好 同学们现在呢来看一下
我们这个boosting
集成方法当中的这个GBDT 哈
我们这个GBDT 呢它是一种梯度提升树哈
那我们在介绍这个GBDT 之前呢
我们首先给大家介绍一下我们这个比较
容易理解的这个提升树
也就是BDT
然后呢我们再在这个提升树的基础上
来给大家介绍一下我们这个GBDT 哈 
那么在这里我们首先看一下我们这个BDT
我们这个BDT呢它是一种就是
使用这个CART
决策树来作为基学习器的一种集成学习方法
首先呢我们来看一下我们下面这幅图哈
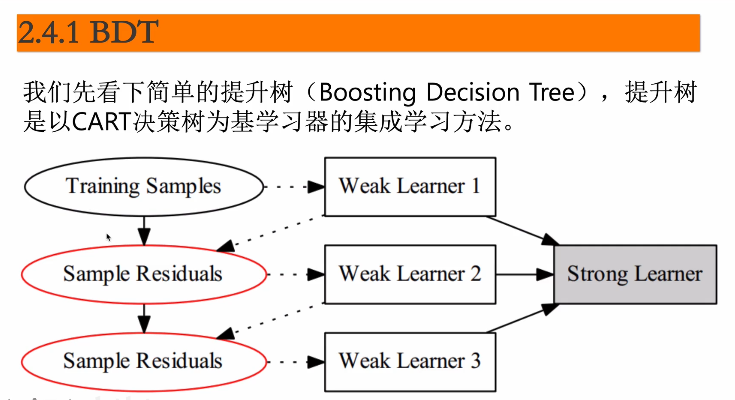
我们这幅图呢就表明了我们这个BDT
它的整个的一个学习过程哈
那首先我们拿到了一组训练数据
也就是我们这个training simple 是不是啊
我就拿我这种这一组训练数据呢来训练我第一个弱学习器
那拿到我这第一个弱学习器之后
是不是可以对它进行一个预测呀
对不对 我使用我的预测结果跟我原来的训练数据做差
那我就得到了我原数据跟我这个预测结果之间的一个残差
是不是啊
那我在训练我第二个弱学习器的时候呢
我就使用我得到的这个残差来作为我的训练数据
我得到了
我就可以训练得到我 这第二个弱学习器 是不是
那同样的第三个弱学习器 我就可以使用
我第二个弱学习器的一个预测结果跟我跟他的训练数据
再做一个残差是不是
然后这就是我第三个弱学习器的一个训练数据
对不对
那我这样重复n 次 我是不是就有了n 个weak learner
就是n 个弱学机器 对不对
那我把这个n 个弱学习器给它加在一起
它就构建成了我们这个就是比较强的这个学习器哈
也就是说我们这个BDT的一个集成结果
那我们做预测的时候呢 我们就使用我们这个strong
learner
也就是说这个强学习器来进行预测就可以了哈
这是我们这个提升的一个简单的流程哈

然后我们来看一下我们这个提升数它到底是怎么做的呢
我们这个提升数呢 它本身就是这个bosting
所以呢它也是我们这个加法模型和我们这个前项分布
算法是不是
所以呢我们首先来给大家看一下我们这个整个的一个呃流程啊
首先呢我拿到一组数据之后
我首先初始化第零个就是第一个提升数 我把它初始化零
那我现在在训练f 一的时候 大家想一下我这个f
零它的预测结果是零 我f 一是不是就是我原始的数据啊
对不对 所以我可以得到我们这个f 一 我拿到呢就得到了f
m 减一个这样的若学习
机器啊这个啊这是我们的就是我们f 零x 呢我们先设为零
就是初始化一个提升数哈 那我拿到这个提升数之后
我是不是可以训练下一个弱学习器呀 对不对
那我在f 零的时候
大家讲一下我的弱学习器是不是就拿我这个训练数据来进行训练就可
以了 是不是 那再往下的时候 我才是使用这个残差哈
比方说我现在已经迭代了m 减一次了 我要来求解我d m
次的这个提升数哈 这个f m x 大家注意一下啊
这里呢是我们这个就是弱学习器的一个核
而这个t x sit m 呢是我们这个弱学习器决策树哈
那我学我要学的我们这个f m x 的时候 我是不是就是
利用我前m 次的一个预测 然后呢求得残差之后来训练我这第m
棵决策树就可以了 是不是 也就是说我在d m 次迭代的时候
我就是要得到我这d m 决策数是不是
那最终的结果f m 呢我就是把这m
棵决策树给它进行一下求和 得到的就是我们这个强学习器
也就是b d t 的一个集成结果啊那
大家看一下我们这个t x sit m 哈 这里面x
是它的一个训练数据 对不对 然后这个c t m
呢是我们的一个参数啊
就是说我在构建这个决策数当中的一些参数
然后我们再来看一下我们怎么来求解我们这个t x 西塔m 呢
因为我求解f m x 的时候 主要是求解这d m
和决策数是不是
那跟其他的算法是一样的
我们在这里呢也是要构建一下我们这个叫做什么损失函数哈
那在这里看一下我们在这里d f m 次预测的时候
我们大家想一下我们这个f m 减一 我认为它是
是就是已知的 是不是我就已经完成了
