有针对性的营销需要我们确定客户群或客户细分,并将他们聚集在一起的特征进行定义。例如,在开发新品牌时,您想知道新产品是否有可能从您投资组合的其他部分吸引可能会或可能不会高度参与当前产品的客户。在定义和标记受众时,您可能希望定义不同的观望行为群体。细分应用的数量和使用ML在python中实现细分的方法一样多。
在本教程中,我的目标是引导您完成针对客户细分的初步实验。我将使用Kaggle Teleco数据为您提供帮助:
- 对数据进行概要分析和预处理,
- 以创建三个用于细分客户的聚类模型,并使用通用的统计过程可视化其输出,
- 以评估模型的性能,
- 从而揭示每个聚类背后的定义特征(即,可解释性)
数据剖析 Data Profiling
每个项目都从两种实践开始:数据剖析(什么是数据?)和探索性数据分析(我的数据捕获了什么关系?)。在本教程中,我将跳过EDA,这对我非常不利,正如我们在讨论噪声如何影响模型时在文章结尾看到的那样。
因为我的最终目标是创建一个可处理列转换的可部署管道,所以我将想知道列是什么数据类型以及它们的值的分布。
特征剖析评估输出样例
对于电话服务,家属,合作伙伴和无纸化账单等二进制功能,我想使用cat codes或LabelEncoder()将它们转换为类别代码(0或1);对于基于字符串的类别(如PaymentMethod),我想生成虚拟对象(dummies)。这将使我们能够结合有状态特征和连续值来驱动集群模型。
#binary featuresbinary_features = ['PhoneService','Dependents','Partner','PaperlessBilling']for feat in binary_features:customers[feat] = customers[feat].astype('category').cat.codes#dummy featuresdummy_features = ['PaymentMethod','Contract','StreamingMovies','TechSupport','DeviceProtection','OnlineBackup','OnlineSecurity','InternetService','MultipleLines','StreamingTV']dummies = pd.get_dummies(customers, columns = dummy_features)customers = pd.merge(customers, dummies)customers.drop(columns = dummy_features, inplace = True)customers.head()for col in customers.columns:print(col)#Scale the non-binary, not dummy valuesnot_binary_values = ['tenure', 'TotalCharges']scaler = StandardScaler()customers[not_binary_values] = scaler.fit_transform(customers[not_binary_values])#Final scaled, transformed X for modelingscaled_X = customers.drop(columns = ['customerID'])
Code for transforming dummies, binary, and scaled features
对于这些连续值,我们将希望像上面一样缩放它们。这是因为某些使用欧几里得距离作为度量的聚类模型(kmeans,BIRCH)将需要具有一定程度的z标准化,才能对连续的值赋予相等的权重。对于非欧几里得来说,这会造成一定程度的失真-我们想尝试一下性能。在本教程中,我们将使用StandardScaler()标准化连续值,然后继续进行。
模型搭建
我测试了三种用于细分客户的模型,将它们传递给Universal Manifold Approximation and Projection,以便在三个维度上可视化它们——尽管有40个维度。
我的三种分割算法是K-Means聚类,带噪声的基于密度的应用程序空间聚类(DBSCAN)和使用层次结构的平衡迭代减少与聚类(BIRCH)。
#Kmeanskmeans = KMeans(n_clusters=5)kmeans.fit(scaled_X)#DBSCANdbs = DBSCAN(eps = 2.3, min_samples = minPts * 2)dbs.fit(scaled_X)#BIRCHbch = Birch(branching_factor = 50, threshold = 10, n_clusters = None)bch.fit(scaled_X)
该代码用于构建所有三个模型。我如何选择超级参数?见下文!
我选择了UMAP来减少可视化。我们通常会在可视化中看到t-SNE或PCA用于减少维数的地方,问题是它们的聚类得到了优化,以显示聚类之间的距离。这是以牺牲集群之间的多重关系为代价的。换句话说,它们不能用于比较聚类之间的距离,这种方法思考聚类“相似性”非常有用。 tSNE可以确保使用这种方法在多维上彼此接近的点在低维度上仍将保持接近;但是,它不能保证将“遥远”的点保留在低维的远处。为了克服这个问题,UMAP使用了一个交叉熵代价函数,该函数定义了大X时低Y和高Y之间的差异,而不是简单地计算X和Y之间的距离。
如果您想进一步了解UMAP的工作原理,请查看这篇文章。为了利用UMAP,我构建了一个函数,该函数从模型中接收数据并执行降维。然后,我将其传递给3d绘图函数,该函数既可以在笔记本中打开,也可以推送给plotly。
#visualize our modeldef umap_reduction(n_components, data, cluster_labels):neighbors = data.shape[1] - 1names = ['x', 'y', 'z']manifold = umap.UMAP(n_neighbors = neighbors, n_components = n_components, min_dist = .5)embeddings = manifold.fit_transform(data)viz_matrix = pd.DataFrame(embeddings)viz_matrix.rename({i:names[i] for i in range(n_components)}, axis = 1, inplace = True)viz_matrix['labels'] = cluster_labelsreturn viz_matrixdef plot_3d(df, name='labels'):iris = px.data.iris()fig = px.scatter_3d(df, x='x', y='y', z='z', color=name, opacity=0.5)fig.update_traces(marker=dict(size=2))fig.show()pio.write_html(fig, file= 'index.html', auto_open = True)
Kmeans
Kmeans通过选择k(我们想要在数据中找到的簇数)来工作。我们如何选择呢?我们可以使用拐点图(inertia elbow plot)来判断,inertia是对群集中的点有多远的量化,我们希望将其最小化。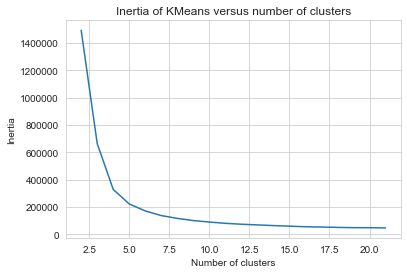
inertia是“簇内平方和” –点越靠近簇的中心,方差越小。在弯头,添加更多的聚类可以最小化减少方差,并不必要地增加模型的复杂性!
#here, we're going to test our inertia for each number clusters. We're aiming for an elbowscores = [KMeans(n_clusters=i+2).fit(scaled_X).inertia_ for i in range(20)]sns.lineplot(np.arange(2, 22), scores)plt.xlabel('Number of clusters')plt.ylabel("Inertia")plt.title("Inertia of KMeans versus number of clusters");
绘制拐点图。您也可以选择轮廓分数,但是我更喜欢将其用作比较器评估而不是优化。
然后,该算法会随机初始化每个质心,选择与该点到最近的质心距离的平方成正比的下一个点。然后,我们进行一些重新分配和更新-将数据中的每个点(重新)分配给质心最靠近它的聚类,然后重新计算每个质心的位置,作为分配给该聚类的所有点的均值(中心)。重新分配和更新将一直持续到质心停止移动或点停止切换群集为止。

若有收获,就点个赞吧
0 人点赞
