1 概述
为了便于内存管理, 以及降低内存泄漏的可能性, Wireshark 有自己的内存管理机制:
- WMEM
Wireshark 内存管理框架,epan/wmem/ - Buffer
wsutil/buffer.h - tvbuff
epan/tvbuff.h
本文首先解读 doc/README.wmem, 然后再分析它们的主要实现原理, 为方便分析有时候会编写一些代码. 这些代码见 github.com/zzqcn/wsdev, 提及的时候会给出相对路径.
2 doc/README.wmem
见 https://www.yuque.com/zzqcn/wireshark/gv8cfc
3 wmem
有关 wmem, 本文第 2 章已经说了很多了, 这里主要结合源码分析, 代码调用等进行额外阐述.
3.1 概述
wmem 使用面向对象设计, 相当于实现了 4 个内存池类:
- simple_allocator
- block_allocator
- block_fast_allocator
- strick_allocator
并且在内部根据这些类创建了 3 个内存池对象, 解析器等代码可直接调用:
- wmem_file_scope(), block_allocator 对象
- wmem_epan_scope(), block_allocator 对象
- wmem_packet_scope(), block_fast_allocator 对象
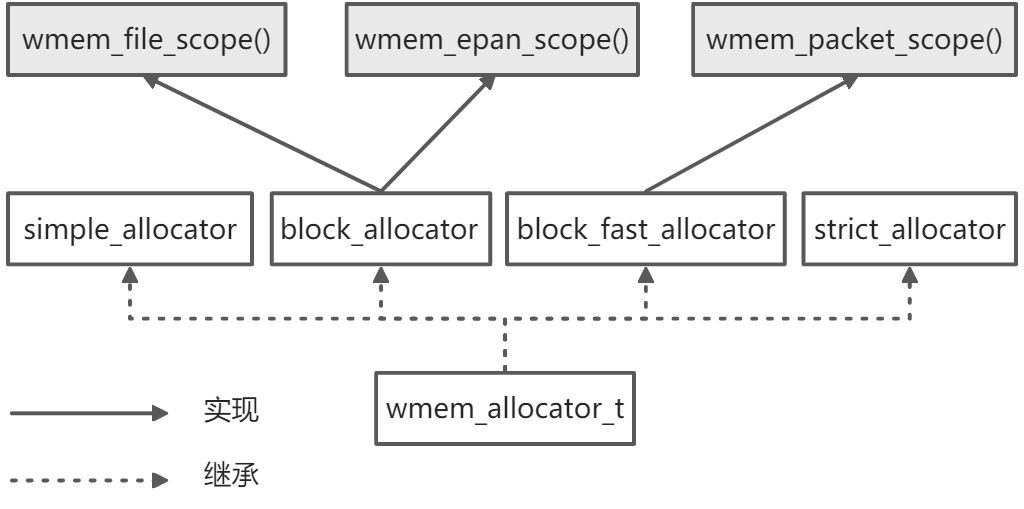
wmem_allocator_new() 实现了工厂模式, 通过传入的参数不同来创建不同的 allocator.
// epan/wmem/wmem_core.cwmem_allocator_t *wmem_allocator_new(const wmem_allocator_type_t type){wmem_allocator_t *allocator;wmem_allocator_type_t real_type;if (do_override) {real_type = override_type;}else {real_type = type;}allocator = wmem_new(NULL, wmem_allocator_t);allocator->type = real_type;allocator->callbacks = NULL;allocator->in_scope = TRUE;switch (real_type) {case WMEM_ALLOCATOR_SIMPLE:wmem_simple_allocator_init(allocator);break;case WMEM_ALLOCATOR_BLOCK:wmem_block_allocator_init(allocator);break;case WMEM_ALLOCATOR_BLOCK_FAST:wmem_block_fast_allocator_init(allocator);break;case WMEM_ALLOCATOR_STRICT:wmem_strict_allocator_init(allocator);break;default:g_assert_not_reached();/* This is necessary to squelch MSVC errors; is thereany way to tell it that g_assert_not_reached()never returns? */return NULL;};return allocator;}
3.x block allocator
3.x wmem数据结构
历史
Version 1 of this allocator was embedded in the original emem framework. It
didn’t have to handle realloc or free, so it was very simple: it just grabbed
a block from the OS and served allocations sequentially out of that until it
ran out, then allocated a new block. The old block was never revisited, so
it generally had a bit of wasted space at the end, but the waste was
small enough that it was simply ignored. This allocator provided very fast
constant-time allocation for any request that didn’t require a new block from
the OS, and that cost could be amortized away.
Version 2 of this allocator was prompted by the need to support realloc and
free in wmem. The original version simply didn’t save enough metadata to do
this, so I added a layer on top to make it possible. The primary principle
was the same (allocate sequentially out of big blocks) with a bit of extra
magic. Allocations were still fast constant-time, and frees were as well.
Large parts of that design are still present in this one, but for more
details see older versions of this file from git or svn.
Version 3 of this allocator was written to address some issues that
eventually showed up with version 2 under real-world usage. Specifically,
version 2 dealt very poorly with memory fragmentation, almost never reusing
freed blocks and choosing to just keep allocating from the master block
instead. This led to particularly poor behaviour under the tick-tock loads
(alloc/free/alloc/free or alloc/alloc/free/alloc/alloc/free/ or …) that
showed up in a couple of different protocol dissectors (TCP, Kafka).
block & chunk
As in previous versions, allocations typically happen sequentially out of
large OS-level blocks. Each block has a short embedded header used to
maintain a doubly-linked list of all blocks (used or not) currently owned by
the allocator. Each block is divided into chunks, which represent allocations
and free sections (a block is initialized with one large, free, chunk). Each
chunk is prefixed with a wmem_block_chunk_t structure, which is a short
metadata header (8 bytes, regardless of 32 or 64-bit architecture unless
alignment requires it to be padded) that contains the length of the chunk,
the length of the previous chunk, a flag marking the chunk as free or used,
and a flag marking the last chunk in a block. This serves to implement an
inline sequential doubly-linked list of all the chunks in each block. A block
with three chunks might look something like this:
0 _________________________^ ___________ / ______________ \ __________||---||--|-----/-----------||--------/--------------||--\-----/----------||||hdr|| prv | len | body || prv | len | body || prv | len | body ||||---||--------------------||--/--------------------||-------------------||\______________________/
/* See section "4. Internal Design" of doc/README.wmem for details* on this structure */struct _wmem_allocator_t {/* Consumer functions */void *(*walloc)(void *private_data, const size_t size);void (*wfree)(void *private_data, void *ptr);void *(*wrealloc)(void *private_data, void *ptr, const size_t size);/* Producer/Manager functions */void (*free_all)(void *private_data);void (*gc)(void *private_data);void (*cleanup)(void *private_data);/* Callback List */struct _wmem_user_cb_container_t *callbacks;/* Implementation details */void *private_data;enum _wmem_allocator_type_t type;gboolean in_scope;};typedef struct _wmem_block_allocator_t {wmem_block_hdr_t *block_list;wmem_block_chunk_t *master_head;wmem_block_chunk_t *recycler_head;} wmem_block_allocator_t;/* The header for an entire OS-level 'block' of memory */typedef struct _wmem_block_hdr_t {struct _wmem_block_hdr_t *prev, *next;} wmem_block_hdr_t;/* The header for a single 'chunk' of memory as returned from alloc/realloc.* The 'jumbo' flag indicates an allocation larger than a normal-sized block* would be capable of serving. If this is set, it is the only chunk in the* block and the other chunk header fields are irrelevant.*/typedef struct _wmem_block_chunk_t {guint32 prev;/* flags */guint32 last:1;guint32 used:1;guint32 jumbo:1;guint32 len:29;} wmem_block_chunk_t;/* This is what the 'data' section of a chunk contains if it is free. */typedef struct _wmem_block_free_t {wmem_block_chunk_t *prev, *next;} wmem_block_free_t;
When allocating, a free chunk is found (more on that later) and split into
two chunks: the first of the requested size and the second containing any
remaining free. The first is marked used and returned to the caller.
