有哪些「神奇」的数据获取方式? - 知乎
2017年4月5日 星期三
01:19
https://www.zhihu.com/question/32164316
作为互联网营销策划,经常需要查询一些数据来完善方案逻辑,因此整理了一些数据网站,分享给大家。
主要为互联网数据和一些传统数据的查询,主要包括:
1. 互联网部分:移动端数据(微信、微博、APP),网站数据,综合数据,票房和电视收视率,视频指数,内容数据
2. 传统数据部分:经济数据,企业数据,金融数据,汽车数据,建筑数据,医疗数据,服装数据,建筑数据
只涉及数据查询不涉及报告下载,至于下载数据报告网站(看点赞情况再分享吧),用完这些网站,如果还有什么数据查不到,私信我,再分享一些网站给你查(我就说说别当真/调皮)
特地将数据网站整理为书签,点击此链接直接导入书签:https://pan.baidu.com/s/1nvSBeBn…
最近看了一下数据(感谢195,2385次收藏/流汗)别光收藏、感谢呀,顺便点个赞呗:越点赞越好运
一、移动端数据
l 微信数据(营销老是要分析一些KOL和自媒体)
1. 排名列表_日榜
2. 新媒体指数
3. 微问数据_微信公众号分析
4. 微榜 | 爱微帮新媒体榜 Beta
5. simplyKOL微信数据
6. 微指数微信大数据领导者微信文章微信营销微信公众账号大全_微信排行榜
7. 微信公众平台导航_微信公众账号大全
8. 可查90数据-易赞 (部分数据配合数据透视,有更多惊喜)
l 微博数据(宝强过后微博又开始红了一段时间)
1. 知微传播分析-WeiboReach
2. 微博认证-名人堂
3. 发现-热门微博
4. 微风云_微博风云榜
5. 数据首页-微博数据中心-新浪微博
l APP数据(帮几家金融机构的APP,做过推广和优化,所以收藏了一些网站)
1. 热门苹果应用搜索 只查IOS
2. App Annie App Store Stats | iOS热门 App 排行榜 中国 - 所有类别 只查IOS
3. 应用雷达-iOS深度移动推广运营服务平台|苹果APP排名搜索优化统计分析 只查IOS
4. 友盟指数 - 最专业的移动互联网行业发展趋势指数
5. 首页-应用排名分析平台-爱盈利
6. ASO100 - 中国最专业的 App Store 排名、ASO 数据平台
7. App竞品大数据平台_App运营、ASO优化必上APPDUU
8. APP宏观数据—友盟指数 - 最专业的移动互联网行业发展趋势指数
9. 应用排名分析平台-爱盈利
10. APP排名查询-易观千帆(数据比较详细,可惜只能免费查三天)
11. 安卓&IOS APP数据-酷传 - 添加应用 安卓和IOS都可以查
二、网站权重和数据(网站SEO和SEM不太懂,但是有一家很牛的供应商,主要做中间商,整理方案)营销的时候,SEO和舆情更配
1. Alexa网站排名查询
2. 中国站长站
3. 站长工具-百度权重排名查询-站长seo查询 - 爱站网
4. 网站排名网站数据流量查询中国网站排名_网络媒体精品推荐
5. 友情链接—友情链接查询|友情链接检查工具-站长帮手网
6. PR真假—PR查询|PR真假查询|PR劫持检测-站长帮手网
7. 友情链接交换—go9go友情链接平台—想链就链go9go
8. 行业网站排名行业网站排行榜行业网站大全 - 网站排行榜
三、综合指数(写传播结案和分析客户传播节奏的时候用)
1. 百度指数
2. 搜狗指数
3. Google 趋势
4. 好搜指数-搜索大数据分享平台
5. 微指数首页
6. 热搜榜单首页—百度搜索风云榜
7. 艾曼指数首页
8. 淘宝指数 - 淘宝消费者数据研究平台(已经没有了,以前很好用)
9. 阿里指数 - 社会化大数据分析平台(必须要开过淘宝店的账号,更可气的是只能查询单一行业)
10. 阿里指数_最权威专业的行业价格、供应、采购趋势分析(这个就能完美解决上面的问题)
四、票房和电视收视率(额……为什么有这些网站,才不会告诉别人,是因为我喜欢看电影)
1. 中国票房
2. 电视收视率—CSM
3. 猫眼票房分析
4. 精选预告片 - 预告片世界
五、视频指数(近期想切入视频IP市场的推广,也就是想想)
1. 搜库-专找视频
2. 腾讯视频指数
3. 中国网络视频指数 – 网络视频收视数据分析平台
4. 优酷指数 - 中国第一视频网,提供视频播放,视频发布,视频搜索
5. 搜狐视频指数中心 - 搜狐视频
6. 爱奇艺指数
六、内容排行(这个网站偶尔看一下热点吧,用的比较少)
1. 网评排行-搜狐
一、经济数据
1. 人民银行
2. 国家数据
3. 中国银行业监督管理委员会
4. 中国统计信息网
5. 统计数据
6. 中华人民共和国国家统计局 统计数据
7. 专项统计数据-中国证券业协会
8. 居民消费价格指数(CPI) 数据中心 东方财富网
二、企业数据(有时候接到一些Brief,大部分客户不靠谱,可能会问候一下他企业背景)
1. 全国企业信用信息公示系统 (官方出品)
2. 企业信息—天眼查-最专业的企业工商信息查询(这个比官方的好用)
3. 企业名录-企业黄页_必途网企业黄页大全
4. 企业信用查询企业信用报告查询系统注册信息查询网-信用视界
三、金融数据
l 网贷数据(去年P2P,不,是互联网金融很火的)
1. 金汇金融_平台指数_P2P网贷平台评级网贷315
2. 【p2p网贷平台排名】最新网贷平台排名网络借贷平台排名网络贷款平台排名-网贷之家
3. 平台报告-零壹数据
4. 上海贷款小额贷款贷款公司_银行贷款 - 融360
5. 平台指数P2P网贷平台评级网贷315
6. 新金网 - 最专业的互联网金融导航网站
7. P2P网贷平台数据排行对比网贷平台数据网贷天眼
8. p2p排行榜,网络理财排行榜,第三方p2p平台排行榜 - 76676-最大的投资理财产品点评平台
l 上市公司年报(竟然为了分析社媒趋势去看BAT的年报,表示看不懂呀)
1. 中国—巨潮资讯网
2. 美国—SEC.gov | Company Search Page
3. 香港—:: HKEx :: HKExnews ::
l 信托(信托切入互联网金融相对较慢,今年刚开始接触的几个客户)
1. 研究报告 - 中国信托业协会
2. 中国互联网金融研究中心 中国互联网金融网 中国互联网金融联盟 中国电子商务研究中心
l 其他
1. 案例报告列表融资案例并购案例行业案例企业案例数据分析—投资潮
2. 融资数据—融资事件列表页 | IT桔子
3. 研究院_ChinaVenture投资中国网
4. 百度财富-专业金融服务平台
5. 世界银行-Data | The World Bank
6. 全球股市指数
7. 股指期货数据
四、汽车数据(有一个汽车配件的客户,讲真,汽车客户真的比金融客户前期好搞,不过后期服务就呵呵了)
1. 数据中心 世界汽车统计 中国汽车工业协会
五、建筑数据(我也不知道为什么有这个网站)
中华人民共和国住房和城乡建设部 - 单位资质查询
六、医疗数据
1. 世界卫生组织 | 规划和项目
七、服装数据(才不会告诉你,我是学国际经济与贸易出身的,后来才做了互联网营销策划,其中有一万只羊驼在奔跑)
1. 中国皮革原材料指数
2. 海宁周价格指数
3. 中国柯桥纺织指数
4. 大朗毛织价格指数
八、工业指数
1. 今日国际原油价格,原油价格走势图,原油价格指数-油价网
2. 上海有色金属价格指数
3. 水泥指数
其他数据
1. 中国统计信息服务中心 口碑查询
2. 最具公信力的名人影响力指标 - 必应 影响力
3. 全部榜单—百度搜索风云榜
4. 百度预测-大数据 知天下
l 原始数据-数据淘(这个网站听说可以买到原始数据,不过没有试过)
这些网站还不错,数据也算可以,其他的数据网站没有分享了。这只是网站,具体用法太多了,就没有分享单个教程。强调:网站用的好,真的能用出花来,比如百度指数+百度新闻=客户和竞品的传播节奏。具体网站的功能多试试,不要执着于网站,要多变通思路,希望能找到想要的数据(说服力)。
编辑于 2017-02-24
团支书
用数据认识世界,用数据改变未来
有多少人,因为看到一张漂亮的可视化图表而走上了学习数据分析的道路。
有多少人,因为无法获取到想要的数据,忍痛半途而废。
数据啊,要怎么才能找到你?
