- IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANNELS = 120, 160, 3
INPUT_SHAPE = (IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANNELS) - model = Sequential()
- model.add(Lambda(_lambda _x: (x / 102.83 - 1), input_shape=INPUT_SHAPE))
- model.add(Conv2D(24, (5, 5), activation=’elu’, strides=(2, 2)))
model.add(Conv2D(36, (5, 5), activation=’elu’, strides=(2, 2)))
model.add(Conv2D(48, (5, 5), activation=’elu’, strides=(2, 2))) - model.add(Conv2D(64, (3, 3), activation=’elu’))
model.add(Conv2D(64, (3, 3), activation=’elu’)) - model.add(Dropout(0.5))
- model.add(Flatten())
- model.add(Dense(250, activation=’elu’))
- model.add(Dense(5, activation=’softmax’))
- model.summary()
- model.load_weights(’models/model-008.h5’)
IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANNELS = 120, 160, 3
INPUT_SHAPE = (IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANNELS)
在该代码中,定义了三个全局变量,分别是IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANNELS ,前两个参数分别是图片的长和宽,分别代表长和宽上的像素的多少,第三个参数IMAGE_CHANNELS,可以是通道的意思,一般的彩色图片为RGB三通道图片三个通道的取值范围均为(0~255)。而对于灰度图,灰度图一般为单通道取值也是0~255。在解决一些问题的时候,我们可以将三通道彩色图利用opencv工具转化为单通道灰度图.
model = Sequential()
创建keras深度学习模型,之后调用model为深度学习模型添加神经网络层
model.add(Lambda(_lambda _x: (x / 102.83 - 1), input_shape=INPUT_SHAPE))
该句的含义为:为深度学习模型添加一个lambda层,该层的作用就是_lambda _x: (x / 102.83 - 1)_对于input_shape根据英文直译过来就可以理解这个参数的实际意义,就是输入数据的形状,在全局变量中我们已经定义过该形状为_120, 160, 3。
model.add(Conv2D(24, (5, 5), activation=’elu’, strides=(2, 2)))
model.add(Conv2D(36, (5, 5), activation=’elu’, strides=(2, 2)))
model.add(Conv2D(48, (5, 5), activation=’elu’, strides=(2, 2)))
这三句话的具体含义除了参数上的一些不同,基本一致,都是为了为深度学习模型添加卷积神经网络层,以第一个为例Conv2D表示为添加卷积神经网络层,
- 第一个参数为filters表示为卷积核的数量(关于卷积核的作用,详见
keras卷积神经网络(最常用于计算机图片识别)文档)多个卷积核以提升工作效率,同时在下一层生成第三维度的大小为filters 个数的数据。
