实例来源:MOOC慕课 北京理工大学 嵩天老师的课程实例-《中国大学排名定向爬虫》
1. 概览
对《中国大学排名定向爬虫》实例的改造过程。
学习html网页中表格的提取和解析方法
主要技术方法
2. 原代码分析
目标
目标网址:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
结果
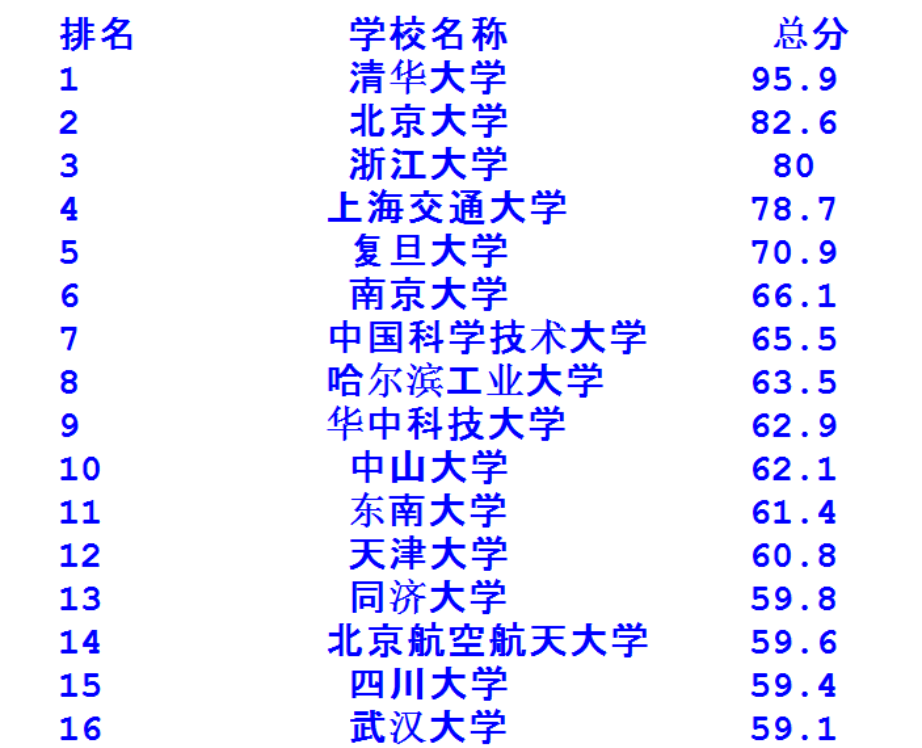
由于网站的改变,原代码已经不能直接运行了
取代网址:’https://www.shanghairanking.cn/rankings/bcur/2021’
检查步骤
1. 检查目标信息是否可以在html网页提取
2. 识别table的层级结构和信息目标
网页——鼠标右键——查看网页源代码——搜索关键信息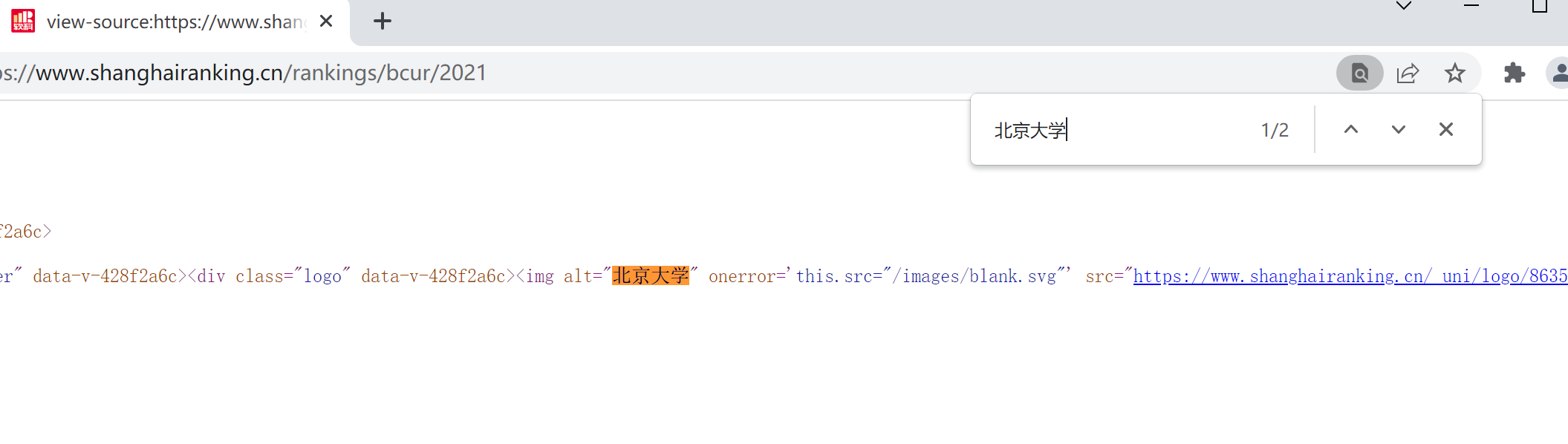 网页——F12
网页——F12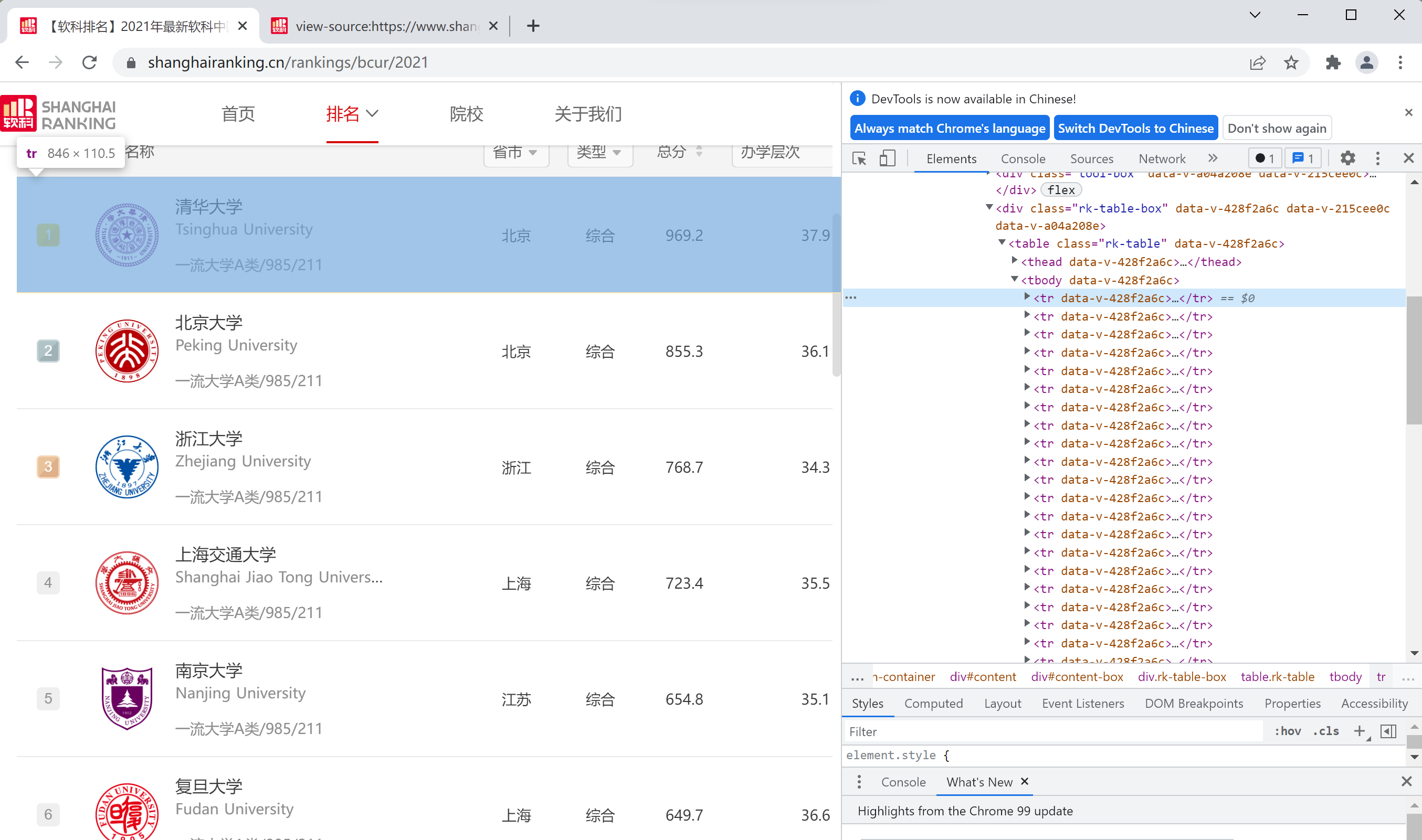
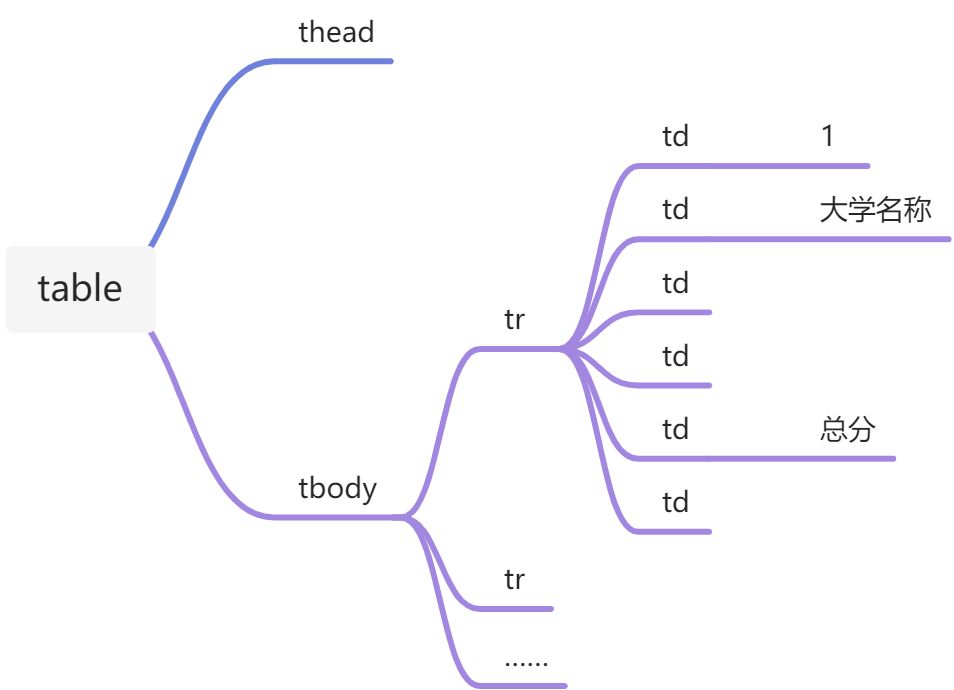
- 找到tbody的子节点tr
- 找到tr的第1、2、5个子节点提取信息
小结
.prettify() 使标签树美观输出,使内容易于阅读
.find(‘tbody’) 找到tbody
.children 向下找到子节点
.string 提取标签中的字.符串内容
.replace(“ “,””) 数据清洗,去除空格
.strip(“\n”) 数据清洗,去除换行符3. 代码改造
```pythonCrawUnivRankingB改造.py
import requests from bs4 import BeautifulSoup import bs4
