[01].项目源码
- 新建一个
java项目
01.WordCountReduce
import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;/** KEYIN:reduse输入key(是一个单词Text)* VALUEIN:reduse输入value(是单词的次数IntWritable)* KEYOUT:reduse输出的key(一个单词Text)* VALUEOUT:reduse输出的value(单词次数IntWritable)*/public class WordCountReduce extends Reducer<Text, IntWritable, Text,IntWritable> {private IntWritable outValue = new IntWritable();/** {key,{1,1,1,1,1}}* 这里的数据已经被suffer过了!* {thoughts,{1,1}}*/@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0 ;for(IntWritable value:values) {sum+=value.get();}outValue.set(sum);context.write(key, outValue);}}
02.WordCountMapper
import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;/** KEYIN:默认已经拿到的key(行首的偏移量:LongWritable(相当于java的long类型))** VALUEIN:默认分片好的内容(Text类型(相当于string))** KEYOUT:输出的key(Text类型)** VALUEOUT:输出的value(都是1,记作{"word",1},数字类型IntWritable(int))*/public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private Text outKey = new Text();private IntWritable intValue = new IntWritable();@Overrideprotected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException {String wordArr[] = value.toString().split("[^a-zA-Z]+");for(String word:wordArr) {outKey.set(word);intValue.set(1);context.write(outKey, intValue);}}}
03.WordCountDriver
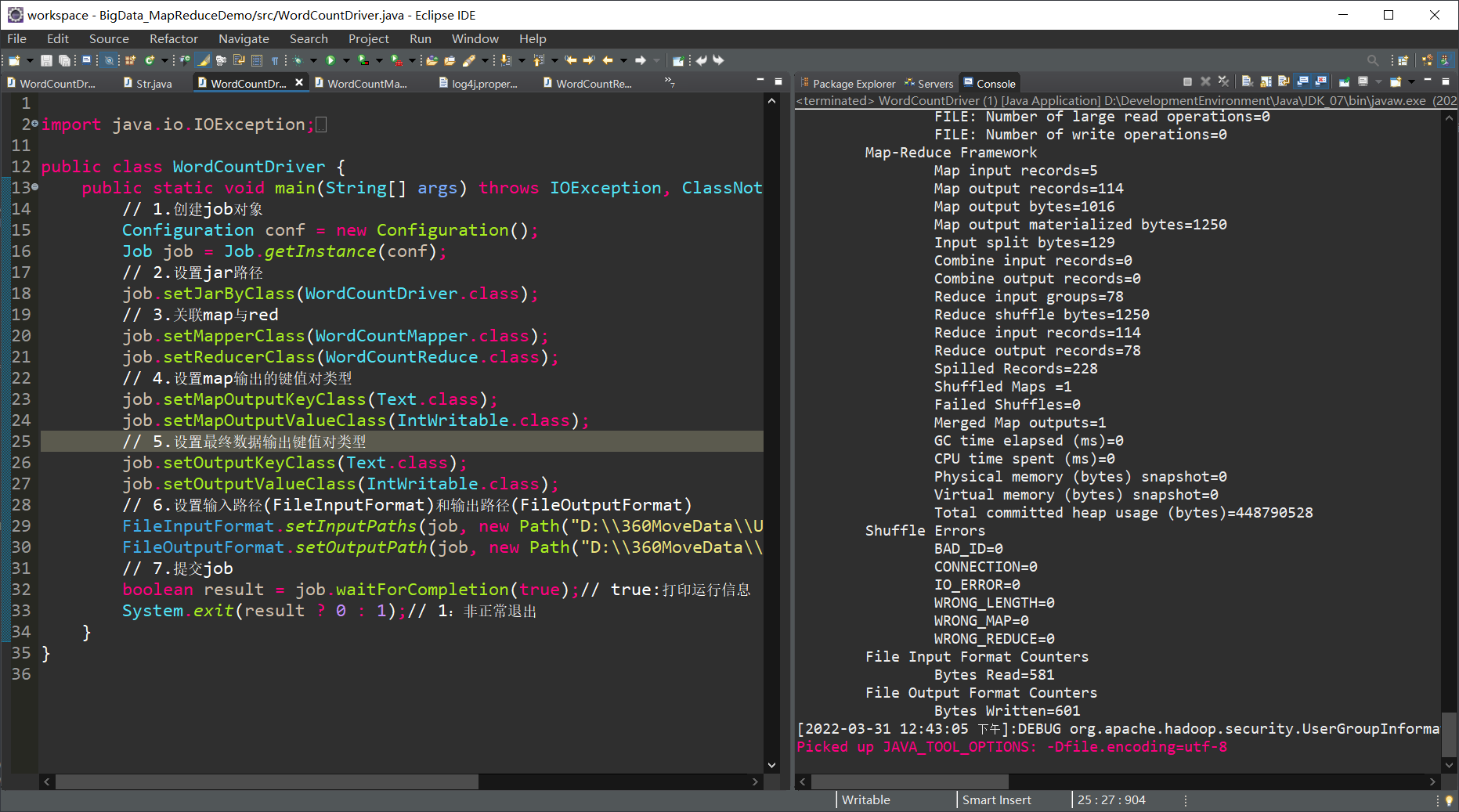
import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1.创建job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2.设置jar路径job.setJarByClass(WordCountDriver.class);// 3.关联map与redjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReduce.class);// 4.设置map输出的键值对类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5.设置最终数据输出键值对类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6.设置输入路径(FileInputFormat)和输出路径(FileOutputFormat)FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7.提交jobboolean result = job.waitForCompletion(true);// true:打印运行信息System.exit(result ? 0 : 1);// 1:非正常退出}}
本地测试的版本
// 6.设置输入路径(FileInputFormat)和输出路径(FileOutputFormat)FileInputFormat.setInputPaths(job, new Path("D:\\360MoveData\\Users\\AIGameJXB\\Desktop\\Hadoop\\JavaProjectBigData\\src\\cn\\aigamejxb\\hadoop\\mapreduce\\input"));//输出路径必须是不存在的路径,否则如果它发现存在该目录,那么就直接停止FileOutputFormat.setOutputPath(job, new Path("D:\\360MoveData\\Users\\AIGameJXB\\Desktop\\Hadoop\\JavaProjectBigData\\src\\cn\\aigamejxb\\hadoop\\mapreduce\\output"));// 7.提交jobboolean result = job.waitForCompletion(true);//true:打印运行信息System.exit(result?0:1);//1:非正常退出
04.
