本文主要内容
- 介绍存储字符的方式
- 介绍String,StringBuilder,StringBuffer三者间的区别
- String不可变性的实现方式
- 介绍 StringBuilder 以及 StringBuffer 字符串可变的实现方式
- StringBuffer线程安全的实现方式
字符存储方式
介绍
JDK9之前,String使用字符数组存储字符,字符集为unicode,编码方案使用的是UTF-16,可变长,2字节或者4字节。但是某些情况下,使用的字符码位不需要占用那么大的位宽,8位就足以。JDK9对其进行了优化,引入了新的编码方案,LATIN1,用1字节的位宽来表示部分字符,同时存储由char数组变为了byte数组。直接看一看源码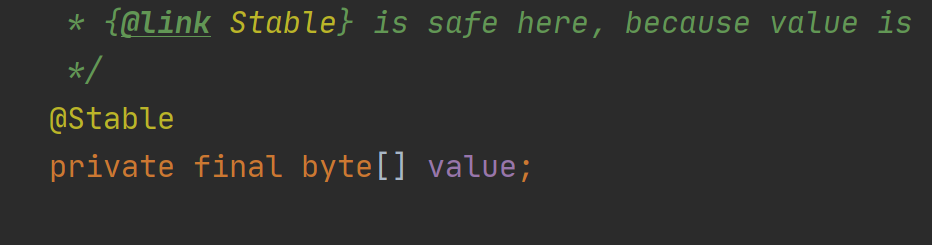
可以看到,变为了byte数组,那这里就有个疑问,使用byte数组进行保存时,如何获取字符串长度呢?可以看到这个,通过右移来进行判断



byte的默认值是0,默认使用的是LATIN1编码。直接使用length获取字符长度也存在着问题,因为utf16为变长字符,当需要标识4字节位宽的字符时length并无法显示正确长度。
字符集与编码方案
狭义来讲,字符集就是字符的集合,定义了字符的样子以及对应的编码,但是并没有确定编码对应的具体二进制编码。编码与二进制编码的映射映射公式由编码方案决定。常见的例子有 Unicode 与 UTF-8,UTF-16,UTF-32。
广义来讲,字符集不仅包含了字符的集合,字符对应的编码,还包含了编码方案,也就是不仅确定了字符的样子,对应的编码还确定了编码对应的二进制编码,比如 GB2312 ,ASCII
