[01].准备工作
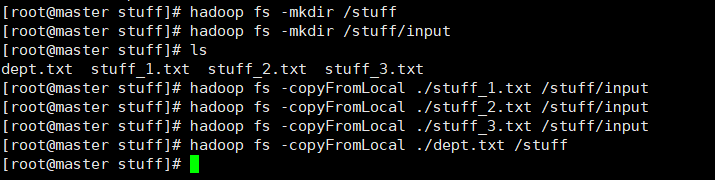
- 前台
/stuff/dept.txt
/stuff/input(用不着)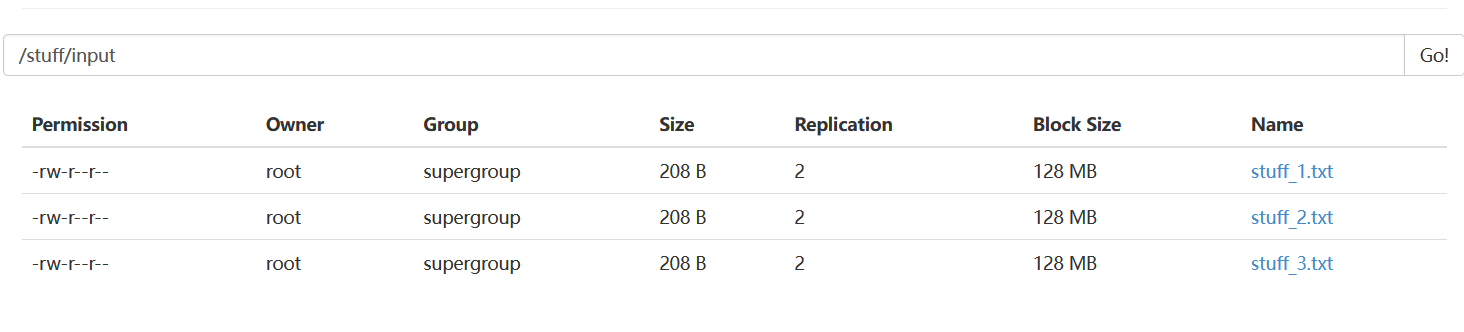
- 本地
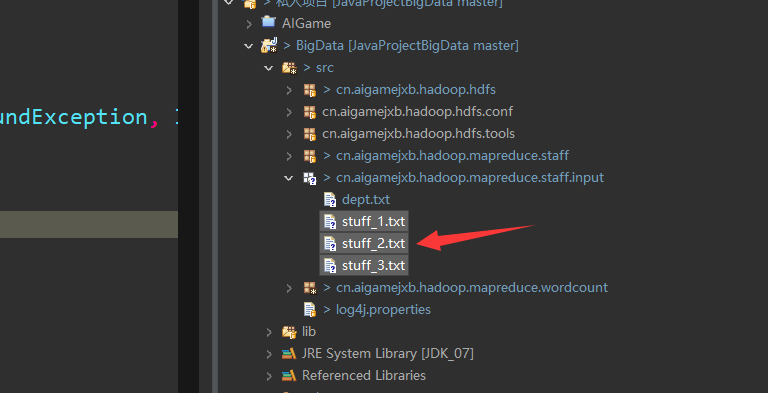
需要这样三个员工资源,我的其实都是一样的,为了简便起见。
stuf_1.txt(其他三个一样或者你自己随便写)103294 11 9033103295 12 9033103296 14 9033103297 13 9033103298 12 9033103299 11 9033103290 13 9033103291 14 9033103292 14 9033103293 10 9033103284 10 9033103274 11 9033103264 12 9033
dept.txt部门编号10 暴龙奥特曼分部11 迪迦奥特曼分部12 艾斯奥特曼分部13 泰罗奥特曼分部14 赛罗奥特曼分部
01.老师给定的数据
staff_01.txt10021456 11 923910021457 14 716810021458 12 858010021459 11 653710021460 12 873510021461 14 708610021462 14 963710021463 10 741110021464 12 650610021465 12 914110021466 11 686510021467 12 613010021468 11 807510021469 12 865410021470 11 685610021471 13 745210021472 10 951410021473 14 752410021474 12 983610021475 11 663310021476 12 972410021477 11 642510021478 10 822210021479 10 735310021480 13 694510021481 10 850710021482 14 740610021483 11 857410021484 13 779010021485 11 605010021486 12 821110021487 11 923610021488 12 610810021489 10 631910021490 11 998010021491 14 855410021492 12 996910021493 12 958210021494 10 774610021495 13 966410021496 14 990510021497 11 707210021498 11 707610021499 10 727610021500 10 626310021501 11 852510021502 10 677410021503 10 656110021504 14 938310021505 11 7630
staff_02.txt10003566 13 795310003567 10 735610003568 14 930710003569 11 662410003570 11 751510003571 11 796610003572 13 795110003573 10 876310003574 11 892410003575 14 863310003576 12 652610003577 12 653710003578 13 760510003579 10 856010003580 11 710310003581 10 704910003582 10 739510003583 10 952910003584 12 607310003585 14 997410003586 13 995810003587 12 652510003588 14 723410003589 12 759110003590 11 797810003591 12 868310003592 11 965310003593 13 876310003594 12 685810003595 11 977310003596 13 892210003597 14 626710003598 13 881010003599 12 787510003600 10 821010003601 12 906110003602 10 760610003603 14 793610003604 13 991210003605 14 945610003606 13 713310003607 12 713910003608 12 804710003609 10 684010003610 12 833810003611 13 721210003612 13 619410003613 13 929610003614 11 689010003615 14 6866
staff_03.txt10014823 12 913910014824 14 800210014825 14 991910014826 10 997610014827 12 679010014828 11 766910014829 12 976310014830 11 910510014831 12 868810014832 13 759510014833 13 971010014834 14 665510014835 13 852110014836 12 962010014837 14 912910014838 13 738710014839 12 935610014840 12 674010014841 13 830810014842 10 927210014843 14 758410014844 12 676710014845 14 718410014846 10 999810014847 12 974410014848 10 867510014849 12 692910014850 10 809610014851 12 861910014852 11 818910014853 14 605310014854 10 704910014855 14 618410014856 14 9899