When freeing, the chunk in question is marked as free. Its neighbouring
chunks are then checked; if either of them are free, the consecutive free
chunks are merged into a single larger free chunk. Induction can show that
applying this operation consistently prevents us ever having consecutive
free chunks.
Free chunks (because they are not being used for anything else) each store an
additional pair of pointers (see the wmem_block_free_t structure) that form
the backbone of the data structures used to track free chunks.
管理与回收
The extra pair of pointers in free chunks are used to build two doubly-linked
lists: the master and the recycler. The recycler is circular, the master is
a stack.
The master stack is only populated by chunks from new OS-level blocks,
so every chunk in this list is guaranteed to be able to serve any allocation
request (the allocator will not serve requests larger than its block size).
The chunk at the head of the master list shrinks as it serves requests. When
it is too small to serve the current request, it is popped and inserted into
the recycler. If the master list is empty, a new OS-level block is allocated,
and its chunk is pushed onto the master stack.
The recycler is populated by ‘leftovers’ from the master, as well as any
chunks that were returned to the allocator via a call to free(). Although the
recycler is circular, we will refer to the element referenced from the
allocator as the ‘head’ of the list for convenience. The primary operation on
the recycler is called cycling it. In this operation, the head is compared
with its clockwise neighbour. If the neighbour is as large or larger, it
becomes the head (the list rotates counter-clockwise). If the neighbour is
smaller, then it is removed from its location and inserted as the counter-
clockwise neighbour of the head (the list still rotates counter-clockwise,
but the head element is held fixed while the rest of the list spins). This
operation has the following properties:
- fast constant time
- once the largest chunk is at the head, it remains at the head
- more iterations increases the probability that the largest chunk will be
the head (for a list with n items, n iterations guarantees that the
largest chunk will be the head).分配
When an allocation request is received, the allocator first attempts tosatisfy it with the chunk at the head of the recycler. If that does not
succeed, the request is satisfied by the master list instead. Regardless of
which chunk satisfied the request, the recycler is always cycled.3.x 使用wmem
allocator
下面的实际代码演示了如何简单调用 wmem allocator (代码见我的 wsdev wmem/allocator): ```cinclude
include “epan/epan.h”
include “epan/wmem/wmem.h”
int main(int argc, char* argv) { wmem_allocator_t pool; char* buf;
wmem_init();pool = wmem_allocator_new(WMEM_ALLOCATOR_SIMPLE);if (NULL == pool) {g_print("create simple pool failed\n");return -1;}buf = wmem_alloc(pool, 64);g_print("buf: %p\n", buf);wmem_destroy_allocator(pool);// error code below, will cause segment fault// buf = wmem_alloc(pool, 64);// g_print("buf: %p\n", buf);pool = wmem_allocator_new(WMEM_ALLOCATOR_BLOCK);if (NULL == pool) {g_print("create block pool failed\n");return -1;}buf = wmem_alloc(pool, 64);g_print("buf: %p\n", buf);wmem_destroy_allocator(pool);wmem_cleanup();return 0;
}
:::warning在调用任何 wmem 函数之前应先调用 wmem_init() 初始化 wmem 子模块, 最后调用 wmem_cleanup() 反初始化, 当然 wireshark/tshark 已在合适的地方调用了这两个函数:::<a name="nyabb"></a>### scope下面的实际代码演示了如何简单调用 wmem allocator (代码见[我的 wsdev](https://github.com/zzqcn/wsdev) wmem/allocator):```c#include <glib.h>#include "epan/epan.h"#include "epan/wmem/wmem.h"int main(int argc, char **argv){wmem_allocator_t *epan_pool;wmem_allocator_t *file_pool;wmem_allocator_t *packet_pool;char *epan_buf, *file_buf, *packet_buf;int i;// error code below, will cause assertion failed,// must call wmem_init() first// epan_pool = wmem_epan_scope();wmem_init();epan_pool = wmem_epan_scope();if (NULL == epan_pool) {g_print("epan_pool is NOT inited\n");return -1;}file_pool = wmem_file_scope();packet_pool = wmem_packet_scope();epan_buf = wmem_alloc(epan_pool, 64);if (NULL == epan_buf) {g_print("alloc in epan pool failed\n");goto end;}g_snprintf(epan_buf, 64, "epan string");g_print("epan_buf: %s\n", epan_buf);wmem_enter_file_scope();file_buf = wmem_alloc(file_pool, 64);if (NULL == file_buf) {g_print("alloc in file pool failed\n");goto end;}g_snprintf(file_buf, 64, "file string");g_print("file_buf: %s\n", file_buf);for (i = 0; i < 5; i++) {wmem_enter_packet_scope();packet_buf = wmem_alloc(packet_pool, 32);g_snprintf(packet_buf, 16, "packet string %d", i + 1);g_print("packet_buf: %s\n", packet_buf);wmem_leave_packet_scope();g_print("packet_buf: %s\n", packet_buf);}wmem_leave_file_scope();// error code below, will cause segment fault,// because we have leave file scope// g_print("file_buf: %s\n", file_buf);g_print("epan_buf: %s\n", epan_buf);// no wmem_leave_epan_scope() API,// it will auto-destroyed when wmem_cleanup() is calledend:wmem_cleanup();return 0;}
4 tvbuff
4.1 概述
即 Testy, Virtual Buffer. 这样命名有两个含义:
- Testy (易怒的): 尝试越界访问数据时将抛出异常
- Virtualizable: 可以通过已有 tvbuff 创建新的 tvbuff, 而仅有原始 tvbuff 持有数据, 新 tvbuff 并不真的持有数据
在 epan 中, 通常是把多个 tvbuff 构成链表(或栈)来使用的. 当解析一个 frame 时:
packet.c 中的上游解析器将最初的 tvb (包含完整 frame) 放到链表中, 并调用下游解析器, 下游解析器再调用下游, 如此往复. 每个下游解析器把新的 tvb 链到传给它的 tvb 中. 解析完成后, 控制权回到上游解析器, (在epan_dissect_cleanup()中) tvb 链表通过 tvb_free_chain() 调用被释放.
tvbuff 有三种类型:
- real
包含指向实际数据的 guint8* 指针, 其缓冲区是被分配和连续的. - subset
subset tvbuff 对应一个底层(backing) tvbuff, 它类似于一个窗口, 通过它只能看到底层 tvbuff 的一部分 - composite
composite tvbuff 由多个 tvbuff 组合而成, 形成一个更大的 byte array
tvbuff 实现了一种面向对象机制, struct tvbuff 相当于基类, 而 real/subset/composite 等 tvbuff 相当于 struct tvbuff 的派生类, 它们的不同行为是通过 struct tvb_ops 来特化的.
