什么是机器学习
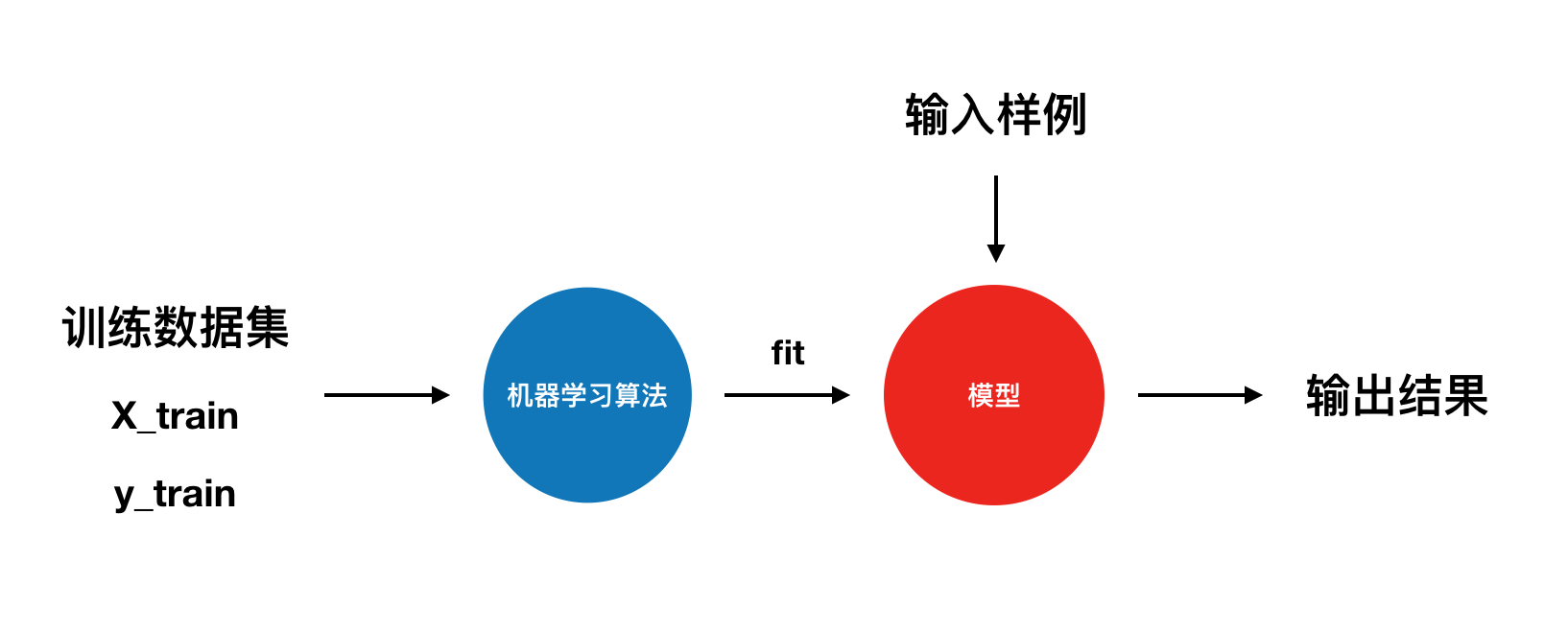
KNN算法基本思想
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
两个点的相似程度用空间中的距离来表示,最常用的是中数数学就学过的欧拉距离:
对欧拉距离进行扩展到多维空间:
实现过程
from math import sqrtfrom collections import Counterdef KNN_classify(k, X_train, y_train, x):assert 1<=k<=X_train.shape[0], 'k must be valid'assert X_train.shape[0] == y_train.shape[0], \"the size of X_train must equal to the size of y_train"assert X_train.shape[1] == x.shape[0], \"the feature number of x must equal to X_train "distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in X_train]nearest = np.argsort(distances)topK_y = [y_train[i] for i in nearest[:k]]votes = Counter(topK_y)return votes.most_common(1)[0][0]
