什么是Redis
Redis(Remote Dictionary Server) 是一个使用 C 语言编写的,开源的(BSD许可)高性能非关系型(NoSQL)的键值对数据库。
Redis 可以存储键和五种不同类型的值之间的映射。键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。另外,Redis 也经常用来做分布式锁。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
它具有以下特点:
- 高性能
Redis具有极高的性能,其读的速度可达11万次/秒,写的速度可达8万次/秒。
- 数据结构丰富
Redis相比大多数其它Key-Value存储系统,有着更丰富的数据结构,包括了字符串(string)、哈希(hash)、列表(list)、无序集合(set)、有序集合(sorted set)。
- 高可用
Redis3.0支持分布式集群,集群可以是多主多从,数据自动从主节点备份到从节点,当主节点发生异常时,可由其对应的从节点顶替,以保持整个集群的高可用。
- 易于扩展
Redis3.0支持分布式集群,Redis所有的数据都存储在16384个槽(slot)内。创建集群时,需要把槽分配给各个主节点。扩容时,只需要把槽重新分配给新的主节点,然后开启数据迁移即可,在扩容的过程中集群仍然是可用的。
- 原子性
Redis是单线程的,其所有操作都是原子性的,避免了多线程带来的复杂性。
- 可持久化
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
为什么要使用Redis
假如用户
第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的, 硬盘的寻址速度是毫秒级的。从数据库中获取到数据后将数据存在 Redis 中,这样下一次再访问这些数据的时候就可以直接从 Redis 中获取了, Redis 数据是存在内存中的,内存的寻址速度是纳秒级的,所以可以极大提升响应速度 ,同时缓解数据库压力 。
时间单位: 秒(s) ,毫秒(ms) ,微秒(us) ,纳秒(ns)
1秒=1000毫秒
1毫秒等于1000微秒
1微秒等于1000纳秒
现在很多互联网应用的服务端都使用到了Redis,到底大家为什么要用Redis呢?Redis有很多特性,比如高性能、高可用、数据类型丰富、易于扩展、可持久化、原子性等等,我觉得其中的“高性能”和“数据类型丰富”是最具决定性的,分析思路如下。
- 性能
关系型数据库的数据存储在硬盘,在高并发环境下I/O较高,并发能力弱,Redis的数据存储在内存,性能远高于关系型数据库。关系型数据库的性能受硬件、SQL质量、数据量等方面的影响较大,不能一概而论,但一般认为不超过1万次/秒,而Redis的读的速度可达11万次/秒,写的速度可达8万次/秒。
另一方面,随着数据量的增大,关系型数据库的查询速度会显著降低,而Redis则不会。
- 数据类型丰富
如果只是因为关系型数据库的性能问题,那么其它缓存(比如Memcache)也能减少数据库的查询次数,为什么是Redis?因为Redis支持字符串(string)、哈希(hash)、列表(list)、无序集合(set)、有序集合(sorted set)多种数据类型,这些数据类型能在实战中能发挥出强大的作用,在后续的系列文章中我会一一介绍各种数据类型的应用场景。
当然,高可用、易于扩展、可持久化、原子性等特点也是很重要的特性,深入理解有助于实战应用。
Redis如何通过读写分离来承载读请求QPS超过10万+
1.redis高并发跟整个系统的高并发之间的关系
redis,你要搞高并发的话,不可避免,要把底层的缓存搞得很好
mysql,高并发,做到了,那么也是通过一系列复杂的分库分表,订单系统,事务要求的,QPS到几万,比较高了
要做一些电商的商品详情页,真正的超高并发,QPS上十万,甚至是百万,一秒钟百万的请求量
光是redis是不够的,但是redis是整个大型的缓存架构中,支撑高并发的架构里面,非常重要的一个环节
首先,你的底层的缓存中间件,缓存系统,必须能够支撑的起我们说的那种高并发,其次,再经过良好的整体的缓存架构的设计(多级缓存架构、热点缓存),支撑真正的上十万,甚至上百万的高并发
要做一些电商的商品详情页,真正的超高并发,QPS上十万,甚至是百万,一秒钟百万的请求量光是Redis是不够的,但是Redis是整个大型缓存架构中,支撑高并发的架构里面,非常重要的一个环节.
