- SQL是什么
- 1. 数据库基本操作
- 2. DML和DQL
- 1.3 插入数据-单条DML insert into
- 1.4 插入数据-多条 insert into
- 1.5 更新/删除数据 update/delete
- 1.6 sql 通配符
- 1.7 sql的运算符
- 1.8 sql操作符
likebetween数字/日期and 数字/日期闭区间is null - 1.9 从已有表中选择数据创建新表
- 2 添加/删除约束的sql语句
- 3 简单子查询
- 4 IN子查询
- 5 distinct 不同值
- 6 join详解
- 7 union
- 8 describe查看表结构
- 9 create index 在表中创建索引
- 10 drop 与 truncate table
- 11 VIEW 视图
- 12 AND 和 OR
- 13 ORDER BY
- 14 like 用于在where子句中搜索列中的指定模式
- 15 IN 允许我们在where子句中规定多个值
- 16 BETWEEN 在where中使用,选取两个值之间的数据范围
- 3. SQL函数
SQL是什么
对数据库进行查询和修改操作的语言叫做SQL ( Structured Query Language, 结构化查询语言) 。
SQL是一种数据库查询和程序设计语言,用于存取树以及查询、更新和管理关系数据库系统。
SQL主要包含以下四部分:
- 数据定义语言(Data Definition Language, DDL)
用来创建或删除数据库以及表对象,主要有:
DROP删除数据库和表等对象CREATE创建数据库和表等对象ALTER修改数据库和表等对象
- 数据操作语言(Data Manipulation Language, DML)
用来变更表中的记录,著有有
SELECT查询表中的数据INSERT向表中插入新数据UPDATE更新表中数据DELETE删除表中的数据
- 数据查询语言(Data Query Language, DQL)
查询表中的记录,主要包含SELECT指令- 数据控制语言(Data Control Language, DCL)
确认或取消对数据库中的数据进行的变更。还可以对数据库中的用户设定权限,主要包含:
GRANT赋予用户操作权限REVOKE取消用户的操作权限COMMIT确认对数据库中的数据进行变更ROLLBACK取消对数据库中的数据进行的变更
1. 数据库基本操作
一、数据库的数据类型

数值类型
MySQL支持所有标准SQL数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
BIT数据类型保存位字段值,并且支持MyISAM、MEMORY、InnoDB和BDB表。
作为SQL标准的扩展,MySQL也支持整数类型TINYINT、MEDIUMINT和BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
UNSIGNED 表示为无符号
ZEROFILL 位数不足用0 填充。该属性默认添加UNSIGNED属性
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
TINYINT |
1 byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
**INT或INTEGER** |
4 bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
DOUBLE |
8 bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个”零”值,当指定不合法的MySQL不能表示的值时使用”零”值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | 大小 | 用途 |
|---|---|---|
CHAR |
0-255 bytes | 定长字符串 |
VARCHAR |
0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
TEXT |
0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
注意:char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
二、表的创建和删除
三、创建表的完整性约束

完全性约束是为了保证数据库中数据的完整性

主键primary key
CREATE TABLE test('idNO' INT(4) PRIMARY KEY,...);
注释comment
CREATE TABLE test(`id` INT(11) UNSIGNED COMMENT '编号')COMMENT='测试表';
设置字符集编码
CREATE TABLE [IF NOT EXISTS] 表明(...)CHARSET= 字符集名;charset=utf8mb4