在数据团之前的活动中,我们推出过免费和收费的课程,教大家怎么通过爬虫获取互联网数据。
但是,仅仅有互联网数据是不够的……它顶多占常见数据类型的1/8:
剩下7/8的数据去哪里找呢?
有没有一个活雷锋的组织,里面有许多热衷于分享数据的小伙伴,甚至会按照我的需求去帮忙收集数据呢?
有!
数据界的活雷锋、最最神奇的数据获取方式——
【城市数据研习社】城市数据库开放啦!
活动平台:
QQ群“研习社—城市数据库”,群号 143892177(加群注明:城市数据分享)。
——————————-
这是一篇广告
广告及其推广内容免费
——————————-
主要活动说明:
1、数据共享:
由城市数据研习社、国匠城、城市数据团共同提供的数据,公开发放给大家,同时欢迎小伙伴儿分享自己的数据,建议标注数据来源、数据量、数据坐标等信息。现分享数据包括:
(1) 全国重点城市的POI数据
λ 城市:北京、上海、深圳、重庆、南京、青岛、西安、武汉、成都、苏州、厦门、长沙、哈尔滨、贵阳、杭州、昆明、徐州、三亚、关注……
λ 标签:餐饮、旅游景点、公共设施、交通设施、购物、教育、金融、商务住宅、生活、体育、医疗、政府办公、住宿服务
(2) 世界重点城市基础地图数据
λ 城市:伦敦、纽约、摩纳哥、威尼斯、香港、马德里、莫斯科、柏林、澳门
λ 标签:建筑面、POI点、道路线
(3) 全国高清影像图数据
λ 支持地图:谷歌地图、高德地图、腾讯地图、百度地图、必应地图等
(4)全国省界、市界的行政边界数据
(5)世界行政区划矢量数据
(6)全国地貌数据
2、数据导航:
数据导航报告是国匠城精心整理的数据获取网站的汇总,报告见群文件——城市数据研习社数据导航报告;同时欢迎大家积极提供数据获取的网站与途径,共同完善数据导航报告。
3、数据申请:
提供由研习社、国匠城、城市数据团三大机构通过商业合作、购买等方式获取的数据,需要通过协助推送优秀城市数据分析师及相关数据技能分享的方式申请获得,且以城市(城镇)为单位,申请该城市(城镇)相关数据:
(1)城市基础数据
(2)DEM地形数据
(3)街道单元的人口数据
(4)生态湖泊水系数据
(5)城市公园绿地数据
4、数据众筹:
通过提交“数据众筹计划书”,由城市数据研习社的小智发布“数据众筹公告”,招募小伙伴,自愿组成“数据众筹小组”,进行数据收集、整理,城市数据研习社提供部分技术支持。
5、数据支持:
城市数据团与滴滴大数据研究中心、TalkingData、同策房产咨询、银联智慧研究院、大众点评研究院、链家研究院、支付宝口碑、上海道融自然保护与可持续发展中心、高德地图、安居客等多家机构有着良好合作关系,现面向研究者们开放商业级数据申请接口,研究者通过填写“研究计划书”参与数据支持活动,通过审核后将由数据提供方对研究者提供数据。
怎样参与?
加入”研习社—城市数据库”QQ群,群号码为143892177(加群注明:城市数据分享)
编辑于 2016-12-21
金胤臻
一个勾引家,一个治愈者,HOW联合创始人,Data Scientist
===== 更新 =======
很多朋友想要知道更多应用,因为最近时间比较紧,我这里先写一下之前我在美国用过的selenium免费下载天气数据的办法。
美国有很多天气的网站,之前做的一个项目需要我从四个网站抓取同一个地点的数据,然后对比一下。很多网站的天气数据都是公开的,免费,没有问题,下载就行。但是有个商业网站,Weather Source 是需要购买api付费的。而且比较贵。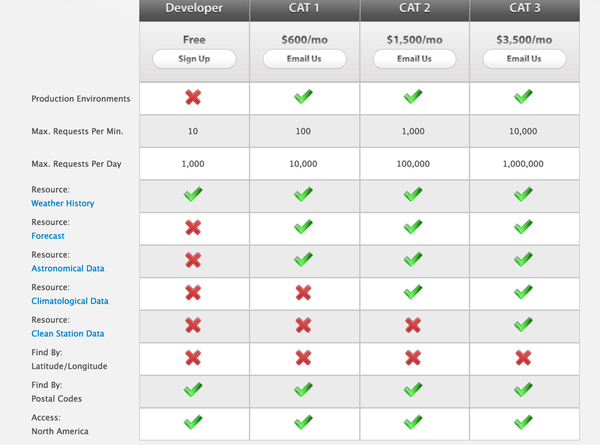
free的那一栏其实很多资源都没办法用,然后1000个requests意味着最多1000个地方的数据可以下下来,而且数据量太少了。其他的价格很贵。
后来我看了一下,发现还有一个可以手动下载的地方:
30天,只要40美金。
点击sign in就可以进去了。进去之后是这样一个页面: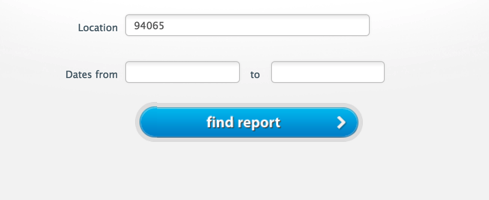
然后输入你的zipcode,查找find report,之后你会发现: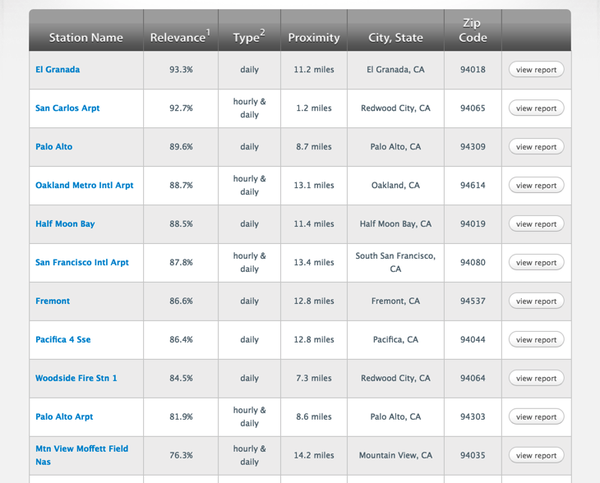
点击进入 随便找一个station,点击view report,然后你会看到
点击spredsheet downloads就可以下载你需要的数据了。点击下载的时候会跳转到一个下载页面然后告诉你需要保存么?
