前言
本文主要内容:
操作系统基础
进程与线程的区别
在linux内核中,进程与线程都被视为任务,由链表结构进行表示与管理。如何区分线程与进程呢?该链表结构会记录当前线程id,主线程id,主线程地址。当主线程id等于当前线程id时,就表明当前是进程,所以,在内核中的存储结构这一方面,它们没有什么区别,主要区别在于资源占用方面。首先明确下它们的定位
进程:资源拥有的基本单位
线程:调度的基本单位
所以,可以认为进程是给多个线程提供资源的。看一下进程的虚拟内存结构
点击查看【processon】
用户空间是进程私有的,当进程切换时,用户空间中的信息需要保存,寄存器中保存的信息也要保存,而统一个进程中,不同线程切换时,只需要保存栈和寄存器中的信息,这资源占用是大大减少的
线程的实现方式
实现线程主要有3种方式:使用内核线程实现、使用用户线程实现和使用用户线程加轻量级进程混合实现 -深入理解java虚拟机
使用内核线程实现
进程线程都由同一种链表结构管理,存储在内核空间中,顶多是在用户空间中间中进行优化下,线程少占用些资源
程序一般通过轻量级进程(Light Weight Process,LWP)来使用KLT.LWP:KLT = 1:1
缺点:
- 代价较高。基于内核线程实现,线程的使用过程中,会频繁的在用户态和内核态间来回切换
- 线程数量较少。内核空间小,可以创建的线程数量不多
使用用户线程实现