新建表
show databases;use firstdb;create table if not exists `Student`(`StuId` int primary key auto_increment comment '学号',`StuName` varchar(20) not null comment '姓名',`LoginPwd` varchar(20) not null comment '登录密码',`Sex` char(6) not null default('female') comment '性别',`GradeId` int comment '班级号 对应班级表外键',`Mobile` varchar(11) comment '手机号',`Address` varchar(255) default('未知') comment '地址',`Email` varchar(50),`IdentityCard` char(18) unique comment '身份证号 唯一',`CreateDate` datetime default(now()) comment '创建时间')engine=InnoDB comment 'most byte4 utf8的超集 完全兼容utf8 能够使用4个字节存储更多的字符';# engine MyISAM 不支持事务,空间小 主要以查询访问为主;# InnoDB
查看表定义 describer tablename desc
describe student ;

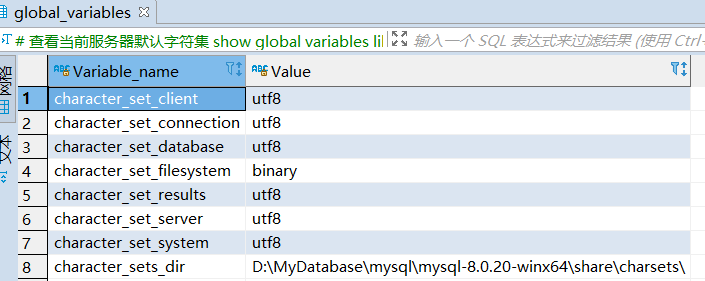
查看当前服务器默认字符集
# 查看当前服务器默认字符集show global variables like '%character_set%';
插入insert 查询 select
自增主键insert值设为default
insert into student values(default, '周杰伦','qwer1234','male',101,'13888888888','台北市','jiachou@gmail.com','00000000000000001',default);select * from student ;

删除表 drop table tablename
修改表 alter table
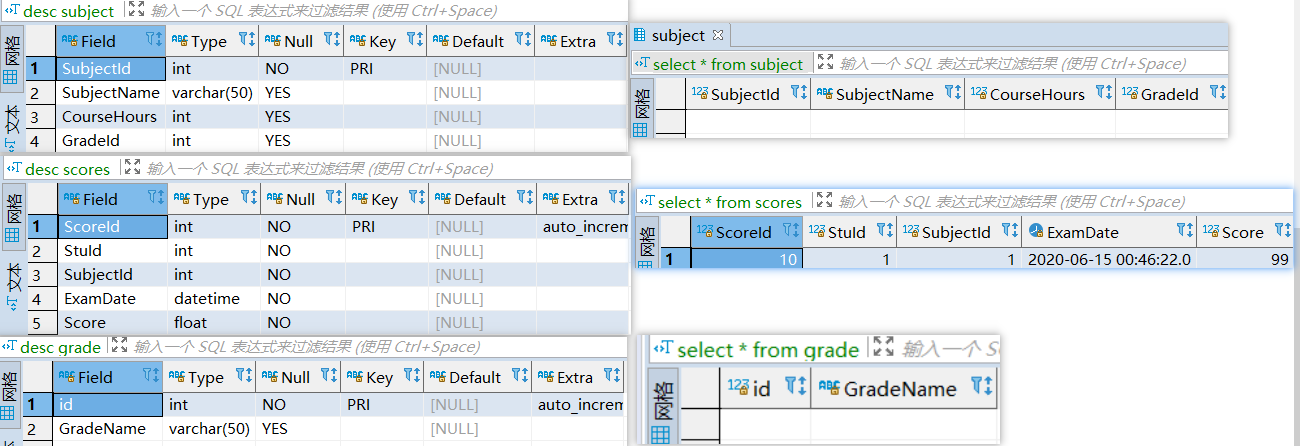
create table Subject(`SubjectId` int(4) comment '课程编号',`SubjectName` varchar(50) comment '课程名称',`CourseHours` int(4) comment '学时',`GradeId` int comment '年级编号');create table Grade(`id` int primary key auto_increment comment '年纪编号 主键 自增1',`GradeName` varchar(50) comment '年级名称');create table Score(`ScoreId` int primary key auto_increment comment '自己创建的主键:自增的成绩Id',`StuId` int not null comment '学号',`SubjectId` int(4) not null comment '课程编号',`ExamDate` datetime not null comment '考试日期',`Score` float(4) not null comment '考试成绩');# 修改score表中的自增列从10开始alter table `Score` auto_increment=10;insert into `Score` values(default, 1,1,now(),99);select * from score ;# 修改表名 [to] 可选alter table score rename to `Scores`;# 增加字段alter table grade add `NickName` varchar(20) default('年级别称');show tables;# 修改字段属性alter table grade change `NickName` `NewNick` varchar(50) default('新别称');desc grade;# 删除字段alter table grade drop `NewNick`;# 单独为表增加主键约束 可以单独为主键约束起一个名字alter table subject add constraint `pk_subject` primary key subject(`SubjectId`);desc subject ;# 添加组合主键约束alter table scores add constraint `pk_scores` primary key `scores`(`StuId`,`SubjectId`,`ExamDate`);# 为scores添加外键Stuid 别名 `fk_student_score`alter table scores add constraint `fk_student_score` foreign key(`StuId`) references `Student`(`StuId`);
