点击查看【bilibili】
本实例涉及的技术:Requests & BeautifulSoup
内容概要:
1 功能需求
2 目标网站的 robots协议
3 目标网站分析
4 程度结构的设计
5 代码实现
6 本实例全代码
1 功能需求
获取新闻页面的信息,提取其中的时间、标题、网址信息打印输出信息
2 目标网站的 robots协议
在网站的根目录下查看网站的 robots协议<br /> 浏览器地址栏中输入:[https://www.phei.com.cn/robots.txt](https://www.phei.com.cn/robots.txt)<br /> 结果如下图所示,网站没有robots.txt,对网络爬虫没有限制 <br /><br />本实例仅在技术的学习和探讨<br />网站虽然没有限制,但也请不要无限制爬取。
3 目标网站分析
查看网页源代码:右键>查看网页源代码,可以看到相关信息都保存在html页面中。 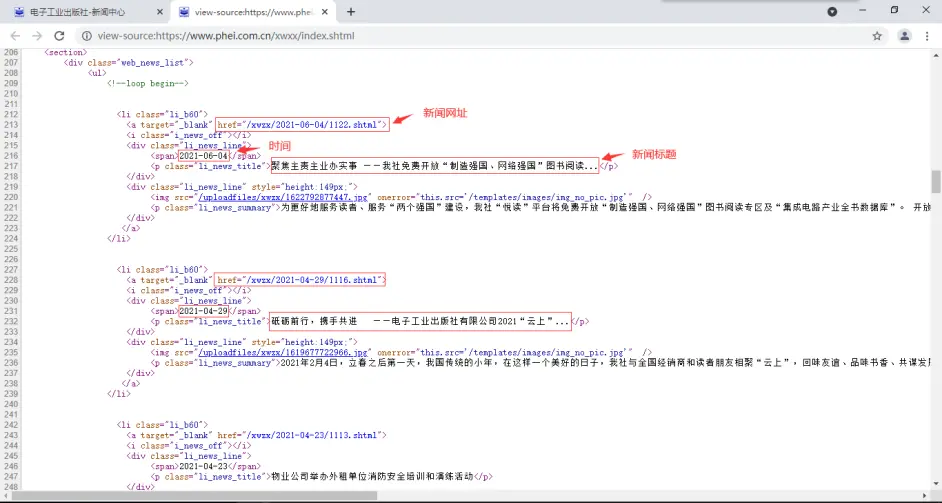
新闻网页的信息 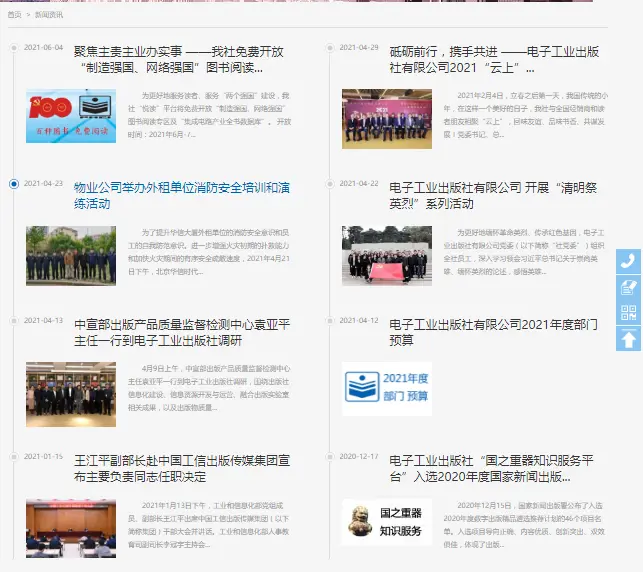
新闻网页的跳转方式
4 程度结构的设计
技术路线:Requests-BeautifulSoup
步骤一:Requests 自动网络url请求提交,循环获得html页面
步骤二:BeautifulSoup解析每个HTML页面,提取目标信息
步骤三:打印输出信息到屏幕
5 代码实现
5.1 Requests获得html页面
使用Requests通用框架,提交url请求,获取网页内容,并使用try-except 异常处理框架,保证程序稳定。
#获取网页源代码def getHTMLText(url):try:headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"}r = requests.get(url, timeout=30, headers=headers,allow_redirects=False)print(r.status_code)r.raise_for_status() # 如果状态不是200,引发HTTPError异常r.encoding = r.apparent_encoding#print(r.text[1000:2000])return r.textexcept:print("网页访问异常!")
