天猫双12商品参数数据:## 前言:
《天猫双11爬虫(福利:212万条商品数据免费下载)》
http://pan.baidu.com/s/1bPV2u6http://pan.baidu.com/s/1gf5IOlthttp://pan.baidu.com/s/1qXWo9Zmhttp://pan.baidu.com/s/1eS82C9cGithub-Tmall1212
## 数据说明:
天猫双12商品原始数据:https://detail.tmall.com/item.htm?id=538420191509
天猫双12商品活动数据: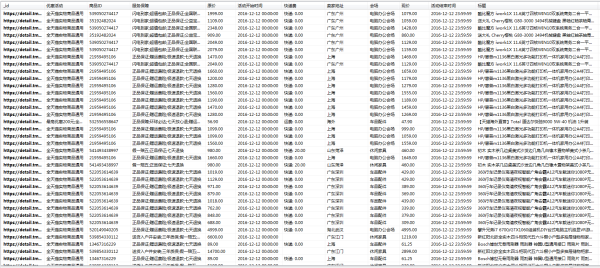
 天猫双12商品图片数据:
天猫双12商品图片数据: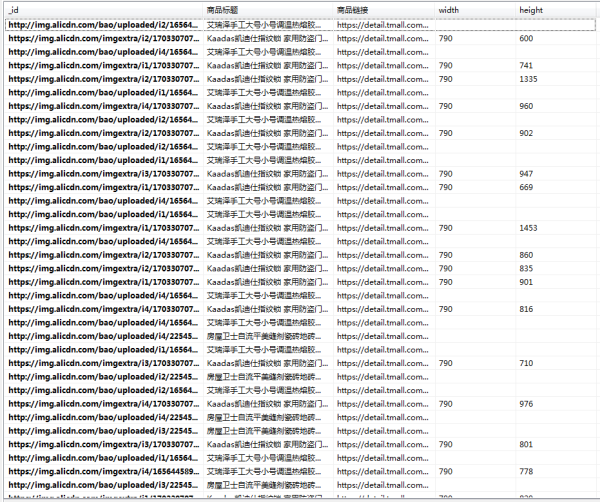
代码说明:
- 程序主要分为两个步骤:从活动主页面入手,抓取到所有商品ID;根据商品ID抓取并解析商品信息。
- 双12活动主页面,里面有35个分会场,将链接解析放在 urldict.py。程序从分会场开始抓。
- 分会场的页面中,有些可点击进入商品详情页,有些可点击进入商店主页。进入商店主页以后可点击进入商品详情页。所以我们从分会场的主页可解析到部分商品ID,以及部分商店URL,进入商店URL再获取其他商品ID。汇总起来就是所有商品ID了。
- 但是天猫加载数据的方式有几种,一个是直接放在html中,一个是通过json加载,或者两者都用。所以在解析各分会场主页也好,解析商店住而已也好,几种情况都要做解析。
- step1.py解析各个分会场,step2.py解析appids(appids可构造json的请求URL,即处理step1.py里面的json调用),step3.py解析商店数据(从里面解析出商品ID,或json的url),step4.py处理商店中的json调用。4个步骤获取完所有商品ID
- crawl_detail.py根据商品ID抓取商品页面,未解析。crawl_property根据商品ID抓取商品的参数数据,带解析。
- parser.py解析crawl_detail.py拿到的页面。至此,任务完成。
- crawl_img.py可根据图片数据去下载图片,一般人都不需要下这些图片吧。 代码时效性比较高,未作特别详细的介绍,有兴趣的可以跑一下,有疑问请留言。
我正在参加CSDN 2016博客之星评选,希望得到您的宝贵一票~https://zhuanlan.zhihu.com/p/24312829

若有收获,就点个赞吧
0 人点赞