mysql系统帮助指令 help
help contents;help `data types`;help `AUTO_INCREMENT`;
| 帮助分类 | 说明 |
|---|---|
| Account Management | 账户管理相关,创建、删除用户以及授权 |
| Administration | 数据库管理 set …; show …; kill ; reset ; shutdown; … |
| Data Definition | 数据定义 如创建、修改数据库 修改表结构 删除表 删除索引等 |
| Data Manipulation | 数据操作 插入数据 导入数据 查询数据 |
| Data Types | 支持的数据类型 如 auto_increment |
| Functions | 函数相关 |
2. DML和DQL
1.数据查询语言(DQL: Data Query Language)数据检索语句,用于从表中获取数据。通常最常用的为保留字SELECT,并且常与FROM子句、WHERE子句组成查询SQL查询语句。
2.数据操纵语言(DML:Data Manipulation Language)主要用来对数据库的数据进行一些操作,常用的就是INSERT、UPDATE、DELETE。 查询和更新指令构成了 SQL 的 DML 部分:
- SELECT - 从数据库表中获取数据
- UPDATE - 更新数据库表中的数据
- DELETE - 从数据库表中删除数据
- INSERT INTO - 向数据库表中插入数据
- 数据定义语言(DDL:Data Define Language)使我们可以创建或删除表,也可以定义索引键,规定表之间的连接,以及施加表的约束
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
1 使用sql语句修改删除表
*1.1 修改查看mysql8中的存储引擎
存储引擎是出来不同类型sql操作组件
InnoDB是默认的 最通用的存储引擎 支持事务transaction
show engines; # 查看所有支持引擎show variables like '%storage_engine%';
# 修改表的存储引擎alter table test engine=MyISAM;# 查看修改后的引擎select * from information_schema.TABLES where TABLE_SCHEMA='firstdb' and TABLE_NAME='test';

1.2 事务(Transaction)是并发控制的基本单位。
所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转账工作:从一个账号扣款并使另一个账号增款,这两个操作要么都执行,要么都不执行,在关系数据库中,一个事务可以是一条SQL语句、一组SQL语句或整个程序。 。所以,应该把它们看成一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
事务和程序的关系:事务和程序是两个概念。一般地讲,一个程序中包含多个事务。
针对上面的描述可以看出,事务的提出主要是为了解决并发情况下保持数据一致性的问题。
事务的语句
在关系数据库中,一个事务可以是一条SQL语句、一组SQL语句或整个程序。
开始事务:BEGIN TRANSACTION(事务)
提交事务:COMMIT TRANSACTION(事务)
回滚事务:ROLLBACK TRANSACTION(事务)
事务的4个属性
- Atomic(原子性):事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要么全部成功,要么全部失败(减款,增款必须一起完成)。
- Consistency(一致性):只有合法的数据可以被写入数据库,否则事务应该将其回滚到最初状态。事务的运行并不改变数据的一致性.例如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随之改变。
- Isolation(隔离性):事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正确性和完整性。同时,并行事务的修改必须与其他并行事务的修改相互独立。
- Durability(持久性):事务完成之后,它对于 系统的影响是永久的,该修改即使出现系统故障也将一直保留,真实的修改了数据库.
