1.访问及关闭网页、浏览器窗口最大化
from selenium import webdriverurl= r"" #目标网址browser = webdriver.Chrome()browser.maximize_window() #最大化浏览器browser.get(url) #访问网址browser.quit() #关闭浏览器
2. 定位网页元素
首先得知道如何查找元素。
网页是由一个个元素构成的,搜索框和“百度一下”按钮都是网页上的元素,而要对元素进行操作,得先找到它们。
Selenium 提供了 8 种定位单个节点的方法,如下所示:
| 方法 | 说明 |
|---|---|
| find_element_by_id() | 通过 id 属性值定位 |
| find_element_by_name() | 通过 name 属性值定位 |
| find_element_by_class_name() | 通过 class 属性值定位 |
| find_element_by_tag_name() | 通过 tag 标签名定位 |
| find_element_by_link_text() | 通过标签内文本定位,即精准定位。 |
| find_element_by_partial_link_text() | 通过标签内部分文本定位,即模糊定位。 |
| find_element_by_xpath() | 通过 xpath 表达式定位 |
| find_element_by_css_selector() | 通过 css 选择器定位 |
2.1 XPath法
可以把XPath理解为这个元素的名字或id。
browser.find_element_by_xpath('XPath内容')
按F12键打开开发者工具,利用“选择”按钮选中搜索框,然后在搜索框对应的那一行源代码上右击,在弹出的快捷菜单中选择“Copy>Copy XPath”命令,把复制的内容(搜索框的XPath内容是“//*[@id=”kw”]”)粘贴到上面的代码里替换“XPath内容”即可。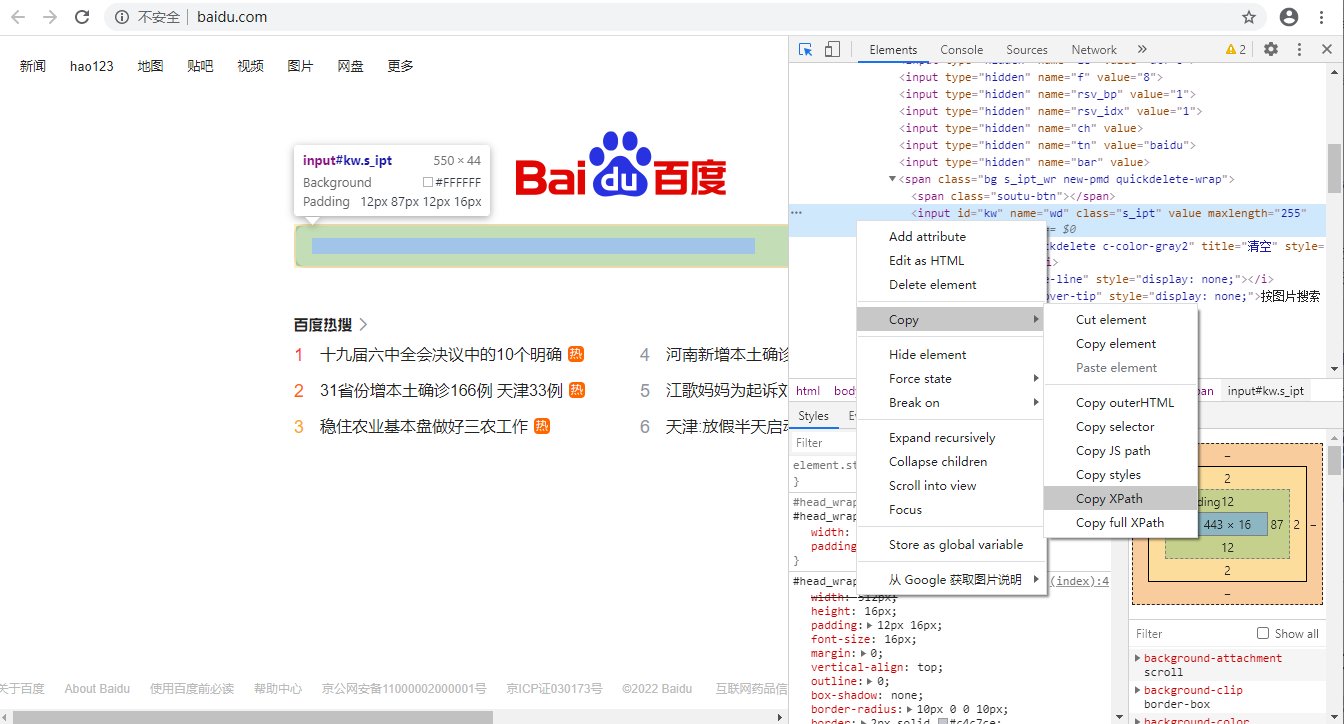
from selenium import webdriverurl= r"http://www.baidu.com/" #目标网址key_word = "python"browser = webdriver.Chrome()browser.maximize_window() #最大化浏览器browser.get(url) #访问网址browser.find_element_by_xpath('//*[@id="kw"]').clear() #清空搜索框内容browser.find_element_by_xpath('//*[@id="kw"]').send_keys(key_word) #搜索框键入内容browser.find_element_by_xpath('//*[@id="su"]').click()#browser.quit() #关闭浏览器
2.2 css_selector法
css_selector法与XPath法的使用方法类似,只需要把代码中的by_xpath换成by_css_selector即可。括号里css_selector内容的获取方法也和XPath类似,右击源代码后选择执行“Copy selector”命令即可