完全建立在用户空间上的线程,就是将线程的管理表交由进程,在用户空间实现。好处很多,因为用户空间更大,内核空间:用户空间是1:3,可以创建更多的线程,二是因为线程不使用内核空间,因此当线程切换时,就不需要进行内核态与用户态之间的切换,更快,更节省资源。但是缺点也突出,因为是由一个内核线程或者称为进程,模拟出来的多个线程,所以在内核感知中,其实还是一个进程,也就是粒度太大,内核进行管理时,将这一大群线程,统一视为一个线程,如果进行阻塞的系统调用,那么这一个进程中的所有线程都要停止
点击查看【processon】
优点:
- 消耗资源较少
- 可创建线程数量较多
缺点:
- 所有线程的操作都需要程序自己完成
- 对于设计底层的功能(处理阻塞,处理线程映射到其它处理器),实现困难或不能实现
使用用户线程加轻量级进程混合实现
字面意思,就是以上两种方式的结合
用户线程数:轻量级进程数 = N:M
点击查看【processon】
java实现线程的方式
Java线程在JDK1.2之前,基于被称为“绿色线程”(Green Threads) 用户线程实现的,而在JDK1.2中,线程模型替换为基于操作系统原生线程模型来实现的
也就是说,在JDK1.2之前,使用的使用用户线程方案,在JDK1.2及以后,java实现线程的方式依赖操作系统,操作系统支持怎样的线程模型,java就是什么样的线程模型。如果操作系统支持多种方案,则可以通过设置jvm参数来选择实现线程的方案。例如在Solaris平台,操作系统支持一对一(通过Bound Threads 或 Alternate Libthread实现)及多对多(通过 LWP/Thread Based Synchronization 实现)
多对多:-XX: +UseLWPSynchronization (默认)
