介绍
HashSet和LinkedHashSet都是不可重复的元素集合,HashSet通过HashMap实现,LinkedHashSet通过LinkedHashMap来实现,所以LinkedHashSet迭代是有顺序的,和add时的顺序一致,HashSet迭代是无序的。
类图如下: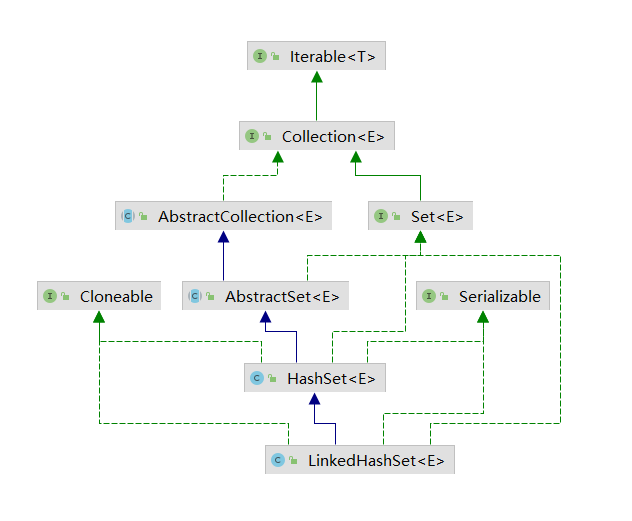
HashSet
底层利用HashMap保存所有的元素,元素都保存在map的key上,因为map的key都是不重复的,所以间接实现了去重的效果,map的value都固定是一个静态的Object对象,称之为PRESENT。
public class HashSet<E>extends AbstractSet<E>implements Set<E>, Cloneable, java.io.Serializable{static final long serialVersionUID = -5024744406713321676L;// 保存所有的元素private transient HashMap<E,Object> map;// Dummy value to associate with an Object in the backing Map// 每个key的value都是它private static final Object PRESENT = new Object();// 默认初始化public HashSet() {map = new HashMap<>();}// 集合转hashsetpublic HashSet(Collection<? extends E> c) {// 默认根据负载因子0.75计算hashmap的容量再+1,不足16默认16map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));addAll(c);}// 自定义初始化容量和负载因子public HashSet(int initialCapacity, float loadFactor) {map = new HashMap<>(initialCapacity, loadFactor);}// 自定义初始化容量public HashSet(int initialCapacity) {map = new HashMap<>(initialCapacity);}// dummy实际上没有用到,可以看到没有访问修饰符,这个构造方法是提供给子类LinkedHashSet使用// dummy的作用是为了和上面的构造函数区别开来HashSet(int initialCapacity, float loadFactor, boolean dummy) {map = new LinkedHashMap<>(initialCapacity, loadFactor);}public Iterator<E> iterator() {return map.keySet().iterator();}public int size() {return map.size();}public boolean isEmpty() {return map.isEmpty();}public boolean contains(Object o) {return map.containsKey(o);}// 添加元素,key为e,value固定为PRESENTpublic boolean add(E e) {return map.put(e, PRESENT)==null;}// 移除元素,元素的value是PRESENTpublic boolean remove(Object o) {return map.remove(o)==PRESENT;}public void clear() {map.clear();}@SuppressWarnings("unchecked")public Object clone() {try {HashSet<E> newSet = (HashSet<E>) super.clone();newSet.map = (HashMap<E, Object>) map.clone();return newSet;} catch (CloneNotSupportedException e) {throw new InternalError(e);}}private void writeObject(java.io.ObjectOutputStream s)throws java.io.IOException {// Write out any hidden serialization magics.defaultWriteObject();// Write out HashMap capacity and load factors.writeInt(map.capacity());s.writeFloat(map.loadFactor());// Write out sizes.writeInt(map.size());// Write out all elements in the proper order.for (E e : map.keySet())s.writeObject(e);}private void readObject(java.io.ObjectInputStream s)throws java.io.IOException, ClassNotFoundException {// Read in any hidden serialization magics.defaultReadObject();// Read capacity and verify non-negative.int capacity = s.readInt();if (capacity < 0) {throw new InvalidObjectException("Illegal capacity: " +capacity);}// Read load factor and verify positive and non NaN.float loadFactor = s.readFloat();if (loadFactor <= 0 || Float.isNaN(loadFactor)) {throw new InvalidObjectException("Illegal load factor: " +loadFactor);}// Read size and verify non-negative.int size = s.readInt();if (size < 0) {throw new InvalidObjectException("Illegal size: " +size);}// Set the capacity according to the size and load factor ensuring that// the HashMap is at least 25% full but clamping to maximum capacity.capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),HashMap.MAXIMUM_CAPACITY);// Create backing HashMapmap = (((HashSet<?>)this) instanceof LinkedHashSet ?new LinkedHashMap<E,Object>(capacity, loadFactor) :new HashMap<E,Object>(capacity, loadFactor));// Read in all elements in the proper order.for (int i=0; i<size; i++) {@SuppressWarnings("unchecked")E e = (E) s.readObject();map.put(e, PRESENT);}}public Spliterator<E> spliterator() {return new HashMap.KeySpliterator<E,Object>(map, 0, -1, 0, 0);}}
LinkedHashSet
LinkedHashSet完美利用了HashSet的方法,只需要构造函数的不同,构造出底层是LinkedHashMap就行,
因为LinkedHashMap是HashMap的子类,LinkedHashMap的节点之间是有顺序的,所以LinkedHashSet的节点也拥有了顺序。
public class LinkedHashSet<E>extends HashSet<E>implements Set<E>, Cloneable, java.io.Serializable {private static final long serialVersionUID = -2851667679971038690L;// 调用HashSet的构造初始化,实际上是new LinkedHashMap(initialCapacity, loadFactor);public LinkedHashSet(int initialCapacity, float loadFactor) {super(initialCapacity, loadFactor, true);}// 调用HashSet的构造初始化,默认负载因子0.75public LinkedHashSet(int initialCapacity) {super(initialCapacity, .75f, true);}// 默认容量16,负载因子0.75public LinkedHashSet() {super(16, .75f, true);}// 初始化一个集合,初始容量是2倍size和11取其中的大值。public LinkedHashSet(Collection<? extends E> c) {super(Math.max(2*c.size(), 11), .75f, true);addAll(c);}@Overridepublic Spliterator<E> spliterator() {return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);}}

若有收获,就点个赞吧
0 人点赞