1.3 插入数据-单条DML insert into
# 向表中插入单条数据INSERT INTO firstdb.student(StuName, LoginPwd, Sex, GradeId, Mobile, Address, Email, IdentityCard, CreateDate)VALUES('皮卡丘', 'qwer', 'male', 2, '15555153250', '真新镇', 'pikaqiu@gmail.com', '0002', now());
1.4 插入数据-多条 insert into
# 向表中插入多条数据insert into `firstdb`.`student` values(default,'皮卡丘', 'qwer', 'male', 2, '15555153250', '真新镇', 'pikaqiu@gmail.com', '0002', now()), (default,'杰尼龟', 'qwer', 'male', 3, '15555153250', '正义联盟', 'jienigui@gmail.com', '0001132', now()), (default,'菊草叶', 'qwer', default, 4, '15555153250', '紫苑镇', 'jucaoye@gmail.com', '000432', now()), (default,'火球鼠', 'qwer', 'male', 1, '15555153250', '黄金市', 'huoqiushu@gmail.com', '00023112', now());
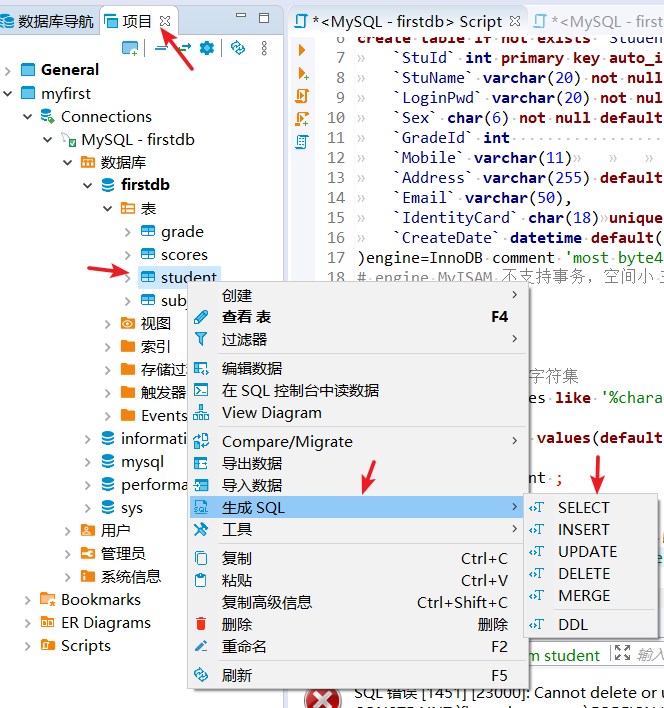
快速生成sql语句
1.5 更新/删除数据 update/delete
更新语法
UPDATE TABLENAME
SET 字段1=值1, 字段2=值2, 字段3=值3,...,
[WHERE CONDITION]
update `student` set StuId=66 where StuName='皮卡丘';update `student` set StuName='肯泰罗' where StuName='火球鼠';update student set sex='female',Address='卡洛斯联盟' where StuName='杰尼龟';
删除语法
DELETE FROM TABLENAME [WHERE CONDITION]
# 不加条件删除整个表
# 删除姓名以叶结尾的至少两个字符的对象delete from student where StuName like '%_叶';
1.6 sql 通配符
| 通配符 | 描述 |
|---|---|
| % | 替代一个或多个字符 |
| _ | 仅替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
| [^charlist]或者[!charlist] | 不在字符列中的任何 |
1.7 sql的运算符
| 运算符 | 描述 | 运算符 | 描述 |
|---|---|---|---|
| = | 等于 | not | 逻辑非 |
| <> or != | 不等于 | and | 逻辑与 |
| > or >= | 大于等于 | or | 逻辑或 |
| < or <= | 小于等于 |
1.8 sql操作符 like between数字/日期and 数字/日期 闭区间 is null
... where StuName like '张%' or StuName like `张_`; # 匹配张后面任意个字符or张后面某个字符... where `GradeId` between 2 and 3; # [between,and]闭区间... where Email is null or is not null; # is null 不等于 = ''
1.9 从已有表中选择数据创建新表
# 创建一个新表 单独保存学生地址drop table if exists AddressBook;create table AddressBook(select `StuName` as `学生姓名`, `Address` as '家庭地址' from student);
学生姓名 家庭地址 杰尼龟 卡洛斯联盟 肯泰罗 黄金市 皮卡丘 真新镇 百变怪 真新镇
2 添加/删除约束的sql语句
约束用于限制加入表的数据的类型。
可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后也可以(通过 ALTER TABLE 语句)。
2.1 NOT NULL 约束
not null 约束强制列不接受NULL值,字段始终包含值,如果不向字段添加值就无法插入或更新记录。
2.2 UNIQUE 约束
约束唯一标识数据库表中的每条记录。UNIQUE和PRIMARY KEY约束均为列或者列集合提供了唯一性的保证。
PRIMARY KEY拥有自动定义的UNIQUE约束。
每个表可以有多个UNIQUE约束,但只可以有一个PRIMARY KEY约束。
创建表的时候创建UNIQUE约束
create table xx{...`id` int nut null,unique (id)}
如果需要命名UNIQUE约束以及为多个列定义UNIQUE约束
