:::tips
此文档较长, 为提升加载速度, 分为 2 部分, 第 2 部分见:
https://www.yuque.com/zzqcn/wireshark/shgg7u
:::
此文档供对 Wireshark 协议解析器开发感兴趣的开发者参考, 它描述了正确的编码模式和一些重要函数和变量的使用.
此文件试图给出有关 Wireshark 开发的深入信息, 但它不可能无所不包. 请随时使用开发者邮件列表沟通.
如果你还没有看过 README.developer, 先看看!
0 预备知识
原标题: Prerequisites
在开发新的解析器之前, 你需要一个”可运行的” Wireshark 开发环境 - 毕竟并不存在所谓的”解析器SDK”.
如何配置这样的开发环境是平台相关的; 详情请参考开发手册, 以及源码根目录中的 INSTALL 和 README.md 文件.
0.1 解析器相关README文件
原标题: Dissector related README files
You’ll find additional dissector related information in the following README files:
- README.heuristic - what are heuristic dissectors and how to write them
- README.plugins - how to “pluginize” a dissector
- README.request_response_tracking - how to track req./resp. times and such
- README.wmem - how to obtain “memory leak free” memory
0.2 编著者
原标题: Contributors
James Coe
Gilbert Ramirez
Jeff Foster
Olivier Abad
Laurent Deniel
Gerald Combs
Guy Harris
Ulf Lamping
Barbu Paul - Gheorghe
1 创建协议解析器代码
原标题: Setting up your protocol dissector code
This section provides skeleton code for a protocol dissector. It also explains the basic functions needed to enter values in the traffic summary columns, add to the protocol tree, and work with registered header fields.
1.1 骨架代码
原标题: Skeleton code
Wireshark requires certain things when setting up a protocol dissector. We provide basic skeleton code for a dissector that you can copy to a new file and fill in. Your dissector should follow the naming convention of “packet-“ followed by the abbreviated name for the protocol. It is recommended that where possible you keep to the IANA abbreviated name for the protocol, if there is one, or a commonly-used abbreviation for the protocol, if any.
The skeleton code lives in the file “packet-PROTOABBREV.c” in the same source directory as this README.
If instead of using the skeleton you base your dissector on an existing real dissector, please put a little note in the copyright header indicating which dissector you started with.
Usually, you will put your newly created dissector file into the directory epan/dissectors/, just like all the other packet-*.c files already in there.
Also, please add your dissector file to the corresponding makefiles, described in section “1.8 Editing CMakeLists.txt to add your dissector” below.
Dissectors that use the dissector registration API to register with a lower level protocol (this is the vast majority) don’t need to define a prototype in their .h file. For other dissectors the main dissector routine should have a prototype in a header file whose name is “packet-“, followed by the abbreviated name for the protocol, followed by “.h”; any dissector file that calls your dissector should be changed to include that file.
You may not need to include all the headers listed in the skeleton, and you may need to include additional headers.
1.2 骨架代码中需要替换的项
原标题: Explanation of needed substitutions in code skeleton
In the skeleton sample code the following strings should be substituted with your information.
YOUR_NAME Your name, of course. You do want credit, don't you?It's the only payment you will receive....YOUR_EMAIL_ADDRESS Keep those cards and letters coming.PROTONAME The name of the protocol; this is displayed in thetop-level protocol tree item for that protocol.PROTOSHORTNAME An abbreviated name for the protocol; this is displayedin the "Preferences" dialog box if your dissector hasany preferences, in the dialog box of enabled protocols,and in the dialog box for filter fields when constructinga filter expression.PROTOABBREV A name for the protocol for use in filter expressions;it may contain only lower-case letters, digits, and hyphens,underscores, and periods.LICENSE The license this dissector is under. Please use a SPDX Licenseidentifier.YEARS The years the above license is valid for.FIELDNAME The displayed name for the header field.FIELDABBREV The abbreviated name for the header field; it may containonly letters, digits, hyphens, underscores, and periods.FIELDTYPE FT_NONE, FT_BOOLEAN, FT_CHAR, FT_UINT8, FT_UINT16, FT_UINT24,FT_UINT32, FT_UINT40, FT_UINT48, FT_UINT56, FT_UINT64,FT_INT8, FT_INT16, FT_INT24, FT_INT32, FT_INT40, FT_INT48,FT_INT56, FT_INT64, FT_FLOAT, FT_DOUBLE, FT_ABSOLUTE_TIME,FT_RELATIVE_TIME, FT_STRING, FT_STRINGZ, FT_EUI64,FT_UINT_STRING, FT_ETHER, FT_BYTES, FT_UINT_BYTES, FT_IPv4,FT_IPv6, FT_IPXNET, FT_FRAMENUM, FT_PROTOCOL, FT_GUID, FT_OID,FT_REL_OID, FT_AX25, FT_VINES, FT_SYSTEM_ID, FT_FC, FT_FCWWNFIELDDISPLAY --For FT_UINT{8,16,24,32,40,48,56,64} andFT_INT{8,16,24,32,40,48,56,64):BASE_DEC, BASE_HEX, BASE_OCT, BASE_DEC_HEX, BASE_HEX_DEC,BASE_CUSTOM, or BASE_NONE, possibly ORed withBASE_RANGE_STRING, BASE_EXT_STRING, BASE_VAL64_STRING,BASE_ALLOW_ZERO, BASE_UNIT_STRING, BASE_SPECIAL_VALS,BASE_NO_DISPLAY_VALUE, or BASE_SHOW_ASCII_PRINTABLEBASE_NONE may be used with a non-NULL FIELDCONVERT when thenumeric value of the field itself is not of significance tothe user (for example, the number is a generated field).When this is the case the numeric value is not shown to theuser in the protocol decode nor is it used when preparingfilters for the field in question.BASE_NO_DISPLAY_VALUE will just display the field name withno value. It is intended for byte arrays (FT_BYTES orFT_UINT_BYTES) or header fields above a subtree. Thevalue will still be filterable, just not displayed.--For FT_UINT16:BASE_PT_UDP, BASE_PT_TCP, BASE_PT_DCCP or BASE_PT_SCTP--For FT_UINT24:BASE_OUI--For FT_CHAR:BASE_HEX, BASE_OCT, BASE_CUSTOM, or BASE_NONE, possiblyORed with BASE_RANGE_STRING, BASE_EXT_STRING orBASE_VAL64_STRING.BASE_NONE can be used in the same way as with FT_UINT8.--For FT_ABSOLUTE_TIME:ABSOLUTE_TIME_LOCAL, ABSOLUTE_TIME_UTC, orABSOLUTE_TIME_DOY_UTC--For FT_BOOLEAN:if BITMASK is non-zero:Number of bits in the field containing the FT_BOOLEANbitfield.otherwise:(must be) BASE_NONE--For FT_STRING, FT_STRINGZ and FT_UINT_STRING:STR_ASCII or STR_UNICODE--For FT_BYTES and FT_UINT_BYTES:SEP_DOT, SEP_DASH, SEP_COLON, or SEP_SPACE to providea separator between bytes; BASE_NONE has no separatorbetween bytes. These can be ORed with BASE_ALLOW_ZEROand BASE_SHOW_ASCII_PRINTABLE.BASE_ALLOW_ZERO displays <none> instead of <MISSING>for a zero-sized byte array.BASE_SHOW_ASCII_PRINTABLE will check whether thefield's value consists entirely of printable ASCIIcharacters and, if so, will display the field's valueas a string, in quotes. The value will still befilterable as a byte value.--For FT_IPv4:BASE_NETMASK - Used for IPv4 address that should neverattempted to be resolved (like netmasks)otherwise:(must be) BASE_NONE--For all other types:BASE_NONEFIELDCONVERT VALS(x), VALS64(x), RVALS(x), TFS(x), CF_FUNC(x), NULLBITMASK Used to mask a field not 8-bit aligned or with a size otherthan a multiple of 8 bitsFIELDDESCR A brief description of the field, or NULL. [Please do not use ""].
If, for example, PROTONAME is “Internet Bogosity Discovery Protocol”, PROTOSHORTNAME would be “IBDP”, and PROTOABBREV would be “ibdp”. Try to conform with IANA names.
1.2.1 Automatic substitution in code skeleton
Instead of manual substitutions in the code skeleton, a tool to automate it can be found under the tools directory. The script is called tools/generate-dissector.py and takes all the needed options to generate a compilable dissector. Look at the above fields to know how to set them. Some assumptions have been made in the generation to shorten the list of required options. The script patches the CMakeLists.txt file adding the new dissector in the proper list, alphabetically sorted.
1.3 解析器及其数据接收
原标题: The dissector and the data it receives
1.3.1 头文件
This is only needed if the dissector doesn’t use self-registration to register itself with the lower level dissector, or if the protocol dissector wants/needs to expose code to other subdissectors.
The dissector must be declared exactly as follows in the file packet-PROTOABBREV.h:
intdissect_PROTOABBREV(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree);
1.3.2 从报文中提取数据(tvb)
原标题: Extracting data from packets
NOTE: See the file /epan/tvbuff.h for more details.
解析函数的 tvb 参数指向包含原始数据的 buffer; 例如, 对某个 UDP 之上的协议, tvb 包含 UDP payload(但不包含 UDP 首部, 以及其他协议首部). tvbuffer 是一种不透明数据结构, 它对隐藏了内部细节, 调用者必须通过函数接口访问其包含的数据.
这些函数接口有:
tvb数据访问接口
Bit accessors for a maximum of 8-bits, 16-bits 32-bits and 64-bits:
guint8 tvb_get_bits8(tvbuff_t *tvb, gint bit_offset, const gint no_of_bits);guint16 tvb_get_bits16(tvbuff_t *tvb, guint bit_offset, const gint no_of_bits, const guint encoding);guint32 tvb_get_bits32(tvbuff_t *tvb, guint bit_offset, const gint no_of_bits, const guint encoding);guint64 tvb_get_bits64(tvbuff_t *tvb, guint bit_offset, const gint no_of_bits, const guint encoding);
Single-byte accessors for 8-bit unsigned integers (guint8) and 8-bit signed integers (gint8):
guint8 tvb_get_guint8(tvbuff_t *tvb, const gint offset);gint8 tvb_get_gint8(tvbuff_t *tvb, const gint offset);
Network-to-host-order accessors:
16-bit unsigned (guint16) and signed (gint16) integers:
guint16 tvb_get_ntohs(tvbuff_t *tvb, const gint offset);gint16 tvb_get_ntohis(tvbuff_t *tvb, const gint offset);
24-bit unsigned and signed integers:
guint32 tvb_get_ntoh24(tvbuff_t *tvb, const gint offset);gint32 tvb_get_ntohi24(tvbuff_t *tvb, const gint offset);
32-bit unsigned (guint32) and signed (gint32) integers:
guint32 tvb_get_ntohl(tvbuff_t *tvb, const gint offset);gint32 tvb_get_ntohil(tvbuff_t *tvb, const gint offset);
40-bit unsigned and signed integers:
guint64 tvb_get_ntoh40(tvbuff_t *tvb, const gint offset);gint64 tvb_get_ntohi40(tvbuff_t *tvb, const gint offset);
48-bit unsigned and signed integers:
guint64 tvb_get_ntoh48(tvbuff_t *tvb, const gint offset);gint64 tvb_get_ntohi48(tvbuff_t *tvb, const gint offset);
56-bit unsigned and signed integers:
guint64 tvb_get_ntoh56(tvbuff_t *tvb, const gint offset);gint64 tvb_get_ntohi56(tvbuff_t *tvb, const gint offset);
64-bit unsigned (guint64) and signed (gint64) integers:
guint64 tvb_get_ntoh64(tvbuff_t *tvb, const gint offset);gint64 tvb_get_ntohi64(tvbuff_t *tvb, const gint offset);
Single-precision and double-precision IEEE floating-point numbers:
gfloat tvb_get_ntohieee_float(tvbuff_t *tvb, const gint offset);gdouble tvb_get_ntohieee_double(tvbuff_t *tvb, const gint offset);
Little-Endian-to-host-order accessors:
16-bit unsigned (guint16) and signed (gint16) integers:
guint16 tvb_get_letohs(tvbuff_t *tvb, const gint offset);gint16 tvb_get_letohis(tvbuff_t *tvb, const gint offset);
24-bit unsigned and signed integers:
guint32 tvb_get_letoh24(tvbuff_t *tvb, const gint offset);gint32 tvb_get_letohi24(tvbuff_t *tvb, const gint offset);
32-bit unsigned (guint32) and signed (gint32) integers:
guint32 tvb_get_letohl(tvbuff_t *tvb, const gint offset);gint32 tvb_get_letohil(tvbuff_t *tvb, const gint offset);
40-bit unsigned and signed integers:
guint64 tvb_get_letoh40(tvbuff_t *tvb, const gint offset);gint64 tvb_get_letohi40(tvbuff_t *tvb, const gint offset);
48-bit unsigned and signed integers:
guint64 tvb_get_letoh48(tvbuff_t *tvb, const gint offset);gint64 tvb_get_letohi48(tvbuff_t *tvb, const gint offset);
56-bit unsigned and signed integers:
guint64 tvb_get_letoh56(tvbuff_t *tvb, const gint offset);gint64 tvb_get_letohi56(tvbuff_t *tvb, const gint offset);
64-bit unsigned (guint64) and signed (gint64) integers:
guint64 tvb_get_letoh64(tvbuff_t *tvb, const gint offset);gint64 tvb_get_letohi64(tvbuff_t *tvb, const gint offset);
NOTE: Although each of the integer accessors above return types with specific sizes, the returned values are subject to C’s integer promotion rules. It’s often safer and more useful to use int or guint for 32-bit and smaller types, and gint64 or guint64 for 40-bit and larger types. Just because a value occupied 16 bits on the wire or over the air doesn’t mean it will within Wireshark.