一对多:-XX: +UseBoundThreads
线程调度方式
主要方式有两种:
- 协同式线程调度(Cooperative Threads-Scheduling)
抢占式线程调度(Preemptive Threads-Scheduling)
协同式线程调度
线程执行时间由线程本身来控制,任务执行完后,通知系统切换线程
优点:实现简单
缺点:线程执行时间不可控制,容易造成阻塞抢占式线程调度
线程执行时间由系统来分配,线程的切换不由线程本身来决定。如果Java中的线程优先级能与运行的系统中的线程有限级相对应,则可以通过设置线程优先级来让线程被优先调度,从而尽可能的增加运行时间(当然,在编码实现中,所应用的锁应该是非公平锁才可以)
java线程优先级:1/Thread.MIN_PRIORITY、2、3、4、5/Thread.NORM_PRIORITY)、6、7、8、9、10/Thread.MAX_PRIORITY
提高线程优先级只是可能会被优先调用,还得考虑操作系统的因素
优点:线程执行时间可控,避免一个线程导致整个进程阻塞的问题Java线程状态及转换
状态
网上有说五种的,有说六种的,还有七种,具体的说法也很多,这里就以 openjdk 14源码为准好了。
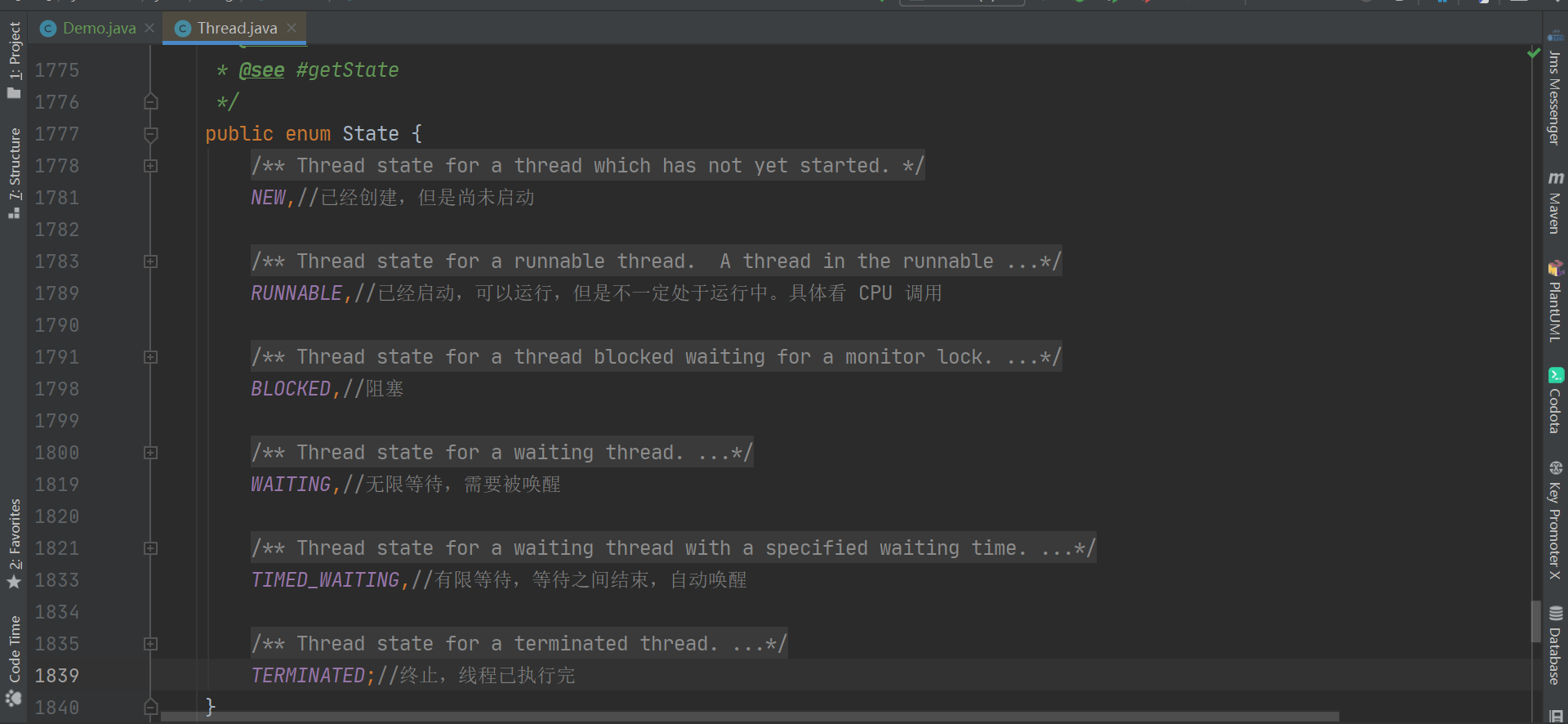
NEW:创建后未使用
- RUNNABLE:此时可能正在运行,也可能在等待被调度
- BLOCKED:阻塞,等待获取互斥锁
- WAITING:需要被显式唤醒
- TIMED_WAITING:无需被显式唤醒,在约定时间过后会自动唤醒
-