- 第二个参数为每个卷积核(filter)的尺寸,括号中的两个5,表示其为一个5x5大小的卷积核,5表示像素(pixel)
- 第三个参数为激励函数(activation_function)一般的神经网络层都会有激励函数
激励函数的作用如下
为了解决不能使用线性方程解决的问题 _若没有激励函数,神经网络就只可以执行线性(lenear)的问题
_卷积神经网络推荐使用relu
循环神经网络推荐使用relu or tanh
激励函数的作用
让某一层的神经元激活起来,将产生的信息传递到后面的神经网络之中
输入值经过hiden layer1和hiden layer2进行处理
举个例子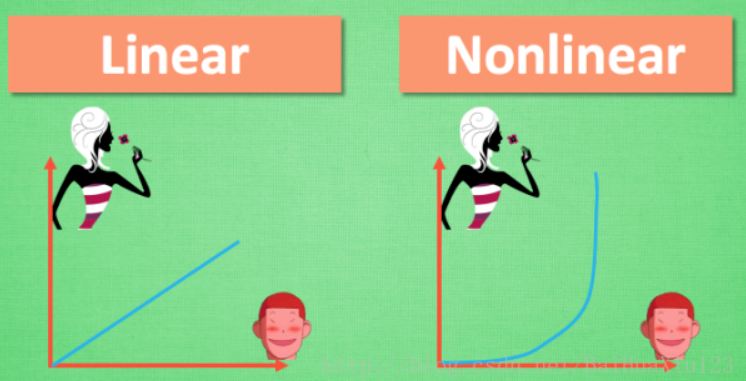
若没有激励函数,神经网路就只能处理左边的线性问题,而对于右边的非线性问题则束手无策,而在生活中我们的问题往往是非线性的。所以要借助激励函数。
上面提到我们在搭建卷积神经网络的时候,通常使用relu这个激励函数,而在本项目中我们使用的激励函数是elu这个激励函数。
elu激励函数与relu激励函数的对比 relu图像:
elu图像:
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。(参考csdn博客:https://blog.csdn.net/zfjBIT/article/details/91633424)
这部分对于激励函数的深层的理解不必过度深究,只需要知道我们在搭建卷积神经网络的时候经常会使用到elu函数和relu函数即可。
- 第四个参数为步长(strides)
该参数表示卷积核的每次扫描的跨越的长度,比如strides=(1,1)表示每次扫描x方向跨一个像素,y方向跨一个像素进行采点,strides=(2,2)表示每次扫描x方向跨两个像素,y方向跨两个像素进行采点,一般来讲,参数为strides=(2,2)的神经网络图片处理之后的输出值要比strides=(1,1)的神经网络层输出的图片的长和宽更小一些。
池化(pooling)是什么? 当参数为
strides=(2,2)的时候,直接卷积之后生成的结果可能会由于跨度的过大而丢失一些重要的信息。这时我们可以使用strides=(1,1)的参数之后通过添加池化层的方式来对上一层卷积层的输出结果进行采点抽离。 池化层会缩小传入值的长和宽,但是对于第三维度不会改变。 在池化层中也会有strides参数的出现,也是表示采点抽离的步长,可以跟卷积层进行类比理解。 大量实验证明使用池化的方式进行采点抽离的方式相较于直接使用卷积层进行采点抽离的方式会保留更多的图片的关键信息。模型的训练更加有效。这里可能是我们的代码需要改进的地方 两种方式的对比
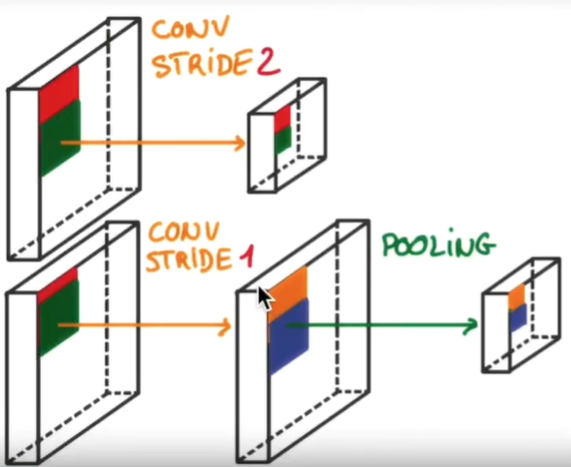
- padding参数
padding参数有两个值,一个是valid一个是same
一般来讲参数为same的输出的值的尺寸要比参数为valid输出的值的尺寸要大一些,
这里可以参考csdn博客:https://blog.csdn.net/syyyy712/article/details/80272071
博客中是以tensorflow来对padding进行讲解的,keras与tensorflow的原理基本一致,可以借鉴一下。
model.add(Conv2D(64, (3, 3), activation=’elu’))
model.add(Conv2D(64, (3, 3), activation=’elu’))
这两层的卷积神经网络层的设置与前三层基本一致,只是一些参数设置成为了默认值,其中strides=(1, 1),<br />padding='valid'多层的神经网络从图片处理中获得更多的信息,使得机器学习更加有效。
model.add(Dropout(0.5))
该层表示Dropout将在训练过程中每次更新参数时随机断开一定百分比(p)的输入神经元连接,防止overfitting情况的发生。
overfitting 问题的产生 过拟合 = 过度自信 = 自负 Overfitting 也被称为过度学习,过度拟合。 它是机器学习中常见的问题。 举个Classification(分类)的例子。
