设计
用 Redis 来存储缓存数据,用它的主要原因是,它提供了多种数据结构,并且在 Redis 中进行集合的交并集操作是一件很容易的事情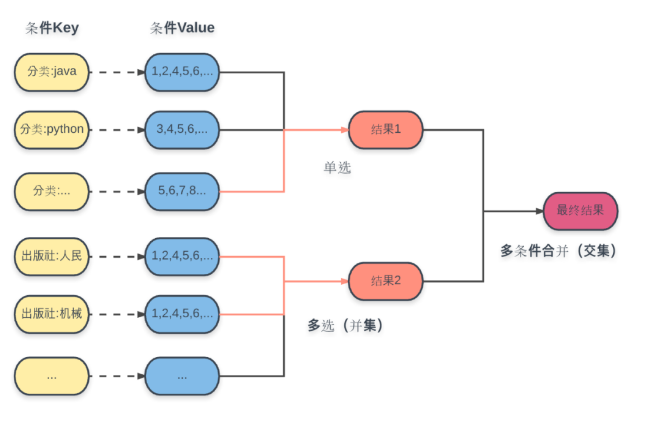
这里每个条件都事先将计算好的结果集 ID 存入对应的 Key 中,选用的数据结构是集合(Set)。
查询操作
- 子类单选:直接根据条件 Key,获取对应结果集。
- 子类多选:根据多个条件 Key,进行并集操作,获取对应结果集。
- 最终结果:将获取的所有子类结果集进行交集操作,得到最终结果。
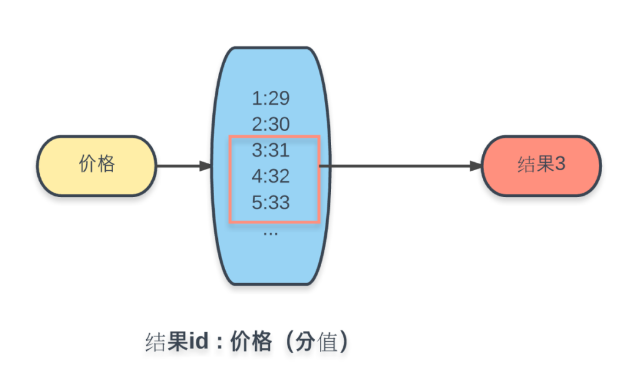
我们采用 Redis 的另一种数据结构进行实现,有序集合(Sorted Set)
这样在 Redis 的有序集合中就可以通过 ZRANGEBYSCORE 命令,根据分数(价格)区间,获取相应结果集。
将数据的查询与计算通过缓存的手段,进行了分离
扩展:
1、分页
这里你或许发现了一个严重的功能缺陷,列表查询怎么能没有分页。是的,我们马上来看 Redis 是如何实现分页的。
分页主要涉及排序,这里简单起见,就以创建时间为例。如图所示: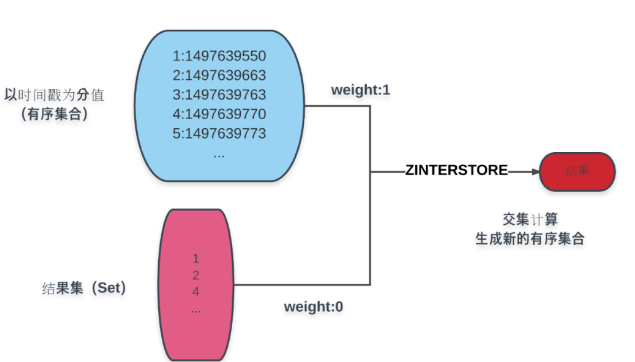
图中蓝色部分是以创建时间为分值的商品有序集合,蓝色下方的结果集即为条件计算而得的结果,通过 ZINTERSTORE 命令,赋结果集权重为 0,商品时间结果为 1,取交集而得的结果集赋予创建时间分值的新有序集合。
对新结果集的操作即能得到分页所需的各个数据:
- 页面总数为:ZCOUNT 命令。
- 当前页内容:ZRANGE 命令。
- 若以倒序排列:ZREVRANGE命令。
2、数据更新
关于索引数据更新的问题,有两种方式来进行。一种是通过商品数据的修改,来即时触发更新操作,一种是通过定时脚本来进行批量更新。
这里要注意的是,关于索引内容的更新,如果暴力的删除 Key,再重新设置 Key。
因为 Redis 中两个操作不会是原子性进行的,所以中间可能存在空白间隙,建议采用仅移除集合中失效元素,添加新元素的方式进行。
3、性能优化
Redis 是内存级操作,所以单次的查询会很快。但是如果我们的实现中会进行多次的 Redis 操作,Redis 的多次连接时间可能是不必要时间消耗。
通过使用 MULTI 命令,开启一个事务,将 Redis 的多次操作放在一个事务中,最后通过 EXEC 来进行原子性执行。
注意:这里所谓的事务,只是将多个操作在一次连接中执行,如果执行过程中遇到失败,是不会回滚的。

若有收获,就点个赞吧
0 人点赞