接下来看下 JDK9 用到的字符集与编码方案
LATIN1 与 UTF-16
ISO 8859-1,正式编号为ISO/IEC 8859-1:1998,又称Latin-1或“西欧语言”,是国际标准化组织内ISO/IEC 8859的第一个8位字符集。它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用附加符号的拉丁字母语言使用。曾推出过 ISO 8859-1:1987 版。 ISO-8859-1的别名有: iso-ir-100, csISOLatin1, latin1, l1, IBM819. Oracle数据库称WE8ISO8859P1。[1]
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为”storage format”)的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
LATIN1就不再过多介绍了,8位定长,平常使用也不会出什么问题。而 UTF-16 可变长表示,在日常使用中,比如 charAt(), length() 等方法,使用方式不当会出现一些bug。比如说这样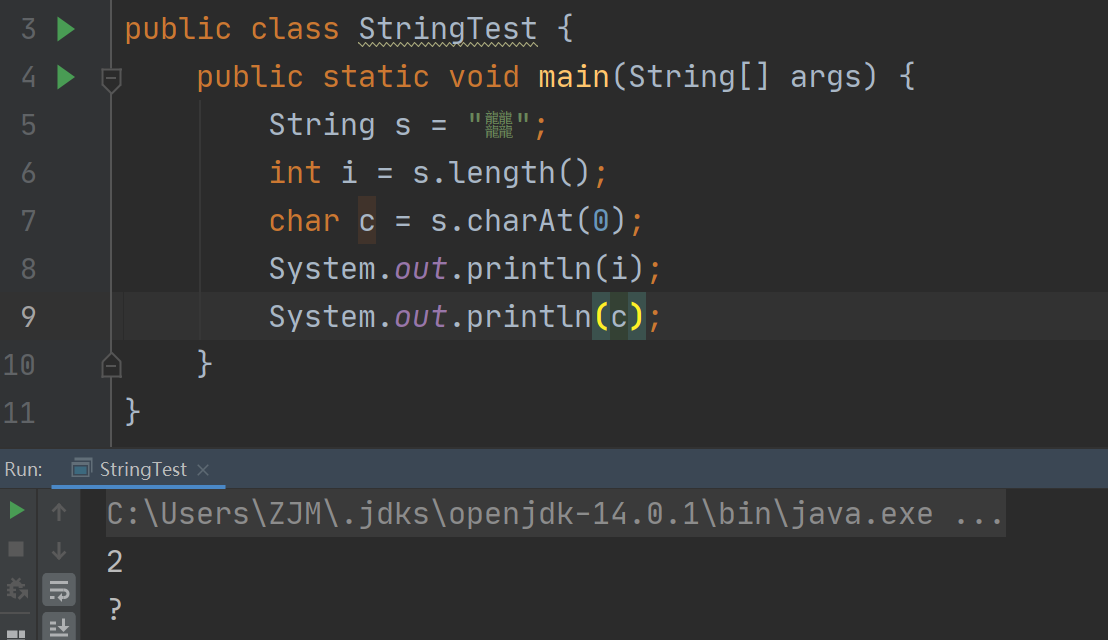
为什么会出现这个 bug 呢?这一切还得从 utf16的编码方式说起~
直接列出需要了解的知识好了,先看字符集 Unicode 中必须要了解的知识
- 码位:字符对应的数字形式
- 平面:Unicode的编码空间为 U+0000 ~ U+10FFFF,Unicode的编码空间被划分为了17个平面,每个平面包含 2^16 个码位,对应到存储上也就是每个平面两字节