def getHTMLText(url): try: r = requests.get(url, timeout=30) #获取html信息 r.raise_for_status() #获取异常信息 r.encoding = r.apparent_encoding #编码 return r.text #返回text except: return “”
def fillUnivList(ulist, html): soup = BeautifulSoup(html, “html.parser”) #解析html页面 for tr in soup.find(‘tbody’).children: if isinstance(tr, bs4.element.Tag):
#print(tr.prettify())tds = tr('td')ulist1 = tds[0].string.replace(" ","").strip("\n")ulist2 = tds[1]('a')[0].string.replace(" ","").strip("\n")ulist3 = tds[4].string.replace(" ","").strip("\n")print(ulist1)print(ulist2)print(ulist3)print('\n')ulist.append([ulist1, ulist2, ulist3])
def printUnivList(ulist, num): tplt = “{0:^10}\t{1:{3}^10}\t{2:^10}” print(tplt.format(“排名”,”学校名称”,”总分”,chr(12288))) for i in range(num): u = ulist[i] print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main(): uinfo = [] url = ‘https://www.shanghairanking.cn/rankings/bcur/2021‘ html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo, 20) # 20 univs
main()
<a name="fw8o6"></a>## 主要内容:技术路线:requests - bs41. bs4库的安装1. html中表格内容的获取2. 中文对齐问题的解决2. 空格和换行符的去除<a name="mrPEB"></a># 补充内容<a name="cAMLk"></a>## bs4库的安装bs4库能对html、xml格式(标签类)进行解析,并提取相关的信息。<br />官网:https://www.crummy.com/software/BeautifulSoup/<br /><a name="q8iob"></a>## 安装命令```python#pip安装pip install beautifulsoup4#换国内源pip安装pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ beautifulsoup4
引入bs4库
import bs4 #安装时为beautifulsoup4,但引用的时候是简写的bs4from bs4 import BeautifulSoup #引入Beautifulsoup类,注意B和S需要大写
下行遍历

#遍历儿子节点for child in soup.body.children:print(child)#遍历子孙节点for child in soup.body.children:print(child)
上行遍历

平等遍历

prettify方法
<tag>.prettify()soup.prettify()

若有收获,就点个赞吧
0 人点赞
