状态(X) : 机器对环境的感知, 所有可能的状态称为状态空间;
动作(A) : 机器所采取的动作, 所有能采取的动作构成动作空间;
转移概率(P) : 当执行某个动作后, 当前状态会以某种概率转移到另一个状态;
奖赏函数(R) : 在状态转移的同时, 环境给反馈给机器一个奖赏。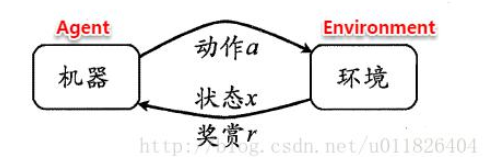
强化学习的主要任务就是通过在环境中不断地尝试, 根据尝试获得的反馈信息调整策
略, 最终生成一个较好的策略π , 机器根据这个策略便能知道在什么状态下应该执行什么动作
常见的策略表示方法:
确定性策略:
 , 即在状态
, 即在状态
随机性策略:
 , 即在状态
, 即在状态  下执行
下执行 动作的概率。
动作的概率。
一个策略的优劣取决于长期执行这一策略后的累积奖赏
T步累计奖励
 ,即执行该策略T步的平均奖赏的期望值
,即执行该策略T步的平均奖赏的期望值
r折扣奖赏
 ,一直执行到最后,同时越往后的奖赏权重越低
,一直执行到最后,同时越往后的奖赏权重越低

若有收获,就点个赞吧
0 人点赞
