
在模型已知时,对任意策略π能估计出该策略带来的期望累积奖赏.
令函数 表示从状态x出发,使用策略π所带来的累积奖赏
表示从状态x出发,使用策略π所带来的累积奖赏
函数 表示从状态x出发,执行动作a后再使用策略π带来的累积奖赏
表示从状态x出发,执行动作a后再使用策略π带来的累积奖赏
状态值函数(V) : V(x) , 即从状态 x 出发, 使用π 策略所带来的累积奖赏;
状态-动作值函数(Q) : Q(x,a) , 即从状态 x 出发, 执行动作 a 后再使用π 策略所带来的累积奖赏。
 表示起始状态,
表示起始状态,  表示起始状态上采取的第一个动作;
表示起始状态上采取的第一个动作;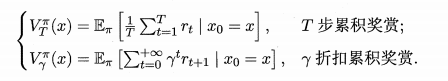
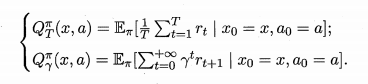
V(x)推导过程

类似地, 对于 r 折扣累积奖赏可以得到: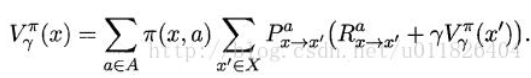
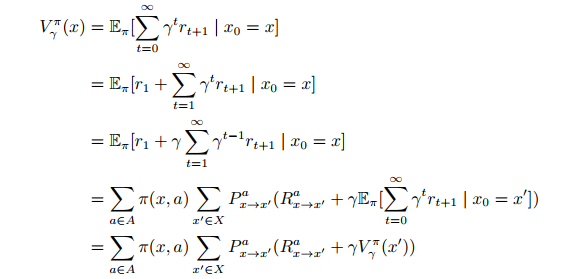
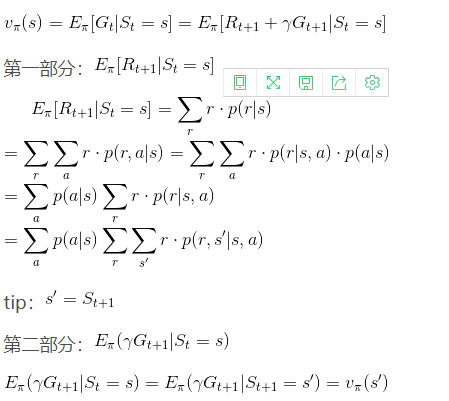

矩阵形式
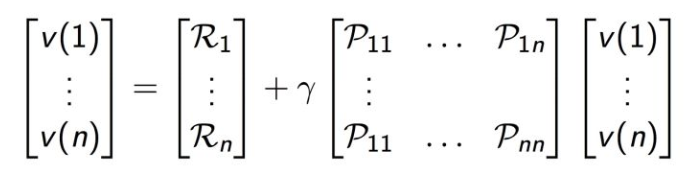


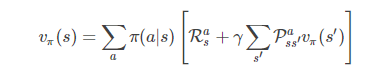
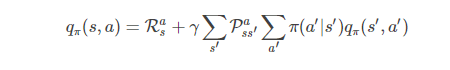
递归计算V(x)
易知: 当模型已知时, 策略的评估问题转化为一种动态规划问题,
即以填表格的形式自底向上,先求解每个状态的单步累积奖赏,
再求解每个状态的两步累积奖赏, 一直迭代逐步求解出每个状态的 T 步累积奖赏。
算法流程如下所

Q(x,a)

若有收获,就点个赞吧
0 人点赞