首先你的底层是缓存中间件,缓存系统必须能够支撑的起来我们说的那种超高并发,其次再经过良好的整体的缓存架构的设计(多级缓存架构,热点缓存)支撑真正的上十万,甚至上百万的高并发.
2.redis不能支撑高并发的瓶颈在哪里
单机的redis能够承载的QPS大概上万到几万不等,具体是根据你业务操作的复杂性,redis提供了很多复杂的操作,比如说lua脚本的话那么QPS就不高了,如果只是key查询value的话,那么QPS就能很高.
如果上千万的用户都访问单击redis的话,那么redis是会承受不住挂掉的,这就是redis不能支撑高并发的瓶颈.
Redis有哪些优缺点
优点
• 读写性能优异, Redis能读的速度是110000次/s,写的速度是81000次/s。
• 支持数据持久化,支持AOF和RDB两种持久化方式。
• 支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并 后的原子性执行。
• 数据结构丰富,除了支持string类型的value外还支持hash、set、zset、list等 数据结构。
• 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
• 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
• Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求 失败,需要等待机器重启或者手动切换前端的IP才能恢复。
• 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一 致的问题,降低了系统的可用性。
Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避 免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的 浪费。
Redis为什么速度那么快
- 完全基于内存,数据放在内存中,官方给出的读写性能10万/S,与机器性能也有关,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1);
- C语言实现,与操作系统距离近
- 数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;Redis全程使⽤hash结构,读取速度快,还有⼀些特殊的数据结构,对数据存储进⾏了优化,如压缩表,对短数据进⾏压缩存储,再如,跳表,使⽤有序的数据结构加快读取的速度。
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗.保证了每个操作的原⼦性,也减少了线程的上下⽂切换和竞争。
- 使用多路 I/O 复用模型,非阻塞 IO;使⽤了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下⽂的切换和竞争。
- 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
- redis使⽤多路复⽤技术,可以处理并发的连接。⾮阻塞IO 内部实现采⽤epoll,采⽤了epoll+⾃⼰实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利⽤epoll的多路复⽤特性,绝不在io上浪费⼀点时间。
官方回答
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的⼤⼩或者⽹络带宽。既然单线程容易实现,⽽且CPU不会成为瓶颈,那就顺理成章地采⽤单线程的⽅案了。
性能指标
关于redis的性能,官⽅⽹站也有,普通笔记本轻松处理每秒⼏⼗万的请求。
详细原因
1)不需要各种锁的性能消耗
Redis的数据结构并不全是简单的Key-Value,还有list,hash等复杂的结构,这些结构有可能会进⾏很细粒度的操作,⽐如在很⻓的列表后⾯添加⼀个元素,在hash当中添加或者删除⼀个对象。这些操作可能就需要加⾮常多的锁,导致的结果是同步开销⼤⼤增加。
总之,在单线程的情况下,就不⽤去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁⽽导致的性能消耗。
2)单线程多进程集群⽅案
单线程的威⼒实际上⾮常强⼤,每核⼼效率也⾮常⾼,多线程⾃然是可以⽐单线程有更⾼的性能上限,但是在今天的计算环境中,即使是单机多线程的上限也往往不能满⾜需要了,需要进⼀步摸索的是多服务器集群化的⽅案,这些⽅案中多线程的技术照样是⽤不上的。所以单线程、多进程的集群不失为⼀个时髦的解决⽅案。
3)CPU消耗
采⽤单线程,避免了不必要的上下⽂切换和竞争条件,也不存在多进程或者多线程导致的切换⽽消耗CPU。
但是如果CPU成为Redis瓶颈,或者不想让服务器其他CUP核闲置,那怎么办?
可以考虑多起⼏个Redis进程,Redis是key-value数据库,不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。
为什么 redis 需要把所有数据放到内存中
Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以 redis 具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘 I/O 速度为严重影响 redis 的性能。在内存越来越便宜的今天,redis 将会越来越受欢迎。如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
Redis的内存分为哪些?