我们在这里呢就求我们这个真实值和我这个d m 减一次
它的就是f
f m 减一和这个t x 的一个预测结果 我使它最小
我是不是就得到了我们这个d m 棵决策树呀 对不对
我的这就是我们的整个的方法 就是要构建我的损失函数
然后呢 利用这个损失函数进行优化 优化之后
我就得到了我这第m 棵决策树哈
那我们这个损失函数怎么构建呢
那它跟肯定是根据你的问题来进行一个构建了哈 比方说
如果你要是使用分类的话 就用于分类的话
你可以用什么指数损失函数 然后呢 如果你是回归问题的话呢
你就可以使用这个平方误差损失 对吧
那我们这里呢当然你也可以使用其他的一般的损失函数啊
只要可以 就是可以进行一个需求导就可以了哈 好
下面我们再看一下 我们来看一下我们这个提升数哈
如果我们是回归问题
并且我们采用了这个平方误差平方损失函数的时候
我们看一下我们叠d m 字迭代式的表示哈 大家看一下
这还是我们刚才构建那个损失函数 是不是我就要使它最小化
对不对
然后呢 我们损失函数的时候呢 我们把它构建一下什么平方损失
然后这个y 是我们的真实值 然后f m 减一呢是我们d m
减一次的一个预测结果 这是我们d
t 呃就是d m 棵决策树是不是 如果我使用平方损失的时候
我是不是就是y 减去f m 减一x 减去t x 西塔m
的平方呀 大家看一下 就我们这个
公式对不对 然后大家看一下这里啊 y 减去f m x
大家想一下
这是不是就是我的真实值跟我上一次预测结果的一个残差 对不对
就是我们这个残差二
然后我这d m 和决策树呢 是不是就对我们这个r
做一个拟合呀 对不对 所以我在训练第m 棵决策树的时候
我的目标值是不是就是我们的损失哈 就是我们这个的
而我们这个b d t 呢也就是提升数呢
也就是通过这个残差来获取到一系列的呃这个叫做决策弱学习器之后
然后求和得到我最终的一个什么最终的一个集成结果哈
好
下面呢我们再给大家就是会呃看一下我们这个提升数它的整体的一个
流程哈 首先在这里我们首先是获取到我们这个训练数据集 对不对
我们在这里呢首先初始化我们这个f 零x 等于零
也就是刚一开始的时候
那我们这认为我们得到的这个呃集成的学习结果呢是零哈 然后呢
我们比方说我要生成m 个
如果学习器我就遍历一下 从一到m 进行一个遍历 然后呢
针对每一个样本 我要计算它的残差 残差的时候
比方说我要计算m 次 小m 次的时候
我是不是又计算我这个当前
真实值跟我就是我这个真实值跟我前m
次的一个预测结果的一个差值 我就获得了这个残差 是不是
那拿到残差之后 我是不是就可以训练第m 棵决策树了
比如说我得到了我们这个t x set m
然后呢我们这个d m 次的这个集成结果 f m x
呢它就等于m f m 减一x 加上我们这个t x 西塔m
是不是 那我们就得到了我们这个f m x 的
然后我遍历完成之后 遍历到大m
我是不是就得到了我最终的一个集成结果 也就是我从m
一直从一加到m 每一棵决策树给它加在一起
我就得到了我最终的这个提升数哈
那这个提升数它的主要点呢就是说我在每次构建这个弱学习器的时候
我使用的都是我上一次预测结果与我上一次训练数据的一个残差
来拟合当前这个弱学习器 对不对 那我们来看一下我们这个g
b d t 它是怎么做的呢 我们这个g b d t
呢它是这个grinding it boston d c n
t 你看大家看一下 这是梯度提升决策数是不是
是啊 大家可以把它理解为吗
能理解为我们这个梯度提升和决策数的一个结合哈
这个呢是这个fried man 他提出来的
他是利用这个最速下降的方法啊
利用我们这个损失函数的负梯度来拟合机学习器 啊 大家看一下
我们刚才在b d t 的时候
我们是使用什么残差来拟合我们这个
积学习器是不是
那我们在这里呢是使用这个损失函数的负梯度来拟合这个积学机器
那我们为什么可以使用这个负梯度来拟合这个机学机器呢
大家看一下 这就是我们这个y
l y i f x i 是不是我们的损失函数啊