- BMP:Basic Multilingual Plane,基本多语言平面。为第一个平面。范围显然就是 U+0000~U+FFFF,其中 U+D800~U+DFFF永久保留不映射到 Unicode 字符
- 辅助平面:其它平面
再看下编码方案 UTF-16
- 辅助平面的编码方式:使用 BMP 中的保留段(U+D800~U+DFFF)来管理辅助平面的编码,直接映射的话显然不够,为2048个,而辅助平面有1048576 个码位。而如果使用组合的方式,前1024与后1024组合,1024 X 1024 = 1048576,正好够,UTF-16就是使用这种方式,称为代理对。也就是0xD800 ~ (0x400 -1 + 0xD800) 与 (0x400 + 0xD800) ~ (0x400 + 0xD800 + 0x400 -1)
- 代理对
- 高位代理\前导代理:U+D800~U+DBFF
- 低位代理\后尾代理:U+DC00~U+DFFF
综上,可以通过判断码位是否在 U+D800~U+DFFF来判断这个字符是否是一个辅助平面的字符。如果是一个辅助平面字符,可以通过代理对的方式来表示,对应在 java 中就是长度为2的字符数组,并通过高位代理及低位代理对应的码位范围来确定字符在字符数组中的位置
至此,有了足以解决上述bug 的理论知识,来解决一下~
String的length方法是直接使用 byte数组的长度 >> coder()。这里的 coder 就是编码方案的不同,LATIN1为 8 位位宽,coder就为0,UTF16虽然是变长,但是默认为 16 位位宽,coder就是1。但是这里使用的是辅助平面的字符,所以为代理对,也就是占用两个 UTF16字符,所以长度为 2而不是 1