任何类型的 tvbuff 都做为 subset tvbuff 的底层 tvbuff, 或做为 composite tvbuff 的成员. composite tvbuff 可包含不同类型的 tvbuff. tvbuff 一旦被创建/初始化/反初始后, 就是只读的, 即不能指向其他数据. 要想指向其他数据, 就必须创建一个新的 tvbuff. tvbuff 一般连在一起以便高效地释放.
:::info
下文中 tvbuff 也简称为 tvb
:::
4.2 数据结构
// epan/tvbuff-int.hstruct tvb_ops {gsize tvb_size;void (*tvb_free)(struct tvbuff *tvb);guint (*tvb_offset)(const struct tvbuff *tvb, guint counter);const guint8 *(*tvb_get_ptr)(struct tvbuff *tvb, guint abs_offset, guint abs_length);void *(*tvb_memcpy)(struct tvbuff *tvb, void *target, guint offset, guint length);gint (*tvb_find_guint8)(tvbuff_t *tvb, guint abs_offset, guint limit, guint8 needle);gint (*tvb_ws_mempbrk_pattern_guint8)(tvbuff_t *tvb, guint abs_offset, guint limit, const ws_mempbrk_pattern* pattern, guchar *found_needle);tvbuff_t *(*tvb_clone)(tvbuff_t *tvb, guint abs_offset, guint abs_length);};struct tvbuff {tvbuff_t *next;const struct tvb_ops *ops;gboolean initialized;guint flags;struct tvbuff *ds_tvb;const guint8 *real_data;guint length;guint reported_length;guint contained_length;gint raw_offset;};
tvbuff 的成员:
next用于构造双向链表ops操作函数集, 这实现了某种面向对象特性initialized是否初始化flags标志位, 目前仅支持 TVBUFF_FRAGMENTds_tvb作为数据源的顶层 tvbreal_data实际数据指针. 当为 null 时可表示: 1)数据长度为0; 2)使用了延迟创建机制, 即直到需要使用数据时才分配内存并填充数据length实际数据长度, 可能会<reported_length, 比如被抓包进程截短的报文. 绝不会大于 reported_length 或 contained_lengthreported_length上报数据长度contained_length有两份种情况: 1)如果是从父 tvb 解出的, 则表示解出的数据长度或所含数据本身表明的长度, 它可能 >reported_length; 2)如果不是从父 tvb 解出的, 则 =reported_length. 它绝不会 >reported_lengthraw_offset相对第一个 real tvb 开头的偏移
:::warning 源代码中对于 contained_length 的注释让我迷惑, 需要后续分析代码确定其真实含义 :::
struct tvbuff 是基本数据结构, 在实际使用时一般对其进行封装, 来实现类似派生类的特定行为, 如 real tvb, subset tvb, frame tvb 等, 不同 tvb 有不同的操作函数(ops).
4.3 一般操作
tvb_new()
实际创建和初始化 tvb.
// epan/tvbuff.ctvbuff_t *tvb_new(const struct tvb_ops *ops){tvbuff_t *tvb;gsize size = ops->tvb_size;...// 这里只是分配ops指定大小的内存, 可能是封装了tvbuff的另一结构体的大小,// 而不包含实际数据的长度.// g_slice_alloc 使用了优化的内存分配方式, 参考:// developer.gnome.org/glib/stable/glib-Memory-Slices.htmltvb = (tvbuff_t *) g_slice_alloc(size);tvb->next = NULL;// 传入特化的ops, 就定义了特化的行为tvb->ops = ops;tvb->initialized = FALSE;tvb->flags = 0;tvb->length = 0;tvb->reported_length = 0;tvb->contained_length = 0;tvb->real_data = NULL;tvb->raw_offset = -1;tvb->ds_tvb = NULL;return tvb;}
tvb_add_to_chain()
链接两个 tvb, 把 child tvb 链接到 parent tvb 末尾.
// epan/tvbuff.c// 将子tvb链到父tvb之后voidtvb_add_to_chain(tvbuff_t *parent, tvbuff_t *child){tvbuff_t *tmp = child;...while (child) {tmp = child;child = child->next;tmp->next = parent->next;parent->next = tmp;}}
经过这个操作后, 原 parent tvb 的尾端(parent->next)和原 child tvb 的链表项顺序都会变化. 如下代码, 先链接 b, c, 再链接 a, b, 那么上一次链接时 b, c 的位置会改变(tvb/base/main.c):
tvb_add_to_chain(b, c);// b -> ctvb_add_to_chain(a, b);// a -> c -> b
tvb_new_chain()
// TODO
// epan/tvbuff_subset.ctvbuff_t *tvb_new_proxy(tvbuff_t *backing){tvbuff_t *tvb;if (backing)tvb = tvb_new_with_subset(backing, backing->reported_length, 0, backing->length);elsetvb = tvb_new_real_data(NULL, 0, 0);tvb->ds_tvb = tvb;return tvb;}// epan/tvbuff.ctvbuff_t *tvb_new_chain(tvbuff_t *parent, tvbuff_t *backing){tvbuff_t *tvb = tvb_new_proxy(backing);tvb_add_to_chain(parent, tvb);return tvb;}
tvb_free()
tvb_free() 直接调用 tvb_free_chain(), 会释放整个 tvb 链表上所有的 tvb.
// epan/tvbuff.cvoidtvb_free(tvbuff_t *tvb){tvb_free_chain(tvb);}voidtvb_free_chain(tvbuff_t *tvb){tvbuff_t *next_tvb;DISSECTOR_ASSERT(tvb);while (tvb) {next_tvb = tvb->next;tvb_free_internal(tvb);tvb = next_tvb;}}static voidtvb_free_internal(tvbuff_t *tvb){gsize size;DISSECTOR_ASSERT(tvb);if (tvb->ops->tvb_free)tvb->ops->tvb_free(tvb);size = tvb->ops->tvb_size;g_slice_free1(size, tvb);}
tvb_get_ptr()
4.4 real tvb
real tvb 可以”看到”完整的一块真实数据. real tvb 的封装比较简单, 仅添加了释放内存回调函数, 操作函数也仅实现了 free 和 offset.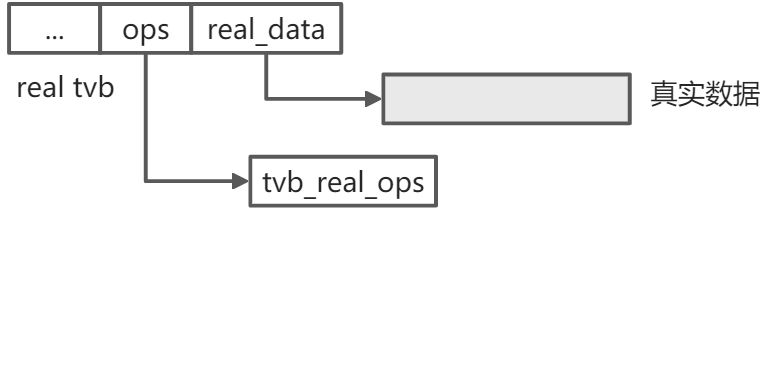
数据结构:
// epan/tvbuff_real.cstruct tvb_real {struct tvbuff tvb;/** Func to call when actually freed */tvbuff_free_cb_t free_cb;};static const struct tvb_ops tvb_real_ops = {sizeof(struct tvb_real), /* size */real_free, /* free */real_offset, /* offset */NULL, /* get_ptr */NULL, /* memcpy */NULL, /* find_guint8 */NULL, /* pbrk_guint8 */NULL, /* clone */};