转换
这里也以 openjdk 14 的源码为准,注释写得蛮清楚的。注释中没有记载的,我会进行注明
NEW -> RUNNABLE
(注释中未说明)
**
这里注释并未说明如何转换,我觉得应该是调用 start() 方法后,进入 RUNNABLE 状态BLOCKED <-> RUNNABLE
注释中的内容如下:

大概是说,在等待获取监视器锁时进入 synchroized 修饰的代码块或者方法中。这是 BLOCKED -> RUNNABLE。如何从 RUNNABLE -> BLOCKED,注释到没有说,不过可以猜想是获取监视器锁(monitor lock)后就转换为了 RUNNABLEWAITING <-> RUNNABLE
注释如下:
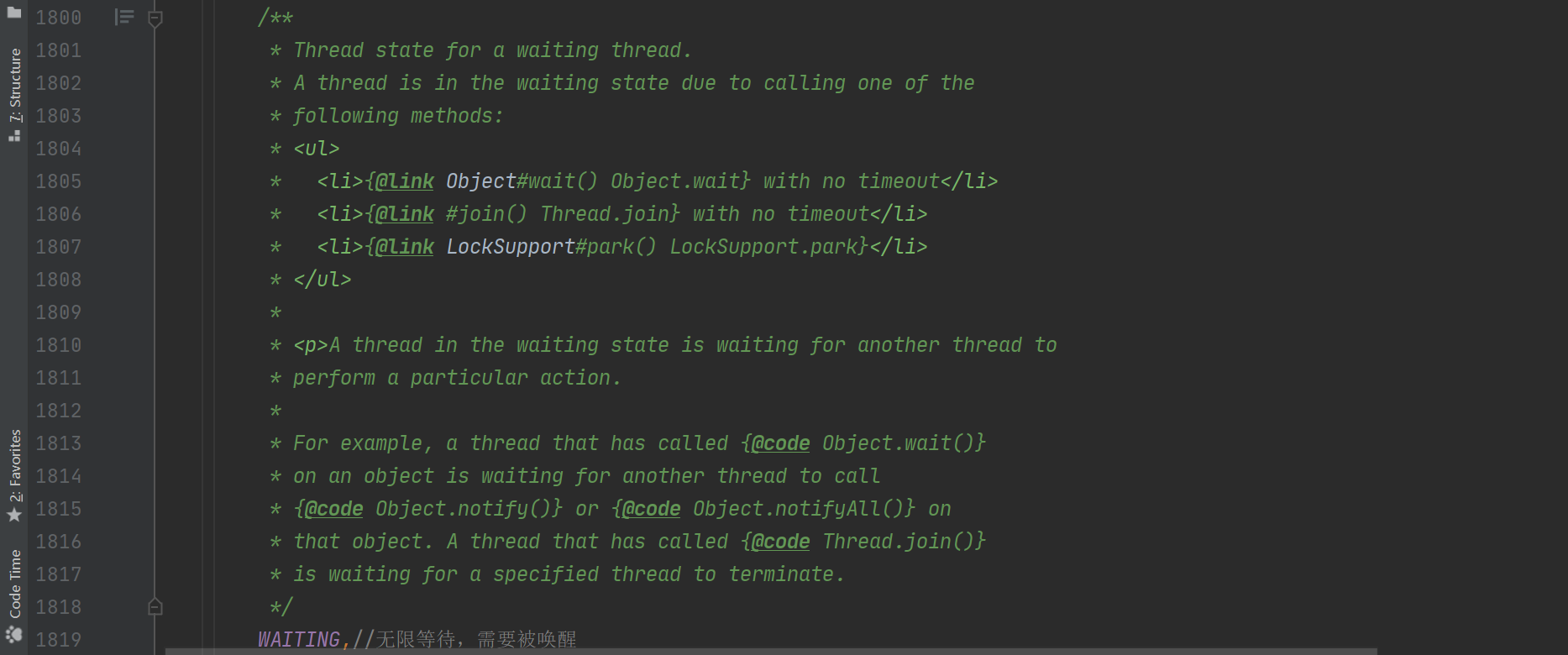
RUNNABLE -> WAITING 调用 Object.wait()方法
- 调用 Thread对象的 join() 方法
- 调用 LockSupport.park()
WAITING -> RUNNABLE
- 如果是因为调用 Object.wait() 转为了 WAITING,那么可以等待其其它线程调用 Object.notify() / Object.notifyAll() 进行唤醒
- 如果是因为调用 Thread对象的 join() 方法转为了 WAITING,那么就等待那个线程结束后才可以继续进行
如果是因为调用 LockSupport.part(),等待 LockSupport.unpart() 进行唤醒(注释中未写)