同样charAt方法也只是判断编码方式的不同, 对于代理对,只是把高位代理作为了码位进行展示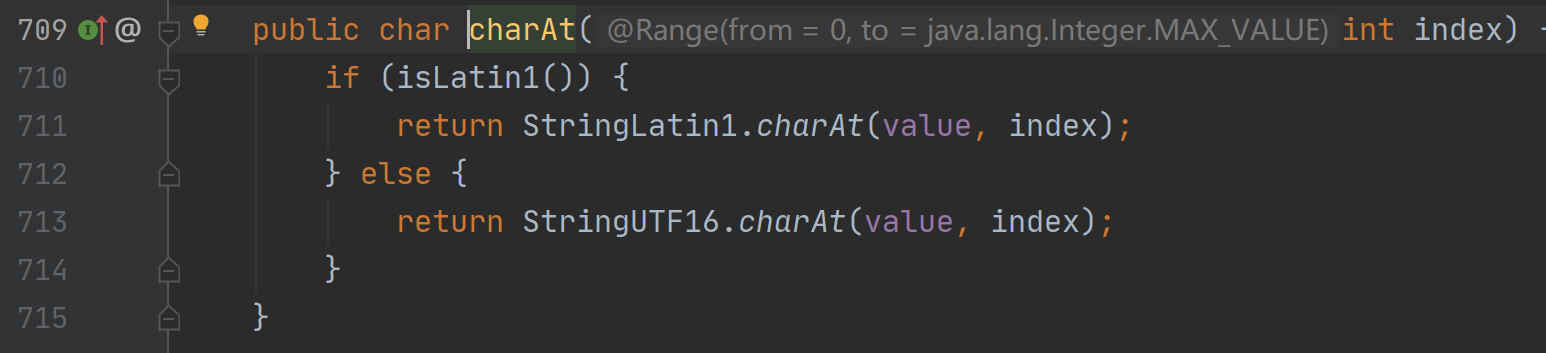
以上是出现bug的原因,接下来进行解决一下~,首先是长度问题,这个我们需要在判断编码方案后,如果是 UTF-16,就逐个码位判断是辅助平面中的还是BMP,这里可以通过那个BMP的保留段的范围来进行判断,并由一个变量来记录码元的数量。这里 JDK 中有实现,不需要再重复造轮子了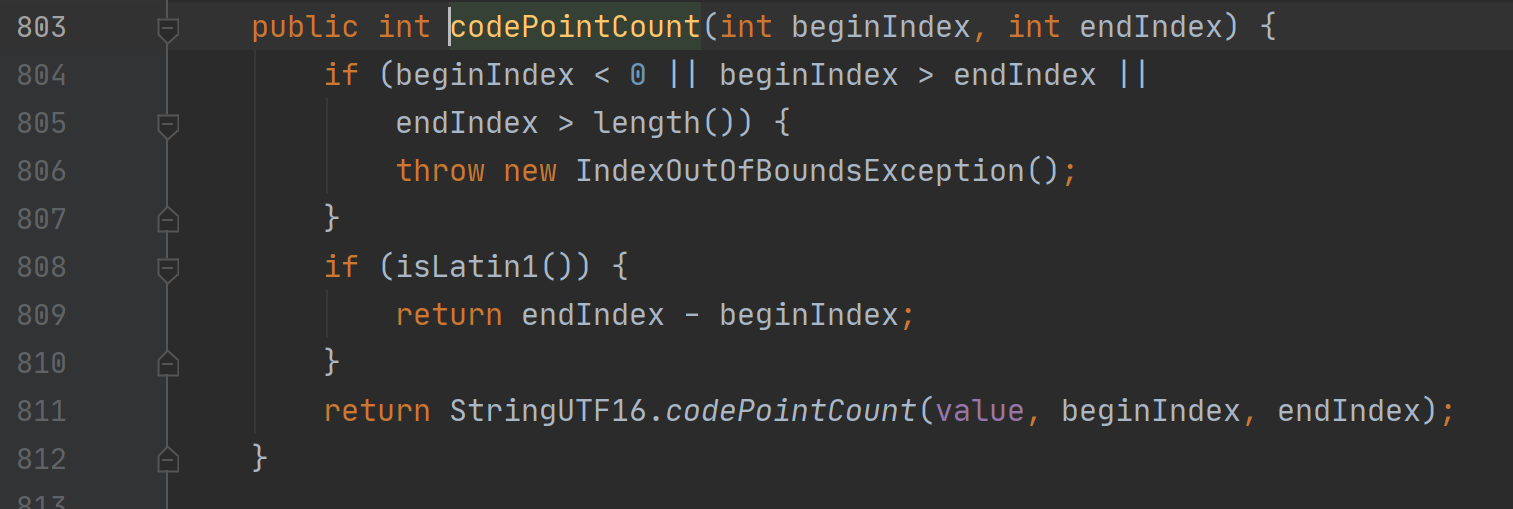

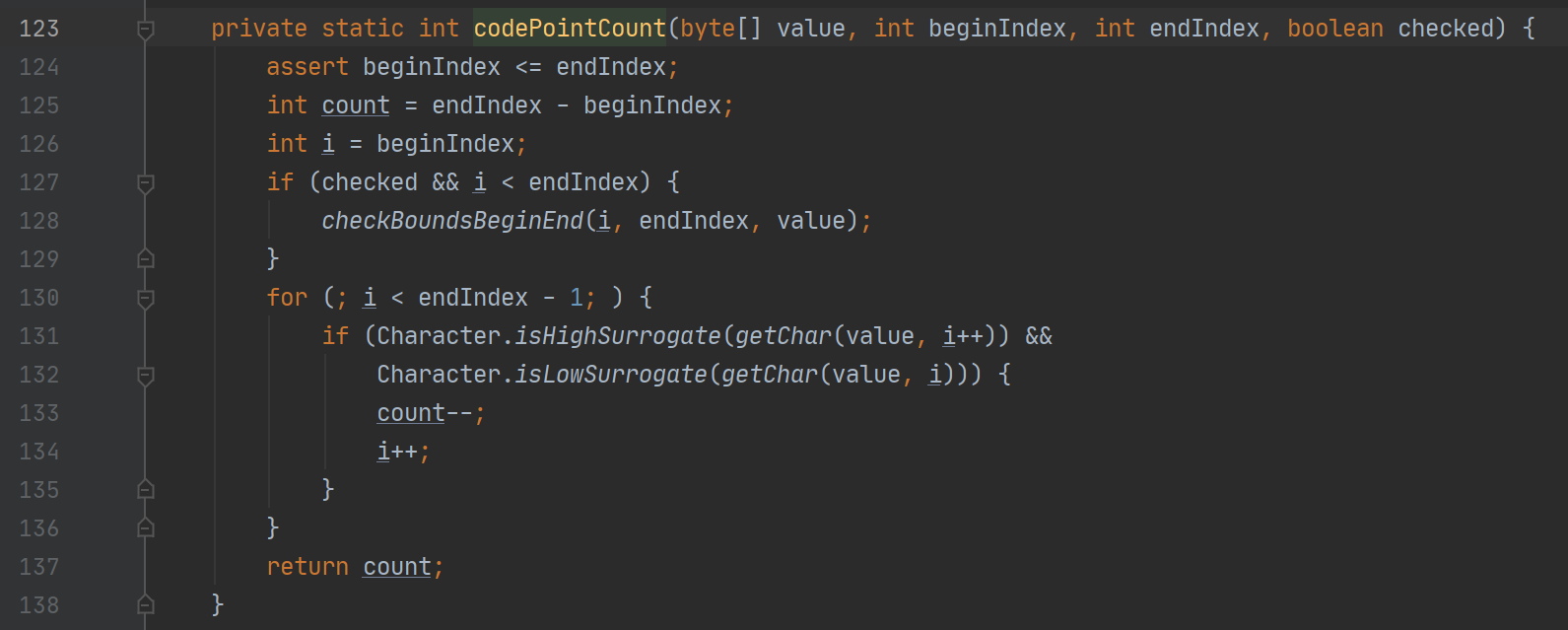
之后就是展示辅助平面中的码位,这里的思路上面已经提到,就是使用长度为2的字符数组进行保存,通过判断高位代理,低位代理的范围将码位放入合适的字符数组中的位置。这里也已经有实现 Character.toChars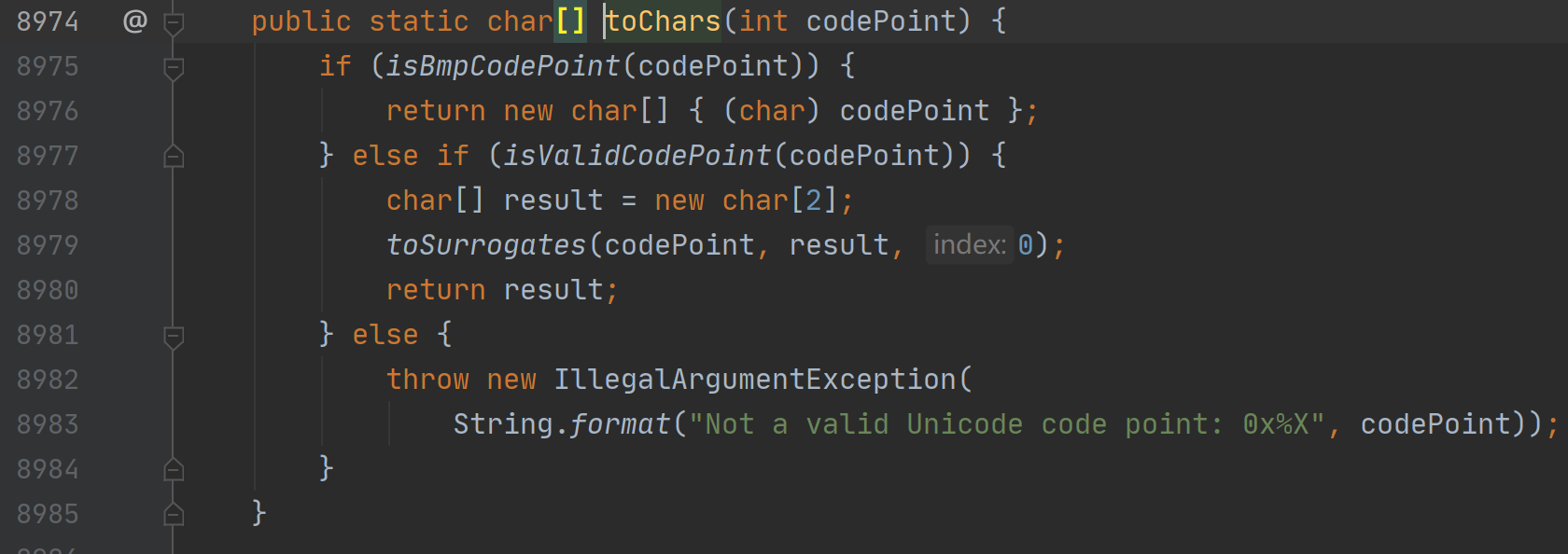
先判断是否是 BMP 中的码位,BMP中的就不需要转换了,直接输出就好,之后还要验证下 码位是否符合规范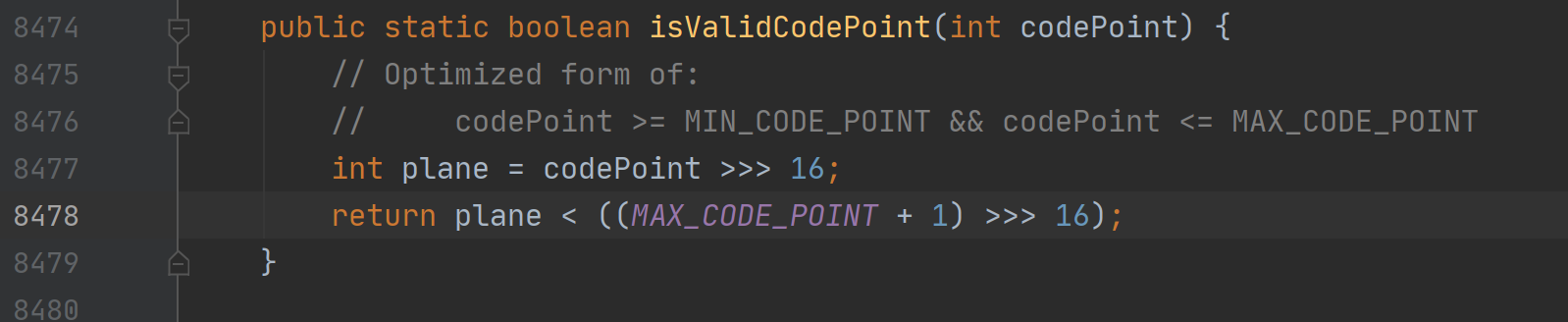
之后就是正题,存储辅助平面字符。根据高位代理与低位代理的范围放入合适的位置
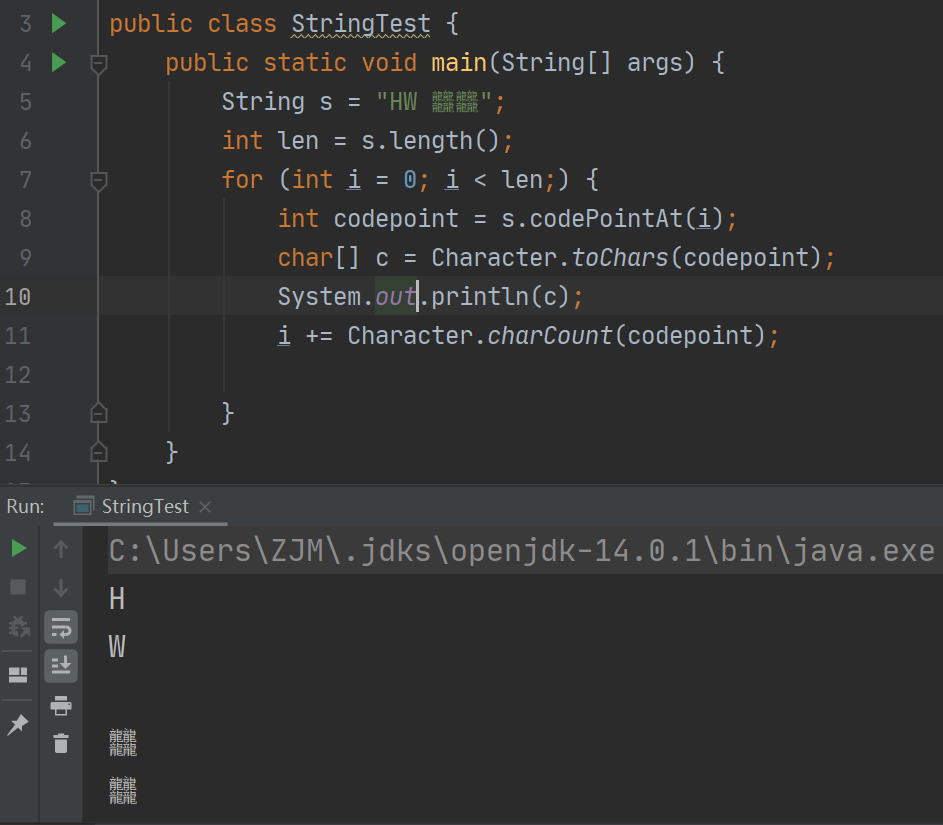
来一个代码,总结以上过程。就实现遍历字符串中的每一个字符的需求好了
