网页一般是由HTML文件和css文件共同渲染组成的,我们在网络爬虫爬取网页信息的时候通常爬取的是网页中的html文件
正则表达式
正则就是用一些具有特殊意义的符号组合在一起,来描述字符或者字符串的方法,或者,正则就是用来描述一类事物的规则
常用到的函数有findall,search等
关于正则表达式的更多知识可以参考正则表达式—菜鸟教程
beautiful soup的安装
pip install beautifulsoup4
练习:百度百科的爬取
模块的导入
import refrom bs4 import BeautifulSoupimport randomfrom urllib.request import urlopen
base_url = 'https://baike.baidu.com'his = ['/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/5162711']url = base_url+his[-1]
爬取和输出
html = urlopen(url).read().decode('utf-8')soup = BeautifulSoup(html,features='lxml')print(soup.find('h1').get_text(),'\t url':his[-1])sub_urls = soup.find_all('a',{'target':'_blank'})
循环多次的爬取
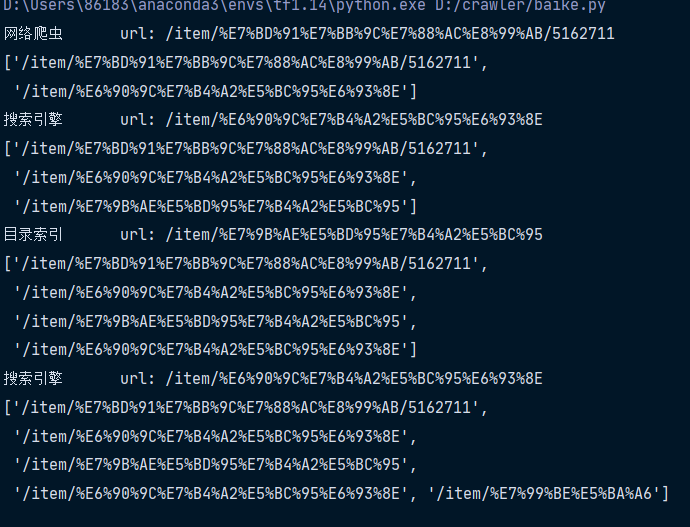
import refrom bs4 import BeautifulSoupimport randomfrom urllib.request import urlopen##导入模块base_url = 'https://baike.baidu.com'his = ['/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/5162711']##定义第一层爬取时的网址for i in range(20):url = base_url+his[-1]html = urlopen(url).read().decode('utf-8')#获取html文件的utf-8的文本形式soup = BeautifulSoup(html,features='html.parser')#BeautifulSoup函数处理,得到相应的返回值print(soup.find('h1').get_text(),'\t url:',his[-1])#返回得到的内容和对应的网址sub_urls = soup.find_all('a',{'target':'_blank','href':re.compile('/item/(%.{2})+$')})#上述的正则表达式中的%是中文字符转为utf-8的编码形式的时候出现的%‘.’表示出现空白字符以外的任意字符,#‘{2}+’表示前面所述的字符出现两次及以上$表示结束符,其中的括号表示要获取的字符字段。# print(sub_urls,type(sub_urls),sub_urls.shape())# print(sub_urls)if len(sub_urls) !=0:his.append(random.sample(sub_urls,1)[0]['href'])#将sub_urls的href的值append到原先的列表中else:#若没有爬取到有效的值his.pop()#默认删除最后一个元素print(his)
最终结果展示
request模块
网页在加载的时候会有若干种加载的形式,这几种形式即使打开网页的关键,最重要的类型就是get和post(也有其他的,比如head``delete)
最常使用到的就是**get**和**post**在95%的时间里都是在使用post和get
post账号登陆 搜索内容 上传图片 上传文件 向服务器传输数据
get正常打开网页 不往服务器传数据
import requestsimport webbrowser#get获取信息# param={'wd':'罗育欣'}# r=requests.get('https://www.baidu.com/s',params=param)# print(r.url)# webbrowser.open(r.url)#post提交信息data = {'firstname':'XC','lastname':'zhang'}r=requests.post('https://pythonscraping.com/pages/files/processing.php',data=data)# webbrowser.open(r.url)print(r.text)
- post形式返回的链接中不会有自己输入的信息
- get形式返回的链接中会出现自己刚才输入的信息
post提交照片
file={'uploadFile':open('imges/nomad.jpg','rb')}r = requests.post('https://pythonscraping.com/files/processing2.php',files=file)print(r.text)
对于网页的连续状况的处理
网页处理连续的状况,相当于实现在浏览器中存储了一个cookie,使用cookie进行下一步的命令cookie的理解
Cookie是保存在客户端的纯文本文件,比如txt文件,所谓的客户端就是我们自己使用的电脑,当我们使用自己的电脑通过浏览器进行访问网页的时候,服务器就会生成一个证书并写入我们本地的电脑
session进行网站的连续操作
session = requests.session()payload = {'username':'zxc','password':'password'}r = session.post('https://pythonscraping.com/pages/cookies/welcome.php',payload)print(r.cookies.get_dict())r = session.get('https://pythonscraping.com/pages/cookies/profile.php')print(r.text)
该种方式个人感觉与神经网络的搭建有些相似,都是创建好一个模型之后进行连续的操作,

若有收获,就点个赞吧
0 人点赞