这仅仅是最简单的基本实现,在scikit-learn中实现的更全面,复杂的KNN算法
机器学习算法性能
直接使用全部数据作为训练数据存在两个问题:模型很差,存在真实的损失。真实的环境很难拿到真实的label。为解决这两个问题,我们对数据实行分离,分离为训练数据train和测试数据test。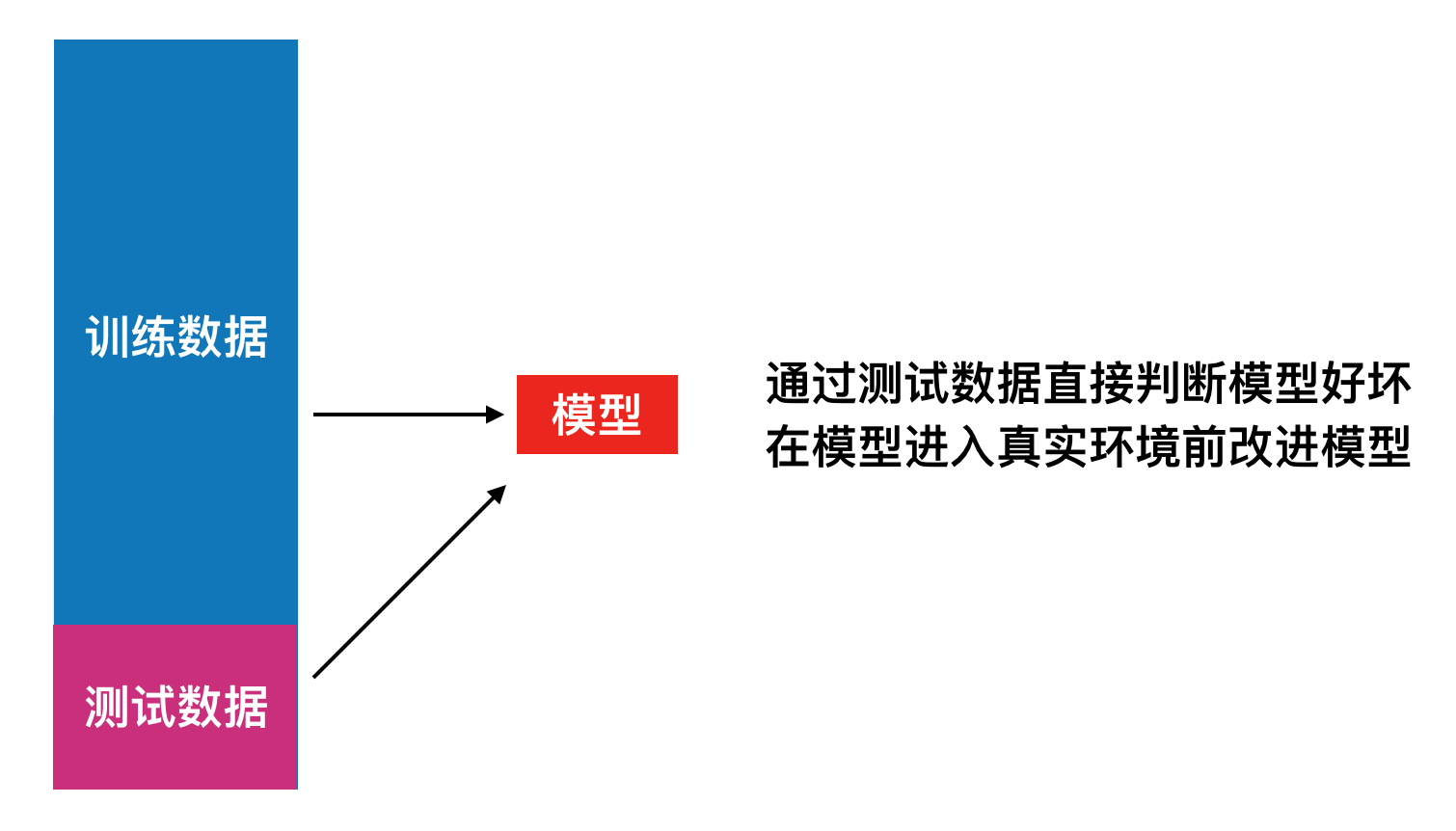
在分离split数据前,需要对数据进行洗牌shuffled,确保数据的随机性。最后用分类准确度(accuracy)进行评分。
超参数
- 超参数:在算法运行前需要决定的参数。
- 模型参数:算法过程中学习的参数。
kNN算法没有模型参数,KNN算法中的K就是典型的超参数。
普通的KNN算法没考虑距离的权重,所以KNN算法还有种用法,就是考虑距离。数学上有几种不同的距离,平时我们所说的距离一般是批欧拉距离,除此以外,还有
曼哈顿距离 
由曼哈顿距离和欧拉距离可以推导出
明可夫斯基距离 
当p=1时,明可夫斯基距离就是曼哈顿距离,p=2时为欧拉距离,推广以后就可以得到一个新的超参数P。
在Scikit-learn中可以方便的使用GridSearchCV来进行网格搜索,方便的找到最佳超参数。

若有收获,就点个赞吧
0 人点赞