public class StringTest {public static void main(String[] args) {String s = "HW 𪚥𪚥";int len = s.length();for (int i = 0; i < len;) {int codepoint = s.codePointAt(i);char[] c = Character.toChars(codepoint);System.out.println(c);i += Character.charCount(codepoint);}}}
三者区别
这个问题,一看就是老面试题了,直接开背
- String与StringBuilder,StringBuffer间的主要区别
- String类型的变量字符内容不可变,而StringBuffer,StringBuilder类型的变量,其字符内容可以改变
- StringBuffer与StringBuilder间的主要区别
- StringBuffer线程安全,StringBuilder线程不安全
那这些特性是如何实现的呢?请看下回分解~
String不可变性的实现方式
String 不可变,这里是指属性不可变,具体就是存储的字符不可变。实现的方式也很简单,就是给存储字符的数组加上 final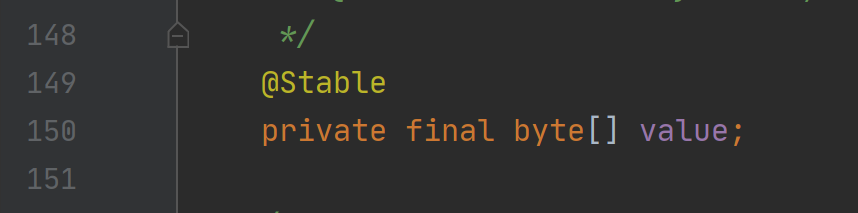
但是,这个属性的final 只是指向这个数组的地址不可变,至于这个数组中的内容,final是不起作用的。举个例子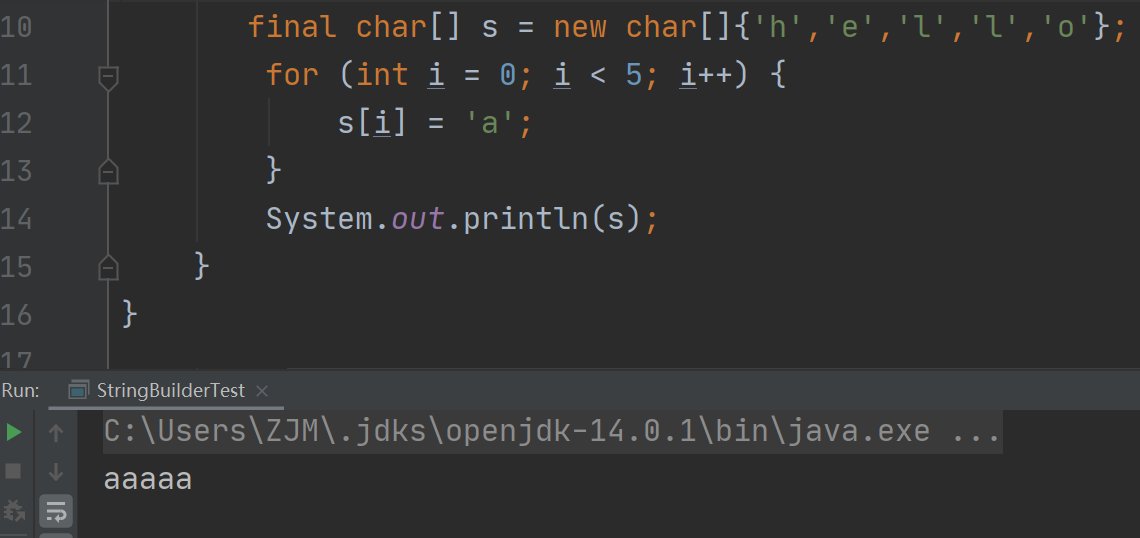
所以为了堵住这个漏洞,String类禁止继承,防止修改属性中的内容。
StringBuilder及StringBuffer可变字符串的实现方式
实现很简单,就是不使用 final 字符串来修饰 byte数组。这个属性和追加字符串的方法都由AbstractStringBuilder 进行封装
