前言
环境
-
本文主要内容
介绍HashMap实现映射的方式
- 介绍HashMap解决Hash冲突的方式
-
阅读建议
-
正文
如何实现映射?
源码
在向HashMap 中添加新元素时,肯定是要进行映射的,因此可以写一个添加新元素的 Demo,然后通过调试来观察下映射的过程 ```java package cn.zjm404.stu.java.hashmap;
import java.util.HashMap;
public class HashTest {
public static void main(String[] args) {
HashMap
开始调试~<br /><br />调用put后会跳转到putVal方法中。这里还要对 key 进行一些处理,注意,这里的 hash 方法并不是映射函数,而是进行了扰动<br /><br />以下为 hash 方法的内容,这里对key 的 hashcode 进行了一些处理,解决了 key 为 null时的特殊情况;让hashcode的高十六位与低十六位进行异或运算,既缩小了hashcode的范围减轻了之后映射位置时的计算压力,又使得低位有了高位的信息,让散列更松散,更均匀<br />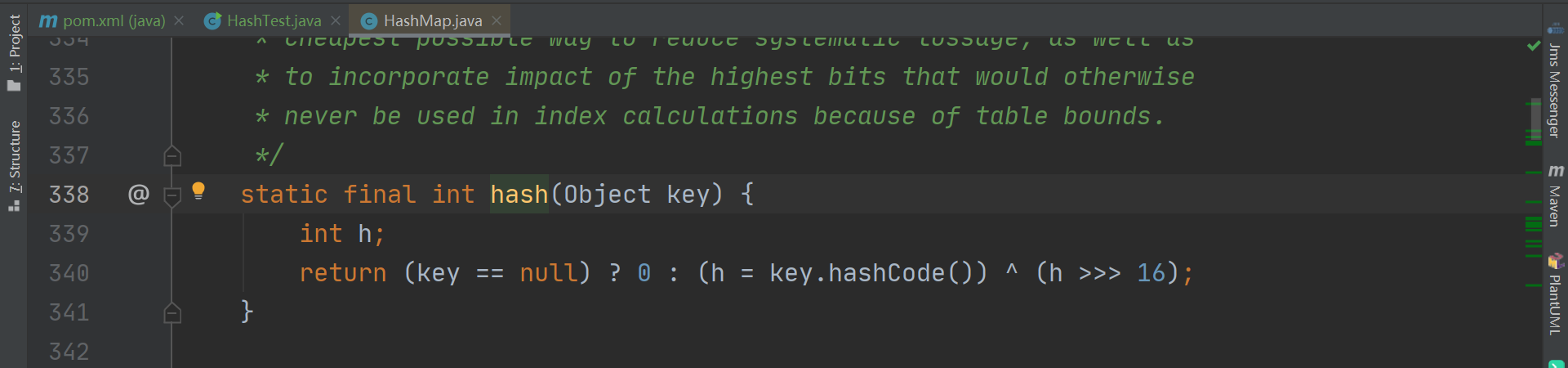<br />扰动后,进入putVal。这里红线圈起来的代码,是真正的映射方法,这里是用使用与运算来更快的完成取余操作,等价于 **hash值%桶长。**(注意这里的 n 必须为2的n次幂数才可以用 & 来实现取余,所以这也是桶长必须为2的n次幂数的原因之一。原理是,从二进制的角度,一个数除以2 相当于右移 n 位,因右移而消失的数就是余数,因此如果获取了被移走的那几位数,就获取了余数。举例来讲,7 / 2 就相当于 111 右移 1 位,为 11,转为十进制,3。获取被移走的数,就获得了余数,那么 111 & (2-1) 即是 111 & 1 = 1,余数为 1)<br />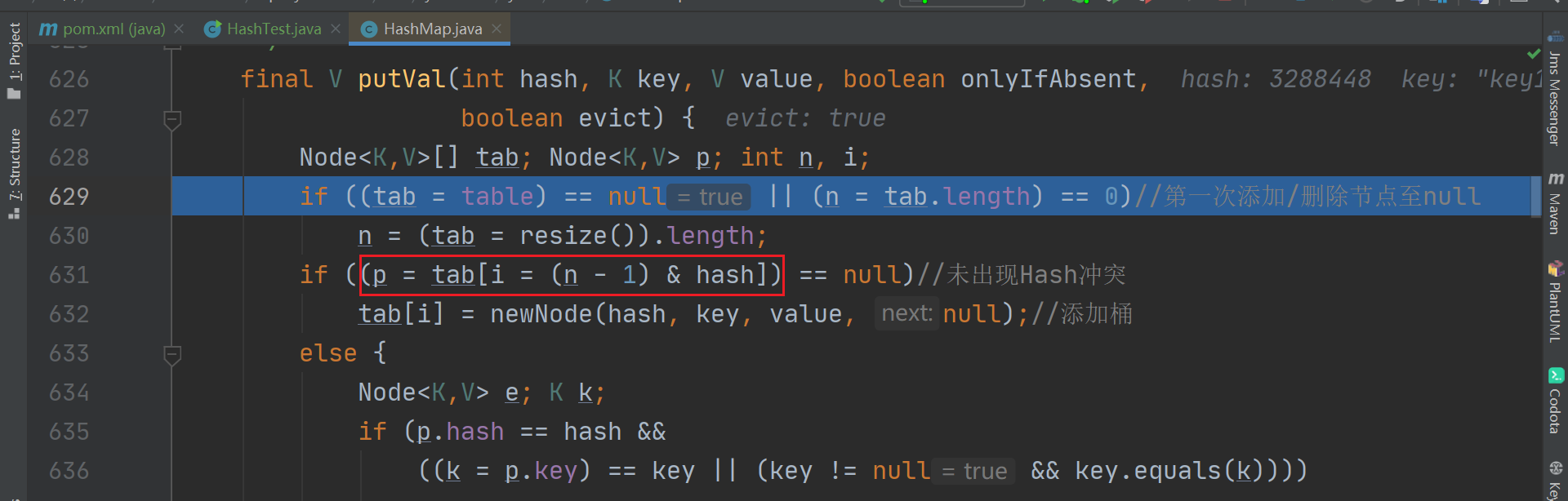<br />此外,由于 HashMap 使用拉链法解决 Hash 冲突,如果槽位已被占用,也就是可能存在链的情况下,还需要通过比较 key 值来确定位置<br />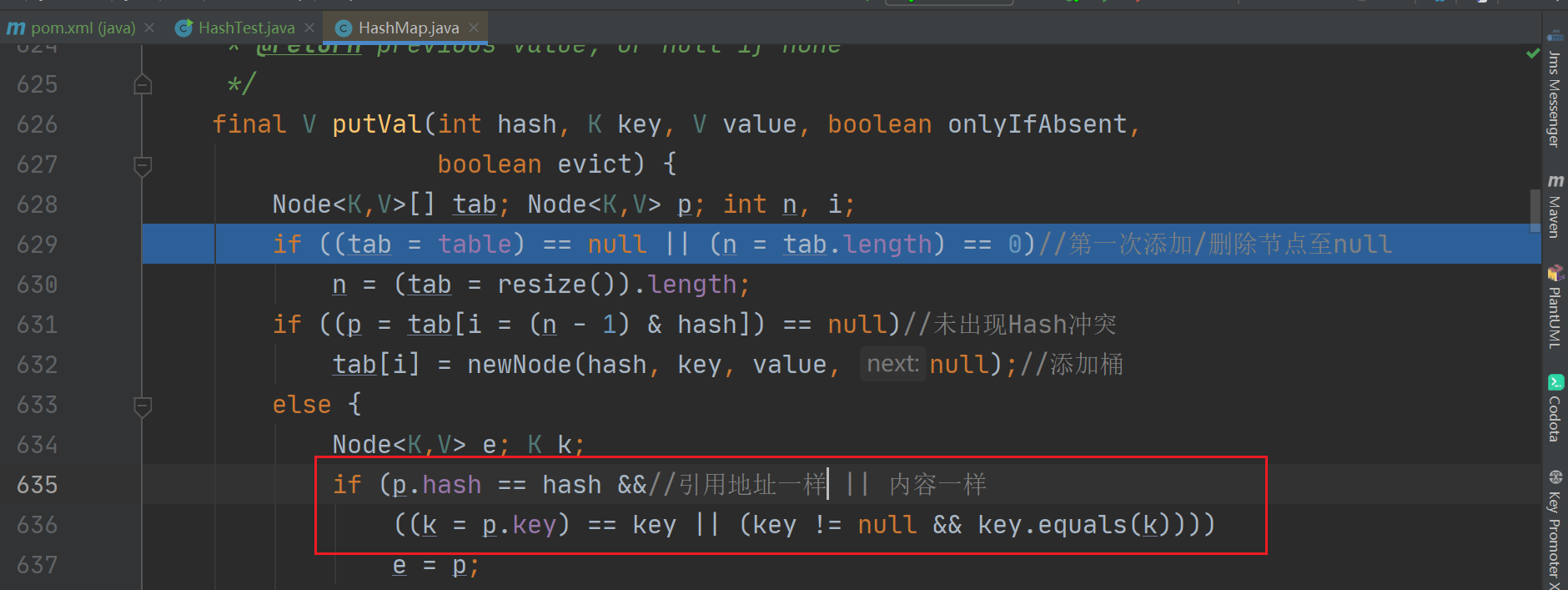<br />以上就是实现映射的相关源码<a name="WwLoj"></a>### 总结映射相关源码如下<br /><br /><br /><br />过程为:- 先对 hashcode 进行扰动,让 hashcode 的高十六位与低十六位进行异或运算,缩小 hashcode 范围,同时让低位拥有高位信息,使得散列更均匀- 使用 & 进行取余,通过 hashcode 与 桶长进行取余,获取元素在桶中的映射位置。如果该位置不为空,则桶中可能存在链,需要通过比较 key 值来确定在链中的位置<a name="cMShY"></a>## 如何解决Hash冲突?<a name="B4v0W"></a>### 源码可以顺着之前的插入源码继续,上面已说明,HashMap 是使用拉链法来解决 hash 冲突,但是在链表中查询元素时,时间复杂度为 O(n),因此,如果链表过长的话,就会严重影响 HashMap 的查询性能,因此,当链表长度 **>=** 阈值(这里的默认阈值为 8)时,会将链表转为红黑树,优化使其在发生哈希冲突时,查询时间复杂度无限接近于 O(logn)。减1是因为要算上加入的这个元素<br />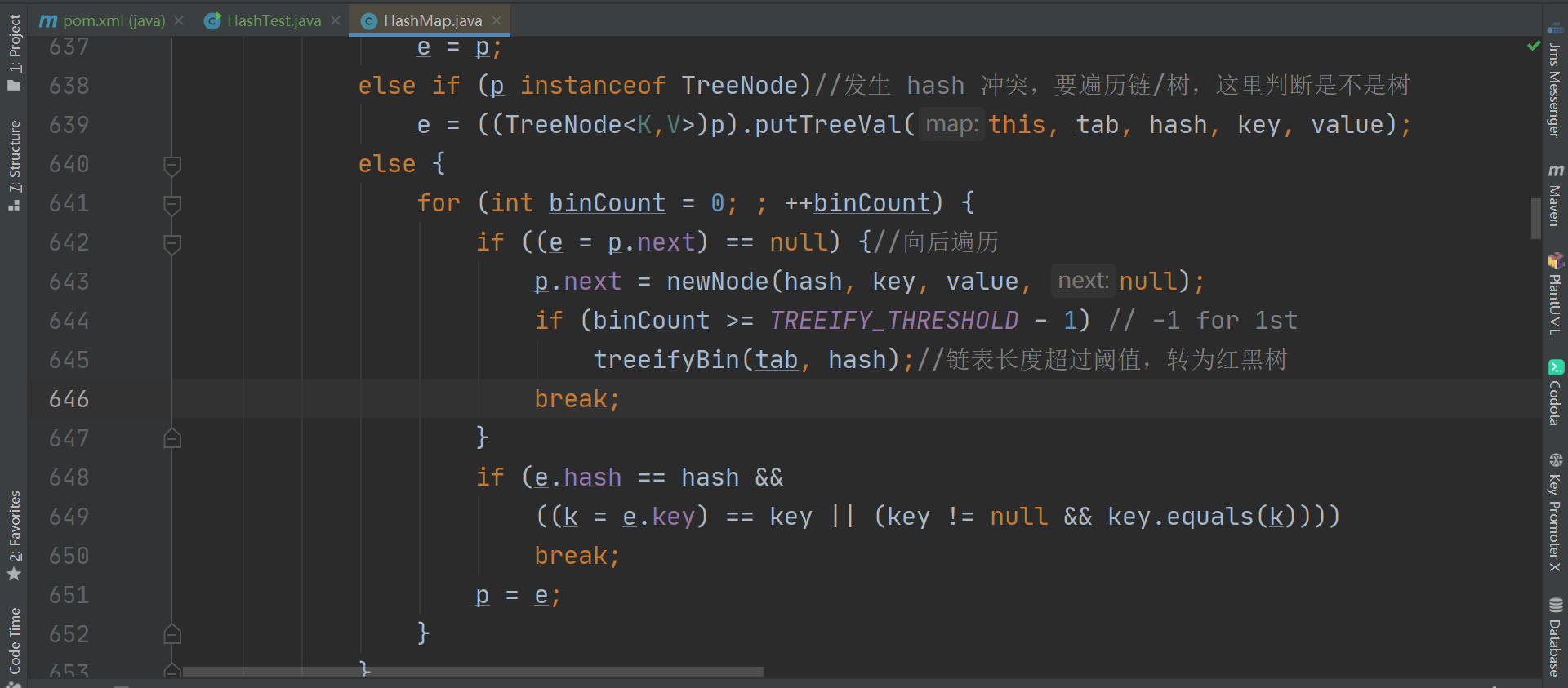<br />当树的节点数 **<=** 阈值(默认阈值为 6)时,会取消树化,转为链表。这一步发生在 split 方法中,而 resize 方法调用了 split ,也就是在扩容的时候,会检测红黑树的节点是否小于阈值,小于则进行转换<br /><a name="0cVP5"></a>### 总结- HashMap 使用拉链法解决 Hash 冲突- 当链表长度 >= 阈值(默认为 8)时,转为红黑树,而当红黑树的节点数 <= 阈值(默认为 6)时,转为链表<a name="zMxAt"></a>## 扩容后,如何实现rehash?当负载因子过大时(HashMap 的负载因子阈值为0.75,负载因子 = 所有节点数 / 桶长度),Hash冲突会剧增,为了减小 hash 冲突,就需要进行扩容(HashMap 是扩容为原来桶数的2倍),而当扩容后需要将旧桶中的值移动到新桶,这里就需要重新映射,也就是 rehash。