创建 real tvb:
epan/tvbuff_real.ctvbuff_t *tvb_new_real_data(const guint8* data, const guint length, const gint reported_length){tvbuff_t *tvb;struct tvb_real *real_tvb;THROW_ON(reported_length < -1, ReportedBoundsError);tvb = tvb_new(&tvb_real_ops);tvb->real_data = data;tvb->length = length;tvb->reported_length = reported_length;tvb->contained_length = reported_length;tvb->initialized = TRUE;/** This is the top-level real tvbuff for this data source,* so its data source tvbuff is itself.*/tvb->ds_tvb = tvb;real_tvb = (struct tvb_real *) tvb;real_tvb->free_cb = NULL;return tvb;}
4.5 subset tvb
subset tvb 只能”看到”真实数据的一部分, 它必须引用一个底层 tvb.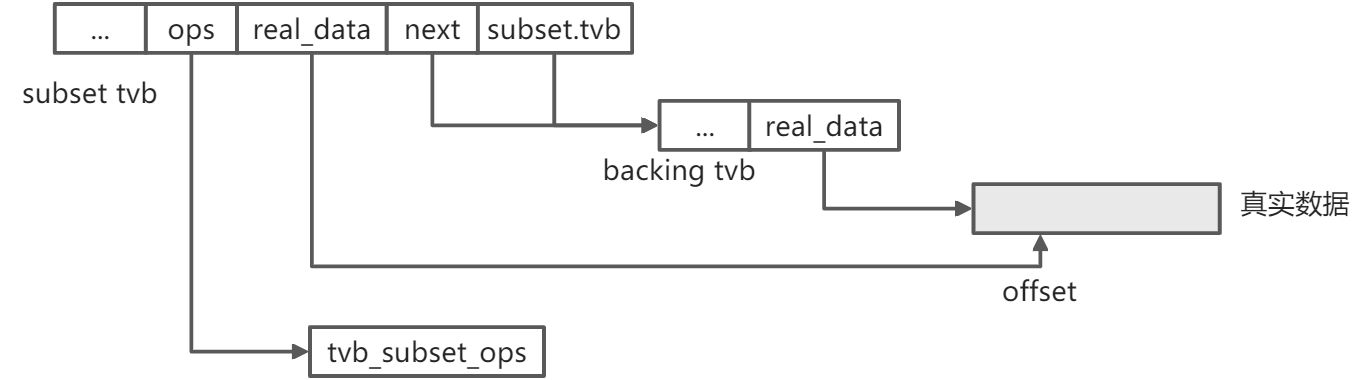
数据结构:
// epan/tvbuff_subset.ctypedef struct {/** The backing tvbuff_t */struct tvbuff *tvb;/** The offset of 'tvb' to which I'm privy */guint offset;/** The length of 'tvb' to which I'm privy */guint length;} tvb_backing_t;struct tvb_subset {struct tvbuff tvb;tvb_backing_t subset;};static const struct tvb_ops tvb_subset_ops = {sizeof(struct tvb_subset), /* size */NULL, /* free */subset_offset, /* offset */subset_get_ptr, /* get_ptr */subset_memcpy, /* memcpy */subset_find_guint8, /* find_guint8 */subset_pbrk_guint8, /* pbrk_guint8 */subset_clone, /* clone */};
创建 subset tvb, 有几种方式, 这里以 tvb_new_subset_length_caplen() 为例:
// epan/tvbuff_subset.cstatic tvbuff_t *tvb_new_with_subset(tvbuff_t *backing, const guint reported_length,const guint subset_tvb_offset, const guint subset_tvb_length){tvbuff_t *tvb = tvb_new(&tvb_subset_ops);struct tvb_subset *subset_tvb = (struct tvb_subset *) tvb;subset_tvb->subset.offset = subset_tvb_offset;subset_tvb->subset.length = subset_tvb_length;subset_tvb->subset.tvb = backing;tvb->length = subset_tvb_length;/** The contained length must not exceed what remains in the* backing tvbuff.*/tvb->contained_length = MIN(reported_length, backing->contained_length - subset_tvb_offset);tvb->flags = backing->flags;tvb->reported_length = reported_length;tvb->initialized = TRUE;/* Optimization. If the backing buffer has a pointer to contiguous, real data,* then we can point directly to our starting offset in that buffer */if (backing->real_data != NULL) {tvb->real_data = backing->real_data + subset_tvb_offset;}/** The top-level data source of this tvbuff is the top-level* data source of its parent.*/tvb->ds_tvb = backing->ds_tvb;return tvb;}tvbuff_t *tvb_new_subset_length_caplen(tvbuff_t *backing, const gint backing_offset, const gint backing_length, const gint reported_length){tvbuff_t *tvb;guint subset_tvb_offset;guint subset_tvb_length;guint actual_reported_length;DISSECTOR_ASSERT(backing && backing->initialized);THROW_ON(reported_length < -1, ReportedBoundsError);tvb_check_offset_length(backing, backing_offset, backing_length,&subset_tvb_offset,&subset_tvb_length);if (reported_length == -1)actual_reported_length = backing->reported_length - subset_tvb_offset;elseactual_reported_length = (guint)reported_length;tvb = tvb_new_with_subset(backing, actual_reported_length,subset_tvb_offset, subset_tvb_length);tvb_add_to_chain(backing, tvb);return tvb;}
backing_offset 是可以 <0 的, 表示反向偏移; backing_length 可以 =-1, 表示直到末尾; reported_length 可以 =-1, 表示取可能的最大值. 对这些情况, 函数内部都会(由`tvb_check_offset_length()`)计算出合适的正值. 新创建的 subset tvb 被链接到底层原始 tvb 的末尾.
4.6 composite tvb
composite tvb 是多个 tvb 的组合, 它引用的一个或多个 tvb 都必须在同一个 tvb 链上, 否则会引发释放后使用, 双重释放等内存使用问题.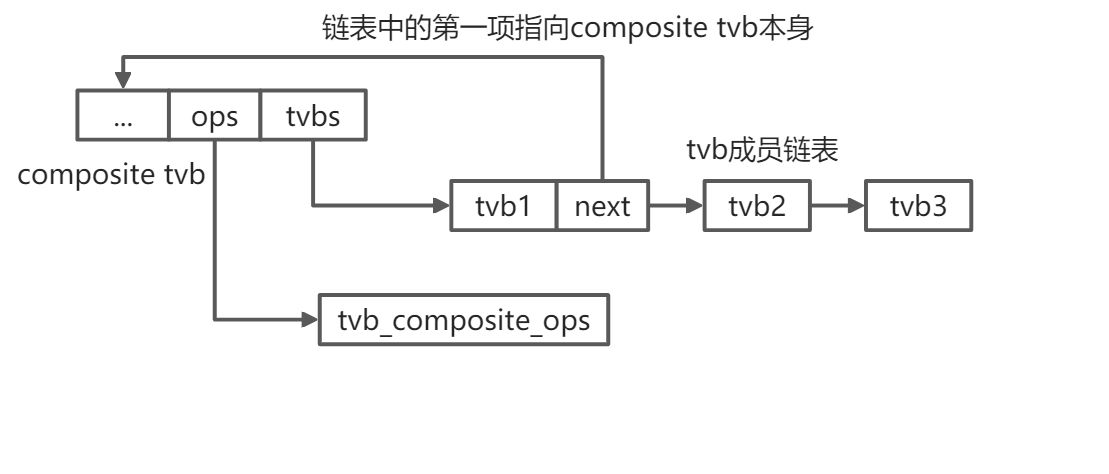
数据结构:
// epan/tvbuff_composite.ctypedef struct {GSList *tvbs;/* Used for quick testing to see if this* is the tvbuff that a COMPOSITE is* interested in. */guint *start_offsets;guint *end_offsets;} tvb_comp_t;struct tvb_composite {struct tvbuff tvb;tvb_comp_t composite;};static const struct tvb_ops tvb_composite_ops = {sizeof(struct tvb_composite), /* size */composite_free, /* free */composite_offset, /* offset */composite_get_ptr, /* get_ptr */composite_memcpy, /* memcpy */NULL, /* find_guint8 XXX */NULL, /* pbrk_guint8 XXX */NULL, /* clone */};
这里用到了 glib 单向链表 GSList:
// glib-2.0/glib/gslist.htypedef struct _GSList GSList;struct _GSList{gpointer data;GSList *next;};
创建 composite tvb.
