什么是决策树
想象一样生活中的一个场景,妈妈给女儿介绍男朋友
女儿:长得帅不帅?
妈妈:挻帅的。
女儿:有没有房子?
妈妈:在老家有一个。
女儿:收入怎么样?
妈妈:还不错,年薪百万。
女儿:做什么工作的?
妈妈:IT,互联网公司做数据挖掘的。
女儿:好,我见见。
现实生活中,我们会遇见各种选择,都是基于经验来做判断,如果把判断背后的逻辑整理成一个结构图,你会发现实际上就是一个树状图,这就是决策树。
可能上面的说法还不是很具体,决策树在sklearn中简单使用如下:
import numpy as npimport matplotlib.pyplot as pltfrom sklearn import datasets# 使用鸢尾花数据iris = datasets.load_iris()X = iris.data[:, 2:] # 使用数据后两个特征y = iris.target# 画图plt.scatter(X[y==0, 0], X[y==0, 1])plt.scatter(X[y==1, 0], X[y==1, 1])plt.scatter(X[y==2, 0], X[y==2, 1])plt.show()
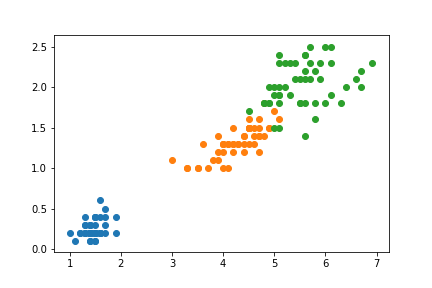
从散点图可以很清楚的看到鸢尾花三个分类的数据特征非常明显。
# 使用sklearn的决策树进行分类学习from sklearn.tree import DecisionTreeClassifierdt_clf = DecisionTreeClassifier(max_depth=2, criterion="entropy")dt_clf.fit(X, y)# 画出决策分类# 决策边界def plot_decision_boundary(model, axis):x0, x1 = np.meshgrid(np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),)X_new = np.c_[x0.ravel(), x1.ravel()]y_predict = model.predict(X_new)zz = y_predict.reshape(x0.shape)from matplotlib.colors import ListedColormapcustom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3])plt.scatter(X[y==0, 0], X[y==0, 1])plt.scatter(X[y==1, 0], X[y==1, 1])plt.scatter(X[y==2, 0], X[y==2, 1])plt.show()
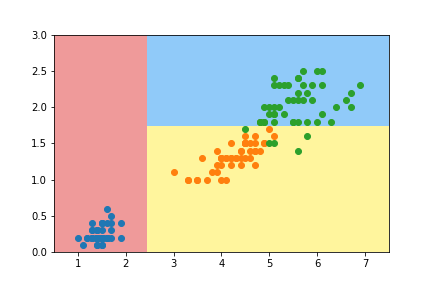
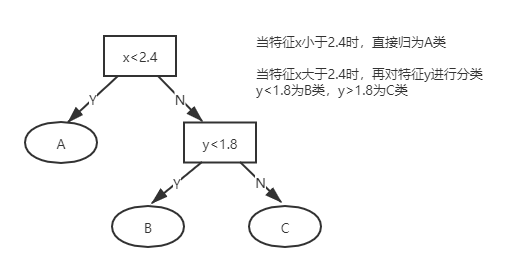
如图,sklearn的决策方式可以用树模型可以表示
小结:

若有收获,就点个赞吧
0 人点赞