通过这样一系列的手工操作我发现了一定的规律,然后就可以用selenium下载文档了。
你会发现下载的链接是:
http://weathersource.com/account/downloads/download?file=dailyCSV&sid=t5s950bd4mjfs0fc1mis08k2a4&location=94065&start-date=1%2F1%2F1970&end-date=1%2F1%2F1970&obs=temp&station-id=28514&latitude=37.5335&longitude=-122.25&download-csv=download+spreadsheet
其中sid 是你需要的key,这个key当你登录了之后会直接有的。然后其他的parameter 就非常容易理解。那么就开始写脚本:
from selenium import webdriver
# 初始化 webdriver
url = ‘http://weathersource.com/‘
driver = webdriver.Chrome()
driver.get(url)
# 中间你可以设置一个断点,然后sign in,之后手工获取你的sid
sid = rawinput(“获取你的sid:”)
url = ‘http://weathersource.com/account/downloads/download?file=dailyCSV&sid={sid}&location={location}&start-date={start_date}&end-date={end_date}&obs=temp&download-csv=download+spreadshee‘
# 假设你的start date, location,还有 end date 都知道,zipcode 你有一堆的zipcode需要获取。
for zipcode in zipcode:
driver .get(url.format(start_date=XXX, end_date=XXX, zipcode=zipcode, sid=sid)
# 这里注意:为了能自动下载文件了,需要在chrome里设置自动保存就好了,不会弹出另存为的页面
通过上面的方法,我开了4个进程,一天之内就下好全美国的所有的数据,而且花了很少的钱,相对于购买api的价钱来说,省了不知道多少。唯一的缺点是,需要手动登录然后获取sid,虽然有些笨,但是对于当时还是个穷学生来说还比较划算。
这个只是一个例子,说明selenium有的时候可以用得很好来巧妙地获取数据。实际操作的时候,如果有api尽量用api,它只是在不可能中寻找可能。
===== 以前 =======
有好多方式方法可以用来获取数据,之前去面试一家公司,直接让我写个爬虫。爬虫脚本是比较容易想到的获取数据的方法。但是有的时候很多网站不提供api,然后用写爬虫的时候又还要用各种软件去截取信息,有的时候会花费一些时间。
相信很多人用过selenium用来做testing。我想在这里介绍一下用selenium来获取数据的方法。selenium可以模拟人在浏览器上如何操作,换句话说,当你在浏览网站的时候,看到网站上上有数据想要手动截取下来,selenium可以模拟整个过程然后进行规模化的抓取数据。那么下面我就举个例子:假如你想要获得微博某条下面所有回复的用户id,你就可以用selenium来直接抓取:
以下我用python的selnium来举例
1. 安装
pip install selenium
2. 脚本
from selenium import webdriver
url = ‘http://weibo.com/ttarticle/p/show?id=2309404020700624096846‘
# 初始化一个webdriver
driver = webdriver.Chrome()
# 用driver打开微博的链接,可能需要登录,手动登录一下就好
driver.get(url)
# 很多网站用h5的版本比较容易得到数据 我们登录微博了之后重新获取一个url,是h5的url
url = ‘http://m.weibo.cn/2723620723/E8ODT8Ydl‘
# 获得评论列表(这个需要自己查看网页的结构,每一个都不太一样)
comment_list = driver.find_elements_by_class_name(‘mod-media’)
for comment in comment_list:
print comment.get_attribute(‘href’)
result:
http://m.weibo.cn/u/2723620723
http://m.weibo.cn/u/2292913074
http://m.weibo.cn/u/1785845023
http://m.weibo.cn/u/2870114170
http://m.weibo.cn/u/2410507423
http://m.weibo.cn/u/2151174850
http://m.weibo.cn/u/1775468601
http://m.weibo.cn/u/2146208555
http://m.weibo.cn/u/2987324042
http://m.weibo.cn/u/2097203285
http://m.weibo.cn/u/5514270657
http://m.weibo.cn/u/1851751764
http://m.weibo.cn/u/3032379471
http://m.weibo.cn/u/3224372162
http://m.weibo.cn/u/1805635755
http://m.weibo.cn/u/2448378651
http://m.weibo.cn/u/1789747610
http://m.weibo.cn/u/3550528030
http://m.weibo.cn/u/3236610784
http://m.weibo.cn/u/2258176024
http://m.weibo.cn/u/5612221249
http://m.weibo.cn/u/6023204693
http://m.weibo.cn/u/2711823422
http://m.weibo.cn/u/1736956963
http://m.weibo.cn/u/2971442923
http://m.weibo.cn/u/5311296945
http://m.weibo.cn/u/1774168531
……
selenium 通过 webdriver 来控制浏览器,然后通过命令让浏览器做一些事情:点击某个链接去某个地方,点击下载的链接下载文件。他的好处是方便,不需要复杂的授权之类的,一般网站都会有cookies,所以你人工手动的授权一次就可以浏览所有的文件了。
好处:
1. 有的时候你直接查看pagesource的时候是看不到很多信息的,但是通过selenium的dom你是可以直接得到,因为pagesource很多是没有执行js,并不能模拟你当前看到的网页的结构。
2. selenium而且更加方便,不需要知道很多网络知识。
3. 很多时候可以做限制级的事情,因为感觉就是人在操作一样。善于运用cookies。
坏处:
1. 每一种网站都不一样,而且网站经常在变化,所以dom的时候你要经常变化。
2. 速度相对来说比较慢
selenium用的好其实可以做很多事情,也可以获得很多数据。之前我去获取一些美国的天气数据的时候,需要下载验证,就用了selenium做批量的处理,所以感觉相对来说还是很方便的。大家可以试试。
编辑于 2016-09-18
justjavac
迷津欲有问 https://github.com/justjavac
之前曾开发过一个全是马赛克的网站:基于 DHT 网络的磁力链接和BT种子的搜索引擎架构。
最初的方案是 Python 爬虫,去各大下载网站爬取种子信息。后来发现这种方案有个最大的缺点就是速度太慢,而且无法知道每个资源的热度。
有天晚上迷迷糊糊,感觉似睡非睡,似醒非醒,突然冒出了一个想法:如果有人想下载一个种子,那么必然有人制作了这个种子。
了解 P2P 原理的人都知道,BT 不需要中心服务器,因为每个节点既是客户端,同时也是服务器,因此我写了一个程序,把它伪装为 DHT 网络中的一个节点,这样当其他客户端想下载某个 torrent 时,就会在 DHT 网络发起广播,当它询问到我的节点时,我就知道了:哦,原来有人要下载这个种子啊,那么在 DHT 网络中肯定有这个种子。于是我把这个种子的信息保存到 MySQL 中。 通过检测别人对我的询问情况,我还可以知道某个种子的热度。
本来打算开源,目前已经弃坑。。。
———————-
广告时间,我的第一场 Live,给大家爆爆我的黑历史:前端工程师的入门与进阶 - 知乎Live - 全新的实时问答。
编辑于 2017-03-13
匿名用户
我说个过分的。马尔奖得主朱松纯老师 ucla统计和计算机两个系教授。2005年时候一心想用他的image parsing彻底解决视觉识别的框架问题 是十分有野心的想法。对如此复杂的框架 收集到足够的人工label数据做ground truth是很难的。朱老师来到湖北鄂州 弄了一个专科学校一帮学美术的 手工帮他label车 椅子 建筑等等等等。 大概一两年 建了个十万多张图片的数据库。
后来 mit几个人 还有li feifei 搞了个网络游戏 有点像大家来找茬 有竞赛性质 让人们来点击label。当然 这个label精度比朱老师的数据库查不少 但数量级实在是多出太多了! !我当时就对老美工业思维搞科研的角度震惊了一把 毕竟 几百万张label过照片 和10万张 能做的事太不一样了。
后来对 vision没有兴趣了 就加入Google挣钱去了。 一天 看到Google收购了一家公司 做recaptcha 就是验证码 大概2009年。三四个人的公司 卖了两千万 我们组以前的一个intern和他cmu导师和搞的。当时就被其思路震惊了。OCR问题里头有很多corner case 一般识别技术是读不出的 这些corner case要么是扫描的古籍英语 要么是角度不对 highly screwed 的路牌 铭片。他们就把这些东西拿出来做验证码 用众数原则判错或对 同时把majority答案作为label存起来。
Google收购后 直接拿来把Google book扫描未识别出的部分拿来做验证码了。label的结果用来改进其识别算法 加速扫描更多的图书和改进street view里未识别出路牌 门牌号。
想想吧 每天不得几亿个人工label被收集啊!2000万我都觉得卖贱了!
思路啊 很重要!
编辑于 2015-08-15
路人甲
喜欢用 『 数据 』讲故事 / 同学,你想学习编程吗?
数据获取的方式么,作为一个深度的数据挖掘控,数据爱好者,我要来回答一次了。
第一是爬虫
到现在,我最常用的获取数据的方式也基本上是爬虫,好处就是看到任何想抓取的数据,爬虫基本上都可以做到。
抓过的一些数据包括:
100w知乎用户信息、420w某彩票信息、200w的交通信息、16w的酒店信息、50w的中文网url…(想到这么多,暂时写着么多)
你以为爬取以上数据的爬虫真的很难吗?错错错!很简单(30行代码可以get all)
这么简单,所见所得,难道你不想试试这种获取数据的方式吗?