// epan/tvbuff_composite.ctvbuff_t *tvb_new_composite(void){tvbuff_t *tvb = tvb_new(&tvb_composite_ops);struct tvb_composite *composite_tvb = (struct tvb_composite *) tvb;tvb_comp_t *composite = &composite_tvb->composite;composite->tvbs = NULL;composite->start_offsets = NULL;composite->end_offsets = NULL;return tvb;}
追加 tvb 成员:
// epan/tvbuff_composite.cvoidtvb_composite_append(tvbuff_t *tvb, tvbuff_t *member){struct tvb_composite *composite_tvb = (struct tvb_composite *) tvb;tvb_comp_t *composite;DISSECTOR_ASSERT(tvb && !tvb->initialized);DISSECTOR_ASSERT(tvb->ops == &tvb_composite_ops);/* Don't allow zero-length TVBs: composite_memcpy() can't handle them* and anyway it makes no sense.*/DISSECTOR_ASSERT(member->length);composite = &composite_tvb->composite;composite->tvbs = g_slist_append(composite->tvbs, member);/* Attach the composite TVB to the first TVB only. */if (!composite->tvbs->next) {tvb_add_to_chain((tvbuff_t *)composite->tvbs->data, tvb);}}
composite 在组合完成后, 转换为可用 tvb. 转换之后不能再进行成员 tvb 添加操作, 而且调用者才可使用其中的数据:
// epan/tvbuff_composite.cvoidtvb_composite_finalize(tvbuff_t *tvb){...composite->start_offsets = g_new(guint, num_members);composite->end_offsets = g_new(guint, num_members);// 遍历链表, 计算每个tvb成员的可用范围, 并更新composite tvbfor (slist = composite->tvbs; slist != NULL; slist = slist->next) {DISSECTOR_ASSERT((guint) i < num_members);member_tvb = (tvbuff_t *)slist->data;composite->start_offsets[i] = tvb->length;tvb->length += member_tvb->length;tvb->reported_length += member_tvb->reported_length;tvb->contained_length += member_tvb->contained_length;composite->end_offsets[i] = tvb->length - 1;i++;}tvb->initialized = TRUE;tvb->ds_tvb = tvb;}
memcpy: // TODO
4.7 frame tvb
4.x 报文解析过程中的tvbuff
顶层tvb
原始报文 tvb (即顶层 tvb) 创建过程:
process_cap_file_single_pass ->process_packet_single_pass ->epan_dissect_run_with_taps ->frame_tvbuff_new_buffer ->frame_tvbuff_new ->tvb_new
process_cap_file_single_pass()
此函数中使用了 wsutil 中实现的 Buffer, 把报文读取到其中. Buffer 会分配内存.
// tshark.cstatic pass_status_tprocess_cap_file_single_pass(capture_file *cf, wtap_dumper *pdh,int max_packet_count, gint64 max_byte_count,int *err, gchar **err_info,volatile guint32 *err_framenum){wtap_rec rec;Buffer buf;...wtap_rec_init(&rec);// 初始化Buffer, 这里会实际分配内存, 具体细节见本文Buffer分析ws_buffer_init(&buf, 1514);...// 逐个读取报文while (wtap_read(cf->provider.wth, &rec, &buf, err, err_info, &data_offset)) {...if (process_packet_single_pass(cf, edt, data_offset, &rec, &buf, tap_flags)) {...}...}...ws_buffer_free(&buf);wtap_rec_cleanup(&rec);return status;}
对于 pcap 报文, wtap_read() 最终会调用 libpcap_read_packet():
// wiretap/libpcap.cstatic gbooleanlibpcap_read_packet(wtap *wth, FILE_T fh, wtap_rec *rec,Buffer *buf, int *err, gchar **err_info){...// packet_size是从pcap frame首部读取到的if (!libpcap_read_header(wth, fh, err, err_info, &hdr))return FALSE;...packet_size = hdr.hdr.incl_len;...if (!wtap_read_packet_bytes(fh, buf, packet_size, err, err_info))return FALSE; /* failed */...}// -->// wiretap/wtap.c/** Read packet data into a Buffer, growing the buffer as necessary.** This returns an error on a short read, even if the short read hit* the EOF immediately. (The assumption is that each packet has a* header followed by raw packet data, and that we've already read the* header, so if we get an EOF trying to read the packet data, the file* has been cut short, even if the read didn't read any data at all.)*/gbooleanwtap_read_packet_bytes(FILE_T fh, Buffer *buf, guint length, int *err,gchar **err_info){ws_buffer_assure_space(buf, length);return wtap_read_bytes(fh, ws_buffer_start_ptr(buf), length, err,err_info);}// -->gbooleanwtap_read_bytes(FILE_T fh, void *buf, unsigned int count, int *err,gchar **err_info){int bytes_read;bytes_read = file_read(buf, count, fh);...return TRUE;}
这里 buf 里只包含报文实际数据(如Ether->IP->..), 不包含 libpcap 帧首部等.
process_packet_single_pass()
这里调用 frame_tvbuff_new_buffer(), 根据之前的 Buffer 创建了顶层 tvb, 然后交给 EPAN 进行解析.
// tshark.cstatic gbooleanprocess_packet_single_pass(capture_file *cf, epan_dissect_t *edt, gint64 offset,wtap_rec *rec, Buffer *buf, guint tap_flags){frame_data fdata;...frame_data_init(&fdata, cf->count, rec, offset, cum_bytes);...if (edt) {...frame_data_set_before_dissect(&fdata, &cf->elapsed_time,&cf->provider.ref, cf->provider.prev_dis);...epan_dissect_run_with_taps(edt, cf->cd_t, rec,frame_tvbuff_new_buffer(&cf->provider, &fdata, buf),&fdata, cinfo);...}...if (edt) {epan_dissect_reset(edt);frame_data_destroy(&fdata);}return passed;}
frame_tvbuff_new_buffer()
这里使用另一个数据结构 tvb_frame 封装 tvbuff, 这样创建的 tvbuff 有特定的操作函数集. 这是常见用法.