log4j.properties# priority :debug<info<warn<error #you cannot specify every priority with different file for log4j log4j.rootLogger=debug,stdout,info,debug,warn,error #console log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern= [%d{yyyy-MM-dd HH:mm:ss a}]:%p %l%m%n #info log log4j.logger.info=info log4j.appender.info=org.apache.log4j.DailyRollingFileAppender log4j.appender.info.DatePattern='_'yyyy-MM-dd'.log' log4j.appender.info.File=./log/info.log log4j.appender.info.Append=true log4j.appender.info.Threshold=INFO log4j.appender.info.layout=org.apache.log4j.PatternLayout log4j.appender.info.layout.ConversionPattern=%m%n #debug log log4j.logger.debug=debug log4j.appender.debug=org.apache.log4j.DailyRollingFileAppender log4j.appender.debug.DatePattern='_'yyyy-MM-dd'.log' log4j.appender.debug.File=./log/debug.log log4j.appender.debug.Append=true log4j.appender.debug.Threshold=DEBUG log4j.appender.debug.layout=org.apache.log4j.PatternLayout log4j.appender.debug.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss a} [Thread: %t][ Class:%c >> Method: %l ]%n%p:%m%n #warn log log4j.logger.warn=warn log4j.appender.warn=org.apache.log4j.DailyRollingFileAppender log4j.appender.warn.DatePattern='_'yyyy-MM-dd'.log' log4j.appender.warn.File=./log/warn.log log4j.appender.warn.Append=true log4j.appender.warn.Threshold=WARN log4j.appender.warn.layout=org.apache.log4j.PatternLayout log4j.appender.warn.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss a} [Thread: %t][ Class:%c >> Method: %l ]%n%p:%m%n #error log4j.logger.error=error log4j.appender.error = org.apache.log4j.DailyRollingFileAppender