StringBuilder 以及 StringBuffer 直接继承使用就可以了


StringBuilder追加字符串的过程
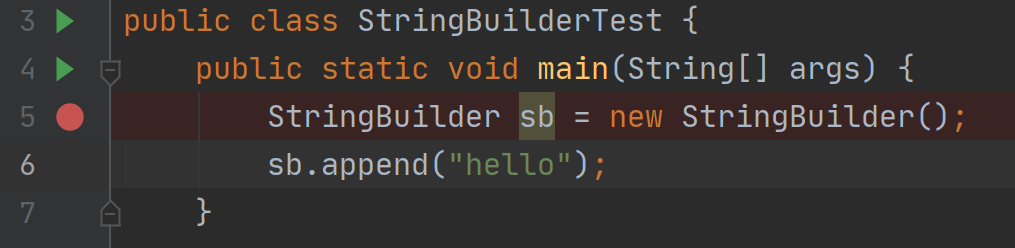
构造
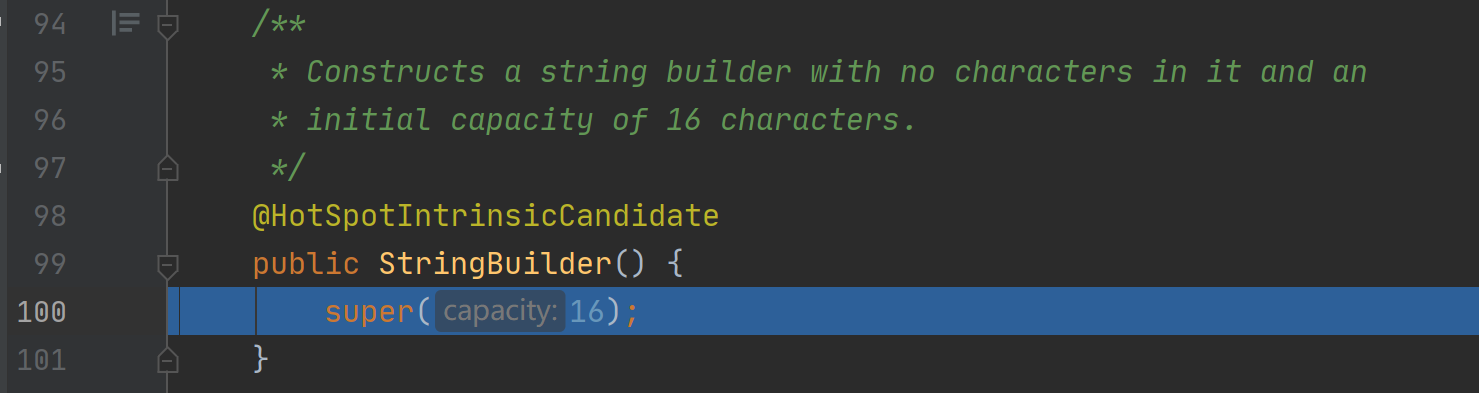
选择合适的编码方式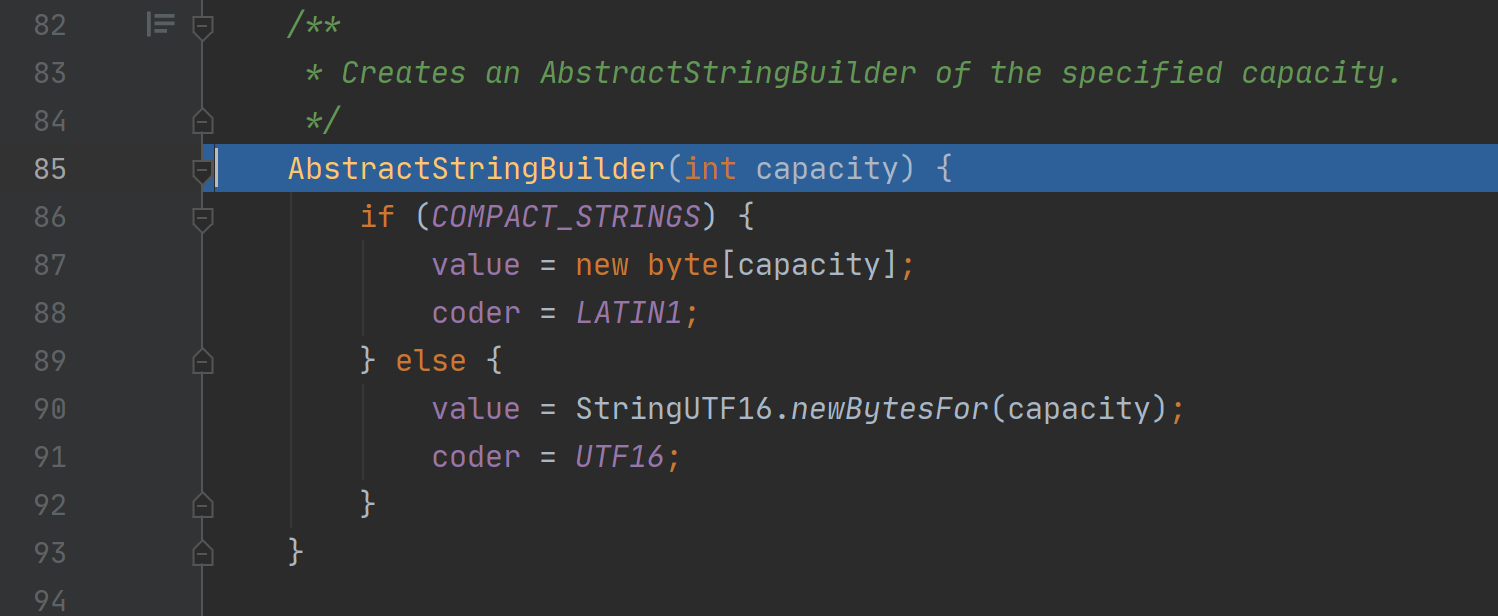
COMPACT_STRINGS默认为 true,也就是默认使用 LATIN1 编码。这里也可以设置 JVM 禁用字符串压缩来强制默认使用 UTF16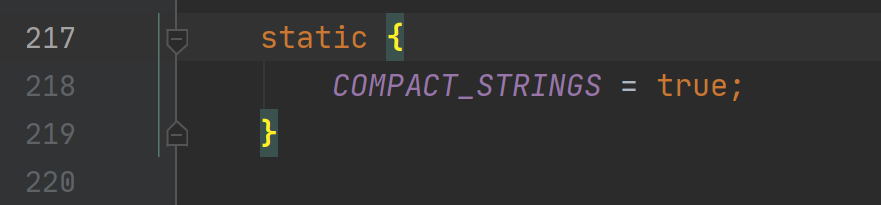
添加
调用AbstractStringBuilder.append
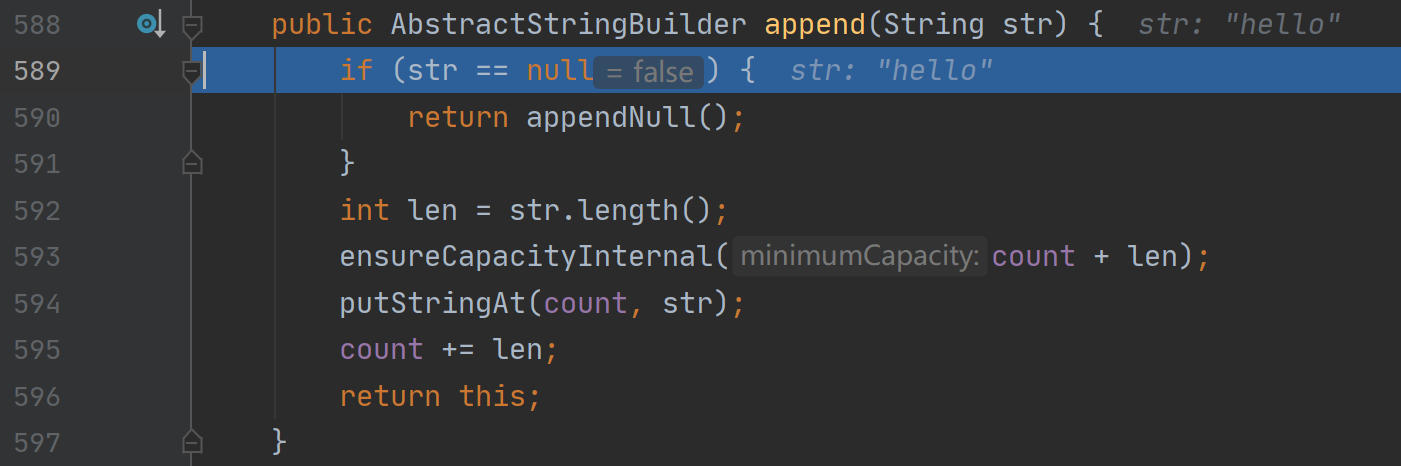
public AbstractStringBuilder append(String str) {//排除空指针if (str == null) {return appendNull();}int len = str.length();ensureCapacityInternal(count + len);putStringAt(count, str);count += len;return this;}
排除空指针

如果是空指针,则会添加”null”到当前字符串中,根据编码方式的不同,选择不同的添加方式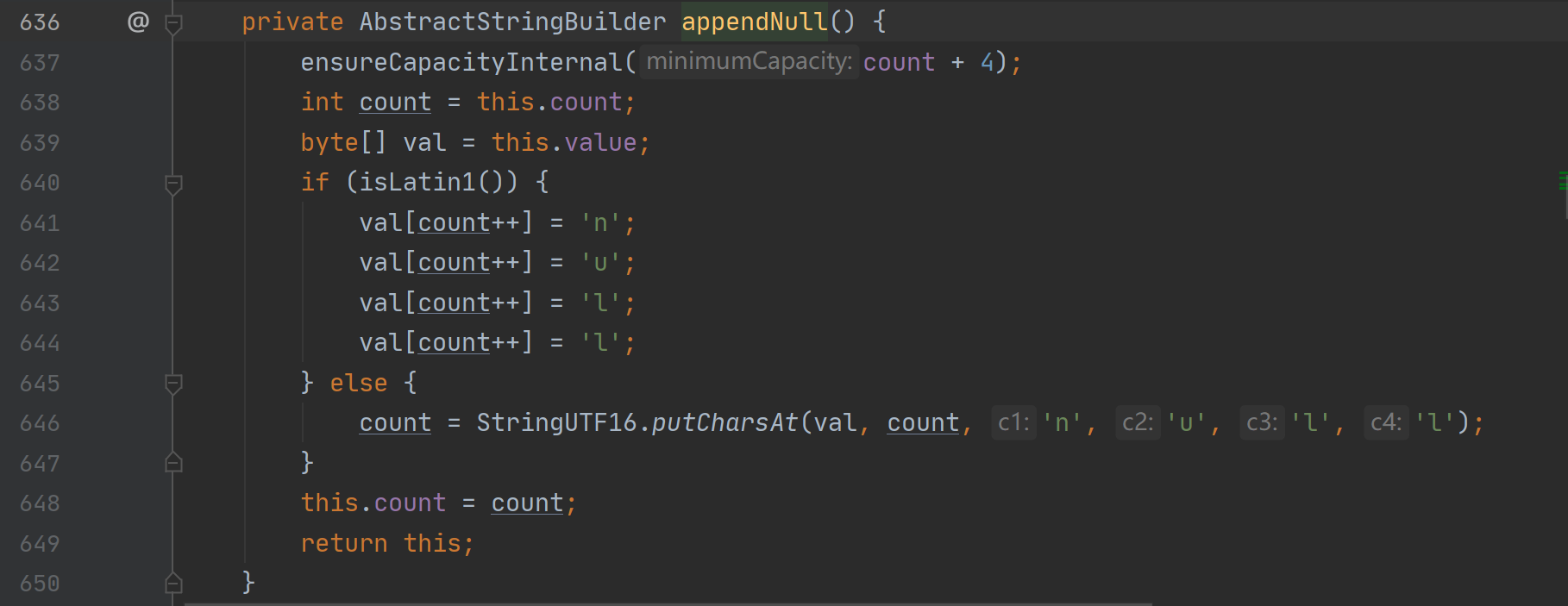
判断当前容量是否足够
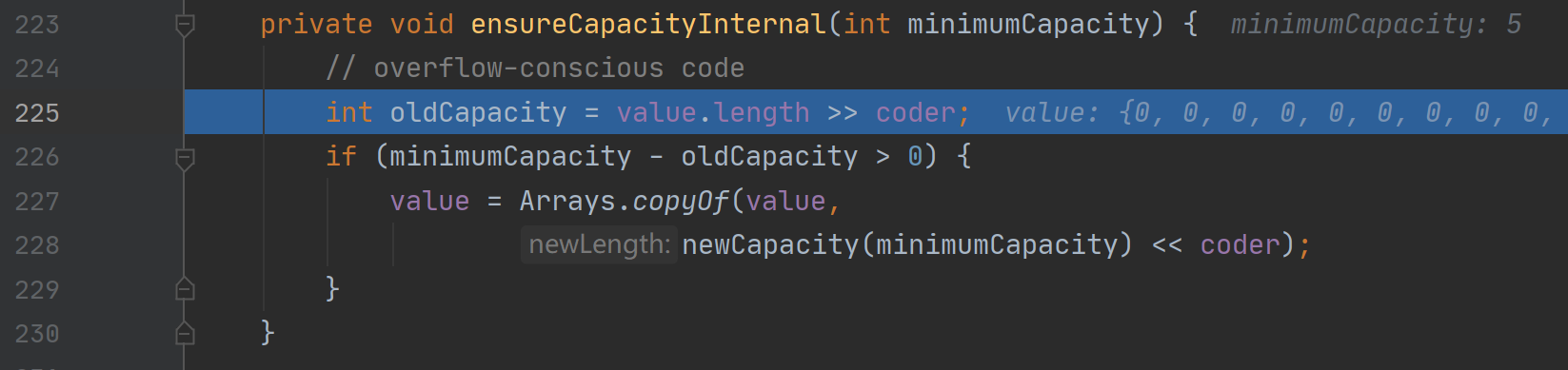