该张图片中的黑色的线才是我们最终想要的结果,但是由于机器学习的过度精确,使得机器过度自信,产生了过拟合的现象,对于这种现象我们常常采用Dropout的方式解决 Dropout方式 Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。 Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。如图:
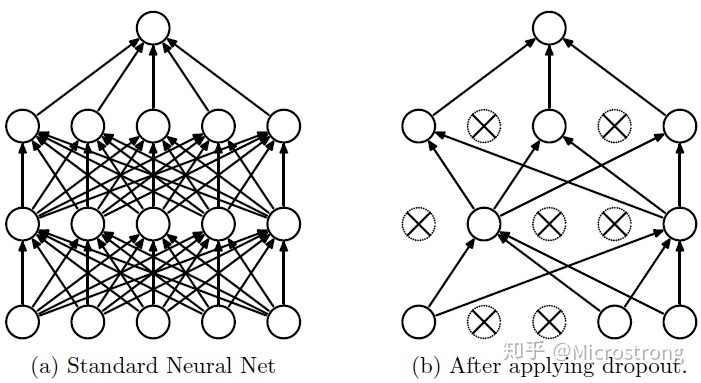
在本次实验中我们随机断开50%的神经元的连接,是模型的泛化性更强,不会太依赖于某些局部特征。
model.add(Flatten())
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
model.add(Dense(250, activation=’elu’))
该层神经网络是一个普通的全连接神经网络(full connected)
全连接层的作用:Output=activation(dot(input,kernel)+bias)
- activation 是按逐个元素计算的激活函数
- kernel 是由网络层创建的权值矩阵
- bias 是其创建的偏置向量 (只在use_bias 为 True 时才有用)
- 第一个参数表示dense层的输出神经元或输出值维度的个数
units :代表该层的输出维度或神经元个数, units解释为神经元个数为了方便计算参数量,解释为输出维度为了方便计算维度
- 第二个参数表示dense层的激励函数的选择,本层中还是选择elu这个激励函数。
model.add(Dense(5, activation=’softmax’))
该层相较于上一层的参数变化就是激励函数的改变,softmax是机器学习进行classification时常用的激励函数。
softmax激励函数 softmax函数的名字可以分为soft和max两部分,其中soft是该函数的最大的特点 在通常的情况下,我们会使用numpy或者tensorflow模块来对数据求最大值,但是使用该方式的求法通常求得的是数据的hardmax,就是求出一组数据的客观意义上的最大值 但是在实际的生活工作问题中,我们常常面临的不是求简单的最大值,我们更加希望可以求出每个输出分类的概率值。
比如对于文本分类来说,一篇文章或多或少包含着各种主题信息,我们更期望得到文章对于每个可能的文本类别的概率值(置信度),可以简单理解成属于对应类别的可信度。所以此时用到了soft的概念,Softmax的含义就在于不再唯一的确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性。
model.summary()
该层用于输出每一层的处理结果,将每一层的关键的处理参数输出出来。
例: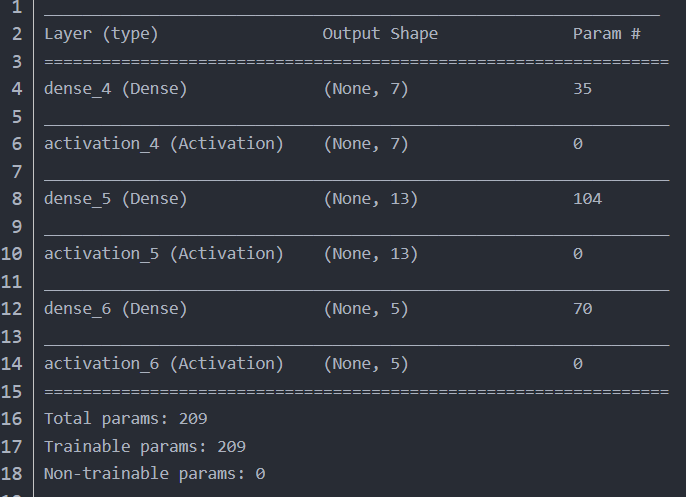
model.load_weights(’models/model-008.h5’)
h5文件
Hierarchical Data Format分层数据格式,二进制文件格式,表示多维数据集和图像的通用格式。
h5是HDF5文件格式的后缀。h5文件对于存储大量数据而言拥有极大的优势,使用h5文件来存储数据效率高。h5文件是一个将‘group’和‘dataset‘合起来的容器,group像是文件夹,dataset是具体数据,文件,文件夹下可以创建子文件夹,子文件下可以放文件。
model.load_weights函数的详解
model.load_weights(filepath, by_name=False): 从 HDF5 文件(由 save_weights 创建)中加载权重。默认情况下,模型的结构应该是不变的。 如果想将权重载入不同的模型(部分层相同), 设置 by_name=True 来载入那些名字相同的层的权重。
所以该句的意思为从’models/model-008.h5’文件路径下的文件中加载权重信息。

若有收获,就点个赞吧
0 人点赞