就是我们对f x i 做了一个梯度
然后我们就用它来拟合我们这个基学习器
那我们为什么可以使用它
它来作为积雪机器的拟合结果呢
我们来看一下我们这个平方损失函数啊
我们就通过平方损失函数来给大家介绍
当然其他损失函数也是可以就是可以获得这个结果的
只不过呢会比较麻烦一些哈
好 我们在这里通过这个平方损失函数来给大家计算一下
为什么我们可以使用这个损失函数的负梯度来替代残差作为我们的一
我们看一下我们在这个损失函数前面呢
我们这个损失函数平方损失的时候
我们就真实值减去预测值的一个平方 对不对 然后呢
我们为了就是为了求导求导哈 我们在前面加了一个二分之一
然后呢 我们对它进行对这个f x i 进行和求导 因为y
i 是我们的真实值 我们是知道的 是不是
所以这里面我们在求导的时候
大家看一下我们这个二郎的前面来是不是负二倍的f x
二倍的y i 减去f x 再乘以负一呀 对不对
我们得到的结果就是f x i 减去y i 对不对
这就是我们这个就是求导之后的结果
那我们这个残差是什么呢 残差是不是y i 减去f x 呀
对不对 所以哈我们这个全差是我们这个梯度的一个相反数
也就说我们这个
残差呢可以用我们这个负梯度来进行一个表示
那我们在这一呃在你和d t 呃d m 个负极学习器的时候
我们就可以使用呢就用这个
损失函数的负梯度来替代替我们这个残差来进行这个拟合哈 好
那我们来看一下我们这个g b d t
它提升的一个就是它的一个流程哈
梯度提升的流程哈
那在这里呢我们首先训练以及是我们这个data 它是x 一x
一x 一直到i n 个样本 然后y 呢是我们的目标值
那首先呢我们初始化一下初始化的时候 那我们这个f 零x
呢就等于我们这里面
那么这里可以给它初始化零啊 也是可以的哈 然后呢
我们在这里给它初始化呢是我们这个y i 和h 零x h
零x 是什么 我们在这里呢就给它呃就给它
写为什么写为一个就是说我第一次预测的时候就使用了原始的这个数
据 它的一个基学习器获取的一个基学习器 然后呢我们这个f
零x 呢我们就得到的就是对它进行求和的一个
结果哈好 那下面呢我们再接着往下拟合哈
就是往下获取我们这个叫做它的一个弱学习器
然后呢我们得到了f 零x 然
然后接下来我就辨别 比如说我需要生成t
科这个弱学习期的时候呢 我们就呃就给它进行什么呢
首先就是计算这个负梯度
负梯度呢也就可以代替我们前面给大家说的这个什么乘差
然后呢我们就利用
利用这个你和残差是不是就你和我们这个学习期呀
你和我们这个梯度的负嗯相反数也是这个负梯度 对不对 然后呢
你和他我得到了我的鸡学习器 这是我们的一个鸡学习器 对不对
机学习器哈 这是我们得到这个机学习器的权重之后呢
然后我们再怎么做呢 这里面大家看一下啊
我是要我你和这个残差的时候 我是用平方
损失来给它进行拟拟合的啊 大家看一下
我们这里面是我们的真实值y i 也有我们的负梯度
然后减去我们这第七颗这个弱学习器 我们是不是要让它最小呀
对不对
最小我获取的那个基学习器才是我们就是最优的那个 对不对
所以这里面我们这里面w t 什么w t 就是我们的参数
我们就获取到了这个
对于当前数据来说
最好的这个弱学习器是不是获取到这个弱学习器之后呢
我们还要做什么
我们在这里跟我们在提呃提升数当中不同的呢我们每一个机器乐器器
权重 然后呢 我们再进行一下拟合 拟合的时候呢
我们就是在这个积学习器前面加了一个什么加了一个
呃 权重之后 我再跟我原始数据
那还有前面的这些这些个叫做若学习器加在一起之后 然后呢
我们再确定一下我们这个阿尔法t 的最优值 然后呢
然后我就得到了我们这个机学习器的一个权重 最后的时候呢
我们这个f t x 呢就是f t f t 减一x
加上我们这个当前的弱学习器乘以一个权重哈 这是我们这个
梯度提升的一个整个的流程哈 在这里我们再去求和的时候呢
我们在这个积学习题前面就要加一个阿尔法
也就是说我们这个权重哈 我们来看一下我们这幅图
这就是我们这个g b d t 它的一个整个的流