private void ensureCapacityInternal(int minimumCapacity) {// overflow-conscious code//获取当前编码下,容量所占字符长度int oldCapacity = value.length >> coder;//如果小于添加字符串后的字符长度,则进行扩容if (minimumCapacity - oldCapacity > 0) {//拷贝旧字符串内容到新字符串,容量大小为 minimumCapacityvalue = Arrays.copyOf(value,newCapacity(minimumCapacity) << coder);}}
添加字符串

private final void putStringAt(int index, String str) {//判断添加的字符串是否与当前字符串使用的是同一种编码方式if (getCoder() != str.coder()) {//进行编码转换inflate();}str.getBytes(value, index, coder);}
判断是否需要编码转换
如果当前字符串与要拼接的字符串 str 不是同一种编码方式,则进行编码转换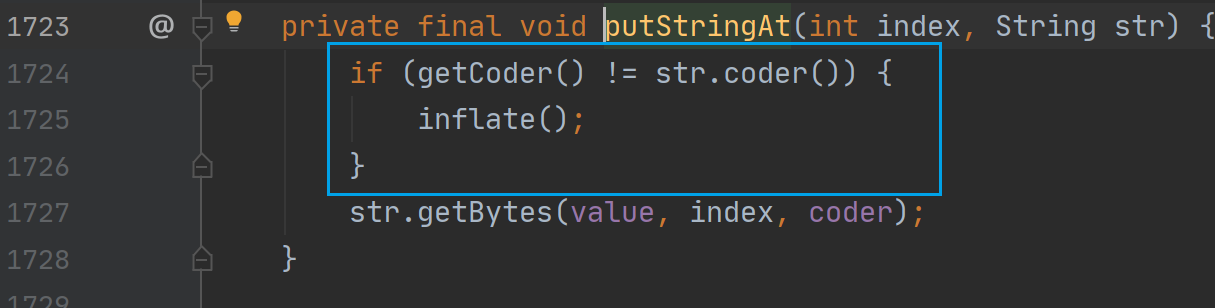
这里进行编码转换的情景是:当前字符串编码为 LATIN1 而要添加的字符串使用的编码方式是 UTF16。将当前字符串转为 UTF16编码方式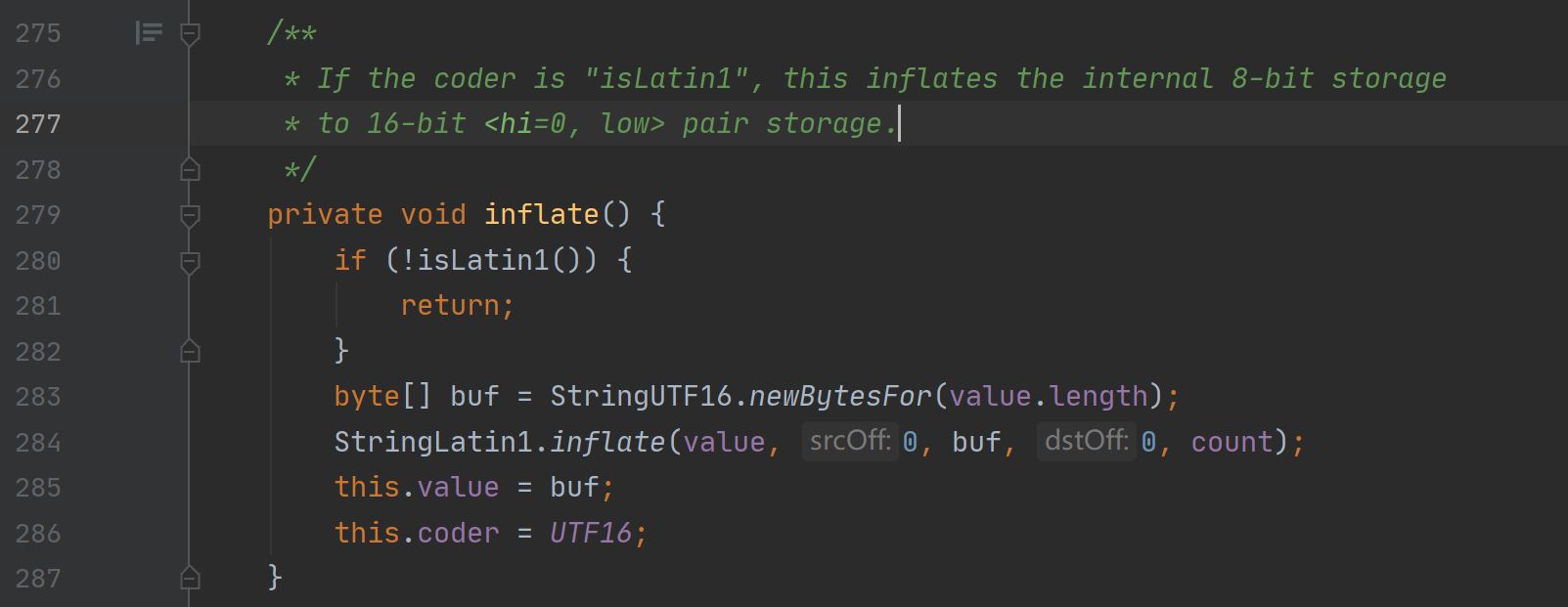
拼接
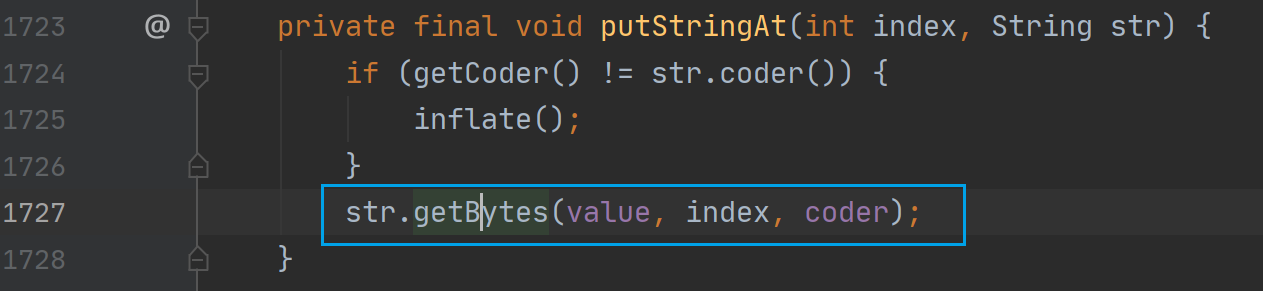
String.getBytes