Single-precision and double-precision IEEE floating-point numbers:
gfloat tvb_get_letohieee_float(tvbuff_t *tvb, const gint offset);gdouble tvb_get_letohieee_double(tvbuff_t *tvb, const gint offset);
Encoding-to_host-order accessors:
16-bit unsigned (guint16) and signed (gint16) integers:
guint16 tvb_get_guint16(tvbuff_t *tvb, const gint offset, const guint encoding);gint16 tvb_get_gint16(tvbuff_t *tvb, const gint offset, const guint encoding);
24-bit unsigned and signed integers:
guint32 tvb_get_guint24(tvbuff_t *tvb, const gint offset, const guint encoding);gint32 tvb_get_gint24(tvbuff_t *tvb, const gint offset, const guint encoding);
32-bit unsigned (guint32) and signed (gint32) integers:
guint32 tvb_get_guint32(tvbuff_t *tvb, const gint offset, const guint encoding);gint32 tvb_get_gint32(tvbuff_t *tvb, const gint offset, const guint encoding);
40-bit unsigned and signed integers:
guint64 tvb_get_guint40(tvbuff_t *tvb, const gint offset, const guint encoding);gint64 tvb_get_gint40(tvbuff_t *tvb, const gint offset, const guint encoding);
48-bit unsigned and signed integers:
guint64 tvb_get_guint48(tvbuff_t *tvb, const gint offset, const guint encoding);gint64 tvb_get_gint48(tvbuff_t *tvb, const gint offset, const guint encoding);
56-bit unsigned and signed integers:
guint64 tvb_get_guint56(tvbuff_t *tvb, const gint offset, const guint encoding);gint64 tvb_get_gint56(tvbuff_t *tvb, const gint offset, const guint encoding);
64-bit unsigned (guint64) and signed (gint64) integers:
guint64 tvb_get_guint64(tvbuff_t *tvb, const gint offset, const guint encoding);gint64 tvb_get_gint64(tvbuff_t *tvb, const gint offset, const guint encoding);
Single-precision and double-precision IEEE floating-point numbers:
gfloat tvb_get_ieee_float(tvbuff_t *tvb, const gint offset, const guint encoding);gdouble tvb_get_ieee_double(tvbuff_t *tvb, const gint offset, const guint encoding);
“encoding” should be ENC_BIG_ENDIAN for Network-to-host-order, ENC_LITTLE_ENDIAN for Little-Endian-to-host-order, or ENC_HOST_ENDIAN for host order.
Accessors for IPv4 and IPv6 addresses:
guint32 tvb_get_ipv4(tvbuff_t *tvb, const gint offset);void tvb_get_ipv6(tvbuff_t *tvb, const gint offset, ws_in6_addr *addr);
NOTE: IPv4 addresses are not to be converted to host byte order before being passed to “proto_tree_add_ipv4()”. You should use “tvb_get_ipv4()” to fetch them, not “tvb_get_ntohl()” OR “tvb_get_letohl()” - don’t, for example, try to use “tvb_get_ntohl()”, find that it gives you the wrong answer on the PC on which you’re doing development, and try “tvb_get_letohl()” instead, as “tvb_get_letohl()” will give the wrong answer on big-endian machines.
gchar *tvb_ip_to_str(tvbuff_t *tvb, const gint offset);gchar *tvb_ip6_to_str(tvbuff_t *tvb, const gint offset);
Returns a null-terminated buffer containing a string with IPv4 or IPv6 Address from the specified tvbuff, starting at the specified offset.
Accessors for GUID:
void tvb_get_ntohguid(tvbuff_t *tvb, const gint offset, e_guid_t *guid);void tvb_get_letohguid(tvbuff_t *tvb, const gint offset, e_guid_t *guid);void tvb_get_guid(tvbuff_t *tvb, const gint offset, e_guid_t *guid, const guint encoding);
String accessors:
guint8 *tvb_get_string_enc(wmem_allocator_t *scope, tvbuff_t *tvb,const gint offset, const gint length, const guint encoding);
Returns a null-terminated buffer allocated from the specified scope, containing data from the specified tvbuff, starting at the specified offset, and containing the specified length worth of characters. Reads data in the specified encoding and produces UTF-8 in the buffer. See below for a list of input encoding values.
The buffer is allocated in the given wmem scope (see README.wmem for more information).
guint8 *tvb_get_stringz_enc(wmem_allocator_t *scope, tvbuff_t *tvb,const gint offset, gint *lengthp, const guint encoding);
Returns a null-terminated buffer allocated from the specified scope, containing data from the specified tvbuff, starting at the specified offset, and containing all characters from the tvbuff up to and including a terminating null character in the tvbuff. Reads data in the specified encoding and produces UTF-8 in the buffer. See below for a list of input encoding values. “*lengthp” will be set to the length of the string, including the terminating null.
The buffer is allocated in the given wmem scope (see README.wmem for more information).
const guint8 *tvb_get_const_stringz(tvbuff_t *tvb, const gint offset, gint *lengthp);
Returns a null-terminated const buffer containing data from the specified tvbuff, starting at the specified offset, and containing all bytes from the tvbuff up to and including a terminating null character in the tvbuff. “*lengthp” will be set to the length of the string, including the terminating null.
You do not need to free() this buffer; it will happen automatically once the next packet is dissected. This function is slightly more efficient than the others because it does not allocate memory and copy the string, but it does not do any mapping to UTF-8 or checks for valid octet sequences.
gint tvb_get_nstringz(tvbuff_t *tvb, const gint offset, const guint bufsize, guint8* buffer);gint tvb_get_nstringz0(tvbuff_t *tvb, const gint offset, const guint bufsize, guint8* buffer);
Copies bufsize bytes, including the terminating NULL, to buffer. If a NULL terminator is found before reaching bufsize, only the bytes up to and including the NULL are copied. Returns the number of bytes copied (not including terminating NULL), or -1 if the string was truncated in the buffer due to not having reached the terminating NULL. In this case, the resulting buffer is not NULL-terminated. tvb_get_nstringz0() works like tvb_get_nstringz(), but never returns -1 since the string is guaranteed to have a terminating NULL. If the string was truncated when copied into buffer, a NULL is placed at the end of buffer to terminate it.
gchar *tvb_get_ts_23_038_7bits_string(wmem_allocator_t *scope, tvbuff_t *tvb, const gint bit_offset, gint no_of_chars);
tvb_get_ts_23_038_7bits_string() returns a string of a given number of characters and encoded according to 3GPP TS 23.038 7 bits alphabet.
The buffer is allocated in the given wmem scope (see README.wmem for more information).
Byte Array Accessors:
gchar *tvb_bytes_to_str(wmem_allocator_t *scope, tvbuff_t *tvb, const gint offset, const gint len);
Formats a bunch of data from a tvbuff as bytes, returning a pointer to the string with the data formatted as two hex digits for each byte. The string pointed to is stored in an “wmem_alloc’d” buffer which will be freed depending on its scope (typically wmem_packet_scope which is freed after the frame). The formatted string will contain the hex digits for at most the first 16 bytes of the data. If len is greater than 16 bytes, a trailing “…” will be added to the string.
gchar *tvb_bytes_to_str_punct(wmem_allocator_t *scope, tvbuff_t *tvb, const gint offset, const gint len, const gchar punct);
This function is similar to tvb_bytes_to_str(…) except that ‘punct’ is inserted between the hex representation of each byte.
GByteArray *tvb_get_string_bytes(tvbuff_t *tvb, const gint offset, const gint length, const guint encoding, GByteArray* bytes, gint *endoff);
Given a tvbuff, an offset into the tvbuff, and a length that starts at that offset (which may be -1 for “all the way to the end of the tvbuff”), fetch the hex-decoded byte values of the tvbuff into the passed-in ‘bytes’ array, based on the passed-in encoding. In other words, convert from a hex-ascii string in tvbuff, into the supplied GByteArray.
gchar *tvb_bcd_dig_to_wmem_packet_str(tvbuff_t *tvb, const gint offset, const gint len, dgt_set_t *dgt, gboolean skip_first);
Given a tvbuff, an offset into the tvbuff, and a length that starts at that offset (which may be -1 for “all the way to the end of the tvbuff”), fetch BCD encoded digits from a tvbuff starting from either the low or high half byte, formatting the digits according to an input digit set, if NUll a default digit set of 0-9 returning “?” for overdecadic digits will be used. A pointer to the packet scope allocated string will be returned.
Note: a tvbuff content of 0xf is considered a ‘filler’ and will end the conversion.
Copying memory:
void* tvb_memcpy(tvbuff_t *tvb, void* target, const gint offset, size_t length);
Copies into the specified target the specified length’s worth of data from the specified tvbuff, starting at the specified offset.
void *tvb_memdup(wmem_allocator_t *scope, tvbuff_t *tvb, const gint offset, size_t length);
Returns a buffer containing a copy of the given TVB bytes. The buffer is allocated in the given wmem scope (see README.wmem for more information).
Pointer-retrieval:
/* WARNING! Don't use this function. There is almost always a better way.* It's dangerous because once this pointer is given to the user, there's* no guarantee that the user will honor the 'length' and not overstep the* boundaries of the buffer. Also see the warning in the Portability section.*/const guint8* tvb_get_ptr(tvbuff_t *tvb, const gint offset, const gint length);
Length query:
Get amount of captured data in the buffer (which is NOT necessarily the length of the packet). You probably want tvb_reported_length instead:
guint tvb_captured_length(const tvbuff_t *tvb);
Get reported length of buffer:
guint tvb_reported_length(const tvbuff_t *tvb);
1.4 处理报文列表窗口中的列
原标题: Functions to handle columns in the traffic summary window
The topmost pane of the main window is a list of the packets in the capture, possibly filtered by a display filter.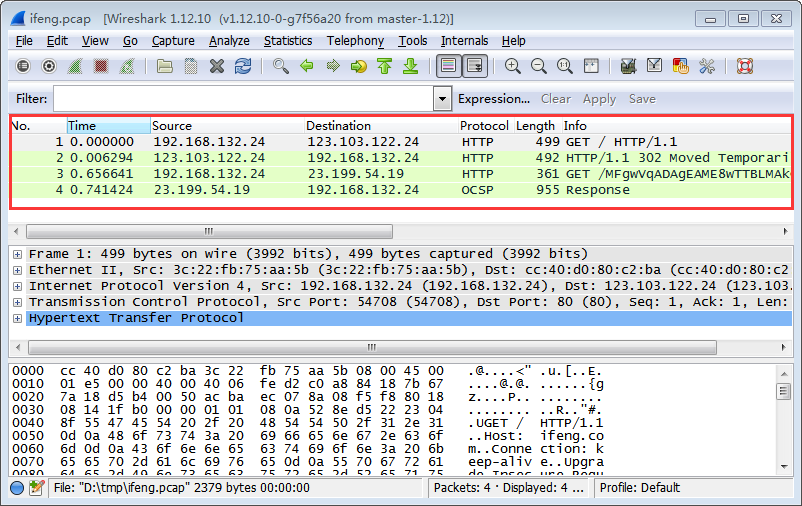
Each line corresponds to a packet, and has one or more columns, as configured by the user.
Many of the columns are handled by code outside individual dissectors; most dissectors need only specify the value to put in the “Protocol” and “Info” columns.
Columns are specified by COL_ values; the COL value for the “Protocol” field, typically giving an abbreviated name for the protocol (but not the all-lower-case abbreviation used elsewhere) is COL_PROTOCOL, and the COL value for the “Info” field, giving a summary of the contents of the packet for that protocol, is COL_INFO.
The value for a column can be specified with one of several functions, all of which take the ‘fd’ argument to the dissector as their first argument, and the COL_ value for the column as their second argument.
1.4.1 col_set_str
‘col_set_str’ takes a string as its third argument, and sets the value for the column to that value. It assumes that the pointer passed to it points to a string constant or a static “const” array, not to a variable, as it doesn’t copy the string, it merely saves the pointer value; the argument can itself be a variable, as long as it always points to a string constant or a static “const” array.