log4j.appender.error.DatePattern='_'yyyy-MM-dd'.log' log4j.appender.error.File = ./log/error.log log4j.appender.error.Append = true log4j.appender.error.Threshold = ERROR log4j.appender.error.layout = org.apache.log4j.PatternLayout log4j.appender.error.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss a} [Thread: %t][ Class:%c >> Method: %l ]%n%p:%m%n05.
words.txt文本文件这是我在网上搜的小学生英语作文。。。
lt was a fine day today. We went to visit the Yakult Milk Factory. At nine o’ clock we all meet at the playground. We went there by school bus. When wegot there, we watched a short cartoon. lt is the introduction of the Yakult milk.And we also drank a bottle of Yakult milk too. It isso delicious. After that they showed us around the workshops. It is so clean and quiet.Mostof them are machines. There are a few workers in this factory. It is the first time for me to see such a mechanicalfactory. At noon, we went to the MacDonald' s for lunch.Today was a happy day for me.[02].环境准备
(主节点)安装一个小工具
yum -y install lrzsz #方便使用拖拽方式上传文件(一会上传words.txt)启动hadoop
[root@master ~]# cd /opt/hadoop-2.6.0/sbin/ [root@master sbin]# ./start-all.sh创建一个文件
hadoop fs -mkdir /wordcount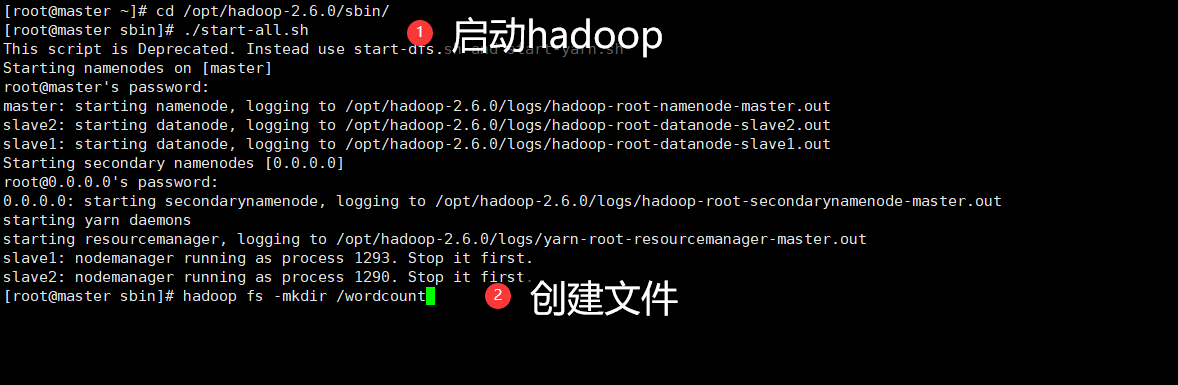
拷贝单词文件
- 把文件拖进去
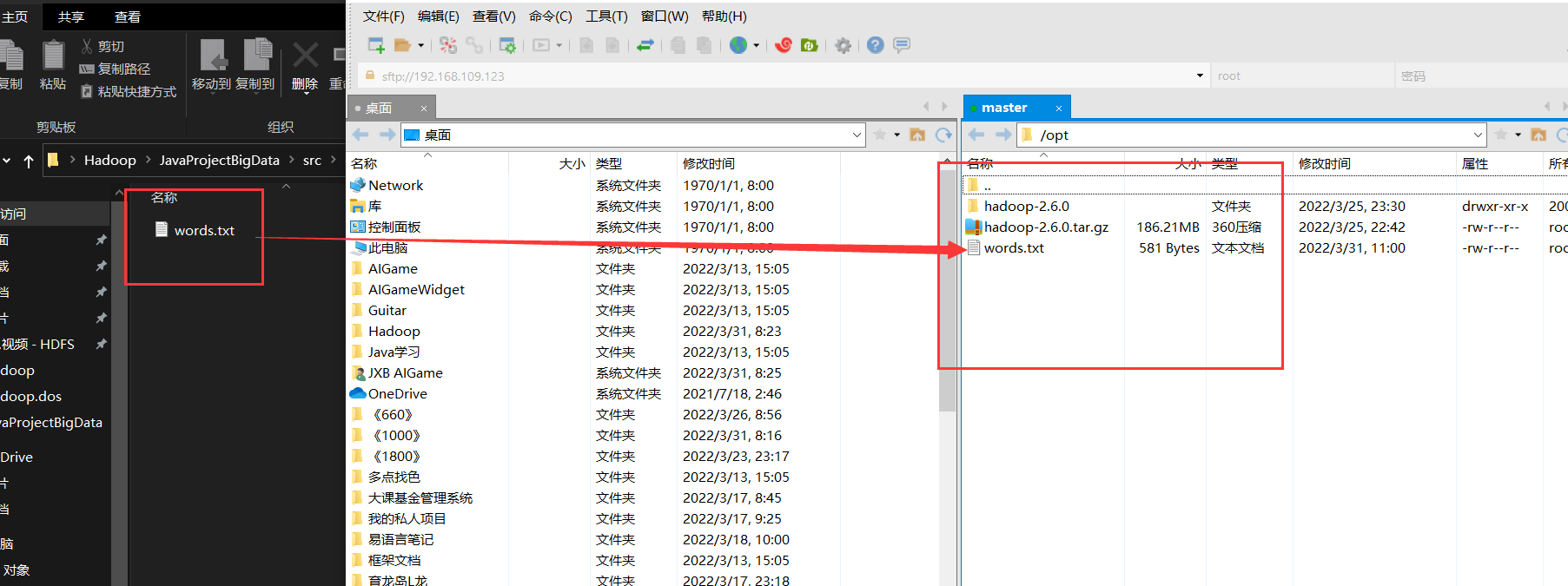
上传到hadoop
hadoop fs -copyFromLocal ./words.txt /wordcount
访问后台,证明上传成功
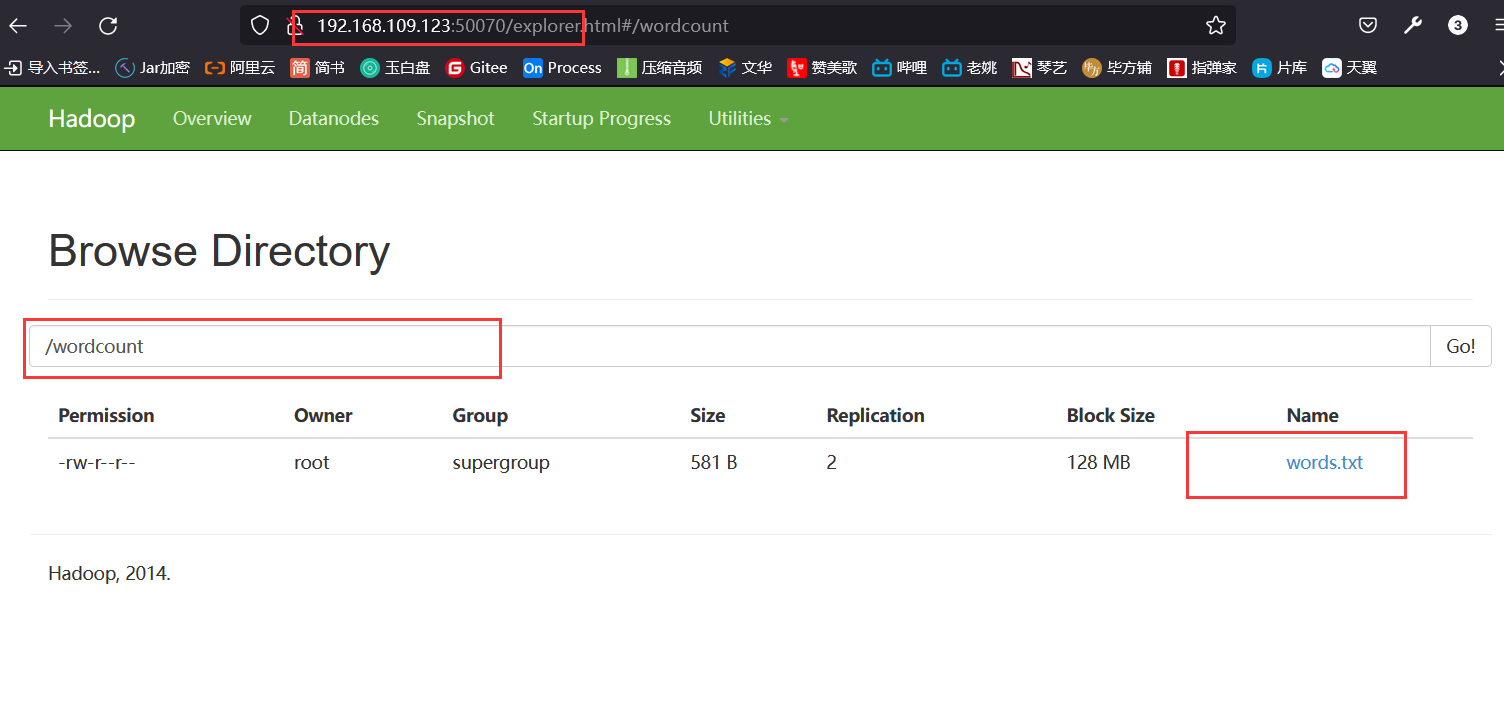
[03].打jar包
- 右键项目
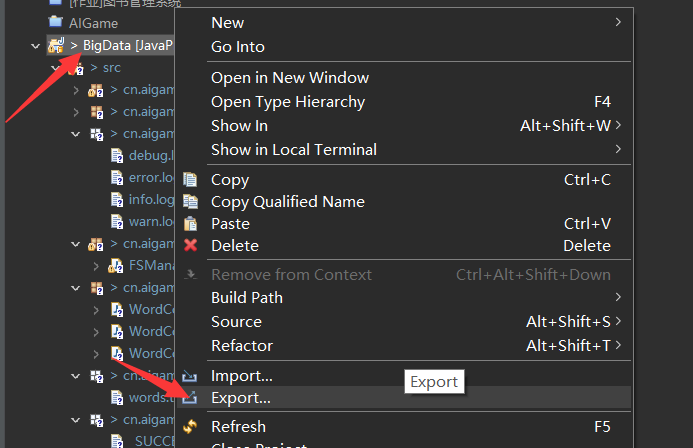
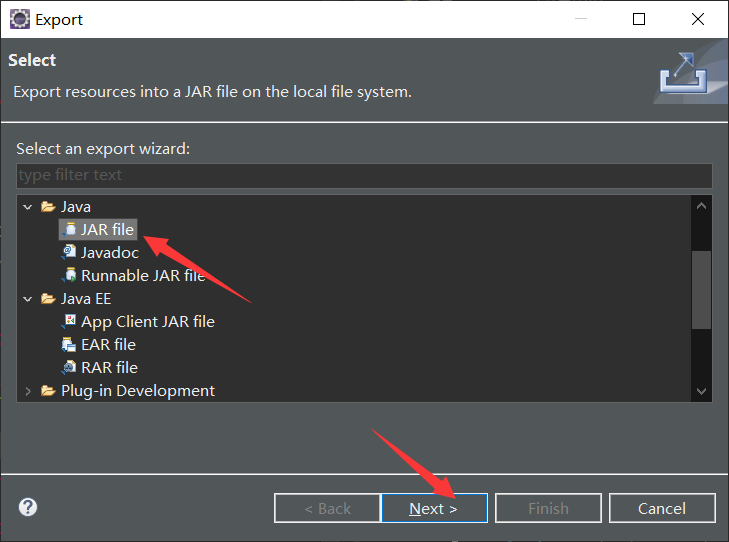
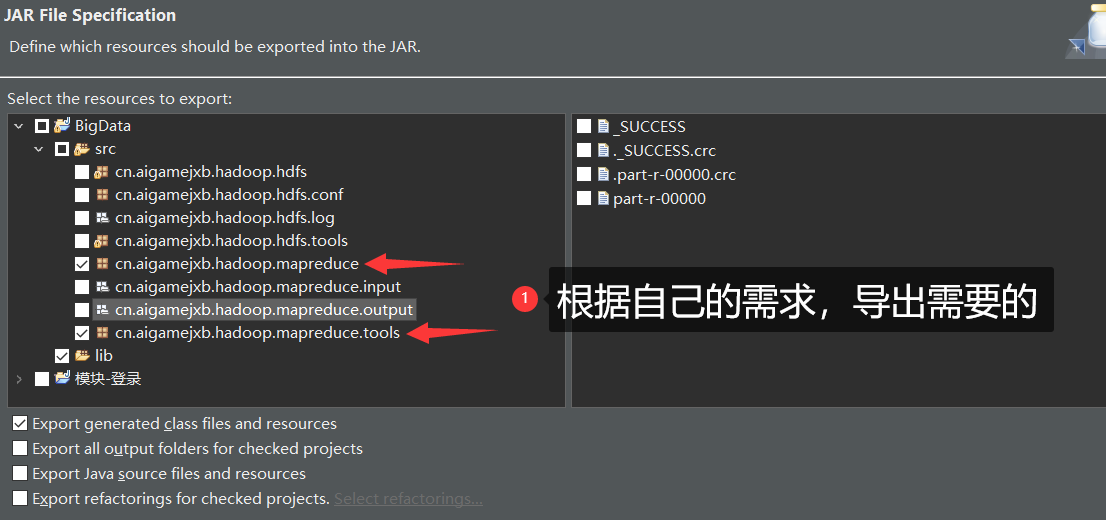
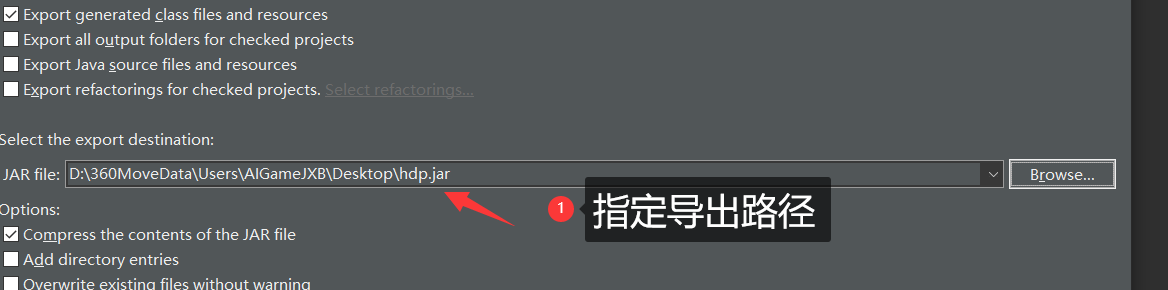
- 直接下一步(默认)
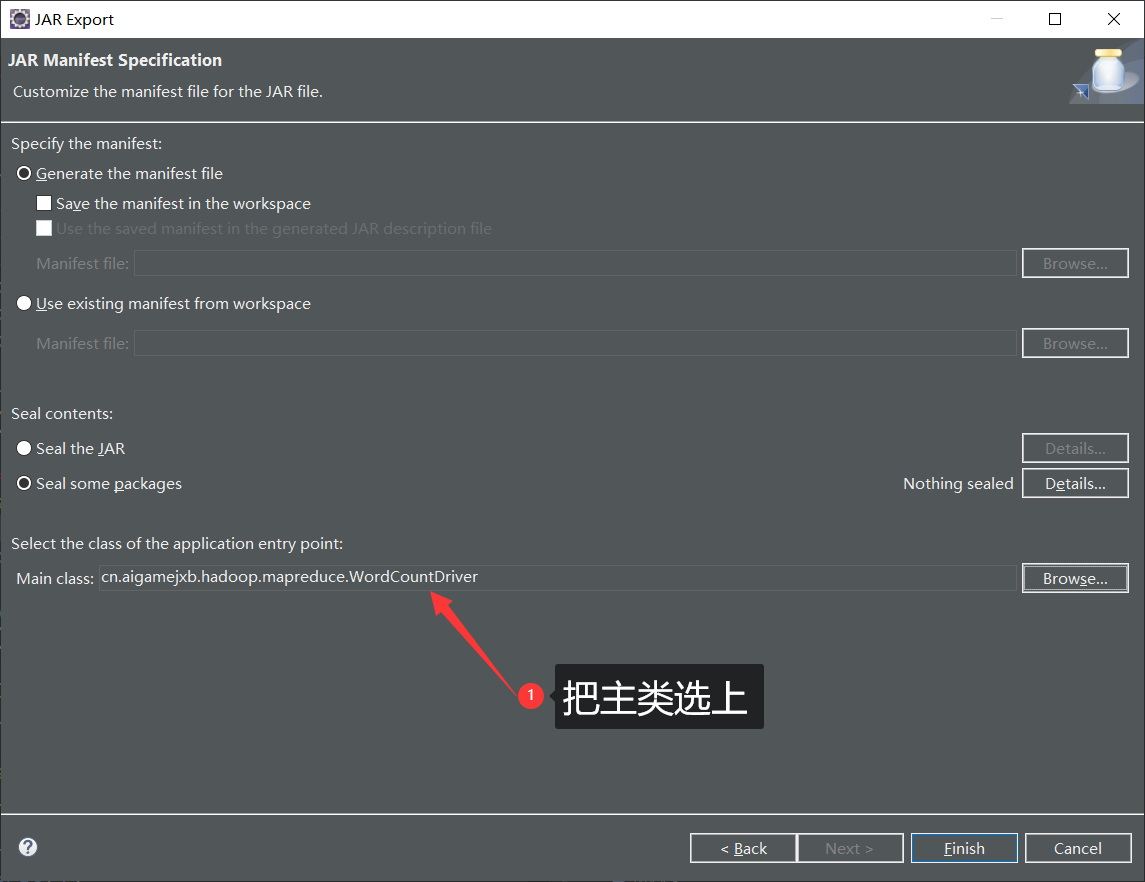