传入的 dst[]为拼接前的字符串,dstBegin为拼接前的字符串的长度,coder为拼接前的字符串的编码方式。这里也会进行一次是否需要转换编码方式的判断。这里判断的情形是:未拼接的字符串编码方式为 UTF16 而要添加的字符串的编码方式为 LATIN1,将要天剑的字符串转发为 UTF16 添加到未拼接的字符串中,这里的转换和拼接是同步进行的
void getBytes(byte dst[], int dstBegin, byte coder) {//检查要增加的字符串与原字符串是否是同一个编码方式if (coder() == coder) {//从desBegin开始,将要拼接的字符串复制到 dstSystem.arraycopy(value, 0, dst, dstBegin << coder, value.length);} else { // this.coder == LATIN && coder == UTF16//进行编码转换StringLatin1.inflate(value, 0, dst, dstBegin, value.length);}}
更新当前字符串长度
因为是可变长,StringBuilder 用 count 来记录存储的数据长度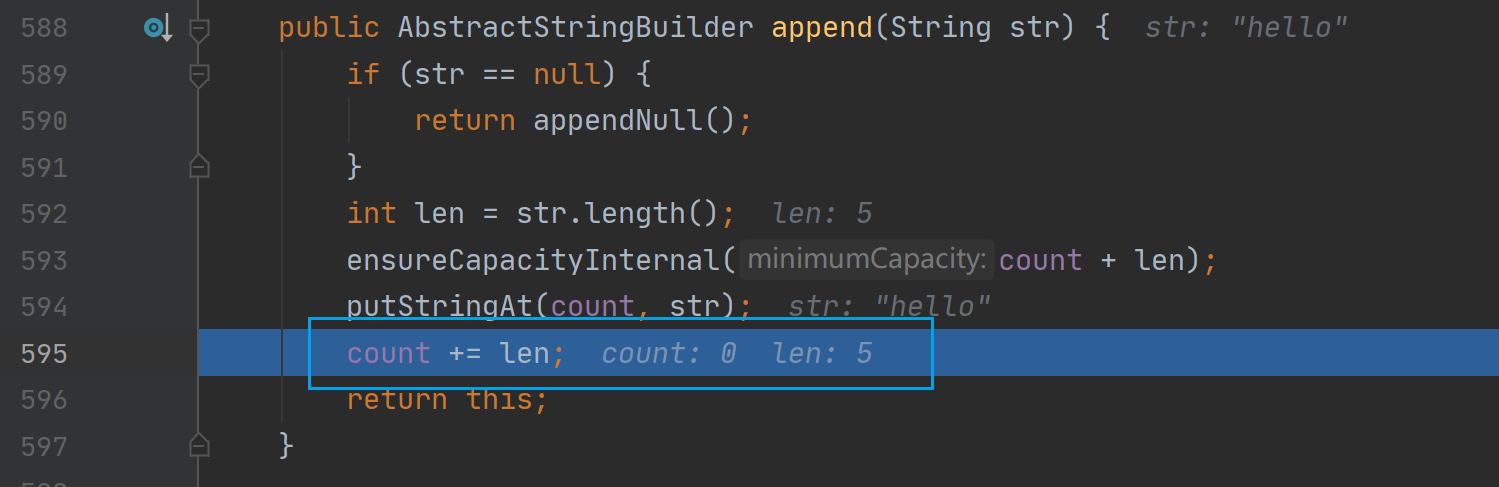
返回当前AbstractStringBuilder实例
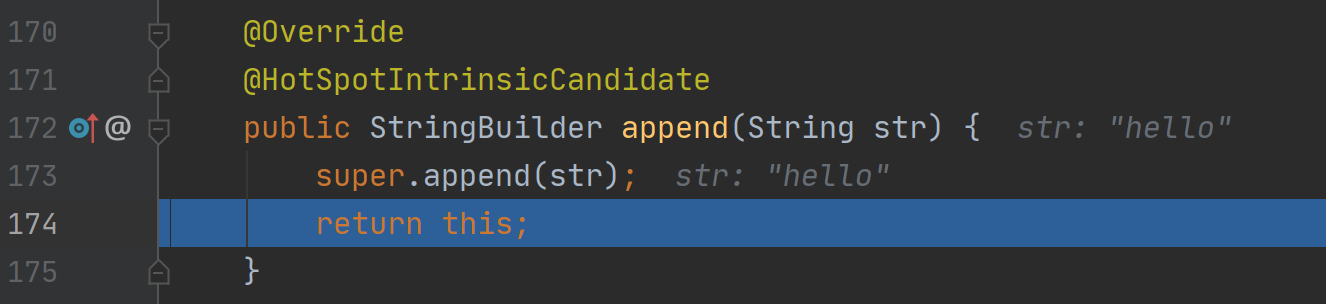
返回当前StringBuilder实例
StringBuffer线程安全的实现方式
实现方式就是用 synchronized 来修饰除构造器以外的所有方法,就像这个样子
参考

若有收获,就点个赞吧
0 人点赞