It is more efficient than ‘col_add_str’ or ‘col_add_fstr’; however, if the dissector will be using ‘col_append_str’ or ‘col_append_fstr” to append more information to the column, the string will have to be copied anyway, so it’s best to use ‘col_add_str’ rather than ‘col_set_str’ in that case.
For example, to set the “Protocol” column to “PROTOABBREV”:
col_set_str(pinfo->cinfo, COL_PROTOCOL, "PROTOABBREV");
1.4.2 col_add_str
‘col_add_str’ takes a string as its third argument, and sets the value for the column to that value. It takes the same arguments as ‘col_set_str’, but copies the string, so that if the string is, for example, an automatic variable that won’t remain in scope when the dissector returns, it’s safe to use.
1.4.3 col_add_fstr
‘col_add_fstr’ takes a ‘printf’-style format string as its third argument, and ‘printf’-style arguments corresponding to ‘%’ format items in that string as its subsequent arguments. For example, to set the “Info” field to “
col_add_fstr(pinfo->cinfo, COL_INFO, "%s request, %u bytes", reqtype, n);
Don’t use ‘col_add_fstr’ with a format argument of just “%s” - ‘col_add_str’, or possibly even ‘col_set_str’ if the string that matches the “%s” is a static constant string, will do the same job more efficiently.
1.4.4 col_clear
If the Info column will be filled with information from the packet, that means that some data will be fetched from the packet before the Info column is filled in. If the packet is so small that the data in question cannot be fetched, the routines to fetch the data will throw an exception (see the comment at the beginning about tvbuffers improving the handling of short packets - the tvbuffers keep track of how much data is in the packet, and throw an exception on an attempt to fetch data past the end of the packet, so that the dissector won’t process bogus data), causing the Info column not to be filled in.
This means that the Info column will have data for the previous protocol, which would be confusing if, for example, the Protocol column had data for this protocol.
Therefore, before a dissector fetches any data whatsoever from the packet (unless it’s a heuristic dissector fetching data to determine whether the packet is one that it should dissect, in which case it should check, before fetching the data, whether there’s any data to fetch; if there isn’t, it should return FALSE), it should set the Protocol column and the Info column.
If the Protocol column will ultimately be set to, for example, a value containing a protocol version number, with the version number being a field in the packet, the dissector should, before fetching the version number field or any other field from the packet, set it to a value without a version number, using ‘col_set_str’, and should later set it to a value with the version number after it’s fetched the version number.
If the Info column will ultimately be set to a value containing information from the packet, the dissector should, before fetching any fields from the packet, clear the column using ‘col_clear’ (which is more efficient than clearing it by calling ‘col_set_str’ or ‘col_add_str’ with a null string), and should later set it to the real string after it’s fetched the data to use when doing that.
1.4.5 col_append_str
Sometimes the value of a column, especially the “Info” column, can’t be conveniently constructed at a single point in the dissection process; for example, it might contain small bits of information from many of the fields in the packet. ‘col_append_str’ takes, as arguments, the same arguments as ‘col_add_str’, but the string is appended to the end of the current value for the column, rather than replacing the value for that column. (Note that no blank separates the appended string from the string to which it is appended; if you want a blank there, you must add it yourself as part of the string being appended.)
1.4.6 col_append_fstr
‘col_append_fstr’ is to ‘col_add_fstr’ as ‘col_append_str’ is to ‘col_add_str’ - it takes, as arguments, the same arguments as ‘col_add_fstr’, but the formatted string is appended to the end of the current value for the column, rather than replacing the value for that column.
1.4.7 col_append_sep_str, col_append_sep_fstr
In specific situations the developer knows that a column’s value will be created in a stepwise manner, where the appended values are listed. Both ‘col_append_sep_str’ and ‘col_append_sep_fstr’ functions will add an item separator between two consecutive items, and will not add the separator at the beginning of the column. The remainder of the work both functions do is identical to what ‘col_append_str’ and ‘col_append_fstr’ do.
1.4.8 col_set_fence, col_prepend_fence_fstr
Sometimes a dissector may be called multiple times for different PDUs in the same frame (for example in the case of SCTP chunk bundling: several upper layer data packets may be contained in one SCTP packet). If the upper layer dissector calls ‘colset_str()’ or ‘col_clear()’ on the Info column when it begins dissecting each of those PDUs then when the frame is fully dissected the Info column would contain only the string from the last PDU in the frame. The ‘col_set_fence’ function erects a “fence” in the column that prevents subsequent ‘col…’ calls from clearing the data currently in that column. For example, the SCTP dissector calls ‘col_set_fence’ on the Info column after it has called any subdissectors for that chunk so that subdissectors of any subsequent chunks may only append to the Info column. ‘col_prepend_fence_fstr’ prepends data before a fence (moving it if necessary). It will create a fence at the end of the prepended data if the fence does not already exist.
1.4.9 col_set_time
The ‘col_set_time’ function takes an nstime value as its third argument. This nstime value is a relative value and will be added as such to the column. The fourth argument is the filtername holding this value. This way, rightclicking on the column makes it possible to build a filter based on the time-value.
For example:
col_set_time(pinfo->cinfo, COL_REL_TIME, &ts, "s4607.ploc.time");
1.5 构造协议树
原标题: Constructing the protocol tree
The middle pane of the main window, and the topmost pane of a packet popup window, are constructed from the “protocol tree” for a packet.![AC$HC2GUE3$}HON]UCYI]AT.png](/uploads/projects/zzqcn@wireshark/081e0f3c7cbc92fa569937d08c0660cc.png)
协议树 (proto_tree) 是通过 GNode 实现, 它是 GLIB 的 N-way tree 数据结构. 当然协议解析器不需要关心 proto_tree 具体是如何实现的; 它们只需将 proto_tree 指针做为参数传入相应的协议树接口, 后者提供了向 proto_tree 添加新分支和节点的功能.
:::tips
目前(3.4.5+) proto_tree 已经不是通过 GNode 实现
:::
当在报文列表窗口中选中一个报文, 或创建报文弹出窗口时, 会创建新的 proto_tree. proto_tree 指针会先传递到最上层协议解析器, 然后再传递到后续解析器, 最后通过 proto_tree_drew() 绘制 GUI 树.
The logical proto_tree needs to know detailed information about the protocols and fields about which information will be collected from the dissection routines. By strictly defining (or “typing”) the data that can be attached to a proto tree, searching and filtering becomes possible. This means that for every protocol and field (which I also call “header fields”, since they are fields in the protocol headers) which might be attached to a tree, some information is needed.
协议树需要知道协议的详细信息, 以及将从解析器中收集哪些信息的字段. 为了搜索和过滤信息, 需要严格定义协议树中的数据. 这意味着添加到协议树中的每个协议和字段(我也称之为”首部字段”, 因为它们是协议首部中的字段), 都需要一些信息.
每个解析器需通过 proto.c 中的核心解析器接口注册它的协议和字段. 最初我想把和解析器有关的所有解析器和字段信息放在一个文件中, 但”去中心化”看上去更好. 放在一个文件会使这个文件很大, 一个小修改就需要编译整个文件; 另外, 允许在运行时进行协议和字段注册, 使得动态加载解析器(可能是用户提供的)成为可能.
为进行注册, 每个协议需要实现注册函数, Wireshark 启动时会调用这些函数. 调用注册函数的代码是自动生成的; 要在启动阶段调用协议注册函数, 需要:
- 包含解析器注册函数的源文件必须添加到 epan/dissectors/CMakeLists.txt 中的 DISSECTOR_SRC
- 注册函数的函数名必须是”proto_register_XXX”格式
- 注册函数不带参数, 也没有返回值
- 注册函数在源码文件中的位置有要求, 函数名要不放到行首, 要不跟在行首的”void “之后, 如:
和void proto_register_XXX(void) {...}
voidproto_register_XXX( void ){...}
解析器注册的每个协议或字段, 都需要对应一个 int 变量(ID). 此 ID 用于在协议和字段之间建立父子关系, 以及在协议树中关联字段和对应的数据.
一些解析器需要在其子树中创建分支来组织字段, 这些分支也需要像字段那样注册. 协议注册仅应注册真正的协议, 这样 display filter 用户接口才能区分协议和字段.
协议的注册信息包括协议名及其缩写.
下面是 frame 协议的注册信息:
int proto_frame;proto_frame = proto_register_protocol (/* name */ "Frame",/* short name */ "Frame",/* abbrev */ "frame" );
首部字段的注册信息也包括名称和缩写, 还包括数据类型. 这有用助于 header_field_info 结构体检查需要哪些信息:
struct header_field_info {const char *name;const char *abbrev;enum ftenum type;int display;const void *strings;guint64 bitmask;const char *blurb;.....};
1.5.x header_field_info成员
name (FIELDNAME)
————————
A string representing the name of the field. This is the name that will appear in the graphical protocol tree. It must be a non-empty string.
abbrev (FIELDABBREV)
—————————
A string with an abbreviation of the field. The abbreviation should start with the abbreviation of the parent protocol followed by a period as a separator. For example, the “src” field in an IP packet would have “ip.src” as an abbreviation. It is acceptable to have multiple levels of periods if, for example, you have fields in your protocol that are then subdivided into subfields. For example, TRMAC has multiple error fields, so the abbreviations follow this pattern: “trmac.errors.iso”, “trmac.errors.noniso”, etc.
The abbreviation is the identifier used in a display filter. As such it cannot be an empty string.
type (FIELDTYPE)
———————
The type of value this field holds. The current field types are:
FT_NONE No field type. Used for fields thataren't given a value, and that can onlybe tested for presence or absence; afield that represents a data structure,with a subtree below it containingfields for the members of the structure,or that represents an array with asubtree below it containing fields forthe members of the array, might be anFT_NONE field.FT_PROTOCOL Used for protocols which will be placingthemselves as top-level items in the"Packet Details" pane of the UI.FT_BOOLEAN 0 means "false", any other value means"true".FT_FRAMENUM A frame number; if this is used, the "GoTo Corresponding Frame" menu item canwork on that field.FT_CHAR An 8-bit ASCII character. It's treated similarly to anFT_UINT8, but is displayed as a C-style characterconstant.FT_UINT8 An 8-bit unsigned integer.FT_UINT16 A 16-bit unsigned integer.FT_UINT24 A 24-bit unsigned integer.FT_UINT32 A 32-bit unsigned integer.FT_UINT40 A 40-bit unsigned integer.FT_UINT48 A 48-bit unsigned integer.FT_UINT56 A 56-bit unsigned integer.FT_UINT64 A 64-bit unsigned integer.FT_INT8 An 8-bit signed integer.FT_INT16 A 16-bit signed integer.FT_INT24 A 24-bit signed integer.FT_INT32 A 32-bit signed integer.FT_INT40 A 40-bit signed integer.FT_INT48 A 48-bit signed integer.FT_INT56 A 56-bit signed integer.FT_INT64 A 64-bit signed integer.FT_FLOAT A single-precision floating point number.FT_DOUBLE A double-precision floating point number.FT_ABSOLUTE_TIME An absolute time from some fixed point in time,displayed as the date, followed by the time, ashours, minutes, and seconds with 9 digits afterthe decimal point.FT_RELATIVE_TIME Seconds (4 bytes) and nanoseconds (4 bytes)of time relative to an arbitrary time.displayed as seconds and 9 digitsafter the decimal point.FT_STRING A string of characters, not necessarilyNULL-terminated, but possibly NULL-padded.This, and the other string-of-characterstypes, are to be used for text strings,not raw binary data.FT_STRINGZ A NULL-terminated string of characters.The string length is normally the lengthgiven in the proto_tree_add_item() call.However if the length given in the callis -1, then the length used is thatreturned by calling tvb_strsize().This should only be used if the string,in the packet, is always terminated witha NULL character, either because the lengthisn't otherwise specified or because acharacter count *and* a NULL terminator areboth used.FT_STRINGZPAD A NULL-padded string of characters.The length is given in the proto_tree_add_item()call, but may be larger than the length ofthe string, with extra bytes being NULL padding.This is typically used for fixed-length fieldsthat contain a string value that might be shorterthan the fixed length.FT_STRINGZTRUNC A NULL-truncated string of characters.The length is given in the proto_tree_add_item()call, but may be larger than the length ofthe string, with a NULL character after the lastcharacter of the string, and the remaining bytesbeing padding with unspecified contents. This istypically used for fixed-length fields that containa string value that might be shorter than the fixedlength.FT_UINT_STRING A counted string of characters, consistingof a count (represented as an integral value,of width given in the proto_tree_add_item()call) followed immediately by that number ofcharacters.FT_ETHER A six octet string displayed inEthernet-address format.FT_BYTES A string of bytes with arbitrary values;used for raw binary data.FT_UINT_BYTES A counted string of bytes, consistingof a count (represented as an integral value,of width given in the proto_tree_add_item()call) followed immediately by that number ofarbitrary values; used for raw binary data.FT_IPv4 A version 4 IP address (4 bytes) displayedin dotted-quad IP address format (4decimal numbers separated by dots).FT_IPv6 A version 6 IP address (16 bytes) displayedin standard IPv6 address format.FT_IPXNET An IPX address displayed in hex as a 6-bytenetwork number followed by a 6-byte stationaddress.FT_GUID A Globally Unique IdentifierFT_OID An ASN.1 Object IdentifierFT_REL_OID An ASN.1 Relative Object IdentifierFT_EUI64 A EUI-64 AddressFT_AX25 A AX-25 AddressFT_VINES A Vines AddressFT_SYSTEM_ID An OSI System-IDFT_FCWWN A Fibre Channel WWN Address
Some of these field types are still not handled in the display filter routines, but the most common ones are. The FT_UINT variables all represent unsigned integers, and the FT_INT variables all represent signed integers; the number on the end represent how many bits are used to represent the number.