你可以用十天左右的时间完成学习,给出学习资料:如何学习Python爬虫[入门篇]? - 学习编程 - 知乎专栏
第二是一些网站可以下载到的数据
(1)、数据分析报告,数据报告,数据圈论坛
(2)、海量数据免费下载
(3)、Datasets | Kaggle
(4)、国云数据市场
(5)、数据包下载列表
(6)、微盛投资:沪深市场5分钟数据 wdz格式 转 txt、通达信,大智慧dad,飞狐dad,钱龙,同花顺,csv,dad,lc5,tdx,nmn,sql等
(7)、国家地球系统科学数据共享平台全球变化研究出版数据直接下载
(8)、中华人民共和国国家统计局>>统计数据
(9)、分类: 地球物理相关资源
(10)、国家数据
(11)、[产业数据统计数据](https://link.zhihu.com/?target=http%3A//www.chyxx.com/data/)
(12)、百度数据开放平台
第三是朋友共享
多接触一些做数据爬虫的朋友,很多热爱爬虫的朋友只是热爱爬虫爬数据但是不知道如何分析,如果有机会大家都是愿意分享出来给朋友分析的。
发布于 2016-08-14
Liu Cao
金融 话题的优秀回答者
郦橙锦妖
等
update: 强烈不推荐搞学术、做量化使用此方法,此方法只适用于商科PPT犬,做一些定性分析时使用。
——-
我不是搞经济学的,但是最近做实习,要找N多千奇百怪的data,其中有些变态的数据,找来找去都找不到。
但是在某个一霎那,你会突然发现某个report/paper 里刚好有我们想要的数据。就像这样: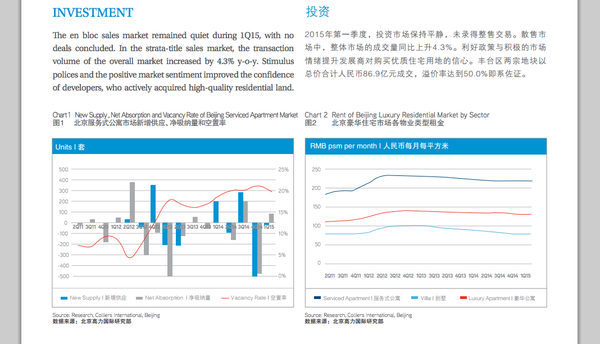
来源:http://www.colliers.com/-/media/files/marketresearch/apac/china/northchina-research/bj-residential-q1-2015.pdf…
但是然并卵… 你去email colliers 要data 他并不会理你啊。
这时候就轮到神器登场了,Ankit Rohatgi 开发的 WebPlotDigitizer。
上传我们想要的图片:
描好坐标轴和点: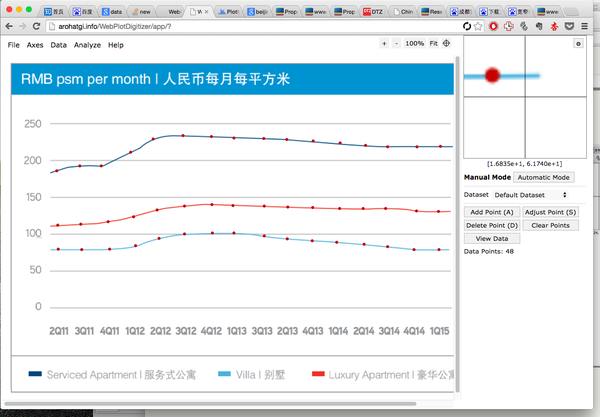
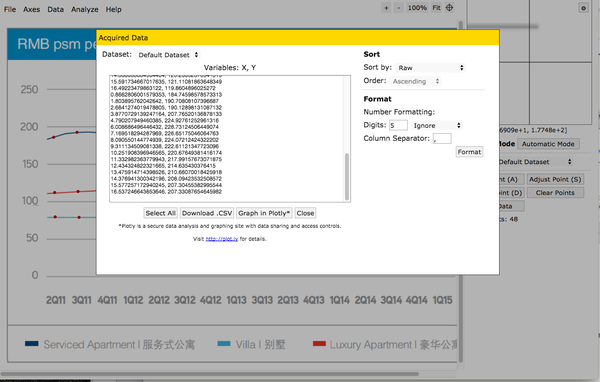
导出数据,大功告成!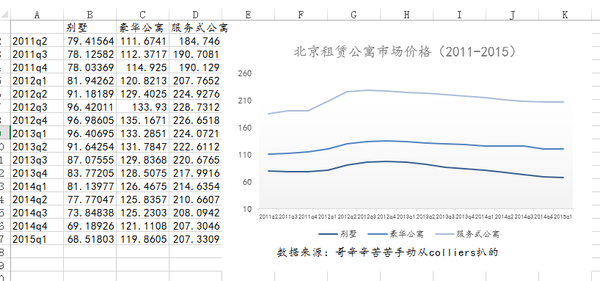
当然还有其他的,比如
Welcome to DataThief
http://digitizer.sourceforge.net/…
Digitize graphs and plots
或者你也可以自己写matlab code啥的识别
反正我是懒得下载软件/自己写code。
---------
其他可以解锁的技能:
NO1.使用 WebPlotDigitizer 自动识别曲线。
NO2.使用 WebPlotDigitizer 处理数据后使用Plotly直接画出曲线。
NO3.使用 WebPlotDigitizer 识别对数坐标轴
编辑于 2015-07-27
林茜茜
做最好看的编程课。
有一个利器,能帮你快速爬取你想要的资源……
有时候,你需要下载电影、音乐的资源,却发现下不下来。
因为你没安装客户端……
或者是找不到下载按钮在哪
这时候,愤怒的你可能会想要自己写个爬虫来搞定,那么在这里要告诉你,不必重新发明轮子了,有这样一个工具,5秒内就能帮你下载好你想要的资源!
使用这个工具,只需要输入命令,然后你就会看到5秒内视频下好了……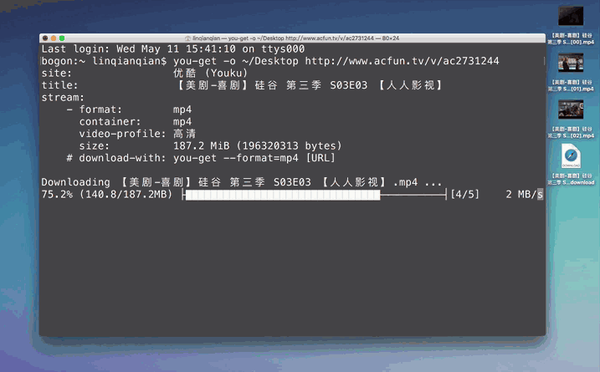
使用 you-get 快速爬取视频并下载
视频
还可以用来任性批量下图……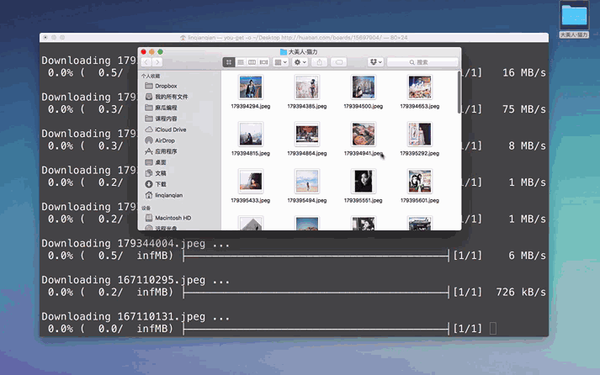
使用 you-get 批量爬取图片
视频
支持64个网站,包括优酷、土豆、爱奇艺、b站、酷狗音乐、虾米……总之你能想到的网站都有! 还有一个黑科技的地方,即使是名单上没有的网站,当你输入链接,程序也会猜测你想要下载什么,然后帮你下载。
这个神器的利器叫做:you-get,是一名华人程序员使用 python 3开发的,在 Github 上已经有接近6000 star, 你可以访问:You-Get 查看详细的使用说明。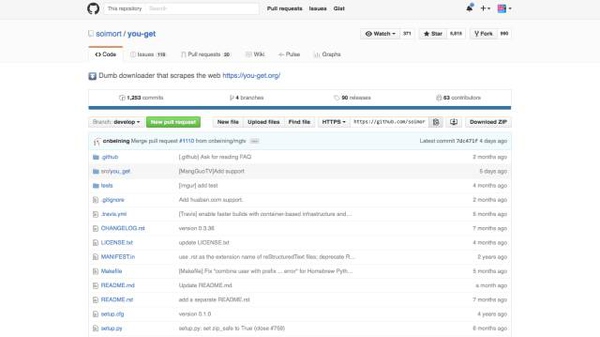
简单来说,使用分3步:
第一步:
你要安装好 Python 3环境,你应该早就安装了对不对!
第二步:
用 pip 安装 you-get
看过实战课程的同学应该对这个很熟悉了
在终端/命令行输入:pip 3 install you-get
第三步:
在终端/命令行输入you-get 加上你想下载的链接,比如:
$ you-get https://stallman.org/rms.jpg
然后伸个懒腰,就下载好啦~
快去帮女神下载美剧,帮基友下载动画吧!