流程哈大家看一下 我们这是我们原始的所有的训练数据
拿到这些训练数据之后呢 我们首先训练一个弱学习器
然后拿到这个弱学习器之后 我是不是可以计算什么计算损失函数
对不对
我对我的损失函数求导求导之后 我就得到了我的梯度 然后呢
在这里得到梯度之后呢 我就可以再训练下一个弱学机器 是不是
然后在获得这个弱学习器之后
我是不是可以把这个弱学习器的预测结果 然后呢
跟我其他的就是前面的多个弱吸气加在一起之后来求一个比较好
好的权重对不对 然后呢 对于每一个弱学习器
我又得到了一个权重
是不是同样的利用这个热水器我也可以得到的一个梯度
得到一个权重 然后
然后呢 这个也是然后得到这些权重之后呢
我们就可以利用这些权重乘以它对应的弱学习器
然后求和之后就得到了我这个梯度提升的一个集成结果哈
这个跟我们在b d t 也就是说跟我们在提升数当中的区别呢
就是说我们这个残差它是使用这个负梯度来给它进行一个替代了
对不对 而且我们每个机学习器中
还加入了对应的参数权重哈 这是我们这个g b d t
梯度的一个提升流程哈 而我们这个g b d t
呢它是用我们这个回归数来给它进行一个构建的 是不是
我们回归数有一个特性是什么呢 我们这个回归数啊
它是将我们这个就是这个空间啊 就是说将这个
参数空间给它划分成了k 个不相交的区域
如果我确定了这个每个区域的k 值c 值的话
大家想一想我的决策树可以写什么 我的决策树是不是可以写成
当我的k 当我的这个值 它存在于我这个d k 个区域的时候
我可以确定我们这个d k 个区域的值
然后把它表示成这个样子呀 对不对
所以呢我们的回归数可以表示成这个这种形式 对不对
这种数学表达形式哈
那我们看一下为什么我们可以表达成这种不同空间啊 就是这种
呃 不同每个区域的这种表示形式啊
大家看一下我们在这里呢我们构建了一个决策树 这是什么呢
就是说嗯就是一个人哈他是不是喜欢唱歌
就是他在喜欢对唱歌的一个喜欢程
然后比方说呢他在这个一一年的时候呢
他是呃在一一年之前是比较喜欢的 然后一年之后呢
又就是嗯就还可以吧
然后一零年之前呢 他是嗯
比较喜欢的 然后呢 一零年之后又是不喜欢的这是我们这个内容
大家看一下啊 我们在这里这是我们构建的这个决策树 是不是啊
我们这个决策树有有三个 这个叫什么 三个叶节点是不是
我们这个三个月节点呢就可以把我们这个整个空间
我们在这里呢是随着时间的
是不是我们就可以把我们这个时间给它划分为三个空间
然后每个空间呢它的输出是多少呢 大家看一下
我如果在这里的时候 它
对应的是不是就是我们这个零点二呀 对不对
然后在这里的时候呢 就是我们这个一点二
然后这个地方呢就是我们这个一点零对不对
所以我们如果把这个决策树
给它表示出来的时候 我们就可以利用它分成的空间 对不对
以及每一个空间它的输出值来给它进行一个表示哈
那这样我把我们的角色数表示成这种形式之后呢
我们是不是可以把这个流程给大家重新写一下
然后在这里还是一样的 这是我们的训练数据 对不对
然后我们有n 个训练数据
然后呢
我们通通过这个训练数据得到了第一个什么得到了第一个这个弱学习
器 拿到弱学习器之后呢 我们下面进行一个就是一个循环哈
然后在这个里面呢 我们首先计算我这个负梯度 然后呢
你和我们这个负梯度
我得到这个回归数 然后这个时候的回归数呢 我要
表示的时候呢 我们就表示c k i 来给它进行一个表示
是不是 然后呢再更新我们这个f t x
然后最后得到我们这个加法的模型哈 这是我们这个
g b d t 这个决策数的时候
你是可以这样进行一个表示哈 当然我们这里啊大家如果注意的话
我们这里是直接是h t x 对不对 然后呢
为什么我们没有将那个wait 呢 因为我们这个c k
c k 里面你是可以加入你这个weight 值的 对不对
然后呢 这是我们这个内容啊 就是说这个c k
本身是一个常数 这个值呢在这里我们是相当于把它加到了这个c
k 里面哈 这是我们这个人
g b d t 回归的一个流程