TIMED_WAITING <-> RUNNABLE
注释如下:
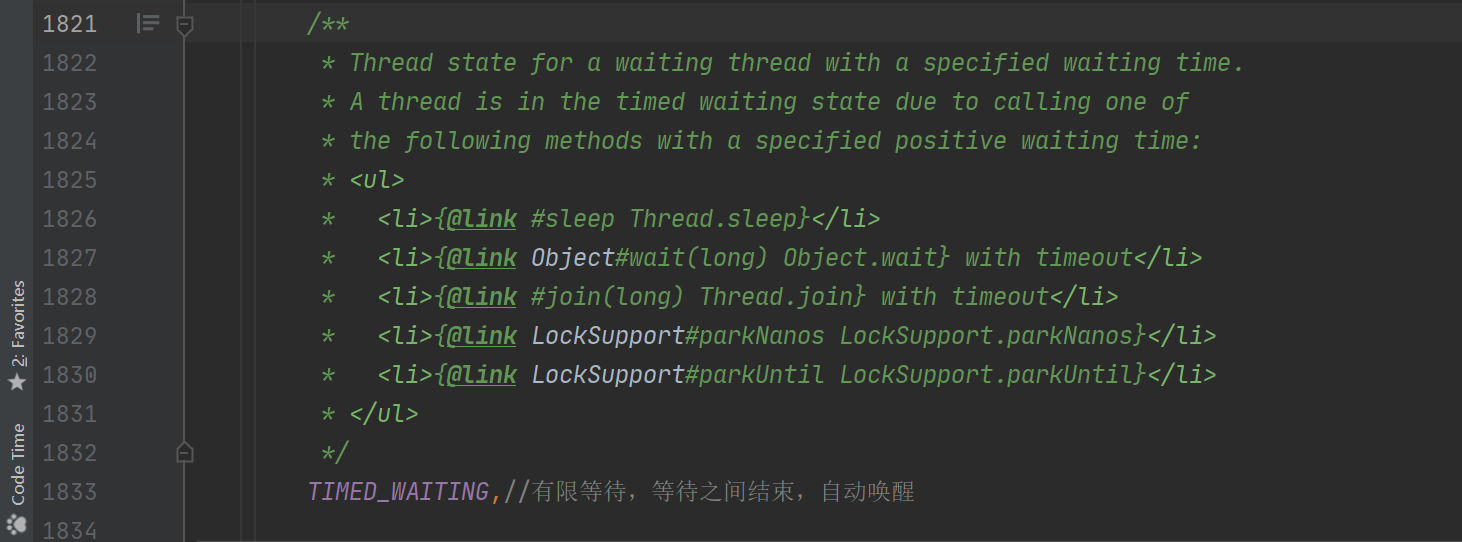
调用以下方法进入定时等待Thread.sleep 单位为毫秒
- Object.wait(long) 单位为毫秒
- Thread对象的 join(long) 单位为毫秒
- LockSupport.parkNanos 单位为纳秒
- LockSupport.parkUntil 单位为毫秒
_RUNNABLE -> _TERMINATED
图示
这个图示蛮清楚的,直接看这个好了~来源:https://www.uml-diagrams.org/java-thread-uml-state-machine-diagram-example.html
不过这个图我觉得也有问题.从 等待被唤醒后,并不会进入阻塞态,应该进入Runnable 状态。从openjdk 14中关于进入阻塞的态的注释可以知道,当等待获取 monitor lock 且进入 synchronized 修饰的方法或者代码块时,才会进入阻塞。
再加点注释,READY 与 RUNNING 并未在 Thread 的状态枚举类中表现出,也就是这两个状态是检测不出来的,只有一个 RUNNABLE。但是在理论中,这是存在的,当线程调用 start后,进入 Ready 状态,等待 CPU 分配时间片,进行调用;被调用后进入 Running。这两个状态也是可以互相转换的,处于 Running 状态的线程调用 yield() 方法后会让出时间片,重新进入 Ready 状态。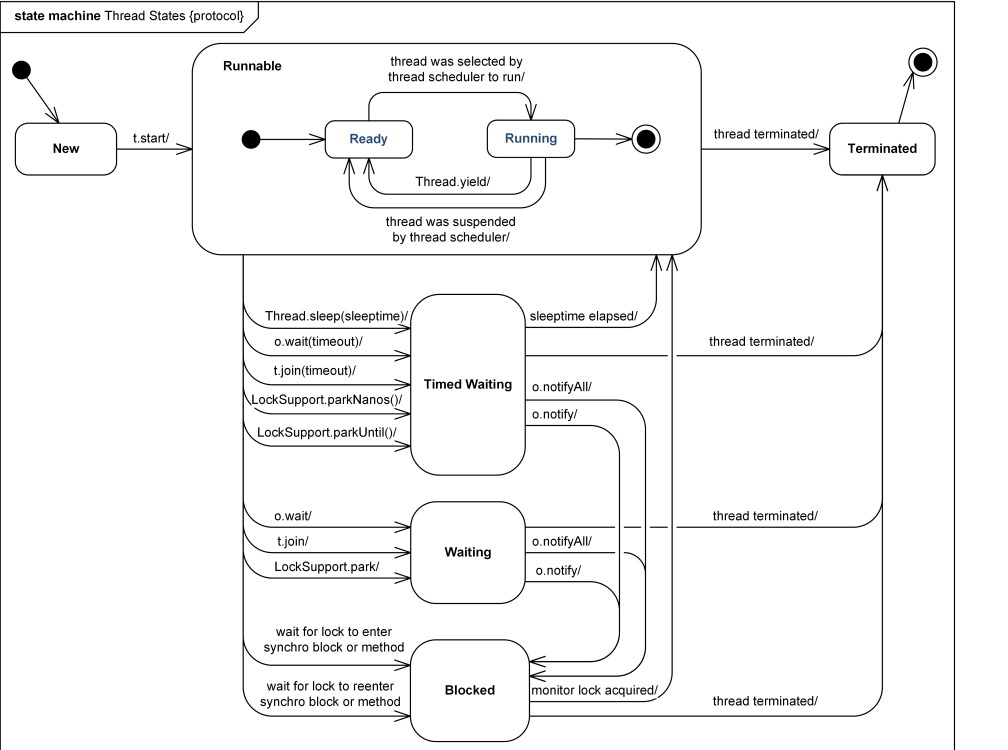