数据
作为数据库,数据是最主要的部分;这部分占用的内存会统计在used_memory中。
进程本身运行需要的内存
Redis主进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与Redis数据占用的内存相比可以忽略。这部分内存不是由jemalloc分配,因此不会统计在used_memory中。
缓冲内存
缓冲内存包括客户端缓冲区、复制积压缓冲区、AOF缓冲区等;
客户端缓冲存储客户端连接的输入输出缓冲;
复制积压缓冲用于部分复制功能;
AOF缓冲区用于在进行AOF重写时,保存最近的写入命令。
在了解相应功能之前,不需要知道这些缓冲的细节;这部分内存由jemalloc分配,因此会统计在used_memory中。
内存碎片
内存碎片是Redis在分配、回收物理内存过程中产生的。例如,如果对数据的更改频繁,而且数据之间的大小相差很大,可能导致redis释放的空间在物理内存中并没有释放,但redis又无法有效利用,这就形成了内存碎片。内存碎片不会统计在used_memory中。
Redis 内部结构有哪些
dict
本质上是为了解决算法中的查找问题(Searching)是一个用于维护key和value映射关系的数据结构,与很多语言中的Map或dictionary类似。本质上是为了解决算法中的查找问题(Searching)。
sds
sds就等同于char * 它可以存储任意二进制数据,不能像C语言字符串那样以字符’\0’来标识字符串的结束,因此它必然有个长度字段。
skiplist 跳跃表
跳表是一种实现起来很简单,单层多指针的链表,它查找效率很高,堪比优化过的二叉平衡树,且比平衡树的实现。
ziplist 压缩表
ziplist是一个编码后的列表,是由一系列特殊编码的连续内存块组成的顺序型数据结构。
Memcache 与 Redis 的区别都有哪些
存储方式不同:
Memcache 是把数据全部存在内存中,数据不能超过内存的大小,断电后数据库会挂掉。
Redis 有部分存在硬盘上,这样能保证数据的持久性。
数据支持的类型不同:
memcahe 对数据类型支持相对简单
redis 有复杂的数据类型。
使用底层模型不同:
它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。
Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
支持的 value 大小不一样:
redis 最大可以达到 1GB
而 memcache 只有 1MB
如果redis要支撑超过10万+的并发,那应该怎么做?
单机的redis几乎不太可能说QPS超过10万,除非一些特殊情况,比如机器性能特别好,配置特别高,运维维护特别好,而且代码超过不是特别复杂.不过一般情况下redis单击也就是在几万就到头了.
要想支撑10W加的QPS的话:
集群,可以考虑主从哨兵集群等等.
一般来说,对缓存一般都是支持读高并发的,写的请求是比较少的,可能写的请求也就是一秒钟就几千,或者一两千,而大量的读请求一般都是一秒钟二十万次读
一般是主从架构.下面的架构就能支撑20W+的QPS,如果还不够的话,就再增加slave,每增加一个就能躲5W加的QPS,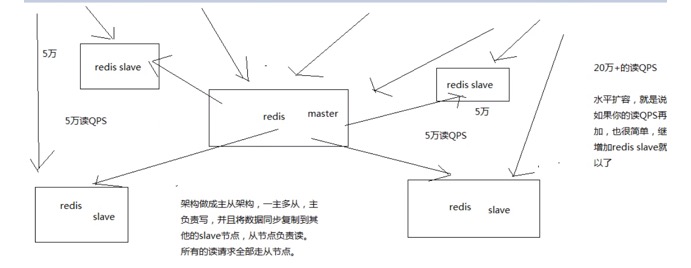
(1)redis采用异步方式复制数据到slave节点,不过redis 2.8开始,slave node会周期性地确认自己每次复制的数据量
(2)一个master node是可以配置多个slave node的
(3)slave node也可以连接其他的slave node
(4)slave node做复制的时候,是不会block master node的正常工作的
(5)slave node在做复制的时候,也不会block对自己的查询操作,它会用旧的数据集来提供服务; 但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了
(6)slave node主要用来进行横向扩容,做读写分离,扩容的slave node可以提高读的吞吐量
Redis单线程如何处理那么多的并发客户端连接
Redis的IO多路复用(类似NIO的原理):redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
为什么Redis 是单线程的?