// frame_tvbuff.cstruct tvb_frame {struct tvbuff tvb;Buffer *buf; /* Packet data */const struct packet_provider_data *prov; /* provider of packet information */gint64 file_off; /**< File offset */guint offset;};static const struct tvb_ops tvb_frame_ops = {sizeof(struct tvb_frame), /* size */frame_free, /* free */frame_offset, /* offset */frame_get_ptr, /* get_ptr */frame_memcpy, /* memcpy */frame_find_guint8, /* find_guint8 */frame_pbrk_guint8, /* pbrk_guint8 */frame_clone, /* clone */};tvbuff_t *frame_tvbuff_new_buffer(const struct packet_provider_data *prov,const frame_data *fd, Buffer *buf){// ws_buffer_start_ptr()返回Buffer中的数据指针return frame_tvbuff_new(prov, fd, ws_buffer_start_ptr(buf));}/* based on tvb_new_real_data() */tvbuff_t *frame_tvbuff_new(const struct packet_provider_data *prov, const frame_data *fd,const guint8 *buf){struct tvb_frame *frame_tvb;tvbuff_t *tvb;// 使用特定的frame操作函数集tvb_frame_opstvb = tvb_new(&tvb_frame_ops);// buf指向Buffer中的内存, 该内存是Buffer之前分配的,// 所以这个tvb实际并没有分配内存和拷贝, 只是引用tvb->real_data = buf;// fd->cap_len是实际抓包抓到的数据长度, 而fd->pkt_len是所谓的上报长度tvb->length = fd->cap_len;tvb->reported_length = fd->pkt_len > G_MAXINT ? G_MAXINT : fd->pkt_len;tvb->contained_length = tvb->reported_length;tvb->initialized = TRUE;// 这个tvb是顶层real tvb, 它的数据源就是它自己tvb->ds_tvb = tvb;frame_tvb = (struct tvb_frame *) tvb;// frame_tvb->buf不为NULL时tvb_frame_ops->frame_free会释放内存,// 但process_cap_file_single_pass()中会自己释放buffer,// 所以这里设为NULL表示不需要调用frame_free自动释放frame_tvb->buf = NULL;return tvb;}
解析器交接时的tvb
epan 结构体中包含 tvb 成员:
struct epan_dissect {struct epan_session *session;tvbuff_t *tvb;proto_tree *tree;packet_info pi;};
在解析过程中, 如 dissect_record() (epan/packet.c) 中, 设置 epan->tvb.
// epan/epan.cvoidepan_dissect_run_with_taps(epan_dissect_t *edt, int file_type_subtype,wtap_rec *rec, tvbuff_t *tvb, frame_data *fd,column_info *cinfo){wmem_enter_packet_scope();tap_queue_init(edt);dissect_record(edt, file_type_subtype, rec, tvb, fd, cinfo);tap_push_tapped_queue(edt);/* free all memory allocated */wmem_leave_packet_scope();}
把 tvb 添加到 packet info 的 data source 链表中, 并开始协议解析.
/* Creates the top-most tvbuff and calls dissect_frame() */voiddissect_record(epan_dissect_t *edt, int file_type_subtype,wtap_rec *rec, tvbuff_t *tvb, frame_data *fd, column_info *cinfo){.../* Add this tvbuffer into the data_src list */add_new_data_source(&edt->pi, edt->tvb, record_type);...call_dissector_with_data(frame_handle, edt->tvb, &edt->pi, edt->tree, &frame_dissector_data);...}
这里的 frame_handle 就是伪协议”frame”对应的解析器句柄.
// epan/packet.c/* Call a dissector through a handle and if this fails call the "data"* dissector.*/intcall_dissector_with_data(dissector_handle_t handle, tvbuff_t *tvb,packet_info *pinfo, proto_tree *tree, void *data){int ret;ret = call_dissector_only(handle, tvb, pinfo, tree, data);if (ret == 0) {/** The protocol was disabled, or the dissector rejected* it. Just dissect this packet as data.*/DISSECTOR_ASSERT(data_handle->protocol != NULL);call_dissector_work(data_handle, tvb, pinfo, tree, TRUE, NULL);return tvb_captured_length(tvb);}return ret;}// -->/* Call a dissector through a handle but if the dissector rejected it* return 0.*/intcall_dissector_only(dissector_handle_t handle, tvbuff_t *tvb,packet_info *pinfo, proto_tree *tree, void *data){int ret;DISSECTOR_ASSERT(handle != NULL);ret = call_dissector_work(handle, tvb, pinfo, tree, TRUE, data);return ret;}// -->static intcall_dissector_work(dissector_handle_t handle, tvbuff_t *tvb, packet_info *pinfo_arg,proto_tree *tree, gboolean add_proto_name, void *data){packet_info *pinfo = pinfo_arg;const char *saved_proto;guint16 saved_can_desegment;int len;guint saved_layers_len = 0;int saved_tree_count = tree ? tree->tree_data->count : 0;...saved_proto = pinfo->current_proto;saved_can_desegment = pinfo->can_desegment;saved_layers_len = wmem_list_count(pinfo->layers);DISSECTOR_ASSERT(saved_layers_len < PINFO_LAYER_MAX_RECURSION_DEPTH);...pinfo->saved_can_desegment = saved_can_desegment;pinfo->can_desegment = saved_can_desegment-(saved_can_desegment>0);if ((handle->protocol != NULL) && (!proto_is_pino(handle->protocol))) {pinfo->current_proto =proto_get_protocol_short_name(handle->protocol);.../* XXX Should we check for a duplicate layer here? */if (add_proto_name) {pinfo->curr_layer_num++;wmem_list_append(pinfo->layers, GINT_TO_POINTER(proto_get_id(handle->protocol)));}}if (pinfo->flags.in_error_pkt) {len = call_dissector_work_error(handle, tvb, pinfo, tree, data);} else {/** Just call the subdissector.*/len = call_dissector_through_handle(handle, tvb, pinfo, tree, data);}if (handle->protocol != NULL && !proto_is_pino(handle->protocol) && add_proto_name &&(len == 0 || (tree && saved_tree_count == tree->tree_data->count))) {...while (wmem_list_count(pinfo->layers) > saved_layers_len) {if (len == 0) {...pinfo->curr_layer_num--;}wmem_list_remove_frame(pinfo->layers, wmem_list_tail(pinfo->layers));}}pinfo->current_proto = saved_proto;pinfo->can_desegment = saved_can_desegment;return len;}// -->static intcall_dissector_through_handle(dissector_handle_t handle, tvbuff_t *tvb,packet_info *pinfo, proto_tree *tree, void *data){const char *saved_proto;int len;saved_proto = pinfo->current_proto;if ((handle->protocol != NULL) && (!proto_is_pino(handle->protocol))) {pinfo->current_proto =proto_get_protocol_short_name(handle->protocol);}if (handle->dissector_type == DISSECTOR_TYPE_SIMPLE) {len = ((dissector_t)handle->dissector_func)(tvb, pinfo, tree, data);}else if (handle->dissector_type == DISSECTOR_TYPE_CALLBACK) {len = ((dissector_cb_t)handle->dissector_func)(tvb, pinfo, tree, data, handle->dissector_data);}else {g_assert_not_reached();}pinfo->current_proto = saved_proto;return len;}
接下来调用协议 frame 的解析器 ():
// epan/dissectors/packet-frame.c...case REC_TYPE_PACKET:if ((force_docsis_encap) && (docsis_handle)) {dissector_handle = docsis_handle;} else {...dissector_handle =dissector_get_uint_handle(wtap_encap_dissector_table,pinfo->rec->rec_header.packet_header.pkt_encap);}if (dissector_handle != NULL) {guint32 save_match_uint = pinfo->match_uint;pinfo->match_uint =pinfo->rec->rec_header.packet_header.pkt_encap;call_dissector_only(dissector_handle,tvb, pinfo, parent_tree,(void *)pinfo->pseudo_header);pinfo->match_uint = save_match_uint;} else {col_set_str(pinfo->cinfo, COL_PROTOCOL, "UNKNOWN");col_add_fstr(pinfo->cinfo, COL_INFO, "WTAP_ENCAP = %d",pinfo->rec->rec_header.packet_header.pkt_encap);call_data_dissector(tvb, pinfo, parent_tree);}break;...