阻塞与等待的异同
这里阻塞指的是 BLOCKED 状态,等待指的是 WAITING 与 TIMED_WAITING 状态。写着写着发现阻塞与等待好像,于是记录下问题。
参考
共同点
-
不同点
阻塞态的唤醒由 JVM 决定,被动;而等待状态什么时候结束可以由开发者自己决定,主动
wait 与 sleep
调用后,都进入阻塞态。但是wait会释放锁,sleep 不释放锁
yield 与 sleep(0)的异同
共同点
不同点
这里有些争议。网上大部分文章都提到,yield让出 cpu 调度后会考虑线程的优先级,只有与当前线程同级或者更高优先级的线程才可以被调度,而 sleep 则不考虑调度。但是,一是,openjdk 14及openjdk 8中的注释并未提到这点(两个注释是一样的)
(openjdk 14)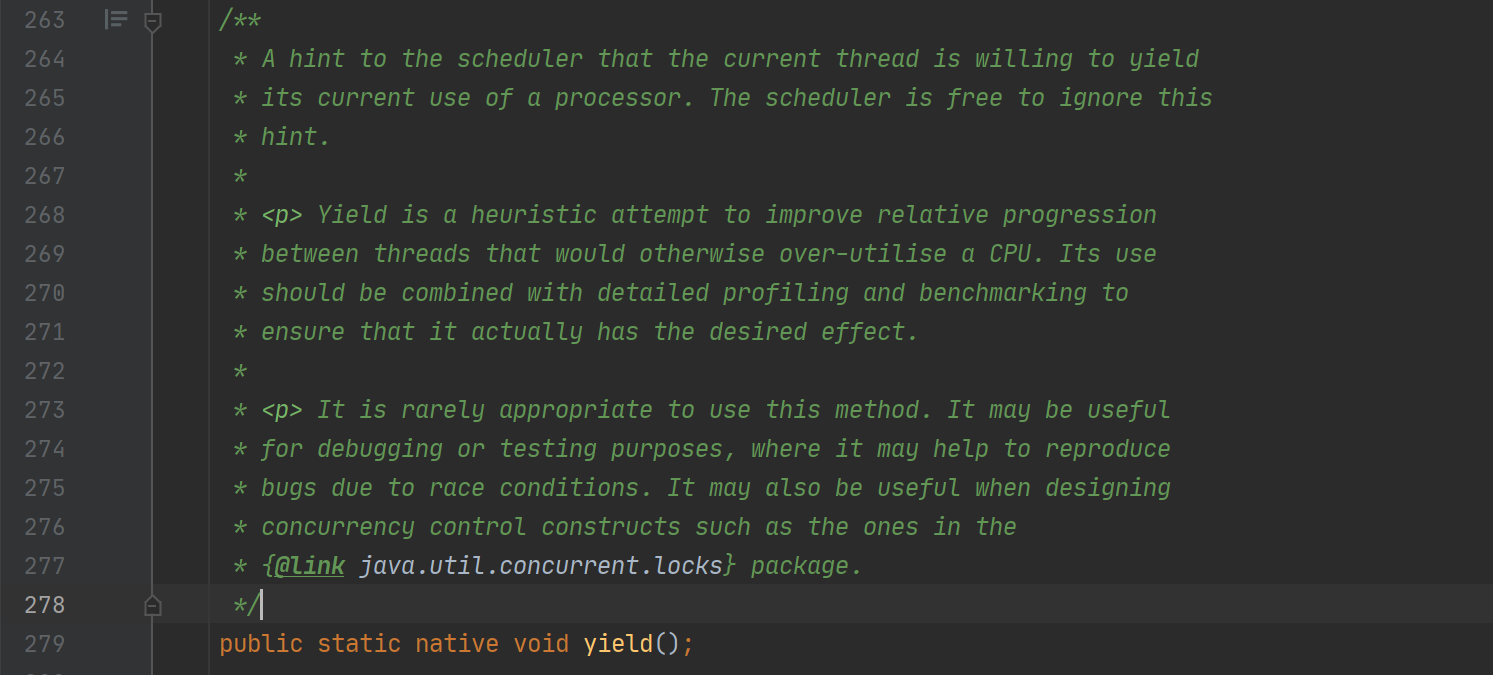
(openjdk 8)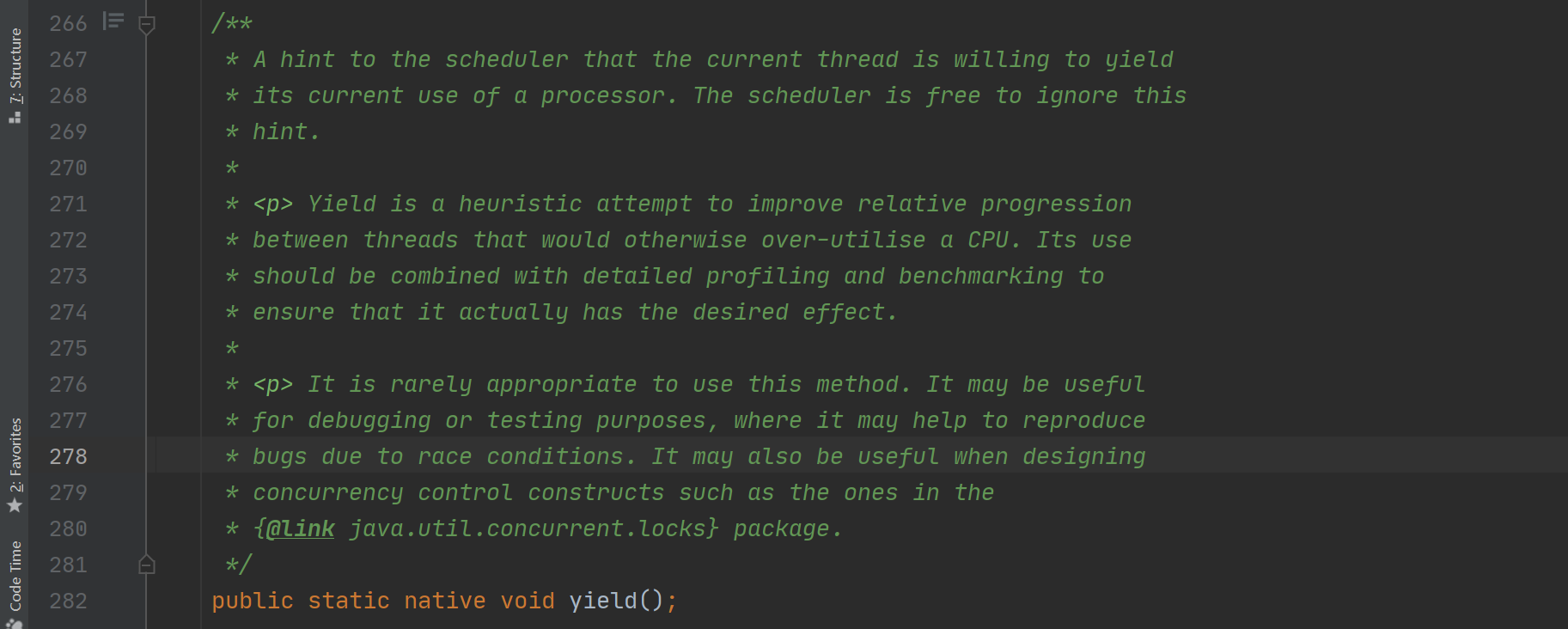
并且,有大佬从源码角度分析了,链接如下 https://juejin.im/post/6844903971463626766。我对这篇文章的理解是,只要有等待cpu调度的线程,yield就会让出调度,并不会考虑优先级问题。
- 当 sleep 的等待时间为 0时,是可以从 sleep 转为 yield(虽然默认是不进行转换)
java内存模型
一种抽象出的概念,屏蔽各种硬件和操作系统的内存访问差异,实现在各种平台下都有一致的内存访问效果。由主内存和工作内存组成,通过八个操作来进行内存间的交互。
