算法是作用于数据结构之上的,深度优先搜索算法和广度优先搜索算法都是基于“图”这种数据结构。
如何理解图(Graph)
图是一种非线性表数据结构,图中的元素叫做顶点(vertex)。顶点可以与任意其它顶点建立连接关系,这种关系叫做连(edge)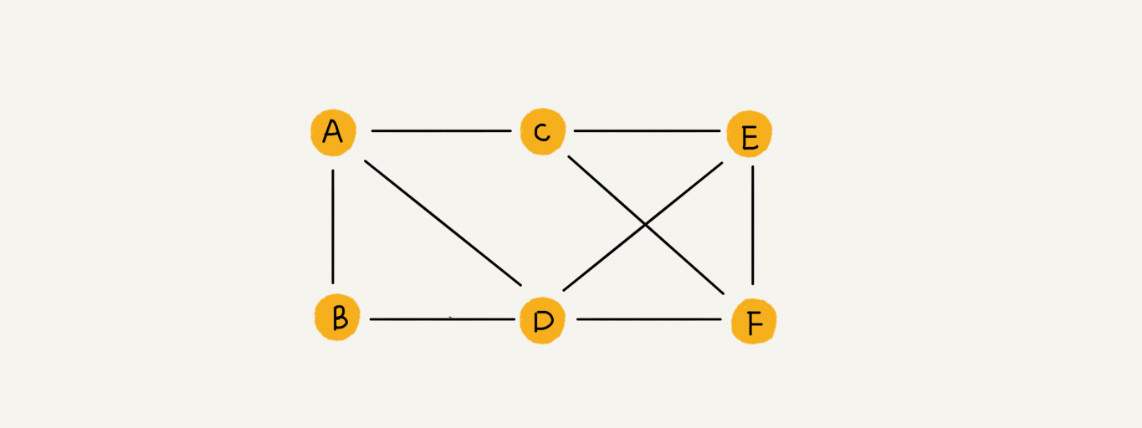
邻接表存储方法
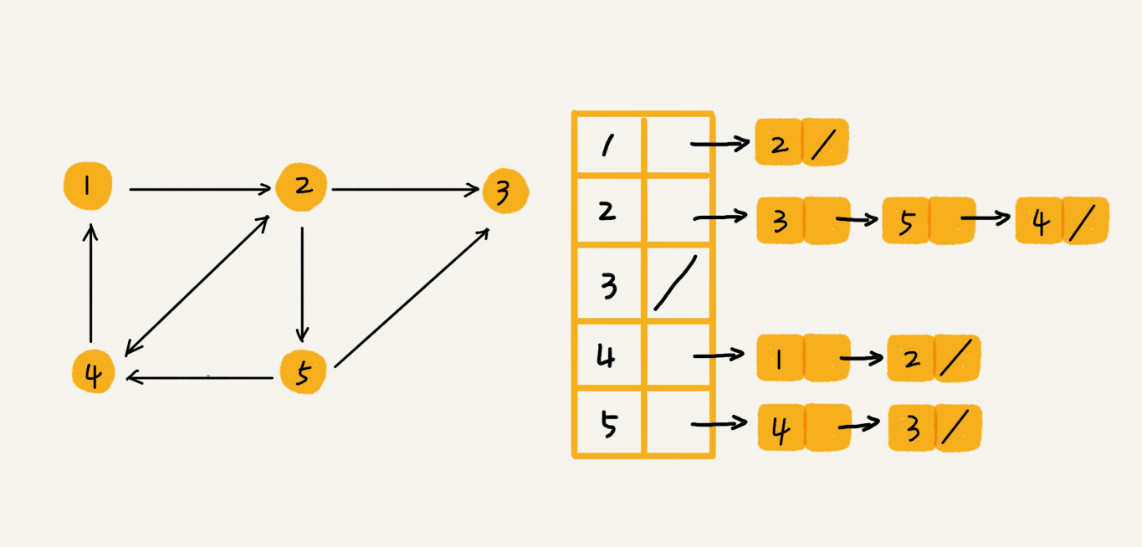
每个顶点对应一条链表,链表中存储的是与这个顶点相连接的期货顶点。
Graph的代码实现
import java.util.LinkedList;import java.util.Queue;public class Graph {private int vertex; // 图的顶点数private LinkedList<Integer> adj[]; // 邻接表public Graph(int v){this.vertex = v;adj = new LinkedList[v];for (int i = 0; i < v; i++){adj[i] = new LinkedList<>();}}// 无向图的边存两次public void addEdge(int s, int t){adj[s].add(t);adj[t].add(s);}/*** 广度优先搜索* @param s 源点数* @param t 目标数*/public void bfs(int s, int t){if(s == t) return;// 记录已访问的点,防上重复访问boolean[] visited = new boolean[vertex];visited[s] = true;// 记录搜索路径int[] pre = new int[vertex];for (int i = 0; i < pre.length; i++){pre[i] = -1;}//队列用于存储已被访问,但相连的顶点还没有访问的顶点Queue<Integer> queue = new LinkedList<>();queue.add(s);while (queue.size() != 0){int w = queue.poll();for (int i =0; i < adj[w].size(); i++){int q = adj[w].get(i);if(!visited[q]){pre[q] = w;if(q == t){print(pre, s, t);return;}visited[q] = true;queue.add(q);}}}}public void print(int[] prev, int s, int t){if (prev[t] != -1 && t !=s){print(prev, s, prev[t]);}System.out.print(t + " ");}public static void main(String[] args) {Graph graph = new Graph(8);graph.addEdge(0,1);graph.addEdge(0,3);graph.addEdge(1,2);graph.addEdge(1,4);graph.addEdge(2,5);graph.addEdge(4,5);graph.addEdge(4,6);graph.addEdge(5,7);graph.addEdge(6,7);graph.bfs(0,1);}}

若有收获,就点个赞吧
0 人点赞