Some constraints are imposed on the header fields depending on the type (e.g. FTBYTES) of the field. Fields of type FT_ABSOLUTE_TIME must use ‘ABSOLUTE_TIME{LOCAL,UTC,DOYUTC}, NULL, 0x0’ as values for the ‘display, ‘strings’, and ‘bitmask’ fields, and all other non-integral types (i.e.. types that are _not FT_INT and FT_UINT) must use ‘BASE_NONE, NULL, 0x0’ as values for the ‘display’, ‘strings’, ‘bitmask’ fields. The reason is simply that the type itself implicitly defines the nature of ‘display’, ‘strings’, ‘bitmask’.
display (FIELDDISPLAY)
—————————-
The display field has a couple of overloaded uses. This is unfortunate, but since we’re using C as an application programming language, this sometimes makes for cleaner programs. Right now I still think that overloading this variable was okay.
For integer fields (FT_UINT and FT_INT), this variable represents the base in which you would like the value displayed. The acceptable bases are:
BASE_DEC,BASE_HEX,BASE_OCT,BASE_DEC_HEX,BASE_HEX_DEC,BASE_CUSTOM
BASE_DEC, BASE_HEX, and BASE_OCT are decimal, hexadecimal, and octal, respectively. BASE_DEC_HEX and BASE_HEX_DEC display value in two bases (the 1st representation followed by the 2nd in parenthesis).
BASE_CUSTOM allows one to specify a callback function pointer that will format the value.
For 32-bit and smaller values, custom_fmt_func_t can be used to declare the callback function pointer. Specifically, this is defined as:
void func(gchar *, guint32);
For values larger than 32-bits, custom_fmt_func_64_t can be used to declare the callback function pointer. Specifically, this is defined as:
void func(gchar *, guint64);
The first argument is a pointer to a buffer of the ITEM_LABEL_LENGTH size and the second argument is the value to be formatted.
Both custom_fmt_func_t and custom_fmt_func_64_t are defined in epan/proto.h.
For FT_UINT16 ‘display’ can be used to select a transport layer protocol using one of BASE_PT_UDP, BASE_PT_TCP, BASE_PT_DCCP or BASE_PT_SCTP. If transport name resolution is enabled the port field label is displayed in decimal and as a well-known service name (if one is available).
For FT_BOOLEAN fields that are also bitfields (i.e., ‘bitmask’ is non-zero), ‘display’ is used specify a “field-width” (i.e., tell the proto_tree how wide the parent bitfield is). (If the FT_BOOLEAN ‘bitmask’ is zero, then
‘display’ must be BASE_NONE).
For integer fields a “field-width” is not needed since the type of integer itself (FT_UINT8, FT_UINT16, FT_UINT24, FT_UINT32, FT_UINT40, FT_UINT48, FT_UINT56, FT_UINT64, etc) tells the proto_tree how wide the parent bitfield is. The same is true of FT_CHAR, as it’s an 8-bit character.
For FT_ABSOLUTE_TIME fields, ‘display’ is used to indicate whether the time is to be displayed as a time in the time zone for the machine on which Wireshark/TShark is running or as UTC and, for UTC, whether the date should be displayed as “{monthname} {day_of_month}, {year}” or as “{year/day_of_year}”.
Additionally, BASE_NONE is used for ‘display’ as a NULL-value. That is, for non-integers other than FT_ABSOLUTE_TIME fields, and non-bitfield FT_BOOLEANs, you’ll want to use BASE_NONE in the ‘display’ field. You may not use BASE_NONE for integers.
It is possible that in the future we will record the endianness of integers. If so, it is likely that we’ll use a bitmask on the display field so that integers would be represented as BEND|BASE_DEC or LEND|BASE_HEX.
But that has not happened yet; note that there are protocols for which no endianness is specified, such as the X11 protocol and the DCE RPC protocol, so it would not be possible to record the endianness of all integral fields.
strings (FIELDCONVERT)
——————————-
— value_string
Some integer fields, of type FT_UINT*, need labels to represent the true value of a field. You could think of those fields as having an enumerated data type, rather than an integral data type.
A ‘value_string’ structure is a way to map values to strings.
typedef struct _value_string {guint32 value;gchar *strptr;} value_string;
For fields of that type, you would declare an array of “value_string”s:
static const value_string valstringname[] = {{ INTVAL1, "Descriptive String 1" },{ INTVAL2, "Descriptive String 2" },{ 0, NULL }};
(the last entry in the array must have a NULL ‘strptr’ value, to indicate the end of the array). The ‘strings’ field would be set to ‘VALS(valstringname)’.
If the field has a numeric rather than an enumerated type, the ‘strings’ field would be set to NULL.
If BASE_SPECIAL_VALS is also applied to the display bitmask, then if the numeric value of a field doesn’t match any values in the value_string then just the numeric value is displayed (i.e. no “Unknown”). This is intended for use when the value_string only gives special names for certain field values and values not in the value_string are expected.
— Extended value strings
You can also use an extended version of the value_string for faster lookups. It requires a value_string array as input. If all of a contiguous range of values from min to max are present in the array in ascending order the value will be used as a direct index into a value_string array.
If the values in the array are not contiguous (ie: there are “gaps”), but are in ascending order a binary search will be used.
Note: “gaps” in a value_string array can be filled with “empty” entries eg: {value, “Unknown”} so that direct access to the array is is possible.
Note: the value_string array values are unsigned; IOW: -1 is greater than 0.
So:
{ -2, -1, 1, 2 }; wrong: linear search will be used (note gap)
{ 1, 2, -2, -1 }; correct: binary search will be used
As a special case:<br /> { -2, -1, 0, 1, 2 }; OK: direct(indexed) access will be used (note no gap)
The init macro (see below) will perform a check on the value string the first time it is used to determine which search algorithm fits and fall back to a linear search if the value_string does not meet the criteria above.
Use this macro to initialize the extended value_string at compile time:
static value_string_ext valstringname_ext = VALUE_STRING_EXT_INIT(valstringname);
Extended value strings can be created at run time by calling
value_string_ext_new(
For hf[] array FT_(U)INT* fields that need a ‘valstringname_ext’ struct, the ‘strings’ field would be set to ‘&valstringname_ext’. Furthermore, the ‘display’ field must be ORed with ‘BASE_EXT_STRING’ (e.g. BASE_DEC|BASE_EXT_STRING).
— val64_string
val64_strings are like value_strings, except that the integer type used is a guint64 (instead of guint32). Instead of using the VALS() macro for the ‘strings’ field in the header_field_info struct array, ‘VALS64()’ is used.
BASE_SPECIAL_VALS can also be used for val64_string.
— val64_string_ext
val64_string_ext is like value_string_ext, except that the integer type used is a guint64 (instead of guint32).
Use this macro to initialize the extended val64_string at compile time:
static val64_string_ext val64stringname_ext = VAL64_STRING_EXT_INIT(val64stringname);
Extended val64 strings can be created at run time by calling
val64_string_ext_new(<ptr to val64_string array>,<total number of entries in the val64_string_array>,/* include {0, NULL} entry */<val64_string_name>);
For hf[] array FT_(U)INT* fields that need a ‘val64stringname_ext’ struct, the ‘strings’ field would be set to ‘&val64stringname_ext’. Furthermore, the ‘display’ field must be ORed with both ‘BASE_EXT_STRING’ and ‘BASE_VAL64_STRING’ (e.g. BASE_DEC|BASE_EXT_STRING|BASE_VAL64_STRING).
— Unit string
Some integer fields, of type FT_UINT* and float fields, of type FT_FLOAT or FT_DOUBLE, need units of measurement to help convey the field value.
A ‘unit_name_string’ structure is a way to add a unit suffix to a field.
typedef struct unit_name_string {char *singular; /* name to use for 1 unit */char *plural; /* name to use for < 1 or > 1 units */} unit_name_string;
For fields with that unit name, you would declare a “unit_name_string”:
static const unit_name_string unitname[] ={ "single item name" , "multiple item name" };
(the second entry can be NULL if there is no plural form of the unit name. This is typically the case when abbreviations are used instead of full words.)
There are several “common” unit name structures already defined in epan/unit_strings.h. Dissector authors may choose to add the unit name structure there rather than locally in a dissector.
For hf[] array FT_(U)INT*, FT_FlOAT and FT_DOUBLE fields that need a ‘unit_name_string’ struct, the ‘strings’ field would be set to ‘&units_second_seconds’. Furthermore, the ‘display’ field must be ORed with ‘BASE_UNIT_STRING’ (e.g. BASE_DEC|BASE_UNIT_STRING).
— Ranges
If the field has a numeric type that might logically fit in ranges of values one can use a range_string struct.
Thus a ‘range_string’ structure is a way to map ranges to strings.
typedef struct _range_string {guint32 value_min;guint32 value_max;const gchar *strptr;} range_string;
For fields of that type, you would declare an array of “range_string”s:
static const range_string rvalstringname[] = {{ INTVAL_MIN1, INTVALMAX1, "Descriptive String 1" },{ INTVAL_MIN2, INTVALMAX2, "Descriptive String 2" },{ 0, 0, NULL }};
If INTVAL_MIN equals INTVAL_MAX for a given entry the range_string behavior collapses to the one of value_string. Note that each range_string within the array is tested in order, so any ‘catch-all’ entries need to come after specific individual entries.
For FT_(U)INT* fields that need a ‘range_string’ struct, the ‘strings’ field would be set to ‘RVALS(rvalstringname)’. Furthermore, ‘display’ field must be ORed with ‘BASE_RANGE_STRING’ (e.g. BASE_DEC|BASE_RANGE_STRING).
— Booleans
FT_BOOLEANs have a default map of 0 = “False”, 1 (or anything else) = “True”.
Sometimes it is useful to change the labels for boolean values (e.g., to “Yes”/“No”, “Fast”/“Slow”, etc.). For these mappings, a struct called true_false_string is used.
typedef struct true_false_string {char *true_string;char *false_string;} true_false_string;
For Boolean fields for which “False” and “True” aren’t the desired labels, you would declare a “true_false_string”s:
static const true_false_string boolstringname = {"String for True","String for False"};
Its two fields are pointers to the string representing truth, and the string representing falsehood. For FT_BOOLEAN fields that need a ‘true_false_string’ struct, the ‘strings’ field would be set to ‘TFS(&boolstringname)’.
If the Boolean field is to be displayed as “False” or “True”, the ‘strings’ field would be set to NULL.
Wireshark predefines a whole range of ready made “true_false_string”s in tfs.h, included via packet.h.
— Custom
Custom fields (BASE_CUSTOM) should use CF_FUNC(&custom_format_func) for the ‘strings’ field.
— Note to plugin authors
Data cannot get exported from DLLs. For this reason plugin authors cannot use existing fieldconvert strings (e.g. from existing dissectors or those from epan/unit_strings.h). Plugins must define value_strings, unit_name_strings, range_strings and true_false_strings locally.
bitmask (BITMASK)
————————-
If the field is a bitfield, then the bitmask is the mask which will leave only the bits needed to make the field when ANDed with a value. The proto_tree routines will calculate ‘bitshift’ automatically from ‘bitmask’, by finding the rightmost set bit in the bitmask. This shift is applied before applying string mapping functions or
filtering.
If the field is not a bitfield, then bitmask should be set to 0.
blurb (FIELDDESCR)
—————————
This is a string giving a proper description of the field. It should be at least one grammatically complete sentence, or NULL in which case the name field is used. (Please do not use “”).
It is meant to provide a more detailed description of the field than the name alone provides. This information will be used in the man page, and in a future GUI display-filter creation tool. We might also add tooltips to the labels in the GUI protocol tree, in which case the blurb would be used as the tooltip text.