当找到下游解析器时, 又调用 call_dissector_only() , 所以形成了递归调用. frame 解析器并没有修改 tvb, 因为 frame 只是一个伪协议, tvb 中并不包含它的实际数据.
对于 Ethernet 报文, 下游是 eth 解析器, 而且对于普通 Ethrnet 报文, 它也没有修改 tvb. 下游是 ethertype 解析器.
ethertype 创建了 next_tvb, 把它传递给下游解析器, 此 tvb 不包含 ethernet 首部. ethertype 解析函数返回时, 仍返回原 tvb 长度.
// epan/dissectors/packet-ethertype.cstatic intdissect_ethertype(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, void *data){/* Get the captured length and reported length of the dataafter the Ethernet type. */captured_length = tvb_captured_length_remaining(tvb, ethertype_data->payload_offset);reported_length = tvb_reported_length_remaining(tvb,ethertype_data->payload_offset);...next_tvb = tvb_new_subset_length_caplen(tvb, ethertype_data->payload_offset, captured_length,reported_length);...dissector_found = dissector_try_uint(ethertype_dissector_table,ethertype_data->etype, next_tvb, pinfo, tree);...return tvb_captured_length(tvb);}
设下层是 Ipv4:
// epan/dissectors/packet-ip.cstatic intdissect_ip_v4(tvbuff_t *tvb, packet_info *pinfo, proto_tree *parent_tree, void* data _U_){.../* If ip_defragment is on, this is a fragment, we have all the data* in the fragment, and the header checksum is valid, then just add* the fragment to the hashtable.*/save_fragmented = pinfo->fragmented;if (ip_defragment && (iph->ip_off & (IP_MF|IP_OFFSET)) &&iph->ip_len > hlen &&tvb_bytes_exist(tvb, offset, iph->ip_len - hlen) &&ipsum == 0) {ipfd_head = fragment_add_check(&ip_reassembly_table, tvb, offset,pinfo,iph->ip_proto ^ iph->ip_id ^ src32 ^ dst32 ^ pinfo->vlan_id,NULL,(iph->ip_off & IP_OFFSET) * 8,iph->ip_len - hlen,iph->ip_off & IP_MF);next_tvb = process_reassembled_data(tvb, offset, pinfo, "Reassembled IPv4",ipfd_head, &ip_frag_items,&update_col_info, ip_tree);} else {/* If this is the first fragment, dissect its contents, otherwisejust show it as a fragment.XXX - if we eventually don't save the reassembled contents of allfragmented datagrams, we may want to always reassemble. */if (iph->ip_off & IP_OFFSET) {/* Not the first fragment - don't dissect it. */next_tvb = NULL;} else {/* First fragment, or not fragmented. Dissect what we have here. *//* Get a tvbuff for the payload. */next_tvb = tvb_new_subset_remaining(tvb, offset);/** If this is the first fragment, but not the only fragment,* tell the next protocol that.*/if (iph->ip_off & IP_MF)pinfo->fragmented = TRUE;elsepinfo->fragmented = FALSE;}}if (next_tvb == NULL) {/* Just show this as a fragment. */col_add_fstr(pinfo->cinfo, COL_INFO,"Fragmented IP protocol (proto=%s %u, off=%u, ID=%04x)",ipprotostr(iph->ip_proto), iph->ip_proto,(iph->ip_off & IP_OFFSET) * 8, iph->ip_id);if ( ipfd_head && ipfd_head->reassembled_in != pinfo->num ) {col_append_frame_number(pinfo, COL_INFO, " [Reassembled in #%u]",ipfd_head->reassembled_in);}call_data_dissector(tvb_new_subset_remaining(tvb, offset), pinfo,parent_tree);pinfo->fragmented = save_fragmented;return tvb_captured_length(tvb);}if (tvb_reported_length(next_tvb) > 0) {/* Hand off to the next protocol.XXX - setting the columns only after trying various dissectors meansthat if one of those dissectors throws an exception, the frame won'teven be labeled as an IP frame; ideally, if a frame being dissectedthrows an exception, it'll be labeled as a mangled frame of thetype in question. */if (!ip_try_dissect(try_heuristic_first, iph->ip_proto, next_tvb, pinfo,parent_tree, iph)) {/* Unknown protocol */if (update_col_info) {col_add_fstr(pinfo->cinfo, COL_INFO, "%s (%u)",ipprotostr(iph->ip_proto), iph->ip_proto);}call_data_dissector(next_tvb, pinfo, parent_tree);}}pinfo->fragmented = save_fragmented;return tvb_captured_length(tvb);}
一般条件下, 会创建一个 subset tvb, 传递给下游. 设下层是 udp, 最终调用 decode_udp_ports() 函数:
voiddecode_udp_ports(tvbuff_t *tvb, int offset, packet_info *pinfo,proto_tree *udp_tree, int uh_sport, int uh_dport, int uh_ulen){...next_tvb = tvb_new_subset_length_caplen(tvb, offset, len, reported_len);...if ((low_port != 0) &&dissector_try_uint(udp_dissector_table, low_port, next_tvb, pinfo, tree)) {handle_export_pdu_dissection_table(pinfo, next_tvb, low_port);return;}if ((high_port != 0) &&dissector_try_uint(udp_dissector_table, high_port, next_tvb, pinfo, tree)) {handle_export_pdu_dissection_table(pinfo, next_tvb, high_port);return;}...call_data_dissector(next_tvb, pinfo, tree);...}
如果下游是 DNS, 直接在 dissector_try_uint() 调用中结束, 最终调用 dissect_dns_common() , 其中正常流程没有创建 tvb, 也没有递交后下游.
所有协议层解析完毕后, 调用栈回退, 回到调用起点, 如 epan_dissect_run_with_taps(), 其中调用 wmem_leave_packet_scope(), 释放在当前报文作用域内存池中分配 的内存. 再回退, 如 process_packet_single_pass(), 会释放 epan_dissect_t 相关资源:
// tshark.c, process_packet_single_pass()if (edt) {epan_dissect_reset(edt);frame_data_destroy(&fdata);}// epan/epan.cvoidepan_dissect_reset(epan_dissect_t *edt){.../* Free the data sources list. */free_data_sources(&edt->pi);if (edt->tvb) {/* Free all tvb's chained from this tvb */tvb_free_chain(edt->tvb);edt->tvb = NULL;}if (edt->tree)proto_tree_reset(edt->tree);tmp = edt->pi.pool;wmem_free_all(tmp);memset(&edt->pi, 0, sizeof(edt->pi));edt->pi.pool = tmp;}// epan/frame_data.cvoidframe_data_destroy(frame_data *fdata){if (fdata->pfd) {g_slist_free(fdata->pfd);fdata->pfd = NULL;}}
其中, 调用 tvb_free_chain() 释放了各协议(可能)创建的 tvb. 不少情况下这些 tvb 没有对报文进行重组或拷贝, 这样的话实际上只是 free 掉 tvb 对象本身.
报文重组时的tvb
5 Buffer
Buffer 实现了简单的内存块管理, 仅用于 wiretap.