create table xx{...constraint <alias> unique (id,address) # id 和 address列组合主键 alias}
当表已经创建时新增UNIQUE约束
alter table <tbname> add unique (id);alter table <tbname> add <alias> unique (id,address);
撤销UNIQUE约束
alter table <tbname> drop index <alias>;alter table <tbname> drop constraint <alias>;
2.3 PRIMARY KEY主键
约束唯一标识数据库表中的每条记录,主键必须包含唯一的值,主键列不能有NULL值,每个表都应该有且仅有一个主键。
alter table <tbname> add constraint <alias> primary key ();alter table <tbname> drop primary key;
2.4 FOREIGN KEY 外键
外键约束用于预防破坏表之间连接的动作。
也能防止非法数据插入外键列,因为他必须是它指向的那个表中的值之一。
一个表中的FOREIGN KEY指向另一个表中的PRIMARY KEY。
create table xx{...FOREIGIN KEY (age) REFERENCES tbname(id)};create table xx{age int foregin key references tbname(id)};
新增FOREIGN KEY
alter table xx add foreig key (??) references yy(??);alter table xx add constraint alias forign key (??) references yy(??);
撤销外键
alter table xx drop foreign key alias;alter constraint alias;
2.5 CHECK约束
限定列中的值的范围
create table xx{id int not null,...check (id > 0),...age int not null check (age > 0),...};
新增约束
alter table xx add constraint alias check (aa>0 and bb >20);alter table xx add check (aa>0);
撤销约束
alter table xx drop check alias;alter table xx drop constraint alias;
2.6 DEFAULT约束
列有默认值
撤销默认值
alter table xx alter column_name drop default;
# 删除外键关系 外键别名alter table scores drop foreign key `fk_student_score`;# 执行之前需要清除主外键关系delete from student ; # 删除指定数据truncate table student ; # 自动清空标识列中的起始数据
3 简单子查询
3.1 简单查询 提取数据显示出来
SELECT 列名|表达式|函数|常量
FROM tablename
[WHERE CONDITION]
[ORDER BY 排序的列名 [ASC OR DESC]]
# 查询地址以镇结尾的数据 以stuid降序输出select *from student where Address like '%_镇' order by StuId desc;# 查询地址不是真新镇的 stuid降序输出select *from student where Address <> '真新镇' order by StuId desc;
StuId StuName LoginPwd Sex GradeId Mobile Address IdentityCard CreateDate 68 百变怪 qwer female 7 15555153250 真新镇 00052 2020-06-15 15:36:47.0 66 皮卡丘 qwer male 2 15555153250 真新镇 pikaqiu@gmail.com 0002 2020-06-15 14:39:49.0
连接列 生成别名 concat() as
select concat(`Address`,`StuName`) as '全名' from student;
全名 | ————| 卡洛斯联盟杰尼龟| 黄金市肯泰罗 | 真新镇皮卡丘 | 真新镇百变怪 |
查询过程
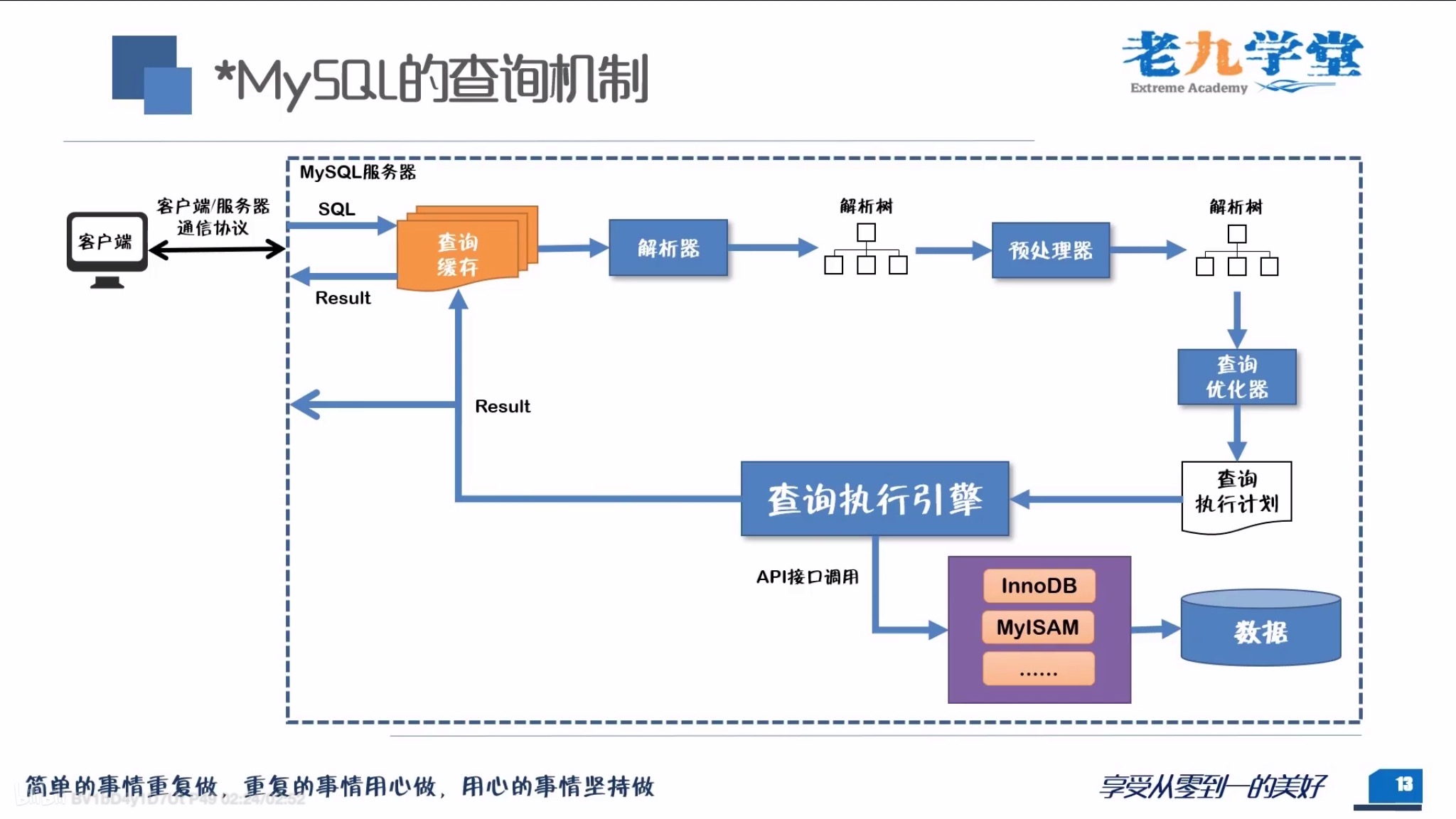
4 IN子查询
LIMIT子句
SELECT <字段名列表>
FROM <表或视图>
[WHERE CONDITION] [GOURP BY <列名> [ASC or DESC]]
[LIMIT [位置偏移量,]行数];
select Stuid,StuName,MObile,Address,BornDatefrom StuInfowhere GradeId=1ORDER BY StuId DESCLIMIT 1; # 显示前1条数据LIMIT 1,1 # 从第2条开始显示前1条