rehash 有两种方式,一种是渐进式,redis 就是使用的这种方式,一种是一次性 rehash ,也就是一次完成, HashMap 使用的就是这种方式,但是 一次性 rehash时,无法进行其它操作,如果旧值太多,就会影响使用。HashMap 是如何解决一次性 rehash 速度慢的问题呢?前面提到,桶的长度必须为 2 的 n 次幂数,而进行映射的方式是 (桶长度 -1 )& hash 因此,当扩容为原来两倍时,只有两种情况- 未改变,还是原来的映射位置- 改变,新位置为 旧位置下标*2```javafinal Node<K,V>[] resize() {Node<K,V>[] oldTab = table;//保存旧节点int oldCap = (oldTab == null) ? 0 : oldTab.length;//记录旧桶数量int oldThr = threshold;//保存旧HashMap容量int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {//如果旧桶数量大于最大桶数量,则没办法扩容threshold = Integer.MAX_VALUE;return oldTab;}//新桶数量扩大为旧桶数量的两倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)//如果小于最大桶数量且大于默认桶数量newThr = oldThr << 1; // double threshold 新可用桶数量扩容为旧可用桶数量的两倍}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;//进行初始化else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;//实际可用的HashMap容量 = 容量 * 负载因子newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);//最大的实际可用容量为 Integer.MAX_VALUE}threshold = newThr;//更新容量为实际可用容量@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//设置桶数量为最大容量table = newTab;//更新为新 tabif (oldTab != null) {//如果旧HashMap中存在节点,进行转移for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)//如果没有"链”,只用将桶中的数据移入到新HashMap中就可以了newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)//桶中存在“链”,为 TreeNode则交由红黑树处理((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve order 为链表形式 扩容后,位置可能改变,因为是翻倍,也就是“加个1”,如果位置发生改变也就是原来位置*2。举例原来为11,扩容为111,原来hash值为1101,位置为1101&111 = 101,扩容后1101&1111新位置就是1101Node<K,V> loHead = null, loTail = null;//记录原位置不变Node<K,V> hiHead = null, hiTail = null;//记录原位置改变Node<K,V> next;do {next = e.next;//hash函数逻辑为 (oldCap-1)&e.hash。因此oldCap&e.hash==0则说明位置未改变if ((e.hash & oldCap) == 0) {//扩容后,hash值不变if (loTail == null)//链表头后无节点loHead = e;else//使用尾插法插入loTail.next = e;loTail = e;}else {//扩容后hash值改变,则新位置 = 原位置*2if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {//扩容后,hash值未改变,那么就还是原来的位置loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {//扩容后,hash值改变,则新位置为原位置*2hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}

若有收获,就点个赞吧
0 人点赞