两种方法在本质上是一样的,有时用其中一种方法会失效,换成另一种方法就有效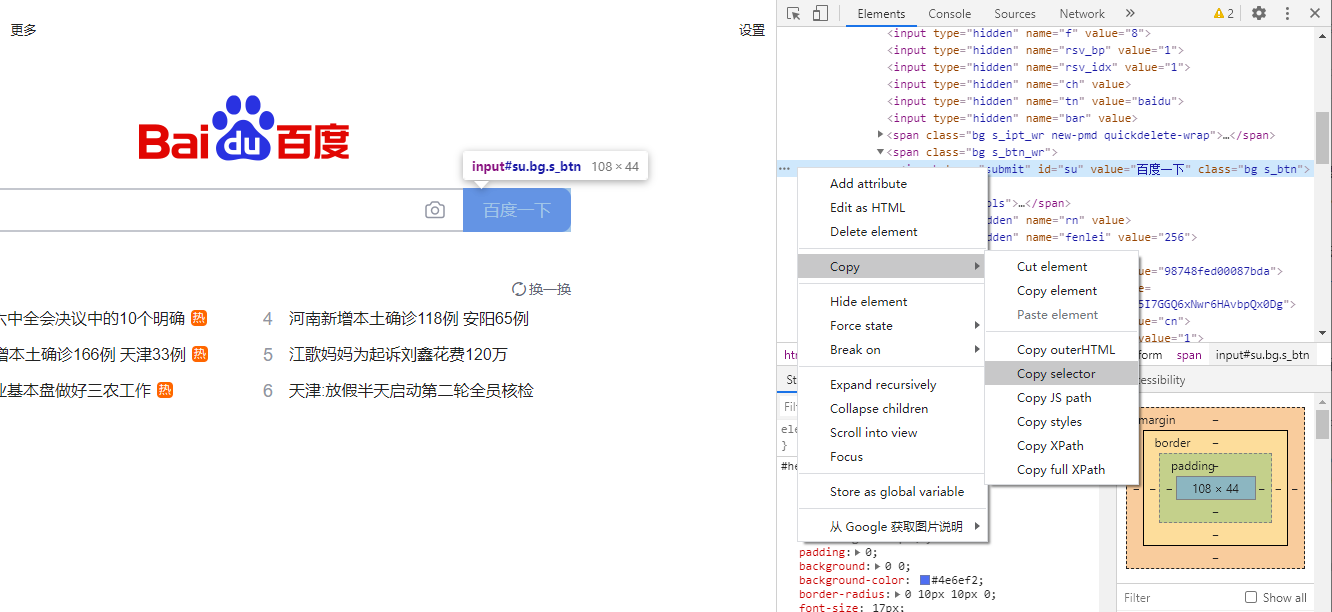
from selenium import webdriverurl= r"http://www.baidu.com/" #目标网址key_word = "python"browser = webdriver.Chrome()#browser.maximize_window() #最大化浏览器browser.get(url) #访问网址browser.find_element_by_css_selector('#kw').clear() #清空搜索框内容browser.find_element_by_css_selector('#kw').send_keys(key_word) #搜索框键入内容browser.find_element_by_css_selector('#su').click()#browser.quit() #关闭浏览器
3. 获取网页源代码
data = browser.page_soure #获取网页源代码print(data)
4. 无界面浏览器设置
from selenium import webdriverchrome_options = webdriver.ChromeOptions()chrome_options.add_argument('--headless')browser = webdriver.Chrome(options = chrome_options)
5. 全代码
from selenium import webdriverimport timeurl= r"http://www.baidu.com/" #目标网址key_word = "python"chrome_options = webdriver.ChromeOptions() #隐藏浏览器界面chrome_options.add_argument('--headless') #隐藏浏览器界面browser = webdriver.Chrome(options = chrome_options) #隐藏浏览器界面#browser = webdriver.Chrome() #显示浏览器界面#browser.maximize_window() #最大化浏览器browser.get(url) #访问网址browser.find_element_by_xpath('//*[@id="kw"]').clear() #清空搜索框内容browser.find_element_by_xpath('//*[@id="kw"]').send_keys(key_word) #搜索框键入内容browser.find_element_by_xpath('//*[@id="su"]').click()time.sleep(3) #等待网页加载data = browser.page_source #获取网页源代码print(data)#browser.quit() #关闭浏览器

若有收获,就点个赞吧
0 人点赞