子查询 IN
select * from student s2 where Sex IN (select Sex from student s where StuName='皮卡丘');# 查询和皮卡丘一个性别的所有人员的所有信息
5 distinct 不同值
关键词 DISTINCT 用于返回唯一不同的值。
SELECT DISTINCT 列名称 FROM 表名称
从 Company” 列中仅选取唯一不同的值,我们需要使用 SELECT DISTINCT 语句:
SELECT DISTINCT Company FROM Orders ;
“Orders”表:
| Company | Order Number |
|---|---|
| IBM | 3532 |
| W3School | 2356 |
| Apple | 4698 |
| W3School | 6953 |
| Company |
|---|
| IBM |
| W3School |
| Apple |
6 join详解
join子句主要用于把两个或者多个表的行结合起来,基于这些表之间的共同字段。主要有内连接 inner join,外连接 left join , right join , full join。
两张表 Com和Region
| id | name |
|---|---|
| 1 | |
| 2 | 淘宝 |
| 3 | 微博 |
| 4 |
| id | address |
|---|---|
| 1 | 美国 |
| 5 | 中国 |
| 3 | 中国 |
| 6 | 美国 |
inner join / join 内连接 交集
SELECT column_name(s)FROM table_name1INNER JOIN table_name2ON table_name1.column_name=table_name2.column_name
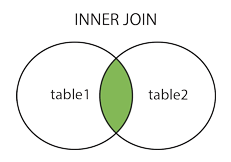
-- 内连接 inner join / join 交集select com.id,com.name,region.addressfrom com join regionon com.id = region.id;
| id | name | address |
|---|---|---|
| 1 | 美国 | |
| 3 | 微博 | 中国 |
left join 外连接 左
— 返回左表的全部行和右表满足on条件的行。如果左表行在右表中没有匹配,
— 那么这一行右表中对应数据用NULL表示。
SELECT column_name(s)FROM table_name1LEFT JOIN table_name2ON table_name1.column_name=table_name2.column_name
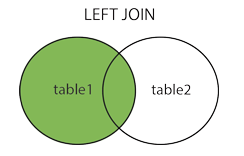
-- 外连接-- left join-- 返回左表的全部行和右表满足on条件的行。如果左表行在右表中没有匹配,-- 那么这一行右表中对应数据用NULL表示。select com.id,com.name,region.addressfrom com left join regionon com.id = region.id;
| id | name | address |
|---|---|---|
| 1 | 美国 | |
| 2 | 淘宝 | null |
| 3 | 微博 | 中国 |
| 4 | null |
right join 外连接右
— 返回右表中全部行和左表满足on条件的行,如果右表的行在左表中没有匹配,
— 左表行用NULL代替。
SELECT column_name(s)FROM table_name1RIGHT JOIN table_name2ON table_name1.column_name=table_name2.column_name
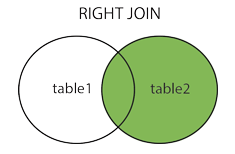
-- right left-- 返回右表中全部行和左表满足on条件的行,如果右表的行在左表中没有匹配,-- 左表行用NULL代替。select *from com right join regionon com.id = region.id;
| id | name | address |
|---|---|---|
| 1 | 美国 | |
| 5 | null | 中国 |
| 3 | 微博 | 中国 |
| 6 | null | 美国 |
full join
— 从左右表返回所有行,如果其中一个表的数据行在另一个表中没有匹配行,
— 返回NULL
SELECT column_name(s)FROM table_name1FULL JOIN table_name2ON table_name1.column_name=table_name2.column_name
-- full join-- 从左右表返回所有行,如果其中一个表的数据行在另一个表中没有匹配行,-- 返回NULLselect com.id,com.name,region.addressfrom com full join regionon com.id = region.id;