dept.txt10 ACCOUNTING11 RESEARCH12 SALES13 OPERATIONS14 DEVELOPMENT
[02].项目代码
01.
StaffMapperimport java.io.IOException;import java.net.URISyntaxException;import java.util.HashMap;import java.util.Map;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import cn.aigamejxb.hadoop.hdfs.tools.FSManager;/** KEYIN:默认已经拿到的key(行首的偏移量:LongWritable(相当于java的long类型))** VALUEIN:默认分片好的内容(Text类型(相当于string))** KEYOUT:输出的key(Text类型)** VALUEOUT:输出的value(都是1,记作{"word",1},数字类型IntWritable(int))*/public class StaffMapper extends Mapper<LongWritable, Text, Text, LongWritable> {//用map集合存放depts的数据private Map<String,String>depts = new HashMap<String,String>();@Overrideprotected void setup(Mapper<LongWritable, Text, Text, LongWritable>.Context context)throws IOException, InterruptedException {//用之前封装好的方法,读取文件try {String content = FSManager.readContent("/stuff/dept.txt");String content_lines[] = content.split("\n");for(String line : content_lines) {if(!line.trim().equals("")) {String items[] = line.split(" ");depts.put(items[0], items[1]);}}} catch (IOException e) {e.printStackTrace();} catch (URISyntaxException e) {e.printStackTrace();}}private Text outKey = new Text();private LongWritable longValue = new LongWritable();@Overrideprotected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException {String items[] = value.toString().split(" ");//按照分隔符切分字符串,提取出部门和工资//item[1]:部门 item[2]:工资//从dept.txt中拿到部门编号:重写setup方法(map之前回调一次,适用于小的表)outKey.set(depts.get(items[1]));//拿到部门对应的编号longValue.set(Long.parseLong(items[2]));//薪水context.write(outKey, longValue);}}
02.
StaffReduceimport java.io.IOException;import org.apache.hadoop.io.DoubleWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;/** KEYIN:reduse输入key(部门名称Text)* VALUEIN:reduse输入value(工资LongWritable[1,2,3,4,5,6...])* KEYOUT:reduse输出的key(部门名称Text)* VALUEOUT:平均工资(DoubleWritable)*/public class StaffReduce extends Reducer<Text, LongWritable, Text,DoubleWritable> {private DoubleWritable outValue = new DoubleWritable();@Overrideprotected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {long num = 0 ;//数量long sum = 0 ;//总数for (LongWritable value : values) {++num;sum+=value.get();}outValue.set(sum/(double)num);//薪水平均值context.write(key, outValue);}}
03.