1.5.1 字段注册
Protocol registration is handled by creating an instance of the header_field_info struct (or an array of such structs), and calling the registration function along with the registration ID of the protocol that is the parent of the fields. Here is a complete example:
static int proto_eg = -1;static int hf_field_a = -1;static int hf_field_b = -1;static hf_register_info hf[] = {{ &hf_field_a,{ "Field A", "proto.field_a", FT_UINT8, BASE_HEX, NULL,0xf0, "Field A represents Apples", HFILL }},{ &hf_field_b,{ "Field B", "proto.field_b", FT_UINT16, BASE_DEC, VALS(vs),0x0, "Field B represents Bananas", HFILL }}};proto_eg = proto_register_protocol("Example Protocol","PROTO", "proto");proto_register_field_array(proto_eg, hf, array_length(hf));
注意 hf_register_info 数组需要声明为 static 变量, 因为 proto_register_field_array() 函数并不会为它创建副本, 它仅仅使用编译器创建的 static 副本. hf_register_info 结构的布局如下:
typedef struct hf_register_info {int *p_id; /* pointer to parent variable */header_field_info hfinfo;} hf_register_info;
可使用 packet.h 中的 array_length() 宏在编译期计算此数组的长度.
如果不需要注册任何字段, 不要创建长度为 0 的 hf 数组; 并非所有的编译器都支持这种写法. 只需省略 hf 数组, 也别调用 proto_register_field_array() 就行了.
允许不同格式的字段以相同缩写进行注册, 如:
static hf_register_info hf[] = {{ &hf_field_8bit, /* 8-bit version of proto.field */{ "Field (8 bit)", "proto.field", FT_UINT8, BASE_DEC, NULL,0x00, "Field represents FOO", HFILL }},{ &hf_field_32bit, /* 32-bit version of proto.field */{ "Field (32 bit)", "proto.field", FT_UINT32, BASE_DEC, NULL,0x00, "Field represents FOO", HFILL }}};
This way a filter expression can match a header field, irrespective of the representation of it in the specific protocol context. This is interesting for protocols with variable-width header fields.
Note that the formats used must all belong to the same group as defined below:
- FT_INT8, FT_INT16, FT_INT24 and FT_INT32
- FT_CHAR, FT_UINT8, FT_UINT16, FT_UINT24, FT_UINT32, FT_IPXNET and FT_FRAMENUM
- FT_INT40, FT_INT48, FT_INT56 and FT_INT64
- FT_UINT40, FT_UINT48, FT_UINT56, FT_UINT64 and FT_EUI64
- FT_ABSOLUTE_TIME and FT_RELATIVE_TIME
- FT_STRING, FT_STRINGZ, FT_UINT_STRING, FT_STRINGZPAD, and FT_STRINGZTRUNC
- FT_FLOAT and FT_DOUBLE
- FT_BYTES, FT_UINT_BYTES, FT_ETHER, FT_AX25, FT_VINES and FT_FCWWN
- FT_OID, FT_REL_OID and FT_SYSTEM_ID
Any field not in a grouping above should NOT be used in duplicate field abbreviations. The current code does not prevent it, but someday in the future it might.
结构体末尾的 HFILL 宏会把其余内部保留字段设为合适的默认值.
1.5.2 向协议树中添加项
原标题: Adding Items and Values to the Protocol Tree
可通过 proto_XXX_DO_YYY() 形式的接口向已有的协议树添加协议项.
Subtrees can be made with the proto_item_add_subtree() function:
item = proto_tree_add_item(....);new_tree = proto_item_add_subtree(item, tree_type);
This will add a subtree under the item in question; a subtree can be created under an item made by any of the “proto_tree_add_XXX” functions, so that the tree can be given an arbitrary depth.
Subtree types are integers, assigned by “proto_register_subtree_array()”. To register subtree types, pass an array of pointers to “gint” variables to hold the subtree type values to “proto_register_subtree_array()”:
static gint ett_eg = -1;static gint ett_field_a = -1;static gint *ett[] = {&ett_eg,&ett_field_a};proto_register_subtree_array(ett, array_length(ett));
in your “register” routine, just as you register the protocol and the fields for that protocol. :::success ett: Ethreal Tree Type :::
The ett_ variables identify particular type of subtree so that if you expand one of them, Wireshark keeps track of that and, when you click on another packet, it automatically opens all subtrees of that type. If you close one of them, all subtrees of that type will be closed when you move to another packet.
There are several functions that the programmer can use to add either protocol or field labels to the proto_tree:
proto_item*proto_tree_add_item(tree, id, tvb, start, length, encoding);proto_item*proto_tree_add_item_ret_int(tree, id, tvb, start, length, encoding,*retval);proto_item*proto_tree_add_item_ret_uint(tree, id, tvb, start, length, encoding,*retval);proto_item*proto_tree_add_item_ret_uint64(tree, id, tvb, start, length, encoding,*retval);proto_item*proto_tree_add_item_ret_boolean(tree, id, tvb, start, length, encoding,*retval);proto_item*proto_tree_add_subtree(tree, tvb, start, length, idx, tree_item,text);proto_item*proto_tree_add_subtree_format(tree, tvb, start, length, idx, tree_item,format, ...);proto_item*proto_tree_add_none_format(tree, id, tvb, start, length, format, ...);proto_item*proto_tree_add_protocol_format(tree, id, tvb, start, length,format, ...);proto_item *proto_tree_add_bytes(tree, id, tvb, start, length, start_ptr);proto_item *proto_tree_add_bytes_item(tree, id, tvb, start, length, encoding,retval, endoff, err);proto_item *proto_tree_add_bytes_format(tree, id, tvb, start, length, start_ptr,format, ...);proto_item *proto_tree_add_bytes_format_value(tree, id, tvb, start, length,start_ptr, format, ...);proto_item *proto_tree_add_bytes_with_length(tree, id, tvb, start, tvb_length, start_ptr, ptr_length);proto_item *proto_tree_add_time(tree, id, tvb, start, length, value_ptr);proto_item *proto_tree_add_time_item(tree, id, tvb, start, length, encoding,retval, endoff, err);proto_item *proto_tree_add_time_format(tree, id, tvb, start, length, value_ptr,format, ...);proto_item *proto_tree_add_time_format_value(tree, id, tvb, start, length,value_ptr, format, ...);proto_item *proto_tree_add_ipxnet(tree, id, tvb, start, length, value);proto_item *proto_tree_add_ipxnet_format(tree, id, tvb, start, length, value,format, ...);proto_item *proto_tree_add_ipxnet_format_value(tree, id, tvb, start, length,value, format, ...);proto_item *proto_tree_add_ipv4(tree, id, tvb, start, length, value);proto_item *proto_tree_add_ipv4_format(tree, id, tvb, start, length, value,format, ...);proto_item *proto_tree_add_ipv4_format_value(tree, id, tvb, start, length,value, format, ...);proto_item *proto_tree_add_ipv6(tree, id, tvb, start, length, value_ptr);proto_item *proto_tree_add_ipv6_format(tree, id, tvb, start, length, value_ptr,format, ...);proto_item *proto_tree_add_ipv6_format_value(tree, id, tvb, start, length,value_ptr, format, ...);proto_item *proto_tree_add_ether(tree, id, tvb, start, length, value_ptr);proto_item *proto_tree_add_ether_format(tree, id, tvb, start, length, value_ptr,format, ...);proto_item *proto_tree_add_ether_format_value(tree, id, tvb, start, length,value_ptr, format, ...);proto_item *proto_tree_add_guid(tree, id, tvb, start, length, value_ptr);proto_item *proto_tree_add_guid_format(tree, id, tvb, start, length, value_ptr,format, ...);proto_item *proto_tree_add_guid_format_value(tree, id, tvb, start, length,value_ptr, format, ...);proto_item *proto_tree_add_oid(tree, id, tvb, start, length, value_ptr);proto_item *proto_tree_add_oid_format(tree, id, tvb, start, length, value_ptr,format, ...);proto_item *proto_tree_add_oid_format_value(tree, id, tvb, start, length,value_ptr, format, ...);proto_item *proto_tree_add_string(tree, id, tvb, start, length, value_ptr);proto_item *proto_tree_add_string_format(tree, id, tvb, start, length, value_ptr,format, ...);proto_item *proto_tree_add_string_format_value(tree, id, tvb, start, length,value_ptr, format, ...);proto_item *proto_tree_add_boolean(tree, id, tvb, start, length, value);proto_item *proto_tree_add_boolean_format(tree, id, tvb, start, length, value,format, ...);proto_item *proto_tree_add_boolean_format_value(tree, id, tvb, start, length,value, format, ...);proto_item *proto_tree_add_float(tree, id, tvb, start, length, value);proto_item *proto_tree_add_float_format(tree, id, tvb, start, length, value,format, ...);proto_item *proto_tree_add_float_format_value(tree, id, tvb, start, length,value, format, ...);proto_item *proto_tree_add_double(tree, id, tvb, start, length, value);proto_item *proto_tree_add_double_format(tree, id, tvb, start, length, value,format, ...);proto_item *proto_tree_add_double_format_value(tree, id, tvb, start, length,value, format, ...);proto_item *proto_tree_add_uint(tree, id, tvb, start, length, value);proto_item *proto_tree_add_uint_format(tree, id, tvb, start, length, value,format, ...);proto_item *proto_tree_add_uint_format_value(tree, id, tvb, start, length,value, format, ...);proto_item *proto_tree_add_uint64(tree, id, tvb, start, length, value);proto_item *proto_tree_add_uint64_format(tree, id, tvb, start, length, value,format, ...);proto_item *proto_tree_add_uint64_format_value(tree, id, tvb, start, length,value, format, ...);proto_item *proto_tree_add_int(tree, id, tvb, start, length, value);proto_item *proto_tree_add_int_format(tree, id, tvb, start, length, value,format, ...);proto_item *proto_tree_add_int_format_value(tree, id, tvb, start, length,value, format, ...);proto_item *proto_tree_add_int64(tree, id, tvb, start, length, value);proto_item *proto_tree_add_int64_format(tree, id, tvb, start, length, value,format, ...);proto_item *proto_tree_add_int64_format_value(tree, id, tvb, start, length,value, format, ...);proto_item *proto_tree_add_eui64(tree, id, tvb, start, length, value);proto_item *proto_tree_add_eui64_format(tree, id, tvb, start, length, value,format, ...);proto_item *proto_tree_add_eui64_format_value(tree, id, tvb, start, length,value, format, ...);proto_item *proto_tree_add_checksum(proto_tree *tree, tvbuff_t *tvb, const guint offset,const int hf_checksum, const int hf_checksum_status, struct expert_field* bad_checksum_expert,packet_info *pinfo, guint32 computed_checksum, const guint encoding, const guint flags);proto_item *proto_tree_add_bitmask(tree, tvb, start, header, ett, fields,encoding);proto_item *proto_tree_add_bitmask_len(tree, tvb, start, len, header, ett, fields,exp, encoding);proto_item *proto_tree_add_bitmask_text(tree, tvb, offset, len, name, fallback,ett, fields, encoding, flags);proto_item *proto_tree_add_bitmask_with_flags(tree, tvb, offset, hf_hdr, ett,fields, encoding, flags);proto_item*proto_tree_add_bits_item(tree, id, tvb, bit_offset, no_of_bits,encoding);proto_item *proto_tree_add_split_bits_item_ret_val(tree, hf_index, tvb, bit_offset,crumb_spec, return_value);voidproto_tree_add_split_bits_crumb(tree, hf_index, tvb, bit_offset,crumb_spec, crumb_index);proto_item *proto_tree_add_bits_ret_val(tree, id, tvb, bit_offset, no_of_bits,return_value, encoding);proto_item *proto_tree_add_uint_bits_format_value(tree, id, tvb, bit_offset,no_of_bits, value, format, ...);proto_item *proto_tree_add_boolean_bits_format_value(tree, id, tvb, bit_offset,no_of_bits, value, format, ...);proto_item *proto_tree_add_int_bits_format_value(tree, id, tvb, bit_offset,no_of_bits, value, format, ...);proto_item *proto_tree_add_float_bits_format_value(tree, id, tvb, bit_offset,no_of_bits, value, format, ...);proto_item *proto_tree_add_ts_23_038_7bits_item(tree, hf_index, tvb,bit_offset, no_of_chars);
The ‘tree’ argument is the tree to which the item is to be added. The ‘tvb’ argument is the tvbuff from which the item’s value is being extracted; the ‘start’ argument is the offset from the beginning of that tvbuff of the item being added, and the ‘length’ argument is the length, in bytes, of the item, bit_offset is the offset in bits and no_of_bits is the length in bits.
The length of some items cannot be determined until the item has been dissected; to add such an item, add it with a length of -1, and, when the dissection is complete, set the length with ‘proto_item_set_len()’:
voidproto_item_set_len(ti, length);
The “ti” argument is the value returned by the call that added the item to the tree, and the “length” argument is the length of the item.
prototree_add_item()
——————————-
proto_tree_add_item is used when you wish to do no special formatting. The item added to the GUI tree will contain the name (as passed in the proto_register*() function) and a value. The value will be fetched from the tvbuff by proto_tree_add_item(), based on the type of the field and the encoding of the value as specified by the “encoding” argument.