主内存与工作内存
主内存:
- 主内存占用的是虚拟机内存(或者说主内存是虚拟机内存的一部分)
- Java模型规定所有变量都存储在主内存
工作内存:
- 每个线程都有独属于自己的工作内存,不同线程之间无法访问各自的工作内存
工作线程中保存着主内存中对应的变量的副本,线程对变量的所有操作都需要在工作内存中进行
交互
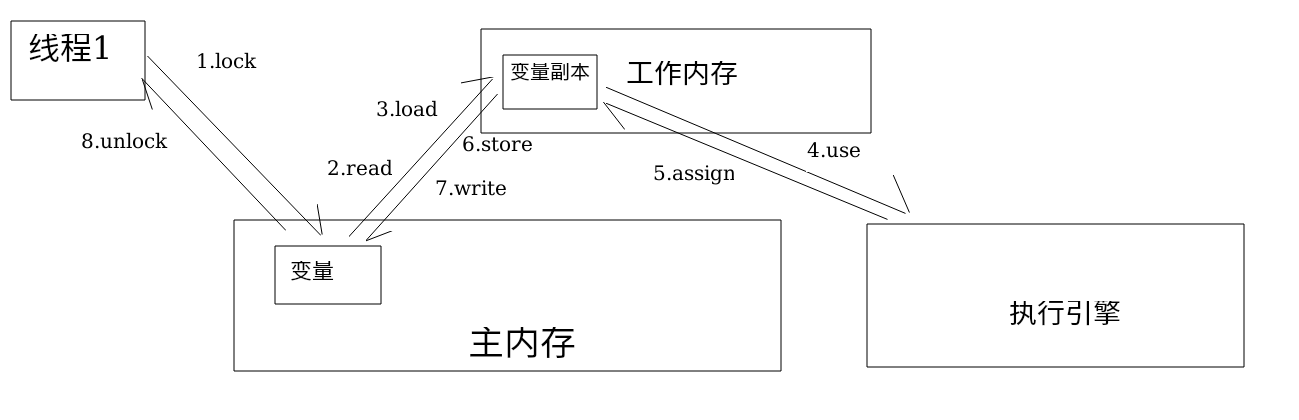
这里的变量指的是线程共享的内容,例如:实例字段,静态字段。而局部变量,方法参数等线程私有的,并不包含在内。所有的变量存储在主内存中,然后线程使用时拷贝到工作内存。
举个例子,某线程对需要使用一个全局变量
该线程先lock,锁定主内存中的变量,标识为线程独占的状态,然后read,传出主内存的变量到线程的工作内存中,之后load,将从主内存中得到的变量值载入到工作区中的一个变量副本中。之后就是修改,use,将工作区中的变量副本的值传入到执行引擎,执行引擎进行操作,然后assign,把执行引擎使用过后的该变量值传给工作区中对应的变量副本。然后store,将变量副本传入主内存,接着write,将从工作内存中得到的变量值放入主内存变量中。最后使用完毕unlock,结束占用。参考
- 一文让你明白CPU上下文切换
- 现代操作系统(第四版)
- Java线程中wait状态和block状态的区别?
- Java Thread States and Life Cycle
- 链接

若有收获,就点个赞吧
0 人点赞