虽然是利器,可能还是不能完全满足你的需求,比如说,如果你想分析热门视频的点赞量和发布时间的关系,这些字段是不包含在内的,还是需要自己写爬虫……
总之,编程是很强大的,能开发出高效的工具节省我们的时间。但如果想要完全按照自己的需求来定制的话,还是投资自己比较快,学好爬虫技能,能让获取信息不再受到阻碍。
—-
想看更多适合编程小白的优质文章,可以关注微信公众号「说人话的Python分享」:
编辑于 2016-05-13
joea.mao
白日梦未醒
免费的数据知道有这些获取方式:
上面的数据都可以申请试用通联-数据商城
如果用二级市场的数据可以用通联旗下的量化平台优矿网,上面通联的数据都是永久免费的,算是母公司对优矿项目的补贴
通联-量化实验室
调用方式如下以沪深股票日行情为例,先选一个API
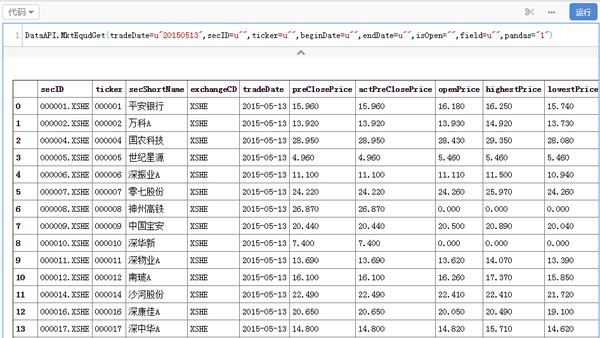
然后写一行代码:data.to_csv(u’spd_data.csv’),就可以把数据存在本地了。
另外还有TuShare -财经数据接口包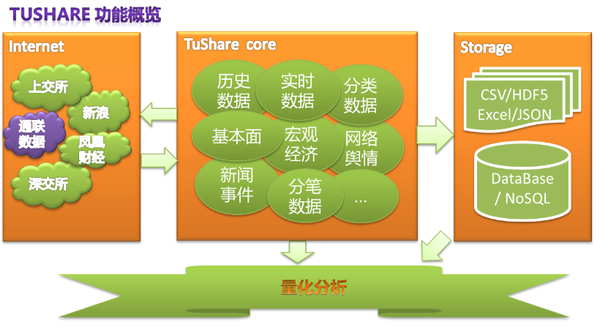
发布于 2016-09-19
杨阳
经济史、计量史学、经济学 话题的优秀回答者
收录于 编辑推荐 ·
Update:
我最烦伸手党,我最烦伸手党,我最烦伸手党。
重要的事情说三遍。
我帮别人抓数据主要基于三点,人情,合作,我看你顺眼。
同样我找别人要数据也遵循以上三点原则,是否有人情,是否能合作,如果都不能,是否能给个满意的价格。
直接在评论留QQ邮箱的请自重。
————————————————————————————————————————————
我来说说我的主要数据获取途径吧,不知道算不算「神奇」的获取方式。
- 人工录入。应该也是我所做的学科(量化历史)的主要获取手段吧。身在这个领域某大牛老师的门下,亲身领教了师门各位前辈师兄师姐录入数据的能力。比如从《清实录》,《万历会计录》等历史文献中寻找相应的变量,如清末进士资料,明代财政税收数据。这都是非常辛苦而且枯燥的工作,但是或许这也是这个领域有意思的地方之一吧。
附,《万历会计录》某页
- 网络过往数据爬取。算是我另一个重要获取手段。R或者Python爬虫,基本上可以做到所见即所得。虽然我不是职业的码农,但还是在这方面下了些功夫,比不上大牛,但是能满足自己需求就行。在忙完自己的事情空闲,也会帮同门的师兄弟抓一些感兴趣的数据,互通有无吧。
- 网络实时数据监控。其实算是一种没法获取过往数据的补救手段。很多网站的数据是具有时效性的,比如某招聘网站招聘数据,某二手房交易出租网站数据,某地污染实时监控数据,这些数据每过一段时间会失去时效性,因此必须让爬虫每隔一段时间,甚至实时去监控网站数据的改变,自己建立一套面板数据。我目前在监控的网站有10多个,都是比较有意思的数据。
- “特殊”漏洞渠道。我个人经常关注乌云,会对有关数据的漏洞敏感一些,有一些个人感觉“有意思”的数据,会在漏洞爆出的时候想办法获取。但是这些数据往往牵扯到对数据来源正当性的质疑,因此至今从未将其用于学术研究,只是个人感兴趣或者叫数据收集癖吧。前几天发现有个政府网站在后台挂了一套自己省的电子版县志,果断拿下。其他有意思的比如XX开房数据,五毛数据等等,总之先入手,说不定有用呢不是?
- 学术合作。有时候数据是靠“换”来的,我有你要的数据,你有我要的数据,那大家互通有无,或许可以推进学术合作,做出对你我都有意义的研究。这应该也是目前学术界普遍流行的模式。欢迎同样有数据收集爱好的同仁私信互通有无哈,如果各位学术界的前辈大佬有需要抓得数据也可以联系我哈,力所能及尽量帮忙。
- 众筹。没错,你别笑,就是众筹。比如这个,哈佛中国经济史大数据研究项目。请注意奖励部分。
研究简介
中国经济史大数据研究项目通过收集和电子化中国县志中数据,分析新中国成立至今(部分涉及民国年间)的社会经济发展。此研究旨在建立新中国成立后最完善的社会经济数据库,其数据涵盖中国近2000个县(市),时间跨度长达65年,包括120个变量。
谈古说今—中国社会经济分析大赛
作为中国经济史大数据研究项目的一部分,此次大赛主要有如下愿景:
1.通过数据分析和报告撰写,增进各高校学生对新中国成立后的社会经济改革和发展途径的了解,促进其对今日中国改革的思考。
2.筛选符合资质要求的优胜参赛者暑期赴哈佛协助研究,并邀请他们参加由哈佛经济学系Richard Freeman教授在NBER(NationalBureau
of Economic Research)举办的学术研讨会。
了解Freeman教授:Richard B. Freeman’s Home Page
3.为参赛者提供平台与世界知名的经济学家对话,了解中国和世界经济学界最新动态。
面向对象
本大赛面向所有在校或毕业大学生,专业、年龄、国籍不限。
比赛流程
1.在线申请
时间:3月18日-4月30日
团队申请:以团队(3-4人)名义申请,团队中须有一名成员作为负责人
个人申请:以个人名义申请,所有申请个人将被随机安排组成团队
2.培训
时间:定期在各高校为新加入参赛者举办
各高校负责人对所在高校的参赛者进行培训,培训内容包括:熟悉变量表,正确掌握重命名。
3.参赛任务:县志扫描文件的重命名
时间:提交时间不晚于5月10日
完成规定量的扫描数据重命名任务,并在完成后及时提交。
3人团队:30个县
4人团队:40个县
4.专题报告
时间:提交时间不晚于5月31日
提交第一阶段任务后,参赛团队在给定的若干题目中自主选题并提出数据申请(仅限参赛小组重命名的数据),完成一篇区域经济发展分析报告。
注意:参赛小组需要在40天内完成重命名和报告(重命名后的数据录入时间一般在一周之内,不计入参赛团队总时间),团队自行分配时间(即:如果15天完成重命名任务并提交,在获得反馈的数据后,参赛团队需要在25天内完成报告并提交)
评分标准
是否完成规定量的重命名任务:通过/不通过(不通过则取消参赛资格)
重命名的完成质量:评分制
报告质量:评分制(组委会将反馈意见与建议)
参赛时间
参数团队的所有数据处理需要于5月10日前提交,报告于5月31日前提交。
获胜奖励
