1. 几种聚类
1.1 层次聚类
层次聚类不仅仅构造了“聚类”,或是个体的一系列单纯分组,还构造了一系列对数据点进行分组的方法。不妨设想用一条水平线对树状图进行“切割”,并忽略线以上的部分,随着水平线下移,我们会得到包含越来越多个簇的不同聚类方式。
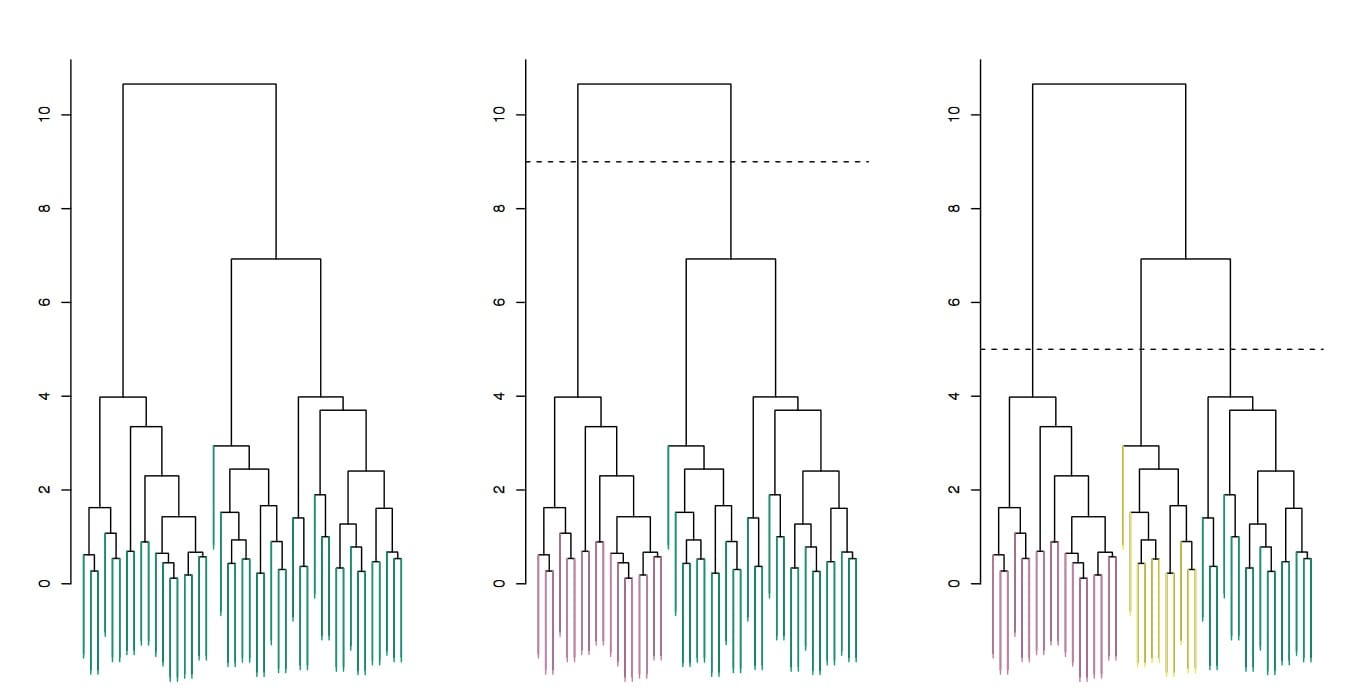
层次聚类的好处之一是,数据分析师可以在决定获取的簇个数之前看到分组情况,即数据相似性的“格局”。我们可以根据想要的簇的树木,在图表的任意位置进行切割,如图中水平虚线所示。
1.2 最邻近聚类:根据形心的聚类
最常用的基于形心的聚类算法称作K-均值聚类(K-means cluster),K-均值的“均值”指的是形心,即簇中实例在每个维度上的值得算术平均值(平均值)。
最后比较聚类结果的时候,可以通过检验簇来比较,也可以根据数值指标比较,如簇的失真度。失真度即簇中所有数据点与其对应簇形心的距离平方之和,失真度越低,聚类越优良。
Todo
- 添加更多的聚类种类
- 添加聚类实现方法(详细的单独开篇,这里附上链接)
- 添加使用的注意事项和评价机制等等
统计学中有一句老话:“相关性不是因果关系”,指两个事件共现并不意味着两者之间存在因果关系。聚类中也有一句相似的警告:“语法相似不等于语义相似”,不能因为两件事物(尤其是两篇文章)有相同的表面特征,就认定他们语义上也一定相关。

若有收获,就点个赞吧
0 人点赞