| id | name | address |
|---|---|---|
| 1 | 美国 | |
| 2 | 淘宝 | null |
| 3 | 微博 | 中国 |
| 4 | null | |
| 5 | null | 中国 |
| 6 | null | 美国 |
7 union
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。有时候可以替代 where 中的or
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
SELECT column_name(s) FROM table_name1UNIONSELECT column_name(s) FROM table_name2
select name,population,area from worldwhere area>3000000unionselect name,population,area from worldwhere population>25000000等价于select name, population, areafrom worldwhere area > 3000000 or population > 25000000
8 describe查看表结构
describe <tablename>;
desc <tablename>;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(25) | YES | | NULL | |
| deptId | int(11) | YES | | NULL | |
| salary | float | YES | | NULL | |
+--------+-------------+------+-----+---------+-------+
4 rows in set (0.14 sec)
show create table; 以sql语句的形式展示表结构
+---------+------------------------------------------------+
| Table | Create Table |
+---------+------------------------------------------------+
| tb_emp1 | CREATE TABLE `tb_emp1` (
`id` int(11) DEFAULT NULL,
`name` varchar(25) DEFAULT NULL,
`salary` float DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=gb2312 |
+---------+------------------------------------------------+
1 row in set (0.01 sec)
9 create index 在表中创建索引
在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。用户无法看到索引,它们只能用来加速查询。
create index index_name on table_name (column_name);
# 唯一索引意味着两个行不能拥有相同的索引值。
create unique index index_name on table_name (column_name);
# 降序索引某个列的值
CREATE INDEX index_name ON table_name (column_name DESC);
# 索引多个列
CREATE INDEX index_name ON table_name (column_name1, column_name2);
10 drop 与 truncate table
# 只删除表内数据,不删除表(保留表结构)
TRUNCATE TABLE table_name;
# drop 删除整个对象,不保留结构
DROP DATABASE/TABLE xx;
ALTER TABLE table_name DROP INDEX index_name;
11 VIEW 视图
视图是可视化的表。
12 AND 和 OR
and 和 or可以在where子语句中把两个或多个条件结合起来
select * from persons where (firstname='Chg' or Firstname='Xi') and LAstname='Fei';
Id|LastName|FirstName|Age|Address|Country|
--|--------|---------|---|-------|-------|
5|Fei |Chg | |Wuhan |China |
13 ORDER BY
order by 用于根据指定的列对结果集进行排序
order by 默认按照升序对记录进行排序 ASC升 DESC降
select LastName ,age,country, address from persons where FirstName ='Chg'order by Age desc ;
LastName|age|country|address|