1.所有参赛者(除任务未完成不通过者)都将获得参赛证明,优胜者将得到Richard Freeman亲笔签名出版物。
2.杰出的参赛小组将在暑期受邀赴美,参加Richard Freeman教授在NBER举办的学术研讨会,并在哈佛大学参与进一步研究工作。
虽然我对这个“获胜奖励”表示呵呵,但是这确实是个不错的想法。如果组织方在赛后会公布数据的话,我要恬不知耻的说:
大神数据分享给我一份吧我给您跪下了。
编辑于 2015-07-16
挖数
移动互联网数据挖掘从业者,行业观察者
有兴趣学习爬虫的童鞋可以穿越到
如何入门 Python 爬虫? - 挖数的回答
———————-分割线
互联网数据分析从业者来答。
学会写爬虫,整个互联网就是你的数据库,爬虫可以自动化地,大批量地帮你将互联网上大量无规则数据爬取下来并归整。
比如用爬虫爬取智联招聘上所有心仪的职位,并对职位描述做词频分析,从而了解该岗位的核心技能要求是什么。
- 爬取智联招聘上深圳地区所有数据挖掘的职位,共608个


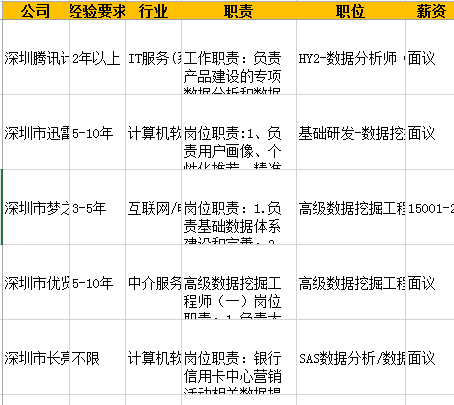
对职位描述做词频分析,用字体大小代表职位覆盖数量
2. 爬取艺恩网上所有华语电影的票房数据,并做成散点图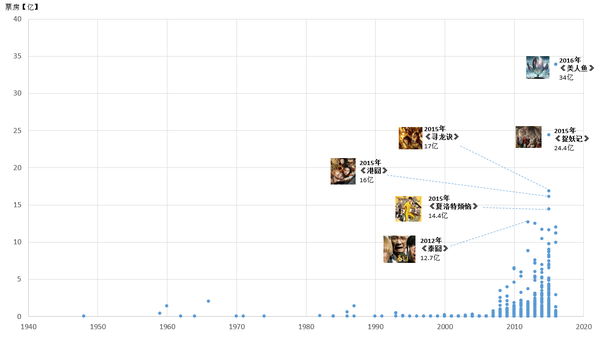
3. 爬取Mtime时光网上所有香港电影的海报,按时间线做成海报墙,展示从1960年到现在香港电影海报风格的变化
初次接触爬虫,是为了学Python,作为一个数据分析师,不会一门开源的编程语言实在说不过去,作为一个数据收集癖,爬虫自然是当仁不让的学习Python的切入点,而我第一个爬取的对象,是糗事百科。
看到这坨便便真的十分有亲切感
当时还不会用BeautifulSoup,只是学了用urllib的简单循环爬取,爬取了热门笑话的前10页并用txt保存。看到刷刷刷的几秒,我的文件夹多了一个写满几百个笑话的txt文件,我的表情是这样的
爬完糗百,然后是豆瓣的电影排名,然后是爬搜房网的二手房信息,接着是学Scrapy,然后是爬JS,一步一步。
爬虫的神奇之处,除了获取data的方便快速外,还在于他的自动化。
- 你可以设置定时爬虫任务,每天爬取招聘网站上新更新的公司及职位并对已爬取的职位进行排重,然后每天回到家看到电脑屏幕上显示
今天深圳地区新增15个数据分析职位及8家招聘单位,然后下面显示详细信息
相较之下,别人找工作是不是low爆了?
- 你可以爬取每天微博上的信息,用Python的分词模块进行分词,每天统计微博上出现最多的词语,这样你可以比别人更早知道最近流行的网络用语,或者是一些舆论热点。
- 你可以爬取网上或者QQ群里的各种表情包,这样跟别人斗图再也不怕弹药不足了。
- 你还能爬取Mtime时光网上热门电影的影评,比如《美人鱼》有20000+条影评,进行分词后统计出每部电影的标签,然后把这些标签化的电影数据库卖给电影舆情公司,捞一笔。
评论区有童鞋在问文科生学爬虫难么,以及怎么学的问题。我的回答是不难,Python就是给文科生学的编程语言(大神轻喷,我知道Python是易学难精)。Python的伪代码式的语句,可以让你像看文言文一样,只要稍加联想就能看懂,Python语句的简洁与高效,可以让你在刚学1天就做出一个爬虫的Demo,让你有神器在手,天下我有的感觉。
举个栗子,把天涯社区首页上的所有新闻标题爬下来并展示在屏幕上,比如这样
只需要短短的15行语句,如下
import urllib
import urllib2
import re
import pandas as pd
a=[]
url=’天涯聚焦_天涯社区‘
request=urllib2.Request(url)
response=urllib2.urlopen(request)
content=response.read().decode(‘utf-8’)
pattern=re.compile(‘
.?title=”(.?)”.?title” >’,re.S)
items=re.findall(pattern,content)
for item in items:
a.append(item)
b=pd.DataFrame(a)
print b
首先是引入需要的模块,urllib和urllib2是连接网络请求数据用的,re是正则表达式用于提取特定的文本,pandas用于将数据用表格的形式规范地展现;
接着定义一个空的队列,用于装入爬取的新闻标题,然后请求天涯的网页链接,将请求到的网页信息用utf-8解码,接着用正则表达式提取需要的新闻标题;
最后用循环的方式把提取到的新闻标题挨个装入队列,转换成表格形式并展现。
如果用requests模块代替urllib还可以缩短到12行左右,是不是很简洁?
最后,请关注我哦,我会好好维护你的时间线的 ( ^ v ^ )/*
编辑于 2016-06-16

chym
天下为公
读博士,做实验,数据很重要。
我之前读博的时候,亲身经历的和听说的,有不少跟收集数据有关的趣事:
1. 为了抓数据,写了一个简单的爬虫程序,为了快,速率调太高,结果搞得全系ip被某知名资料网站封了好几天。。。系里别人还以为那个网站挂了呢。
2. 还是用爬虫程序,把某个研究机构内隐藏很深的A片也下载下来了。当晚我去察看收来的数据,花费了很长时间。。。
3. 某知名教授让我帮他预处理一些图片,我说这个怎么搞?他说我有一个好东西,然后就发给我了一份盗版的ACDSee。。。我才知道原来美国教授也用盗版软件。
4. 还是该教授,为了收集不同蚊子的叫声及其频率,依然在计算机实验室内养蚊子。一个大玻璃箱矗立在若干计算机当中。我严重怀疑他收集到的嗡嗡声是蚊子的还是电脑的。当然他们组的学生没少被咬,而且包的种类繁多,令人眼花缭乱。
5. 某实验室给我们的数据解密密码是FXXX,当时就惊呆了。对方马上解释,他们的密码格式其实是AXXX,BXXX,CXXX……
另外再补充一个我在linkedin工作后遇到的收集数据的趣事,这个我在其它回答提过。
http://www.zhihu.com/question/29431605/answer/44390542…
我们组之前在ingest http://lynda.com上的课程的data。他们给我们提供了api,但是根本不好用。