StaffDriverimport java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.DoubleWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class StaffDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1.创建job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2.设置jar路径job.setJarByClass(StaffDriver.class);// 3.关联map与redjob.setMapperClass(StaffMapper.class);job.setReducerClass(StaffReduce.class);// 4.设置map输出的键值对类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);// 5.设置最终数据输出键值对类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(DoubleWritable.class);// 6.设置输入路径(TextInputFormat)和输出路径(FileOutputFormat)TextInputFormat.addInputPath(job, new Path("D:\\360MoveData\\Users\\AIGameJXB\\Desktop\\Hadoop\\JavaProjectBigData\\src\\cn\\aigamejxb\\hadoop\\mapreduce\\staff\\input\\stuff_1.txt"));TextInputFormat.addInputPath(job, new Path("D:\\360MoveData\\Users\\AIGameJXB\\Desktop\\Hadoop\\JavaProjectBigData\\src\\cn\\aigamejxb\\hadoop\\mapreduce\\staff\\input\\stuff_2.txt"));TextInputFormat.addInputPath(job, new Path("D:\\360MoveData\\Users\\AIGameJXB\\Desktop\\Hadoop\\JavaProjectBigData\\src\\cn\\aigamejxb\\hadoop\\mapreduce\\staff\\input\\stuff_3.txt"));FileOutputFormat.setOutputPath(job, new Path("D:\\360MoveData\\Users\\AIGameJXB\\Desktop\\Hadoop\\JavaProjectBigData\\src\\cn\\aigamejxb\\hadoop\\mapreduce\\staff\\output\\stuff"));// 7.提交jobboolean result = job.waitForCompletion(true);// true:打印运行信息System.exit(result ? 0 : 1);// 1:非正常退出}}
[03].测试运行
截屏(显而易见,运行成功了)
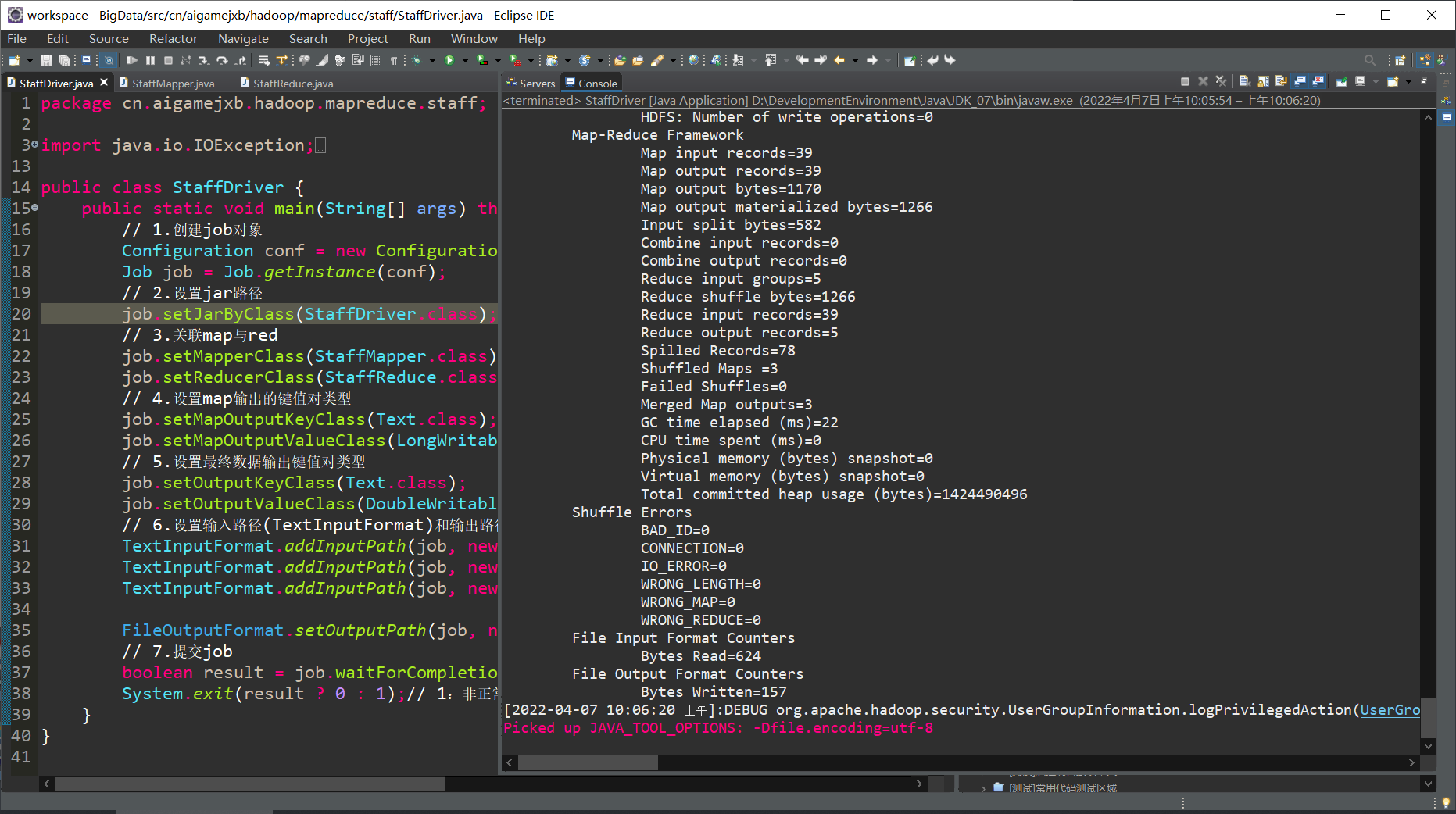
- 接下来去看看输出了什么
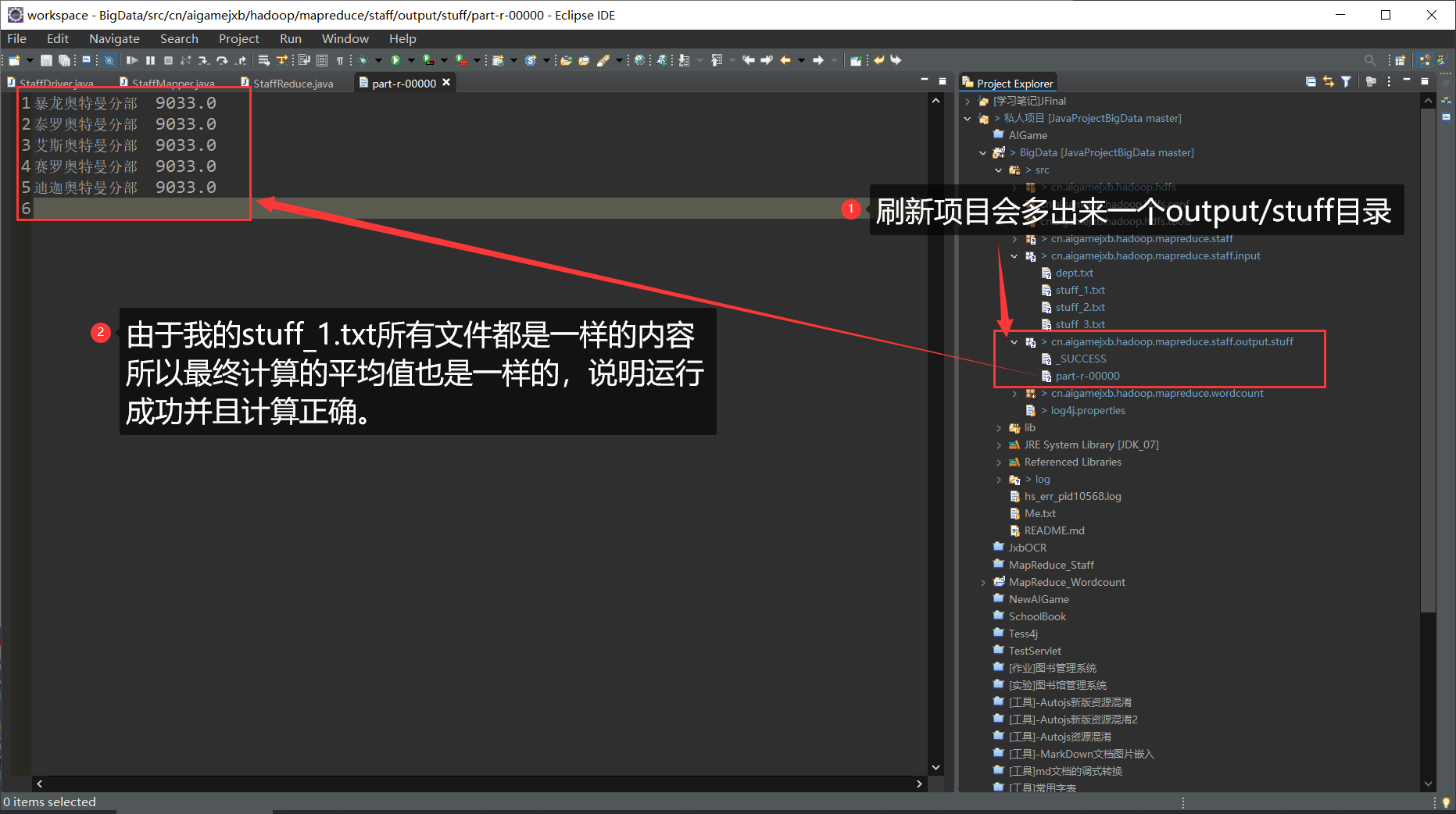

若有收获,就点个赞吧
0 人点赞