For FT_NONE, FT_BYTES, FT_ETHER, FT_IPv6, FT_IPXNET, FT_OID, FT_REL_OID, FT_AX25, FT_VINES, FT_SYSTEM_ID, FT_FCWWN fields, and ‘protocol’ fields the encoding is not relevant; the ‘encoding’ argument should be ENC_NA (Not Applicable).
For FT_UINT_BYTES fields, the byte order of the count must be specified as well as the ‘encoding’ for bytes which should be ENC_NA, i.e. ENC_LITTLE_ENDIAN|ENC_NA
For integral, floating-point, Boolean, FT_GUID, and FT_EUI64 fields, the encoding specifies the byte order of the value; the ‘encoding’ argument should be ENC_LITTLE_ENDIAN if the value is little-endian and ENC_BIG_ENDIAN if it is big-endian.
For FT_IPv4 fields, the encoding also specifies the byte order of the value. In almost all cases, the encoding is in network byte order, hence big-endian, but in at least one protocol dissected by Wireshark, at least one IPv4 address is byte-swapped, so it’s in little-endian order.
For string fields, the encoding specifies the character set used for the string and the way individual code points in that character set are encoded. For FT_UINT_STRING fields, the byte order of the count must be
specified; for UCS-2 and UTF-16, the byte order of the encoding must be specified (for counted UCS-2 and UTF-16 strings, the byte order of the count and the 16-bit values in the string must be the same). In other cases, ENC_NA should be used. The character encodings that are currently supported are:
ENC_ASCII - ASCII (currently treated as UTF-8; in the future,all bytes with the 8th bit set will be treated aserrors)ENC_UTF_8 - UTF-8-encoded UnicodeENC_UTF_16 - UTF-16-encoded Unicode, with surrogate pairsENC_UCS_2 - UCS-2-encoded subset of Unicode, with no surrogate pairsand thus no code points above 0xFFFFENC_UCS_4 - UCS-4-encoded UnicodeENC_WINDOWS_1250 - Windows-1250 code pageENC_WINDOWS_1251 - Windows-1251 code pageENC_WINDOWS_1252 - Windows-1252 code pageENC_ISO_646_BASIC - ISO 646 "basic code table"ENC_ISO_8859_1 - ISO 8859-1ENC_ISO_8859_2 - ISO 8859-2ENC_ISO_8859_3 - ISO 8859-3ENC_ISO_8859_4 - ISO 8859-4ENC_ISO_8859_5 - ISO 8859-5ENC_ISO_8859_6 - ISO 8859-6ENC_ISO_8859_7 - ISO 8859-7ENC_ISO_8859_8 - ISO 8859-8ENC_ISO_8859_9 - ISO 8859-9ENC_ISO_8859_10 - ISO 8859-10ENC_ISO_8859_11 - ISO 8859-11ENC_ISO_8859_13 - ISO 8859-13ENC_ISO_8859_14 - ISO 8859-14ENC_ISO_8859_15 - ISO 8859-15ENC_ISO_8859_16 - ISO 8859-16ENC_3GPP_TS_23_038_7BITS - GSM 7 bits alphabet as describedin 3GPP TS 23.038ENC_3GPP_TS_23_038_7BITS_UNPACKED - GSM 7 bits alphabet where each7 bit character occupies a distinct octetENC_ETSI_TS_102_221_ANNEX_A - Coding scheme for SIM cards with GSM 7 bitalphabet, UCS-2 characters, or a mixture of the two as describedin ETSI TS 102 221 Annex AENC_EBCDIC - EBCDICENC_EBCDIC_CP037 - EBCDIC code page 037ENC_MAC_ROMAN - MAC ROMANENC_CP437 - DOS code page 437ENC_CP855 - DOS code page 855ENC_CP866 - DOS code page 866ENC_ASCII_7BITS - 7 bits ASCIIENC_T61 - ITU T.61ENC_BCD_DIGITS_0_9 - packed BCD (one digit per nibble), digits 0-9ENC_KEYPAD_ABC_TBCD - keypad-with-a/b/c "telephony packed BCD" = 0-9, *, #, a, b, cENC_KEYPAD_BC_TBCD - keypad-with-B/C "telephony packed BCD" = 0-9, B, C, *, #ENC_GB18030 - GB 18030ENC_EUC_KR - EUC-KR
Other encodings will be added in the future.
For FT_ABSOLUTE_TIME fields, the encoding specifies the form in which the time stamp is specified, as well as its byte order. The time stamp encodings that are currently supported are:
ENC_TIME_SECS_NSECS - 8, 12, or 16 bytes. For 8 bytes, the first 4bytes are seconds and the next 4 bytes are nanoseconds; for 12bytes, the first 8 bytes are seconds and the next 4 bytes arenanoseconds; for 16 bytes, the first 8 bytes are seconds andthe next 8 bytes are nanoseconds. The seconds are secondssince the UN*X epoch (1970-01-01 00:00:00 UTC). (I.e., a UN*Xstruct timespec with a 4-byte or 8-byte time_t or a structurewith an 8-byte time_t and an 8-byte nanoseconds field.)ENC_TIME_NTP - 8 bytes; the first 4 bytes are seconds since the NTPepoch (1900-01-01 00:00:00 GMT) and the next 4 bytes are 1/2^32's ofa second since that second. (I.e., a 64-bit count of 1/2^32's of asecond since the NTP epoch, with the upper 32 bits first and thelower 32 bits second, even when little-endian.)ENC_TIME_TOD - 8 bytes, as a count of microseconds since the System/3x0and z/Architecture epoch (1900-01-01 00:00:00 GMT).ENC_TIME_RTPS - 8 bytes; the first 4 bytes are seconds since the UN*Xepoch and the next 4 bytes are are 1/2^32's of a second since thatsecond. (I.e., it's the offspring of a mating between UN*X time andNTP time). It's used by the Object Management Group's Real-TimePublish-Subscribe Wire Protocol for the Data Distribution Service.ENC_TIME_SECS_USECS - 8 bytes; the first 4 bytes are seconds since theUN*X epoch and the next 4 bytes are microseconds since thatsecond. (I.e., a UN*X struct timeval with a 4-byte time_t.)ENC_TIME_SECS - 4 to 8 bytes, representing a value in seconds sincethe UN*X epoch.ENC_TIME_MSECS - 6 to 8 bytes, representing a value in millisecondssince the UN*X epoch.ENC_TIME_SECS_NTP - 4 bytes, representing a count of seconds sincethe NTP epoch. (I.e., seconds since the NTP epoch.)ENC_TIME_RFC_3971 - 8 bytes, representing a count of 1/64ths of asecond since the UN*X epoch; see section 5.3.1 "Timestamp Option"in RFC 3971.ENC_TIME_MSEC_NTP - 4-8 bytes, representing a count of milliseconds sincethe NTP epoch. (I.e., milliseconds since the NTP epoch.)
For FT_RELATIVE_TIME fields, the encoding specifies the form in which the time stamp is specified, as well as its byte order. The time stamp encodings that are currently supported are:
ENC_TIME_SECS_NSECS - 8, 12, or 16 bytes. For 8 bytes, the first 4bytes are seconds and the next 4 bytes are nanoseconds; for 12bytes, the first 8 bytes are seconds and the next 4 bytes arenanoseconds; for 16 bytes, the first 8 bytes are seconds andthe next 8 bytes are nanoseconds.ENC_TIME_SECS_USECS - 8 bytes; the first 4 bytes are seconds and thenext 4 bytes are microseconds.ENC_TIME_SECS - 4 to 8 bytes, representing a value in seconds.ENC_TIME_MSECS - 6 to 8 bytes, representing a value in milliseconds.
For other types, there is no support for proto_tree_add_item().
Now that definitions of fields have detailed information about bitfield fields, you can use proto_tree_add_item() with no extra processing to add bitfield values to your tree. Here’s an example. Take the Format Identifier (FID) field in the Transmission Header (TH) portion of the SNA protocol. The FID is the high nibble of the first byte of the TH. The FID would be registered like this:
name = "Format Identifier"abbrev = "sna.th.fid"type = FT_UINT8display = BASE_HEXstrings = sna_th_fid_valsbitmask = 0xf0
The bitmask contains the value which would leave only the FID if bitwise-ANDed against the parent field, the first byte of the TH.
The code to add the FID to the tree would be;
proto_tree_add_item(bf_tree, hf_sna_th_fid, tvb, offset, 1,ENC_BIG_ENDIAN);
The definition of the field already has the information about bitmasking and bitshifting, so it does the work of masking and shifting for us! This also means that you no longer have to create value_string structs with the values bitshifted. The value_string for FID looks like this, even though the FID value is actually contained in the high nibble. (You’d expect the values to be 0x0, 0x10, 0x20, etc.)
/* Format Identifier */static const value_string sna_th_fid_vals[] = {{ 0x0, "SNA device <--> Non-SNA Device" },{ 0x1, "Subarea Node <--> Subarea Node" },{ 0x2, "Subarea Node <--> PU2" },{ 0x3, "Subarea Node or SNA host <--> Subarea Node" },{ 0x4, "?" },{ 0x5, "?" },{ 0xf, "Adjacent Subarea Nodes" },{ 0, NULL }};
The final implication of this is that display filters work the way you’d naturally expect them to. You’d type “sna.th.fid == 0xf” to find Adjacent Subarea Nodes. The user does not have to shift the value of the FID to the high nibble of the byte (“sna.th.fid == 0xf0”) as was necessary in the past.
prototree_add_item_ret_XXX()
———————————————
proto_tree_add_item_ret_XXX is used when you want the displayed value returned for further processing only integer and unsigned integer types up to 32 bits are supported usage of proper FT is checked.
prototree_add_XXX_item()
——————————-
proto_tree_add_XXX_item is used when you wish to do no special formatting, but also either wish for the retrieved value from the tvbuff to be handed back (to avoid doing tvb_get…), and/or wish to have the value be decoded from the tvbuff in a string-encoded format.
The item added to the GUI tree will contain the name (as passed in the protoregister*() function) and a value. The value will be fetched from the tvbuff, based on the type of the XXX name and the encoding of the value as specified by the “encoding” argument.
This function retrieves the value even if the passed-in tree param is NULL, so that it can be used by dissectors at all times to both get the value and set the tree item to it.
Like other proto_tree_add functions, if there is a tree and the value cannot be decoded from the tvbuff, then an expert info error is reported. For string encoding, this means that a failure to decode the hex value from the string results in an expert info error being added to the tree.
For string-decoding, the passed-in encoding argument needs to specify the string encoding (e.g., ENCASCII, ENC_UTF_8) as well as the format. For some XXX types, the format is constrained - for example for the encoding format for proto_tree_add_time_item() can only be one of the ENC_ISO_8601 ones or ENCRFC_822 or ENC_RFC_1123. For proto_tree_add_bytes_item() it can only be ENC_STR_HEX bit-or’ed with one or more of the ENC_SEP separator types.
proto_tree_add_protocol_format()
————————————————
proto_tree_add_protocol_format is used to add the top-level item for the protocol when the dissector routine wants complete control over how the field and value will be represented on the GUI tree. The ID value for
the protocol is passed in as the “id” argument; the rest of the arguments are a “printf”-style format and any arguments for that format. The caller must include the name of the protocol in the format; it is not added automatically as in proto_tree_add_item().
proto_tree_add_none_format()
——————————————
proto_tree_add_none_format is used to add an item of type FT_NONE. The caller must include the name of the field in the format; it is not added automatically as in proto_tree_add_item().
proto_tree_add_bytes()
proto_tree_add_time()
proto_tree_add_ipxnet()
proto_tree_add_ipv4()
proto_tree_add_ipv6()
proto_tree_add_ether()
proto_tree_add_string()
proto_tree_add_boolean()
proto_tree_add_float()
proto_tree_add_double()
proto_tree_add_uint()
proto_tree_add_uint64()
proto_tree_add_int()
proto_tree_add_int64()
proto_tree_add_guid()
proto_tree_add_oid()
proto_tree_add_eui64()
————————————
These routines are used to add items to the protocol tree if either:
the value of the item to be added isn't just extracted from the packet data, but is computed from data in the packet;the value was fetched into a variable.
The ‘value’ argument has the value to be added to the tree.
NOTE: in all cases where the ‘value’ argument is a pointer, a copy is made of the object pointed to; if you have dynamically allocated a buffer for the object, that buffer will not be freed when the protocol tree is freed - you must free the buffer yourself when you don’t need it any more.
For proto_tree_add_bytes(), the ‘value_ptr’ argument is a pointer to a sequence of bytes.
proto_tree_add_bytes_with_length() is similar to proto_tree_add_bytes, except that the length is not derived from the tvb length. Instead, the displayed data size is controlled by ‘ptr_length’.