然后一天我们在上厕所时还在抱怨此事。突然,身后传来马桶冲水的声音,俺们的CEO从某个单间里大咧咧地走了出来,冲我们呵呵了一下。(因为我们和CEO在同一楼层,所以经常能在厕所碰见。)
他这可真是微微一笑,深藏功与名啊:没过几天他就宣布,Linkedin收购Lynda了。
我们再也不用担心data问题了,吼吼…
编辑于 2015-07-16

最爱麦丽素
不忘初心~充实就好~
一天吃完饭出去散步,周围的小房子不少有开始翻修了,有的直接准备起了6层楼。哎?突然产生一个疑问,怎么这么统一?都这个时候修?春季温度上升终于可一开始搅拌水泥而不必担心被冻住?而且可以一直持续到深秋?这是一个我能想到的最合理的解释。那么为什么同一个星期或者有的就在同一天就开始了呢?我觉得有一种冥冥之中的力量在推动他们~~
据说有钱的土豪都很迷信风水,也很迷信黄道吉日,没准就是看了今天适合动土就选了今天了。老一辈看阴历,年轻人看阳历,都选在5月20号结婚也可以支持这一心理选择偏差。
来吧,找点数据统计下看看先。
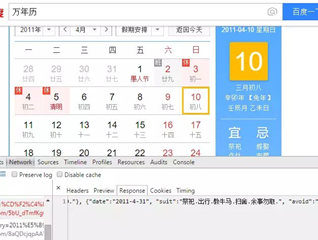
恩,百度的万年历
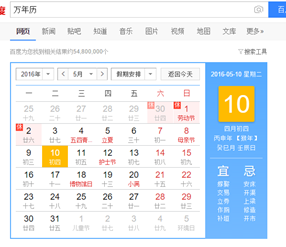
每天的禁忌还蛮多的, 虽然我完全不知道什么意思。
找到API准备爬数据,精简之后的地址如下,其中query=urllib.parse.quota(“yyyy年mm月”),感兴趣的同学大可以去爬一爬。
https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=2016%E5%B9%B46%E6%9C%88&resource_id=6018…
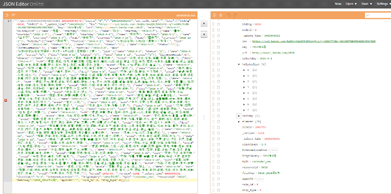
百度只有2008年倒2020年的吉凶计算,大概是为了存储空间吧,也可能是按计划存储执行的任务,13年的数据算周期是够了。但是我发现了个秘密。百度家2012年以前没有大小月之分,在api里随处可见这种异常。大概是他们的程序员觉得这样方便hash?行吧,将就用吧~
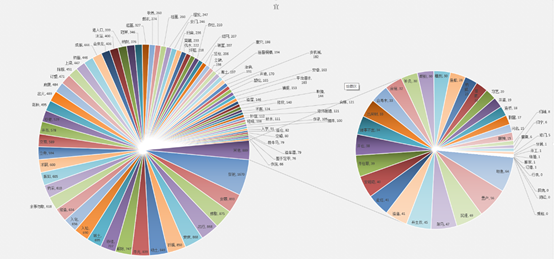
首先两张全部分类的统计数据,一共118个分类简直桑心病狂,吉凶的差集还不为空,看着如此符合古代生活作息的分布规律,我隐隐感觉到了其中的一些端倪。
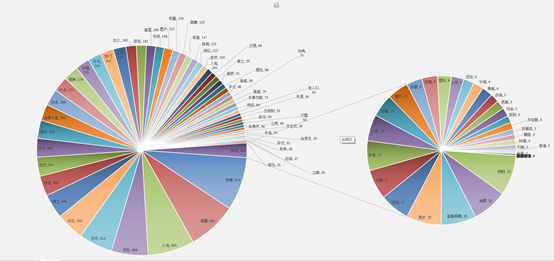
取其中8年的数据,按每天吉凶类别数量画出时间序列:
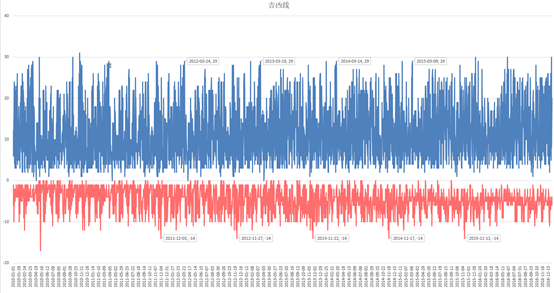
看到了期中几个周期性的极大值和极小值,貌似很规律的样子,来做一下自相关
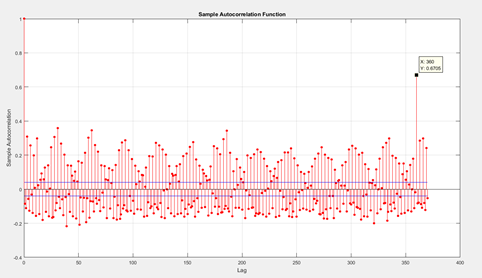
果然,不仅360作为一个大周期,还有31天的小周期,随机和混沌是肯定有的,做一下以360为长度的差分计算:
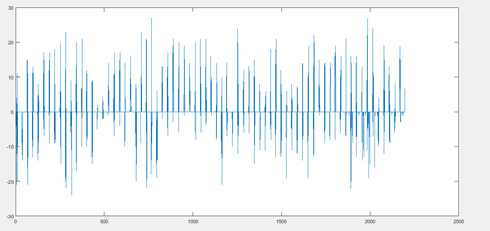
也就是说,你会发现某月某日是个大吉的日子,次月该日又是一个大吉的日子。
以下是自然月对应的事件吉凶比,貌似五月,十一月还是个挺吉利的月份,明明是忙种和收货的日子,所以是希望这段时间不论你做什么都会给你释放积极信号么。
那么看一下我们最初的问题,是不是对于某一个事件,在某个时间段更适合执行呢?
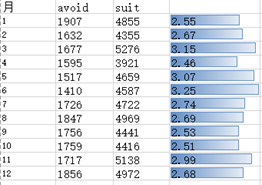
找出最热的吉凶事件[入宅,出行,嫁娶,安葬,开市,祭祀]。
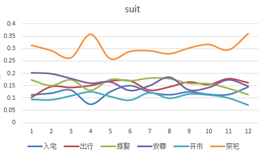
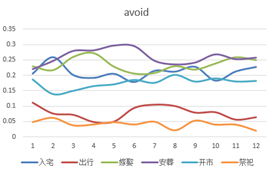
祭祀在4月和12月分别出现了极值,分别是清明和元旦所处的日期。
而星期则没有任何周期现象存在
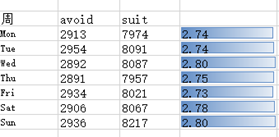
星期制从唐代波斯才开始引进中国,在农历开始时还没有星期这个概念,没有这种周期现象也就并不奇怪了。
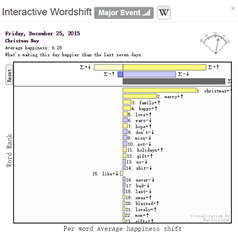
是不是古时,统治阶级为了普及知识,又迫于底层民众的愚昧,动过天干地支太极八卦对每天应该做的事情进行编码,最后聚合成一种策略,也不失为一种好的管理方式。例如年用60个天干地支表示,月日分别用一个卦相表示,可以组成14位2进制编码,一共可以出现2^14次方也就是约4096种组合,然后hash到每一天的事件上,然后就成了黄历。如果这种激励制适合古代,那么黄历适合现代社会嘛? The MITRE Corporation有一个研究Twitter的项目,通过每条推文的分词来计算当天的幸福指数
选取09年到16年的数据。
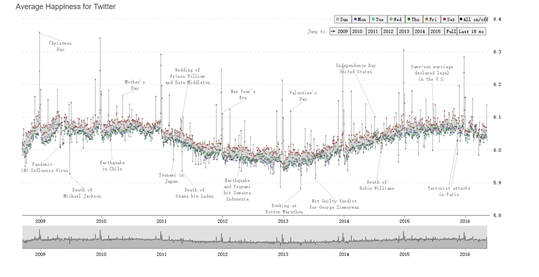
周五和周六要比平常更加幸福,而且并没有季节性波动,现代已经脱离了农耕社会。黄历需要改进啊。
同时,这些数据已经整理好了,需要的同学可以发私信给我,数据打包给你,好了,就这样吧。
欢迎各类奇葩怪咖加微信FavorMylikes,嘻~~~

编辑于 2016-08-07

西子宜
视频/电商行业从业者/社会化营销探索者
说两个行业情况:
1、高德地图的路况数据是人工浏览交管网站更新;
2、大众点评的冷门店铺数据是网络抓取的;
有时候你觉得理所当然的数据获取方式,反而是用更土鳖的方式获取的。
发布于 2015-07-15

李洋
faruto不知何许人也~
有钱任性就买;没钱就爬。
金融数据
see
http://faruto.matlabsky.com/FQuantToolBoxHelpOnLine/…
发布于 2015-07-15

廖正文
铁路 话题的优秀回答者
数车。
美其名曰断面交通量调查。
每年在四道口那个十字路口看见一群人口中念念有词,一手拿笔对着马路上的车指指点点,一手拿着手机掐秒表,就知道交大运输组织学的课讲到了信号控制那一章。。。
编辑于 2017-01-01

Ryan Fan
国内的:
数据圈论坛-国内第一家数据资源现金交易平台,淘数据,数据换钱,来数据圈吧!