那如果我要想见使用我们这个g b d t
来进行一个分类任务的时候 我们怎么做呢 我们这个g b d
t 啊如果
如果你是解决这个分类问题的时候
它仍然是有使用我们这个card 的回归数哈
在这时候呢我们就是使用这个soft max
是根据我们这个类别呢进行一个映射
然后呢 对类别的残差再进行一个拟合哈 给大家看一下
这是我们的整个的一个就是分类问题的一个流程哈
在这里我们这个f
零x 呢就是说对k 个类别来说 我们这里呢首先给它设置为零
就是初始化 这个大k 呢就是说我现在包含k 个类别 然后
然后呢 我这里面每个类别呢 我们希望是生成m 棵树 m
棵决策树来给它进行一个就是呃预测哈
然后我们首先要做的是什么 是
soft max 进行概率的映射是不是 那我就用soft
max 呢把我们这个给它映射成一个概率
然后下面呢我们就要生成什么 就是因为我有k 个类别
每个类别我都要生成这个
这个呃回归数哈弱学习器 然后在这里呢我们这个y i k
是我们的真实值 然后我们减去我们这个p 呃p k x i
然后呢 y i k 这是我们当前要预测的一个结果 对不对
然后呢 我们这里呢这是就要拟合回归数
将我们这个空间呢给它分成几个步
相交的区域 因为我们在这儿还是使用我们这个card 数
对不对 那拿到这个不确定的区域之后哈
就拿到这个呃切割不相交的区域之后呢 我们要确定
每一个区域上的一个输出 对不对 也就是我们这个r j k
m 我们说到这个输出之后 我们是不是就可以给他做一个加法
得到我们最后的这个模型呀 是不是
这就是我们这个分类的问题哈 如果你使用g b d t
来处理这个分类问题是怎么做的哈 大家要注意哈
我们在进行这个分类问题的时候 我们是使用one v s r
e s t 哈就是说
在这里面分类问题的时候 我们还是要给它组合成什么呢
组合成二分类问题之后 再进行一个求解的哈
然后我们看一个例子哈 比如说
我们现在呢有三个类别 然后我们怎么做这个g b d t
的分类呢 我们就要针对每个类别先训练一个回归数
如果有三个类别 那就选哪三棵树
比方说我有一个样本x i 呢 它是第二类 大家想一下啊
我这三棵树的输入对于第一个类别 我们的目标值是不是零呀
就是它肯定不是我第一个类别
然后第二个类别呢就是x i e 对对不对
然后第三个类别呢就是x i 零是不是
然后呢我们每一棵树都的训练过程啊都是要就是构建一个car
的数 对不对
那对于这个x i 呢 我们每一棵树都有了一个预测结果
一个是f 一x 第一类的 还有一个是f 二f 三
就是一二三这三个类别的一个预测结果是不是
那我接下来呢就用这个soft max 来产生我们这个概率哈
如果你是第一个类别的话 我就这样子给他产生一下 是不是
如果你是第二个类别的时候 我们在这里就一x p f 二
然后这是p 二x 这对应的就是我们
这一步是不是得到了我们这个概率 那拿到这个概率之后呢
我们分别计算这个残差
残差呢我们就是刚一开始真实值第一个类别是零 第二个是一
第三个是零 是不是啊 在这里面就是零减去p 一x 三
然后呢 一减去p 二x i 和零减去p 三x i
对这里呢就是我们这个内容对不对
就是每一个类别我都要减去做做一下残差 那拿到残差之后
我是不是就可以继续训练了 对不对
这时候我的目标值是不是就是我们这个残差的一个结果了 对不对
然后呢我再继续训练出每个类别的一棵树 也就是一共三个数
那接下来我是不是就循环这个过程 然后每一个类别都生成
m 棵树对不对 然后最后的时候呢 我们在预测的时候
只要找出我们那个概率最高的 也就是说我们这个三个类别里面
每一个都会输出一个类别 如果拿到一个新的样本之后 每一个
集成的结果都会输出一个类别
就是它属于我当前这个样本的一个类 这是个类别的一个概率
对不对
我们选择这个概率最大的作为我当前样本的一个类别就可以了哈
这是我们这个
d b d t 的一个流程
好 那g b d t 呢我们就给大家介绍到这里哈

若有收获,就点个赞吧
0 人点赞
