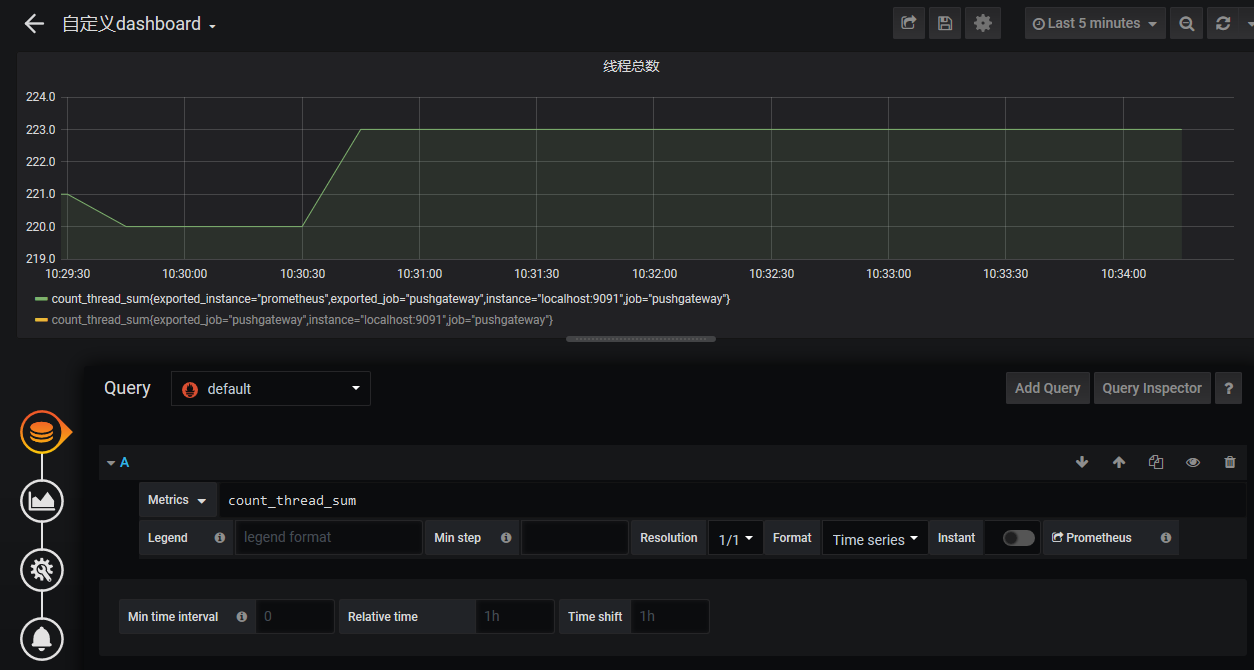
- 监控每个进程资源使用情况

若有收获,就点个赞吧
0 人点赞