5.1 数据结构
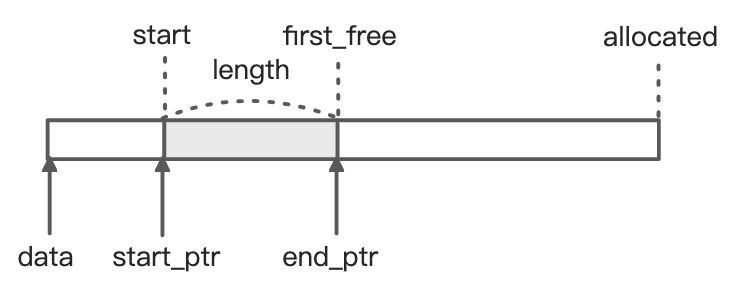
typedef struct Buffer {guint8 *data;gsize allocated;gsize start;gsize first_free;} Buffer;
其中:
- data: 分配的内存块起始地址
- allocated: 分配的内存块大小
- start: 当前数据区起始位置
- first_free: 当前数据区结束位置, 或者说空闲内存块的起始位置
除以上结构体成员外, Buffer 还有一些用宏或函数表示的属性:
- length: 当前数据区大小
- start_ptr: 当前数据区起始指针
- end_ptr: 当前数据区结束位置
这里我特意区分了”内存块”与”数据区”:
- 内存块指分配的大块堆内存; 而数据区则指的是这块内存上当前实际存储的用户数据
- 内存块仅在空间不足时重新分配(更大的空间), 一般不变; 而数据区则是可能经常变化的, 可增大,缩小,清空等, 相当于内存块的一个滑动窗口
Buffer 的结构如下图所示:
5.2 接口
init
初始化 Buffer. Buffer 内存块分配的最小单位是 2KB, 请求分配的大小小于 2KB 时, 仍分配 2KB. 不大于 2KB 的小内存块由指针数组 small_buffers 缓存.
#define SMALL_BUFFER_SIZE (2 * 1024) /* Everyone still uses 1500 byte frames, right? */static GPtrArray *small_buffers = NULL; /* Guaranteed to be at least SMALL_BUFFER_SIZE *//* XXX - Add medium and large buffers? *//* Initializes a buffer with a certain amount of allocated space */voidws_buffer_init(Buffer* buffer, gsize space){g_assert(buffer);if (G_UNLIKELY(!small_buffers)) small_buffers = g_ptr_array_sized_new(1024);if (space <= SMALL_BUFFER_SIZE) {if (small_buffers->len > 0) {buffer->data = (guint8*) g_ptr_array_remove_index(small_buffers, small_buffers->len - 1);g_assert(buffer->data);} else {buffer->data = (guint8*)g_malloc(SMALL_BUFFER_SIZE);}buffer->allocated = SMALL_BUFFER_SIZE;} else {buffer->data = (guint8*)g_malloc(space);buffer->allocated = space;}buffer->start = 0;buffer->first_free = 0;}
首次初始化一个 Buffer 时, 会创建空的 small_buffers 数组;
small_buffers 中缓存被回收的小 Buffer, 见后续 free 流程;
后续再初始化 Buffer 且请求大小 <= 2KB 时, 如果 small_buffers 数组中有缓存的内存块, 就直接使用它, 而不是调用 g_malloc 分配新的内存块, 这可提升性能.
free
释放 Buffer. 如果是小内存块, 则不调用实际的堆内存释放接口(g_free), 而是将它的内存块指针缓存到 small_buffers 数组, 以备之后使用.
/* Frees the memory used by a buffer */voidws_buffer_free(Buffer* buffer){g_assert(buffer);if (buffer->allocated == SMALL_BUFFER_SIZE) {g_assert(buffer->data);g_ptr_array_add(small_buffers, buffer->data);} else {g_free(buffer->data);}buffer->allocated = 0;buffer->data = NULL;}
remove_start
将起始位置往后挪动若干个位置. 当挪动后的位置正好是当前内存块结束位置时, 相当于清空了内存块, 这将导致起始位置和结束位置都清零.
voidws_buffer_remove_start(Buffer* buffer, gsize bytes){g_assert(buffer);if (buffer->start + bytes > buffer->first_free) {g_error("ws_buffer_remove_start ...}buffer->start += bytes;if (buffer->start == buffer->first_free) {buffer->start = 0;buffer->first_free = 0;}}
clean
清空内存块. 清空之后 Buffer 又回到了初始状态.
# define ws_buffer_clean(buffer) ws_buffer_remove_start((buffer), ws_buffer_length(buffer))
assure_space
确保仍有指定大小的空闲块可用. 检查步骤如下:
- 首先检查尾部有没有可用空间, 如果有就返回;
- 否则, 如果已经使用了部分空间, 则把当前实际数据移动到内存块起始处. 这里也检查了首部有没有可用空间, 做数据移动只是为了把原有数据尽可能存放在靠前位置;
- 如果首部有可用空间, 返回;
至此, 已知首部和尾部都没有可用空间, 只能重新分配更大的内存块. 注意, 调用 realloc 成功后, 原内存块中的数据会被拷贝到新内存块中.
/* Assures that there are 'space' bytes at the end of the used spaceso that another routine can copy directly into the buffer space. Afterdoing that, the routine will also want to runws_buffer_increase_length(). */voidws_buffer_assure_space(Buffer* buffer, gsize space){g_assert(buffer);gsize available_at_end = buffer->allocated - buffer->first_free;gsize space_used;gboolean space_at_beginning;/* If we've got the space already, good! */if (space <= available_at_end) {return;}/* Maybe we don't have the space available at the end, but we wouldif we moved the used space back to the beginning of theallocation. The buffer could have become fragmented through lotsof calls to ws_buffer_remove_start(). I'm using buffer->start as thesame as 'available_at_start' in this comparison. *//* or maybe there's just no more room. */space_at_beginning = buffer->start >= space;if (space_at_beginning || buffer->start > 0) {space_used = buffer->first_free - buffer->start;/* this memory copy better be safe for overlapping memory regions! */memmove(buffer->data, buffer->data + buffer->start, space_used);buffer->start = 0;buffer->first_free = space_used;}/*if (buffer->start >= space) {*/if (space_at_beginning) {return;}/* We'll allocate more space */buffer->allocated += space + 1024;buffer->data = (guint8*)g_realloc(buffer->data, buffer->allocated);}
append
在当前内存块后面添加一段数据. 注意首先会调用 assure_space 确保有足够的空间, 然后再进行数据拷贝. 另外注意拷贝的目的地址是 data+first_free, 即当前空闲内存块起始地址 .
voidws_buffer_append(Buffer* buffer, guint8 *from, gsize bytes){g_assert(buffer);ws_buffer_assure_space(buffer, bytes);memcpy(buffer->data + buffer->first_free, from, bytes);buffer->first_free += bytes;}
cleanup
清理 small buffers 数组.
voidws_buffer_cleanup(void){if (small_buffers) {g_ptr_array_set_free_func(small_buffers, g_free);g_ptr_array_free(small_buffers, TRUE);small_buffers = NULL;}}
6 frame_data
// TODO
参考
- Wireshark源码: doc/README.wmem
- Wireshark源码: epan/wmem/
- Wireshark源码: epan/tvbuff.h
- Wireshark源码: wsutil/buffer.h
- Wireshark源码: frame_tvbuff.h
- Wireshark wiki: KnownBugs/OutOfMemory
- GitHub: 我修改过的Wireshark代码(zzqcn分支)
- GitHub: Wireshark调用代码

若有收获,就点个赞吧
0 人点赞