For proto_tree_add_bytes_format() and proto_tree_add_bytes_format_value(), the ‘value_ptr’ argument is a pointer to a sequence of bytes or NULL if the bytes should be taken from the given TVB using the given offset and length.
For proto_tree_add_time(), the ‘value_ptr’ argument is a pointer to an “nstime_t”, which is a structure containing the time to be added; it has ‘secs’ and ‘nsecs’ members, giving the integral part and the fractional part of a time in units of seconds, with ‘nsecs’ being the number of nanoseconds. For absolute times, “secs” is a UNIX-style seconds since January 1, 1970, 00:00:00 GMT value.
For proto_tree_add_ipxnet(), the ‘value’ argument is a 32-bit IPX network address.
For proto_tree_add_ipv4(), the ‘value’ argument is a 32-bit IPv4 address, in network byte order.
For proto_tree_add_ipv6(), the ‘value_ptr’ argument is a pointer to a 128-bit IPv6 address.
For proto_tree_add_ether(), the ‘value_ptr’ argument is a pointer to a 48-bit MAC address.
For proto_tree_add_string(), the ‘value_ptr’ argument is a pointer to a text string; this string must be NULL terminated even if the string in the TVB is not (as may be the case with FT_STRINGs).
For proto_tree_add_boolean(), the ‘value’ argument is a 32-bit integer. It is masked and shifted as defined by the field info after which zero means “false”, and non-zero means “true”.
For proto_tree_add_float(), the ‘value’ argument is a ‘float’ in the host’s floating-point format.
For proto_tree_add_double(), the ‘value’ argument is a ‘double’ in the host’s floating-point format.
For proto_tree_add_uint(), the ‘value’ argument is a 32-bit unsigned integer value, in host byte order. (This routine cannot be used to add 64-bit integers.)
For proto_tree_add_uint64(), the ‘value’ argument is a 64-bit unsigned integer value, in host byte order.
For proto_tree_add_int(), the ‘value’ argument is a 32-bit signed integer value, in host byte order. (This routine cannot be used to add 64-bit integers.)
For proto_tree_add_int64(), the ‘value’ argument is a 64-bit signed integer value, in host byte order.
For proto_tree_add_guid(), the ‘value_ptr’ argument is a pointer to an e_guid_t structure.
For proto_tree_add_oid(), the ‘value_ptr’ argument is a pointer to an ASN.1 Object Identifier.
For proto_tree_add_eui64(), the ‘value’ argument is a 64-bit integer value
proto_tree_add_bytes_format()
proto_tree_add_time_format()
proto_tree_add_ipxnet_format()
proto_tree_add_ipv4_format()
proto_tree_add_ipv6_format()
proto_tree_add_ether_format()
proto_tree_add_string_format()
proto_tree_add_boolean_format()
proto_tree_add_float_format()
proto_tree_add_double_format()
proto_tree_add_uint_format()
proto_tree_add_uint64_format()
proto_tree_add_int_format()
proto_tree_add_int64_format()
proto_tree_add_guid_format()
proto_tree_add_oid_format()
proto_tree_add_eui64_format()
——————————————
These routines are used to add items to the protocol tree when the dissector routine wants complete control over how the field and value will be represented on the GUI tree. The argument giving the value is the same as the corresponding proto_tree_add_XXX() function; the rest of the arguments are a “printf”-style format and any arguments for that format. The caller must include the name of the field in the format; it is not added automatically as in the proto_tree_add_XXX() functions.
proto_tree_add_bytes_format_value()
proto_tree_add_time_format_value()
proto_tree_add_ipxnet_format_value()
proto_tree_add_ipv4_format_value()
proto_tree_add_ipv6_format_value()
proto_tree_add_ether_format_value()
proto_tree_add_string_format_value()
proto_tree_add_boolean_format_value()
proto_tree_add_float_format_value()
proto_tree_add_double_format_value()
proto_tree_add_uint_format_value()
proto_tree_add_uint64_format_value()
proto_tree_add_int_format_value()
proto_tree_add_int64_format_value()
proto_tree_add_guid_format_value()
proto_tree_add_oid_format_value()
proto_tree_add_eui64_format_value()
——————————————————
These routines are used to add items to the protocol tree when the dissector routine wants complete control over how the value will be represented on the GUI tree. The argument giving the value is the same as the corresponding prototree_add_XXX() function; the rest of the arguments are a “printf”-style format and any arguments for that format. With these routines, unlike the proto_tree_add_XXX_format() routines, the name of the field is added automatically as in the proto_tree_add_XXX() functions; only the value is added with the format. One use case for this would be to add a unit of measurement string to the value of the field, however using BASE_UNIT_STRING in the hf definition is now preferred.
proto_tree_add_checksum()
——————————————
proto_tree_add_checksum is used to add a checksum field. The hf field provided must be the correct size of the checksum (FT_UINT, FT_UINT16, FT_UINT32, etc). Additional parameters are there to provide “status” and expert info depending on whether the checksum matches the provided value. The “status” and expert info can be used in cases except where PROTO_CHECKSUM_NO_FLAGS is used.
proto_tree_add_subtree()
——————————-
proto_tree_add_subtree() is used to add a label to the GUI tree and create a subtree for other fields. It will contain no value, so it is not searchable in the display filter process.
This should only be used for items with subtrees, which may not have values themselves - the items in the subtree are the ones with values.
For a subtree, the label on the subtree might reflect some of the items in the subtree. This means the label can’t be set until at least some of the items in the subtree have been dissected. To do this, use ‘proto_item_set_text()’ or ‘proto_item_append_text()’:
voidproto_item_set_text(proto_item *ti, ...);voidproto_item_append_text(proto_item *ti, ...);
‘proto_item_set_text()’ takes as an argument the proto_item value returned by one of the parameters in ‘proto_tree_add_subtree()’, a ‘printf’-style format string, and a set of arguments corresponding to ‘%’ format items in that string, and replaces the text for the item created by ‘proto_tree_add_subtree()’ with the result of applying the arguments to the format string.
‘proto_item_append_text()’ is similar, but it appends to the text for the item the result of applying the arguments to the format string.
For example, early in the dissection, one might do:
subtree = proto_tree_add_subtree(tree, tvb, offset, length, ett, &ti, <label>);
and later do
proto_item_set_text(ti, "%s: %s", type, value);
<br />after the "type" and "value" fields have been extracted and dissected. <label> would be a label giving what information about the subtree is available without dissecting any of the data in the subtree.
Note that an exception might be thrown when trying to extract the values of the items used to set the label, if not all the bytes of the item are available. Thus, one should create the item with text that is as meaningful as possible, and set it or append additional information to it as the values needed to supply that information are extracted.
proto_tree_add_subtree_format()
——————————————
This is like proto_tree_add_subtree(), but uses printf-style arguments to create the label; it is used to allow routines that take a printf-like variable-length list of arguments to add a text item to the protocol tree.
prototree_add_bits_item()
—————————————
Adds a number of bits to the protocol tree which does not have to be byte aligned. The offset and length is in bits.
Output format:
`..10 1010 10.. …. “value” (formatted as FT indicates).`
proto_tree_add_bits_ret_val()
——————————————-
Works in the same way but also returns the value of the read bits.
proto_tree_add_split_bits_item_ret_val()
—————————————————-
Similar, but is used for items that are made of 2 or more smaller sets of bits (crumbs) which are not contiguous, but are concatenated to form the actual value. The size of the crumbs and the order of assembly are specified in an array of crumb_spec structures.
proto_tree_add_split_bits_crumb()
————————————————-
Helper function for the above, to add text for each crumb as it is encountered.
proto_tree_add_ts_23_038_7bits_item()
——————————————————-
Adds a string of a given number of characters and encoded according to 3GPP TS 23.038 7 bits alphabet.
proto_tree_add_bitmask() et al.
———————————————-
These functions provide easy to use and convenient dissection of many types of common bitmasks into individual fields.
header is an integer type and must be of type FT_[U]INT{8|16|24|32||40|48|56|64} and represents the entire dissectable width of the bitmask.
‘header’ and ‘ett’ are the hf fields and ett field respectively to create an expansion that covers the bytes of the bitmask.
‘fields’ is a NULL terminated array of pointers to hf fields representing the individual subfields of the bitmask. These fields must either be integers (usually of the same byte width as ‘header’) or of the type FT_BOOLEAN. Each of the entries in ‘fields’ will be dissected as an item under the ‘header’ expansion and also IF the field is a boolean and IF it is set to 1, then the name of that boolean field will be printed on the ‘header’ expansion line. For integer type subfields that have a value_string defined, the matched string from that value_string will be printed on the expansion line as well.
Example: (from the SCSI dissector)
static int hf_scsi_inq_peripheral = -1;static int hf_scsi_inq_qualifier = -1;static int hf_scsi_inq_devtype = -1;...static gint ett_scsi_inq_peripheral = -1;...static int * const peripheral_fields[] = {&hf_scsi_inq_qualifier,&hf_scsi_inq_devtype,NULL};.../* Qualifier and DeviceType */proto_tree_add_bitmask(tree, tvb, offset, hf_scsi_inq_peripheral,ett_scsi_inq_peripheral, peripheral_fields, ENC_BIG_ENDIAN);offset+=1;...{ &hf_scsi_inq_peripheral,{"Peripheral", "scsi.inquiry.peripheral", FT_UINT8, BASE_HEX,NULL, 0, NULL, HFILL}},{ &hf_scsi_inq_qualifier,{"Qualifier", "scsi.inquiry.qualifier", FT_UINT8, BASE_HEX,VALS (scsi_qualifier_val), 0xE0, NULL, HFILL}},{ &hf_scsi_inq_devtype,{"Device Type", "scsi.inquiry.devtype", FT_UINT8, BASE_HEX,VALS (scsi_devtype_val), SCSI_DEV_BITS, NULL, HFILL}},...
Which provides very pretty dissection of this one byte bitmask.
Peripheral: 0x05, Qualifier: Device type is connected to logical unit, Device Type: CD-ROM
000. .... = Qualifier: Device type is connected to logical unit (0x00)
...0 0101 = Device Type: CD-ROM (0x05)
The proto_tree_add_bitmask_text() function is an extended version of the proto_tree_add_bitmask() function. In addition, it allows to:
- Provide a leading text (e.g. “Flags: “) that will appear before the comma-separated list of field values
- Provide a fallback text (e.g. “None”) that will be appended if no fields warranted a change to the top-level title.
- Using flags, specify which fields will affect the top-level title.
There are the following flags defined:
- BMT_NO_APPEND - the title is taken “as-is” from the ‘name’ argument.
- BMT_NO_INT - only boolean flags are added to the title.
- BMT_NO_FALSE - boolean flags are only added to the title if they are set.
- BMT_NO_TFS - only add flag name to the title, do not use true_false_string
The prototree_add_bitmask_with_flags() function is an extended version of the proto_tree_add_bitmask() function. It allows using flags to specify which fields will affect the top-level title. The flags are the same BMT_NO* flags as used in the proto_tree_add_bitmask_text() function.
The proto_tree_add_bitmask() behavior can be obtained by providing both ‘name’ and ‘fallback’ arguments as NULL, and a flags of (BMT_NO_FALSE|BMT_NO_TFS).
The proto_tree_add_bitmask_len() function is intended for protocols where bitmask length is permitted to vary, so a length is specified explicitly along with the bitmask value. USB Video “bmControl” and “bControlSize” fields follow this pattern. The primary intent of this is “forward compatibility,” enabling an interpreter coded for version M of a structure to comprehend fields in version N of the structure, where N > M and bControlSize increases from version M to version N.
proto_tree_add_bitmask_len() is an extended version of proto_tree_add_bitmask() that uses an explicitly specified (rather than inferred) length to control dissection. Because of this, it may encounter two cases that
proto_tree_add_bitmask() and proto_tree_add_bitmask_text() may not:
- A length that exceeds that of the ‘header’ and bitmask subfields.
In this case the least-significant bytes of the bitmask are dissected.
An expert warning is generated in this case, because the dissection code
likely needs to be updated for a new revision of the protocol.
- A length that is shorter than that of the ‘header’ and bitmask subfields.
In this case, subfields whose data is fully present are dissected,
and other subfields are not. No warning is generated in this case,
because the dissection code is likely for a later revision of the protocol
than the packet it was called to interpret.
proto_item_set_generated()
—————————————
proto_item_set_generated is used to mark fields as not being read from the captured data directly, but inferred from one or more values.
One of the primary uses of this is the presentation of verification of checksums. Every IP packet has a checksum line, which can present the result of the checksum verification, if enabled in the preferences. The result is presented as a subtree, where the result is enclosed in square brackets indicating a generated field.
Header checksum: 0x3d42 [correct]
[Checksum Status: Good (1)]
proto_item_set_hidden()
———————————-
proto_item_set_hidden is used to hide fields, which have already been added to the tree, from being visible in the displayed tree.