数据堂:国内首家大数据共享交易平台
国外的:
Kaggle
UCI
编辑于 2015-07-21
匿名用户
说不上神奇但知道的人不多。
理性人
面向投资者的数据网站。
目前免费,注意,进入网站介绍后,左右两边是能点的。能看到如下这种图。
很良心,操作简单,对于一般投资者很方便,也基本够用了。
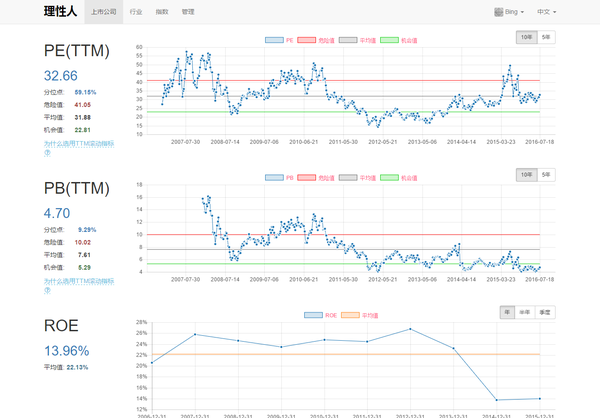
数据 - JoinQuant
其实是个面向个人的量化交易平台,主要是做量化交易的。但是是能免费下载数据的,质量还比较好,比如复权价等比市面上大众常用软件显示的都准。
这是个量化交易平台所以,需要编程调用,可能有一点门槛,不过会编程的话就很方便,操作很自由,数据规整可以在线处理成自己想要的样子。
发布于 2016-09-01

何明科
创业、互联网、投资 话题的优秀回答者
看到这个问题不得不来答一下,因为我们这个项目(用数据化的方式解析投资条款(预告片) - 数据冰山 - 知乎专栏)收集数据和处理数据的方式是在太神奇或者太奇葩了。
应老大的要求,想要对这几年中国尽可能多的私募案例(VC+PE投资)进行研究,一方面寻找投资条款的变化趋势;另一方面可以为创业者提供借鉴,各种价格或者IRR的平均值或者方差,方便创业者评估投资条款是否公平。这算法和建模没啥难度,可是收集原始数据以及处理数据这可就要了命,下面详细分解。
收集数据
要想得到详细的投资条款,必然需要拿到完整的投资Termsheet或者投资协议,这一般来说都是创业公司或者基金的绝密材料(因为涉及到诸多敏感信息,每一方的股权比例和价格写得一清二楚能不敏感吗?),不会轻易外传。于是我们几个小弟就开始了漫长的损人品的挨个求人过程,逐个敲门找到获得过融资的创业者或者投资人,在受到无数的冷屁股及打击之后,矢志不渝得获得了几百份投资协议。同时,许多协议为了保护提供人的敏感信息,还要求对方在提供之前把敏感信息用“XXX”替代,为对方增加了许多工作量,于是就要再次厚颜无耻得不断询问对方处理得怎么样了,什么时候能提供。
处理数据
投资合同一般都是几十页以上,而且许多是英文,下图给大家一个直观印象,每一个小方块都是一页word,下图的文件大概有60多页。

另外法律文件为了严谨,文字描述冗长和复杂(简单说,就是不说人话),下面的语也给大家一个直观印象。
At any time and from time to time after [fifth anniversary of the Closing Date] and if the Qualified Event (as defined below) has not occurred, within ten (10) days (the “Redemption Date”) after the receipt by the Company of a written request from the holders of not less than a majority of the then outstanding Series A Preferred Shares, the Company shall redeem all of the then outstanding Series A Preferred Shares by paying in cash in exchange for the Series A Preferred Shares to be redeemed an amount per share equal to the sum of (x) the Purchase Price plus an IRR of 15% for the period from the issuance date of the Series A Preferred Shares to the Redemption Date, and (B) an amount equal to all cumulative dividends with respect to the Series A Preferred Shares to the Redemption Date which have not been declared and paid (the “Redemption Amount”), proportionally adjusted for Recapitalizations. For the purpose of this Section 6, the “Qualified Event” shall occur if (i) the Common Shares are listed on the XXX Stock Exchange (or successor senior board of the XXX) or other exchange approved by a majority of holders of the Series A Preferred Shares (a “Senior Exchange”), and (ii) the entire market capitalization of the Company is more than $xxx million in any consecutive 30-trading-day period.
读完这些英文,不知道有多少人还没有晕,是不是堪比GRE阅读。
因为这些投资条款的内容实在太专业了,只能找到并说服资深法律或者投资人士(这些人都是很贵而且很不愿意做这种运营级别的活儿)帮忙逐个文件逐个条款阅读,将这些投资条款结构化并录入到数据库。目前我们已经整理完100多个投资文件,还有100多个等待被整理中。
呈现数据
正是因为有了上面的“神奇”工作,才有了下面炫目的图表以及有价值的信息。
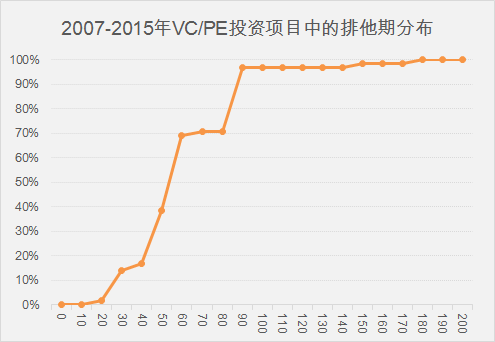
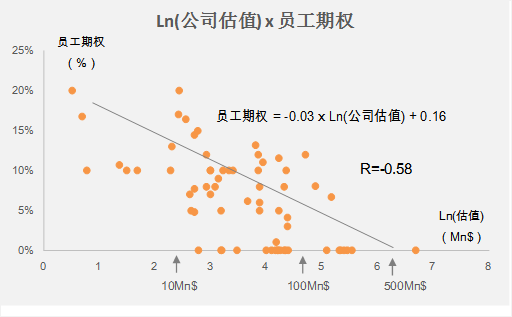
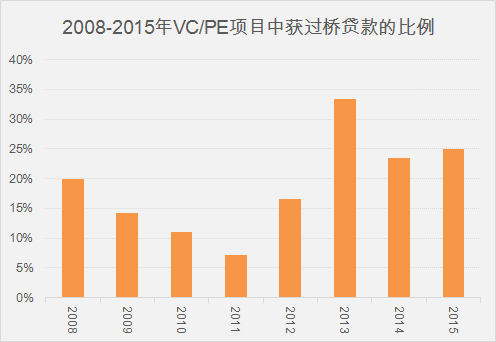
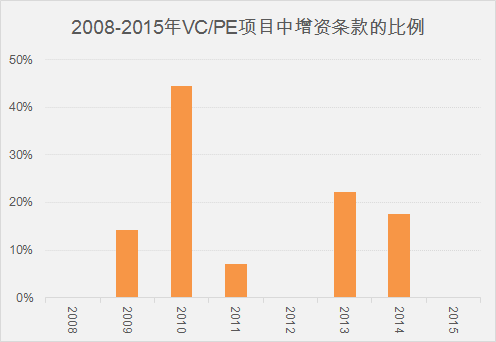
我们的文章已经发布了三期,持续更新中,欢迎大家关注以及给与指导。
用数据化的方式解析投资条款之一:员工期权 - 数据冰山 - 知乎专栏
用数据化的方式解析投资条款之二:过桥贷款 - 数据冰山 - 知乎专栏
用数据化的方式解析投资条款之三:增资权warrant - 数据冰山 - 知乎专栏
编辑于 2015-07-14

中天
电气工程学渣/手机爱好者
有一个叫做《为盲胞读书》的APP,它给你推送一条文字消息,你发一条语音回去,这样就实现了为盲人读书。这些文字和语音是一一对应的,这就是大量的语音数据,是训练语音识别软件的宝贵资料。
已使用 Microsoft OneNote 2016 创建。
据说有钱的土豪都很迷信风水,也很迷信黄道吉日,没准就是看了今天适合动土就选了今天了。老一辈看阴历,年轻人看阳历,都选在5月20号结婚也可以支持这一心理选择偏差。
来吧,找点数据统计下看看先。
恩,百度的万年历
每天的禁忌还蛮多的, 虽然我完全不知道什么意思。
找到API准备爬数据,精简之后的地址如下,其中query=urllib.parse.quota(“yyyy年mm月”),感兴趣的同学大可以去爬一爬。
https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=2016%E5%B9%B46%E6%9C%88&resource_id=6018…
百度只有2008年倒2020年的吉凶计算,大概是为了存储空间吧,也可能是按计划存储执行的任务,13年的数据算周期是够了。但是我发现了个秘密。百度家2012年以前没有大小月之分,在api里随处可见这种异常。大概是他们的程序员觉得这样方便hash?行吧,将就用吧

若有收获,就点个赞吧
0 人点赞

{kind=link}