keras后端的理解
keras是一个模型级库,为使用者提供API服务,而对于极为基础的像张量乘积和卷积运算等操作,keras常常不会执行,而是交给一个专门的、优化的张量操作库来执行,可以将其看作是keras的后端引擎,专门用来数据的计算
对于API的理解
bing一下API发现浏览器给出的解释是:API(Application Programming Interface,应用程序编程接口)是一些预先定义好的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或者理解内部的工作机制
举一个生活中的例子:在生活中,如果我们要打扫房间,处于方便,常常会叫家政公司来给我们打扫,我们只需要在打扫完之后来对打扫结果进行验收,而无需了解打扫的过程和打扫的原理。在我们学习python时使用下载模块来对函数进行调用,个人认为该过程也可以理解为一个API的过程。
keras搭建一个简单的回归神经网络
- 初始数据的收集和处理 ```python import numpy as np np.random.seed(1337) from keras.models import Sequential from keras.layers import Dense import matplotlib.pyplot as plt
创建一些数据,创建一维随机数组
x = np.linspace(-1,1,200) np.random.shuffle(x)#将得到的一维随机数组进行打乱 y=0.5*x+2+np.random.normal(0,0.05,(200,))#计算y的值,顺便加入噪声点
在画布中点出该随机点
plt.scatter(x,y) plt.show()
将数据分类为train_data和test_data
x_train,y_train=x[:160],y[:160] x_test,y_test=x[160:],y[160:]
2. 多层神经网络的搭建```python#从第一层到最后一层的的搭建model=Sequential()model.add(Dense(output_dim=1,input_dim=1))
对于模型的整合和误差计算的方法和优化器的选择
model.compile(loss="mse",optimizer="sgd")
神经网络的运行train
print("training----------")for step in range(301):cost = model.train_on_batch(x_train,y_train)#分批进行训练,但是每一批都使用train数据进行训练if step%100==0:print("train cost",cost)
神经网络训练完之后的tests ```python print(“\n testing—————-“) cost = model.evaluate(x_test,y_test,batch_size=40)#由于test_data一共只有40个
所以要将数据每40个分一批进行测试
print(‘test cost’,cost)
w,b=model.layers[0].get_weights() print(“Weight”=,w,”\nbiases:”,b)
6. 进行可视化```pythony_pred = model.predict(x_test)#利用训练完成之后的模型计算出作用完之后的y_predplt.scatter(x_test,y_test)#在matplot画布上点出各个测试点plt.plot(x_test,y_pred)#根据测试点和y_pred值做出相应的线性图像plt.show()
keras神经网络中的基本概念的理解
dense神经层
dense layer是我们经常提到和使用到的全连接层,dense实现的操作为:output = activation(dot(input, kernel) + bias) 其中 activation 是按逐个元素计算的激活函数,kernel 是由网络层创建的权值矩阵,以及 bias 是其创建的偏置向量 (只在 use_bias=True 时才有用)。
最终结果的展示
matplot中的随机点的图像
train cost和test cost的最终结果的输出
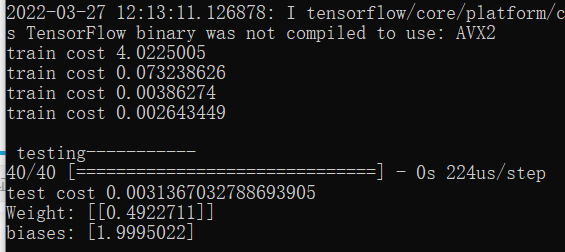
可以明显看到train cost在经过几轮训练之后的值明显的减小
最终test cost的值也足够的小,weight值与biases值已经足够接近于在最初取数据时所添加的weight=0.5,biases=2,说明神经网络训练成功
最终test数值的计算与可视化
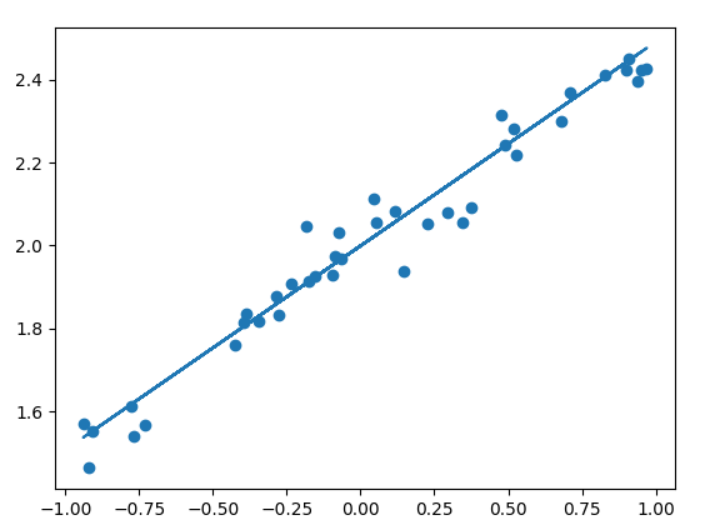
在实验的最终阶段,我们使用与train_data同一时间采用同一方式创建的test_data对模型的可靠程度进行进一步的验证,最终发现使用plt.plot(x_test,y_pred)创建的直线基本可以概括使用plt.scatter(x_test,y_test)方式创建的散点图的基本走势,说明试验成功,所训练出来的神经网络模型具有一定的可靠性。

若有收获,就点个赞吧
0 人点赞