5.2 构造所有页面的url地址
分析新闻页面地址可知,其规律为:首页地址的后缀前面加上“_数字”即为其他页面地址,且数字为倒序。
https://www.phei.com.cn/xwxx/index.shtml #首页地址https://www.phei.com.cn/xwxx/index_54.shtml #第1页地址https://www.phei.com.cn/xwxx/index_53.shtml #第2页地址……https://www.phei.com.cn/xwxx/index_1.shtml #最后1页地址
定义get_urls()函数,构造所有分页url地址:
def get_urls(pages):urls = ['https://www.phei.com.cn/xwxx/index.shtml']for i in range(1,pages):page = 55-iurl = "https://www.phei.com.cn/xwxx/index_{}.shtml".format(page)urls.append(url)#print(urls)return urls
5.3 BeautifulSoup解析html页面提取信息
网页源代码显示,新闻信息都存储在

因此可以使用bs4的”.find_all()”方法可以定位到信息位置:
def parsePage(html):soup = BeautifulSoup(html, 'html.parser')#for tag in soup.find_all(True):#print(tag.name)p = soup.find_all('li','li_b60')#print(p)print(len(p))for i in range(len(p)):print(i)text = p[i]#print(text.prettify()) #美观地打印标签树
同样利用find_all()对定位到的信息进一步准确地提取:
#bs4提取信息def parsePage(html):soup = BeautifulSoup(html, 'html.parser')#for tag in soup.find_all(True):#print(tag.name)p = soup.find_all('li','li_b60')#print(p)print(len(p))for i in range(len(p)):print(i)text = p[i]#print(text.prettify()) #美观地打印标签树#获得新闻时间time = text.find_all('span')print(time)#获得新闻标题title = text.find_all('p','li_news_title')print(title)#获得新闻网址for link in text.find_all('a'):link_part = link.get('href')print(link_part)
结果如下,可以获得精确的信息。
但也存在相关问题:
问题1:信息被一对<>包裹
问题2:获得的网址不完全 
针对上述2个问题对代码进行优化:
def parsePage(html):soup = BeautifulSoup(html, 'html.parser')#for tag in soup.find_all(True):#print(tag.name)p = soup.find_all('li','li_b60')#print(p)print(len(p))for i in range(len(p)):print(i)text = p[i]#print(text.prettify()) #美观地打印标签树#获得新闻时间time = text.find_all('span')time_bs = BeautifulSoup(str(time), 'html.parser')time_text = time_bs.get_text()print(time_text)#获得新闻标题title = text.find_all('p','li_news_title')title_bs = BeautifulSoup(str(title), 'html.parser')title_text = title_bs.get_text()print(title_text)#获得新闻网址for link in text.find_all('a'):link_part = link.get('href')html_url = 'https://www.phei.com.cn'+str(link_part)print(html_url) 作者:穿云蟒 https://www.bilibili.com/read/cv11902002 出处:bilibili
优化后结果: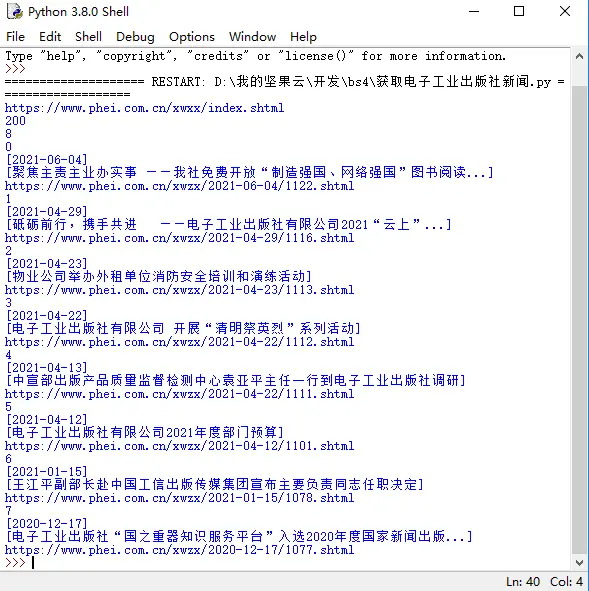
至此,本程序可以准确提取单一页面的时间、标题、网址信息了。
下面进一步进行多页面的信息提取
5.4 构造循环获取html及处理主程序
pages = 2 #输入页面数量urls = get_urls(pages) #调用get_urls()函数构造url地址for url in urls: #循环获得页面并进行处理print(url)html = getHTMLText(url) #获得网页源代码parsePage(html) #解析提取网页信息
全代码:
import requestsfrom bs4 import BeautifulSoup#获取网面源代码def getHTMLText(url):try:headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"}r = requests.get(url, timeout=30, headers=headers,allow_redirects=False)print(r.status_code)r.raise_for_status() # 如果状态不是200,引发HTTPError异常r.encoding = r.apparent_encoding#print(r.text[1000:2000])return r.textexcept:print("网页访问异常!")#bs4提取信息def parsePage(html):soup = BeautifulSoup(html, 'html.parser')#for tag in soup.find_all(True):#print(tag.name)p = soup.find_all('li','li_b60')#print(p)print(len(p))for i in range(len(p)):print(i)text = p[i]#print(text.prettify()) #美观地打印标签树#获得新闻时间time = text.find_all('span')time_bs = BeautifulSoup(str(time), 'html.parser')time_text = time_bs.get_text()print(time_text)#获得新闻标题title = text.find_all('p','li_news_title')title_bs = BeautifulSoup(str(title), 'html.parser')title_text = title_bs.get_text()print(title_text)#获得新闻网址for link in text.find_all('a'):link_part = link.get('href')html_url = 'https://www.phei.com.cn'+str(link_part)print(html_url)def get_urls(pages):urls = ['https://www.phei.com.cn/xwxx/index.shtml']for i in range(1,pages):page = 55-iurl = "https://www.phei.com.cn/xwxx/index_{}.shtml".format(page)urls.append(url)#print(urls)return urlspages = 3urls = get_urls(pages)for url in urls:print(url)html = getHTMLText(url) #获得网页源代码parsePage(html) #解析提取网页信息 作者:穿云蟒 https://www.bilibili.com/read/cv11902002 出处:bilibili

若有收获,就点个赞吧
0 人点赞