以前一直有个误区,以为:高性能服务器 一定是 多线程来实现的
原因很简单因为误区二导致的:多线程 一定比 单线程 效率高。其实不然。
在说这个事前希望大家都能对 CPU 、 内存 、 硬盘的速度都有了解了,这样可能理解得更深刻一点,不了解的朋友点:CPU到底比内存跟硬盘快多少
redis 核心就是 如果我的数据全都在内存里,我单线程的去操作 就是效率最高的,为什么呢,因为多线程的本质就是 CPU 模拟出来多个线程的情况,这种模拟出来的情况就有一个代价,就是上下文的切换,对于一个内存的系统来说,它没有上下文的切换就是效率最高的。redis 用 单个CPU 绑定一块内存的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个CPU上完成的,所以它是单线程处理这个事。在内存的情况下,这个方案就是最佳方案 —— 阿里 沈询
因为一次CPU上下文的切换大概在 1500ns 左右。
从内存中读取 1MB 的连续数据,耗时大约为 250us,假设1MB的数据由多个线程读取了1000次,那么就有1000次时间上下文的切换,
那么就有1500ns * 1000 = 1500us ,我单线程的读完1MB数据才250us ,你光时间上下文的切换就用了1500us了,我还不算你每次读一点数据 的时间,
那什么时候用多线程的方案呢?
答案是:下层的存储等慢速的情况。比如磁盘
内存是一个 IOPS 非常高的系统,因为我想申请一块内存就申请一块内存,销毁一块内存我就销毁一块内存,内存的申请和销毁是很容易的。而且内存是可以动态的申请大小的。
磁盘的特性是:IPOS很低很低,但吞吐量很高。这就意味着,大量的读写操作都必须攒到一起,再提交到磁盘的时候,性能最高。为什么呢?
如果我有一个事务组的操作(就是几个已经分开了的事务请求,比如写读写读写,这么五个操作在一起),在内存中,因为IOPS非常高,我可以一个一个的完成,但是如果在磁盘中也有这种请求方式的话,
我第一个写操作是这样完成的:我先在硬盘中寻址,大概花费10ms,然后我读一个数据可能花费1ms然后我再运算(忽略不计),再写回硬盘又是10ms ,总共21ms
第二个操作去读花了10ms, 第三个又是写花费了21ms ,然后我再读10ms, 写21ms ,五个请求总共花费83ms,这还是最理想的情况下,这如果在内存中,大概1ms不到。
所以对于磁盘来说,它吞吐量这么大,那最好的方案肯定是我将N个请求一起放在一个buff里,然后一起去提交。
方法就是用异步:将请求和处理的线程不绑定,请求的线程将请求放在一个buff里,然后等buff快满了,处理的线程再去处理这个buff。然后由这个buff 统一的去写入磁盘,或者读磁盘,这样效率就是最高。java里的 IO不就是这么干的么~
对于慢速设备,这种处理方式就是最佳的,慢速设备有磁盘,网络 ,SSD 等等,
多线程 ,异步的方式处理这些问题非常常见,大名鼎鼎的netty 就是这么干的。
终于把 redis 为什么是单线程说清楚了,把什么时候用单线程跟多线程也说清楚了,其实也是些很简单的东西,只是基础不好的时候,就真的尴尬。。。。
补一发大师语录:来说说,为何单核cpu绑定一块内存效率最高
“我们不能任由操作系统负载均衡,因为我们自己更了解自己的程序,所以我们可以手动地为其分配CPU核,而不会过多地占用CPU”,默认情况下单线程在进行系统调用的时候会随机使用CPU内核,为了优化Redis,我们可以使用工具为单线程绑定固定的CPU内核,减少不必要的性能损耗!
redis作为单进程模型的程序,为了充分利用多核CPU,常常在一台server上会启动多个实例。而为了减少切换的开销,有必要为每个实例指定其所运行的CPU。
Linux 上 taskset 可以将某个进程绑定到一个特定的CPU。你比操作系统更了解自己的程序,为了避免调度器愚蠢的调度你的程序,或是为了在多线程程序中避免缓存失效造成的开销。
1.单进程单线程优势

若有收获,就点个赞吧
0 人点赞