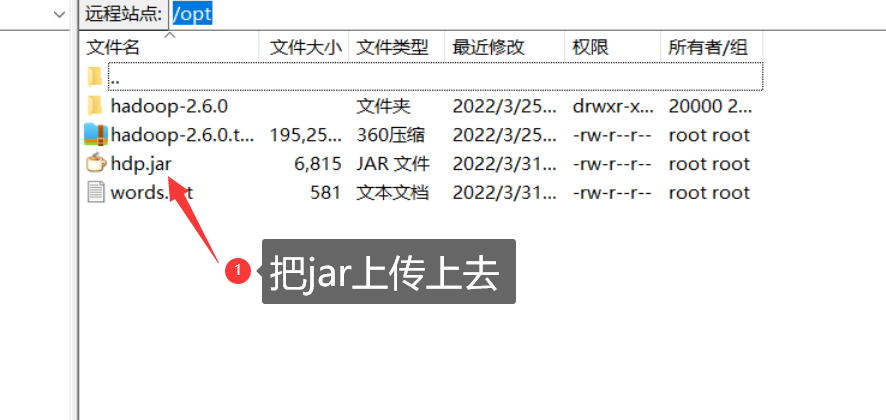
- 打包完后上传jar包
[04].测试运行
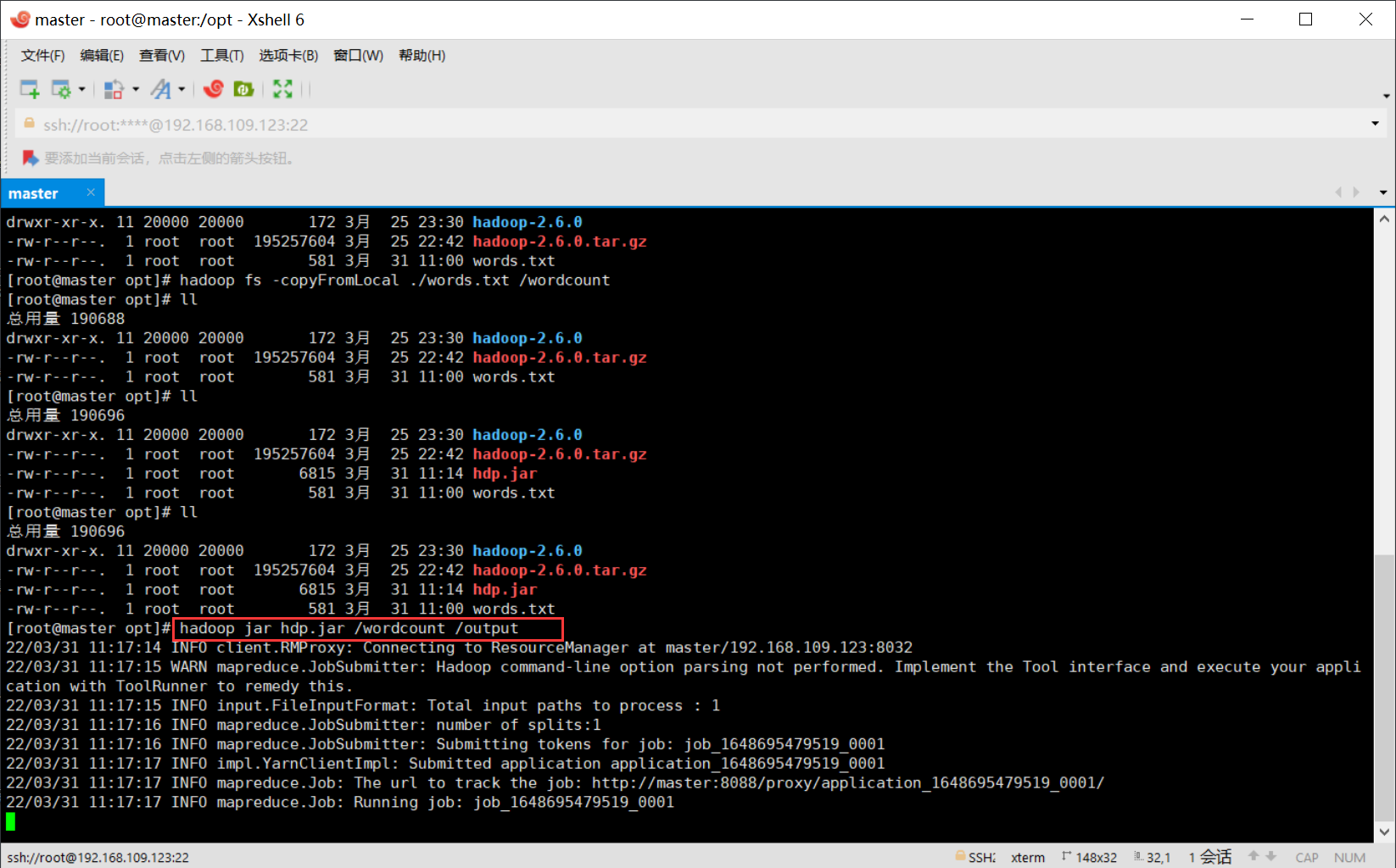
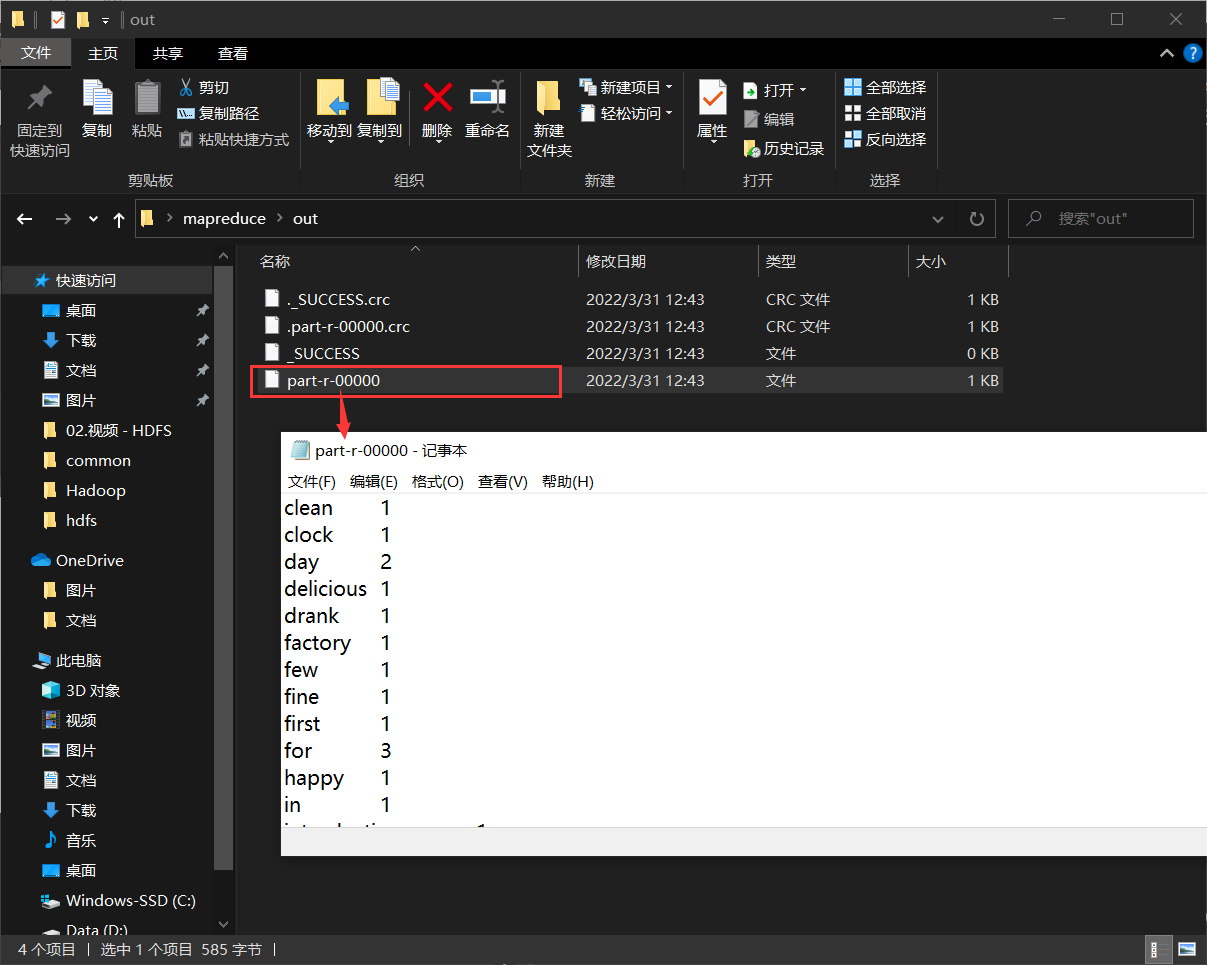
01.本地测试
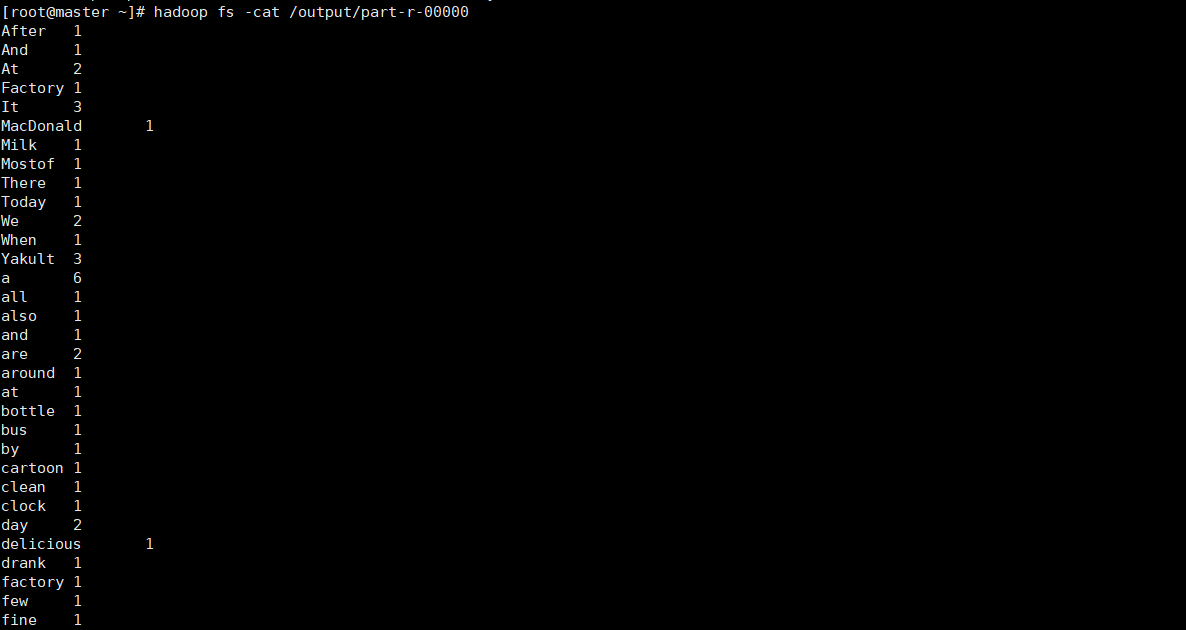
02.Hadoop测试
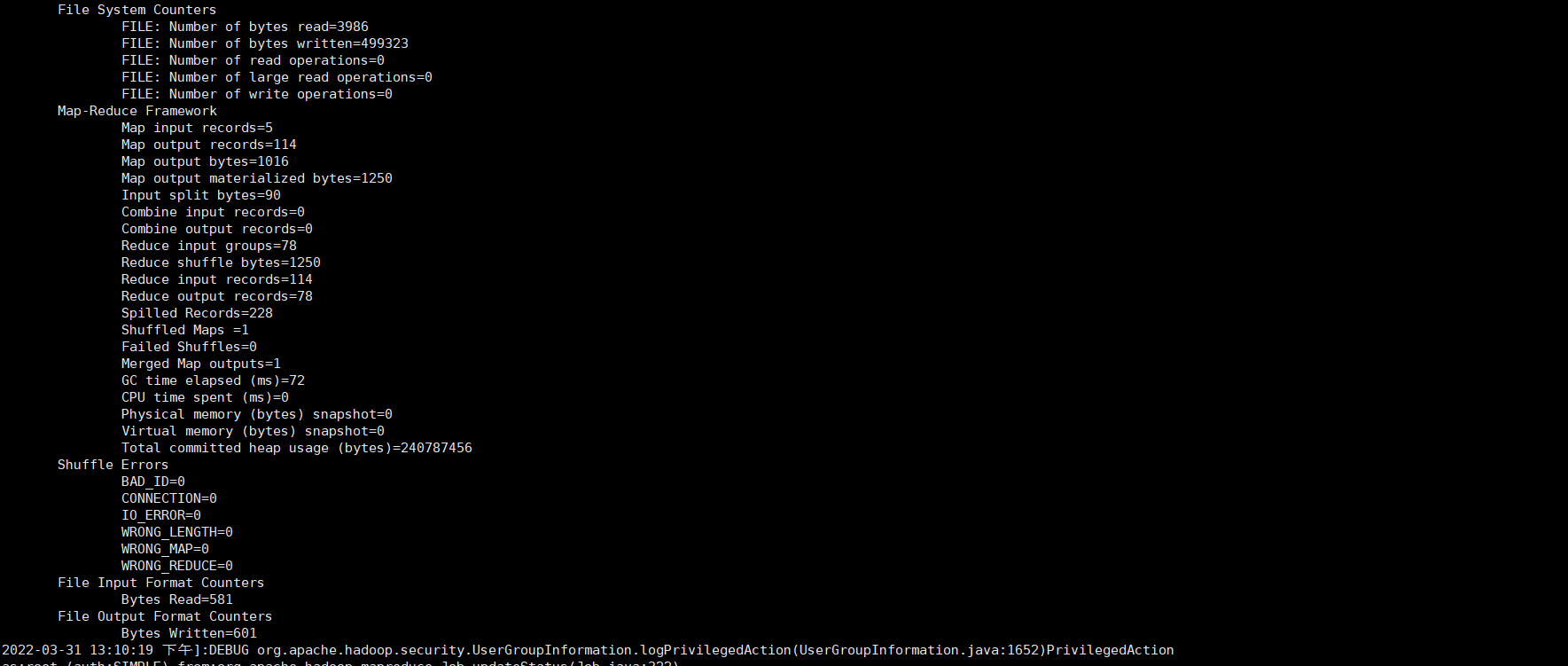
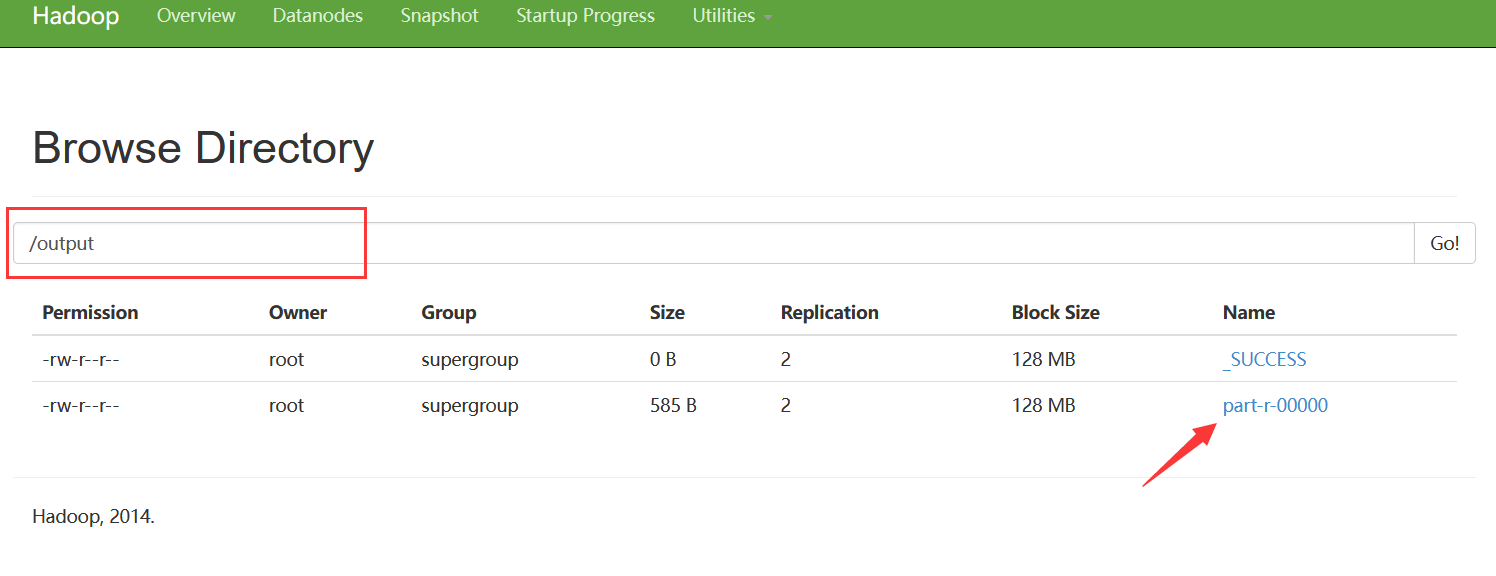
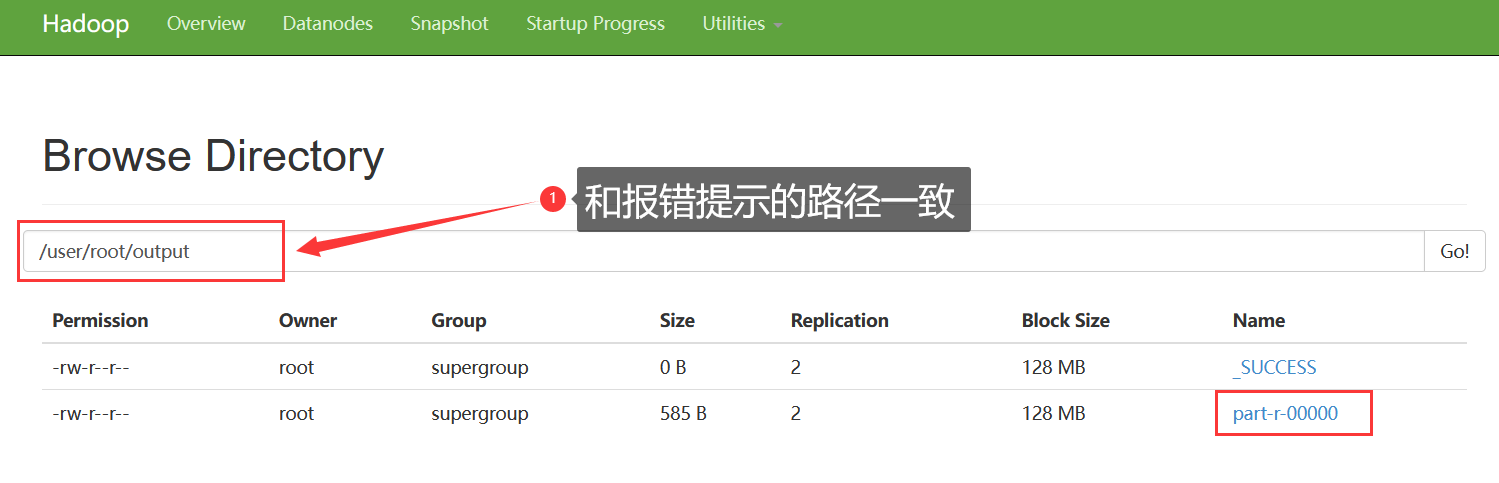
- 查看output中的文件

[06].额外测试
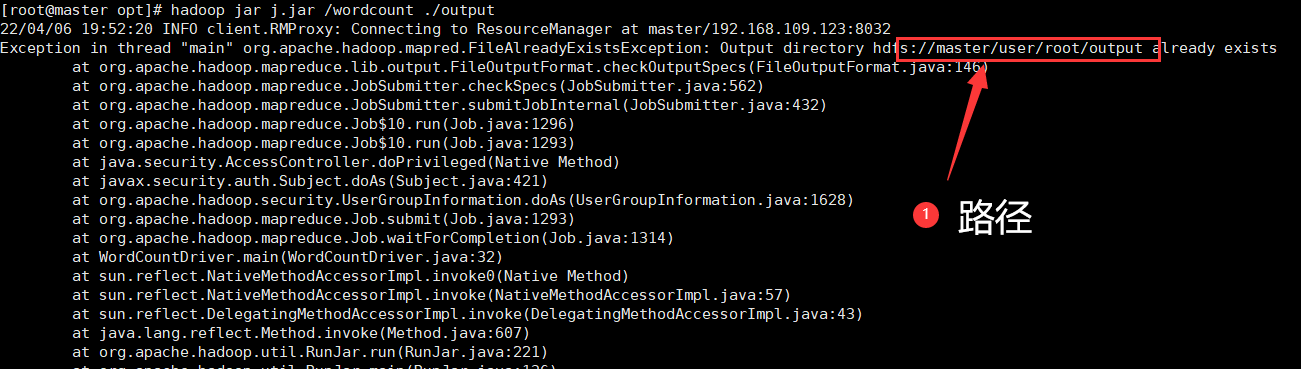
01.runanble的方式打的jar包运行在linux的方式
java -jar r.jar ./input ./output
#r.jar是我用runanble的方式打的jar包,直接用jvm来运行

若有收获,就点个赞吧
0 人点赞