--------|---|-------|-------|
Jing | 25|China |Beijing|
Ken | |China |Hefei |
Fei | |China |Wuhan |
select id,LastName ,age,country, address from persons where FirstName !='Chg'order by Age desc ,id asc;
id|LastName|age|country|address |
--|--------|---|-------|--------|
3|Jing | 42|China |Beijing |
2|Bush | 32|USA |New York|
1|Adams | 21|China |Chengdu |
14 like 用于在where子句中搜索列中的指定模式
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
SELECT column_name(s)
FROM table_name
WHERE column_name LIKE pattern
select * from persons where address like 'H%';
Id|LastName|FirstName|Age|Address|Country|
--|--------|---------|---|-------|-------|
4|Ken |Chg | |Hefei |China |
select * from persons where address like '%ng%';
Id|LastName|FirstName|Age|Address|Country|
--|--------|---------|---|-------|-------|
1|Adams |John | 21|Chengdu|China |
3|Jing |Xi | 42|Beijing|China |
6|Jing |Chg | 25|Beijing|China |
15 IN 允许我们在where子句中规定多个值
select column_name(S)
from table_name
where column_name in (value1,value2,...)
# 选取名为ken和jing人
select LastName , FirstName from persons
where LastName in ('Ken','Jing');
# or
select LastName, FirstName from persons
where LastName ='Ken' or LastName ='Jing';
| LastName | FirstName |
|---|---|
| Jing | Xi |
| Ken | Chg |
| Jing | Chg |
16 BETWEEN 在where中使用,选取两个值之间的数据范围
select column_name(s)
from table_name
where column_name
between val1 and val2
3. SQL函数
1 聚合函数 统计列
| 内置函数 | 作用 |
|---|---|
| AVG() | 均值 |
| COUNT() | 行数 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| SUM() | 和 |
# 聚合函数均值avg()
select avg(`Mobile`) as `平均值` ,`StuName` from student group by (`StuName`);
# 统计总行数
select count(*) as 人数 from student s ;
平均值 StuName 15555153250 杰尼龟 15555153250 肯泰罗 15555153250 皮卡丘 15555153250 百变怪
人数 4
2 字符串函数
| 函数 | 作用 | 示例 |
|---|---|---|
CONCAT(str1,ste2,...) |
连接 | SELECT CONCAT('MY','S','QL') |
INSERT(str, pos ,len , newstr) |
替换pos从1开始 |
SELECT INSERT('这是oracle数据库',3,8,'MYSQL')返回:这是MYSQL数据库 |
LOWER(str) |
小写 | SELECT LOWER('mySQL') mysql |
UPPER(str) |
大写 | SELECT UPPER('mySQL') MYSQL |
SUBSTRING(str, num, len) |
字符串截取 | select substring('输入一个SQL表达式来过滤结果',4,6);个SQL表达 |
3 时间函数
4 数学函数
| 函数 | 作用 | 示例 |
|---|---|---|
CEIL(X) |
返回大于等于x的最小整数 | select ceil(2.1); # 3 |
FLOOR(X) |
返回小于等于x的最大整数 | select floor(2.1);# 2 |
ROUND() |
四舍五入 | select round(2.1); # 2 |

若有收获,就点个赞吧
0 人点赞