NOTE that creating hidden fields is actually quite a bad idea from a UI design perspective because the user (someone who did not write nor has ever seen the code) has no way of knowing that hidden fields are there to be filtered on thus defeating the whole purpose of putting them there. A Better Way might be to add the fields (that might otherwise be hidden) to a subtree where they won’t be seen unless the user opens the subtree—but they can be found if the user wants.
One use for hidden fields (which would be better implemented using visible fields in a subtree) follows: The caller may want a value to be included in a tree so that the packet can be filtered on this field, but the representation of that field in the tree is not appropriate. An example is the token-ring routing information field (RIF). The best way to show the RIF in a GUI is by a sequence of ring and bridge numbers. Rings are 3-digit hex numbers, and bridges are single hex digits:
RIF: 001-A-013-9-C0F-B-555
In the case of RIF, the programmer should use a field with no value and use proto_tree_add_none_format() to build the above representation. The programmer can then add the ring and bridge values, one-by-one, with
proto_tree_add_item() and hide them with proto_item_set_hidden() so that the user can then filter on or search for a particular ring or bridge. Here’s a skeleton of how the programmer might code this.
char *rif;rif = create_rif_string(...);proto_tree_add_none_format(tree, hf_tr_rif_label, ..., "RIF: %s", rif);for(i = 0; i < num_rings; i++) {proto_item *pi;pi = proto_tree_add_item(tree, hf_tr_rif_ring, ...,ENC_BIG_ENDIAN);proto_item_set_hidden(pi);}for(i = 0; i < num_rings - 1; i++) {proto_item *pi;pi = proto_tree_add_item(tree, hf_tr_rif_bridge, ...,ENC_BIG_ENDIAN);proto_item_set_hidden(pi);}
The logical tree has these items:
hf_tr_rif_label, text="RIF: 001-A-013-9-C0F-B-555", value = NONEhf_tr_rif_ring, hidden, value=0x001hf_tr_rif_bridge, hidden, value=0xAhf_tr_rif_ring, hidden, value=0x013hf_tr_rif_bridge, hidden, value=0x9hf_tr_rif_ring, hidden, value=0xC0Fhf_tr_rif_bridge, hidden, value=0xBhf_tr_rif_ring, hidden, value=0x555
GUI or print code will not display the hidden fields, but a display filter or “packet grep” routine will still see the values. The possible filter is then possible:
tr.rif_ring eq 0x013
proto_item_set_url
—————————
proto_item_set_url is used to mark fields as containing a URL. This can only be done with fields of type FT_STRING(Z). If these fields are presented they are underlined, as could be done in a browser. These fields are sensitive to clicks as well, launching the configured browser with this URL as parameter.
1.6 工具函数
原标题: Utility routines
1.6.1 val_to_str, val_to_str_const, try_val_to_str, try_val_to_str_idx
A dissector may need to convert a value to a string, using a ‘value_string’ structure, by hand, rather than by declaring a field with an associated ‘value_string’ structure; this might be used, for example, to generate a COL_INFO line for a frame.
val_to_str() handles the most common case:
const gchar*val_to_str(guint32 val, const value_string *vs, const char *fmt)
If the value ‘val’ is found in the ‘value_string’ table pointed to by ‘vs’, ‘val_to_str’ will return the corresponding string; otherwise, it will use ‘fmt’ as an ‘sprintf’-style format, with ‘val’ as an argument, to generate a string, and will return a pointer to that string. You can use it in a call to generate a COL_INFO line for a frame such as
col_add_fstr(COL_INFO, ", %s", val_to_str(val, table, "Unknown %d"));
If you don’t need to display ‘val’ in your fmt string, you can use val_to_str_const() which just takes a string constant instead and returns it unmodified when ‘val’ isn’t found.
If you need to handle the failure case in some custom way, try_val_to_str() will return NULL if val isn’t found:
const gchar*try_val_to_str(guint32 val, const value_string *vs)
Note that, you must check whether ‘try_val_to_str()’ returns NULL, and arrange that its return value not be dereferenced if it’s NULL. ‘try_val_to_str_idx()’ behaves similarly, except it also returns an index into the value_string array, or -1 if ‘val’ was not found.
The *_ext functions are “extended” versions of those already described. They should be used for large value-string arrays which contain many entries. They implement value to string conversions which will do either a direct access or a binary search of the value string array if possible. See “Extended Value Strings” under section 1.6 “Constructing the protocol tree” for more information.
See epan/value_string.h for detailed information on the various value_string functions.
To handle 64-bit values, there are an equivalent set of functions. These are:
const gchar *val64_to_str(const guint64 val, const val64_string *vs, const char *fmt)const gchar *val64_to_str_const(const guint64 val, const val64_string *vs, const char *unknown_str);const gchar *try_val64_to_str(const guint64 val, const val64_string *vs);const gchar *try_val64_to_str_idx(const guint64 val, const val64_string *vs, gint *idx);
1.6.2 rval_to_str, try_rval_to_str, try_rval_to_str_idx
A dissector may need to convert a range of values to a string, using a ‘range_string’ structure.
Most of the same functions exist as with regular value_strings (see section 1.6.1) except with the names ‘rval’ instead of ‘val’.
1.7 调用其他解析器
当每个解析器完成它负责的协议解析时, 需要创建新的 TVBUFF_SUBSET 类型的 tvbuff, 它包含当前协议的 payload (即与下一个解析器有关的数据).
可通过 tvbuff_new_subset_remaining() 完成这一工作:
next_tvb = tvb_new_subset_remaining(tvb, offset);
Where:
- tvb is the tvbuff that the dissector has been working on. I can be a tvbuff of any type.
- next_tvb is the new TVBUFF_SUBSET.
- offset is the byte offset of ‘tvb’ at which the new tvbuff should start. The first byte is the 0th byte.
也可以用 tvbuff_new_subset_length() :
next_tvb = tvb_new_subset_length(tvb, offset, reported_length);
Where:
- tvb is the tvbuff that the dissector has been working on. It can be a tvbuff of any type.
- next_tvb is the new TVBUFF_SUBSET.
- offset is the byte offset of ‘tvb’ at which the new tvbuff should start. The first byte is the 0th byte.
- reported_length is the number of bytes that the current protocol says should be in the payload.
In the few cases where the number of bytes available in the new subset must be explicitly specified, rather than being calculated based on the number of bytes in the payload, the routine tvb_new_subset_length_caplen() is used:
next_tvb = tvb_new_subset_length_caplen(tvb, offset, length, reported_length);
Where:
- tvb is the tvbuff that the dissector has been working on. It can be a tvbuff of any type.
- next_tvb is the new TVBUFF_SUBSET.
- offset is the byte offset of ‘tvb’ at which the new tvbuff should start. The first byte is the 0th byte.
- length is the number of bytes in the new TVBUFF_SUBSET. A length argument of -1 says to use as many bytes as are available in ‘tvb’.
- reported_length is the number of bytes that the current protocol says should be in the payload. A reported_length of -1 says that the protocol doesn’t say anything about the size of its payload.
要调用某个解析器, 需要通过 find_dissector() 获取它的句柄, 参数是解析器名. 句柄通常在 Wireshark 初始化阶段, 在调用方解析器的 proto_reg_handoff 函数中就被初始化了.
1.7.1 解析器表
调用子解析器的另一种方式是设置解析器表. 解析器表是解析器中以通用标识符(整数或字符串)分组的子解析器列表. 子解析器可调用以下 API 之一将自己注册到解析器表中:
void dissector_add_uint(const char *abbrev, const guint32 pattern, dissector_handle_t handle);void dissector_add_uint_range(const char *abbrev, struct epan_range *range, dissector_handle_t handle);void dissector_add_string(const char *name, const gchar *pattern, dissector_handle_t handle);void dissector_add_for_decode_as(const char *name, dissector_handle_t handle);
示例:
// epan/dissectors/packet-http.c/** Register ourselves as the handler for that port number* over TCP. "Auto-preference" not needed*/dissector_add_uint("tcp.port", port, http_tcp_handle);
dissector_add_for_decode_as doesn’t add a unique identifier in the dissector table, but it lets the user add it from the command line or, in Wireshark, through the “Decode As” UI.
Then when the dissector hits the common identifier field, it will use one of the following APIs to invoke the subdissector:
int dissector_try_uint(dissector_table_t sub_dissectors, const guint32 uint_val, tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree);int dissector_try_uint_new(dissector_table_t sub_dissectors, const guint32 uint_val, tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, const gboolean add_proto_name, void *data);int dissector_try_string(dissector_table_t sub_dissectors, const gchar *string, tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, void *data);
These pass a subset of the remaining packet (typically the rest of the packet) for the dissector table to determine which subdissector is called. This allows dissection of a packet to be expanded outside of dissector without having to modify the dissector directly.
示例:
// epan/dissectors/packet-tcp.c// 注册解析器表"tcp.port"subdissector_table = register_dissector_table("tcp.port","TCP port", proto_tcp, FT_UINT16, BASE_DEC);// 运行时通过解析器表调用后续解析器if (tcpd && tcpd->server_port != 0 &&dissector_try_uint_new(subdissector_table, tcpd->server_port,next_tvb, pinfo, tree, TRUE, tcpinfo)) {...}
1.8 编辑CMakeLists.txt加入解析器
为了使你的解析器做为 Wireshark 的一部分被编译, 需要在 epan/dissectors/CMakeLists.txt 文件中的 DISSECTOR_SRC 部分添加解析器源文件名.
1.9 Using the git source code tree
See [https://www.wireshark.org/develop.html](https://www.wireshark.org/develop.html>)
1.10 Submitting code for your new dissector
See [https://www.wireshark.org/docs/wsdg_html_chunked/ChSrcContribute.html](https://www.wireshark.org/docs/wsdg_html_chunked/ChSrcContribute.html>)
and [https://gitlab.com/wireshark/wireshark/-/wikis/Development/SubmittingPatches.](https://gitlab.com/wireshark/wireshark/-/wikis/Development/SubmittingPatches>.)
VERIFY that your dissector code does not use prohibited or deprecated APIs as follows:
perl <wireshark_root>/tools/checkAPIs.pl <source-filename(s)>VERIFY that your dissector code does not contain any header field related problems:
perl <wireshark_root>/tools/checkhf.pl <source-filename(s)>VERIFY that your dissector code does not contain any display filter related problems:
perl <wireshark_root>/tools/checkfiltername.pl <source-filename(s)>CHECK your dissector with CppCheck (http://cppcheck.sourceforge.net/)) using Wireshark’s customized configuration. This is particularly important on Windows, since Microsoft’s compiler warnings are quite thin:
./tools/cppcheck/cppcheck.sh <source-filename(s)>TEST YOUR DISSECTOR BEFORE SUBMITTING IT.
Use fuzz-test.sh and/or randpkt against your dissector. These are
described at [https://gitlab.com/wireshark/wireshark/-/wikis/FuzzTesting.](https://gitlab.com/wireshark/wireshark/-/wikis/FuzzTesting>.)Subscribe to
[https://www.wireshark.org/lists/.](https://www.wireshark.org/lists/>.)‘git diff’ to verify all your changes look good.
‘git add’ all the files you changed.
‘git commit’ to commit (locally) your changes. First line of commit message should be a summary of the changes followed by an empty line and a more verbose description.
‘git push downstream HEAD’ to push the changes to GitLab. (This assumes that you have a remote named “downstream” that points to a fork of https://gitlab.com/wireshark/wireshark.))
Create a Wiki page on the protocol at [https://gitlab.com/wireshark/editor-wiki.](https://gitlab.com/wireshark/editor-wiki>.)
(You’ll need to request access to https://gitlab.com/wireshark/wiki-editors.))
A template is provided so it is easy to setup in a consistent style.
See: [https://gitlab.com/wireshark/wireshark/-/wikis/HowToEdit](https://gitlab.com/wireshark/wireshark/-/wikis/HowToEdit>)
and [https://gitlab.com/wireshark/wireshark/-/wikis/ProtocolReference](https://gitlab.com/wireshark/wireshark/-/wikis/ProtocolReference>)If possible, add sample capture files to the sample captures page at [https://gitlab.com/wireshark/wireshark/-/wikis/SampleCaptures.](https://gitlab.com/wireshark/wireshark/-/wikis/SampleCaptures>.) These files are used by the automated build system for fuzz testing.
If you don’t think the wiki is the right place for your sample capture, submit a bug report to the Wireshark issue database, found at [https://gitlab.com/wireshark/wireshark/-/issues,](https://gitlab.com/wireshark/wireshark/-/issues>,) qualified as an enhancement and attach your sample capture there. Normally a new dissector won’t be accepted without a sample capture! If you open a bug be sure to cross-link your GitLab merge request.
参考
- Wireshark源码: doc/README.dissector

若有收获,就点个赞吧
0 人点赞
