Redis 的 key 是字符串类型,但是 key 中不能包括边界字符,由于 key 不是 binary safe的字符串,所以像”my key”和”mykey\n”这样包含空格和换行的 key 是不允许的.
Redis的key都是String,而value有五种类型.包括String,List,Set,Zset,Hash,
| 数据类型 | 可以存储 的值 | 操作 | 应用场景 |
|---|---|---|---|
| STRING | 字符串、 整数或者 浮点数 | 对整个字 符串或者 字符串的 其中一部 分执行操 作 对整数和 浮点数执 行自增或 者自减操 作 | 做简单的 键值对缓 存 |
| LIST | 列表 | 从两端压 入或者弹 出元素 对单个或 者多个元 素进行修 剪, 只保留一 个范围内 的元素 | 存储一些 列表型的 数据结 构,类似 粉丝列 表、文章 的评论列 表之类的 数据 |
| SET | 无序集合 | 添加、获 取、移除 单个元素 检查一个 元素是否 存在于集 合中 | 交集、并 集、差集 的操作, 比如交 集,可以 把两个人 的粉丝列 |
| HASH | 包含键值 对的无序 散列表 | 添加、获 取、移除 单个键值 对 获取所有 键值对 检查某个 键是否存 在 | 结构化的 数据,比 如一个对 象 |
| ZSET | 有序集合 | 添加、获 取、删除 元素 根据分值 范围或者 成员来获 取元素 计算一个 键的排名 | 去重但可 以排序, 如获取排 名前几名 的用户 |
02.字符串String类型
string 是最基本的类型,而且 string 类型是二进制安全的。意思是 redis 的 string 可以
包含任何数据,可以是字符串(包括XML JSON),还有数字(整形 浮点数),二进制(图片 音频 视频)。比如 jpg 图片或者序列化的对象。
从内部实现来看其实 string 可以看作 byte数组,最大上限是 1G 字节。
在Redis中字符串类型的Value最多可以容纳的数据长度是512M.
可以存储的值
1.字符串
2.整数
3.浮点数
操作
- 对整个字符串或者字符串的其中一部分执行操作
- 对整数和浮点数执行自增或者自减操作
- 位运算
使用场景
- 做简单的键值对缓存
2. 计数器 / 分布式 ID 生成
3. 位运算做海量数据统计(日活 / 月活)
- Redis的数据是共享的
如果将用户信息存储在web服务的本地缓存,则每个web服务都会缓存一份,当用户修改昵称时,需要通知其它web服务更新用户缓存。
如果将用户信息存储在Redis,则只有一份缓存,所有的web访问的都是同一份缓存,当用户修改昵称时,所有web服务都能同时访问到最新的缓存。
- Redis是单线程的
由于Redis的性能瓶颈在于内存读写速度,而不是CPU,设计者将Redis设计成了单线程模式,其所有操作都是原子性的,避免了多线程带来的复杂性。
基于以上两点特性,Redis的string类型主要有以下应用场景。
- 计数器
string类型的incr和decr命令的作用是将key中储存的数字值加一/减一,这两个操作具有原子性,总能安全地进行加减操作,因此可以用string类型进行计数,如微博的评论数、点赞数、分享数,抖音作品的收藏数,京东商品的销售量、评价数等。
- 分布式锁
string类型的setnx的作用是“当key不存在时,设值并返回1,当key已经存在时,不设值并返回0”,“判断key是否存在”和“设值”两个操作是原子性地执行的,因此可以用string类型作为分布式锁,返回1表示获得锁,返回0表示没有获得锁。例如,为了保证定时任务的高可用,往往会同时部署多个具备相同定时任务的服务,但是业务上只希望其中的某一台服务执行定时任务,当定时任务的时间点触发时,多个服务同时竞争一个分布式锁,获取到锁的执行定时任务,没获取到的放弃执行定时任务。定时任务执行完时通过del命令删除key即释放锁,如果担心del命令操作失败而导致锁一直未释放,可以通过expire命令给锁设置一个合理的自动过期时间,确保即使del命令失败,锁也能被释放。不过expire命令同样存在失败的可能性,如果你用的是Java语言,建议使用JedisCommands接口提供的String set(String key, String value, String nxxx, String expx, long time)方法,这个方法可以将setnx和expire原子性地执行,具体使用方式如下(相信其它语言的Redis客户端也应当提供了类似的方法)。
jedisCommands.set(“IAmAKey”, “1”, “NX”, “EX”, 60);//如果”IAmAKey”不存在,则将其设值为1,同时设置60秒的自动过期时间
- 存储对象
利用JSON强大的兼容性、可读性和易用性,将对象转换为JSON字符串,再存储在string类型中,是个不错的选择,如用户信息、商品信息等。
03.哈希hash类型
hash 是一个 string 类型的 field 和 value 的映射表。添加,删除操作都是 O(1)(平均)。hash类型类似java的HashMap ,允许存放多个key-value
hash 特别适合用于存储对象。相对于将对象的每个字段存成单个 string 类型。将一个对象存储在 hash 类型中会占用更少的内存,并且可以更方便的存取整个对象。省内存的原因是新建一个 hash 对象时开始是用 zipmap(又称为 small hash)来存储的。这个 zipmap 其实并不是 hash table,但是 zipmap 相比正常的 hash 实现可以节省不少 hash 本身需要的一些元数据存储开销。尽管 zipmap 的添加,删除,查找都是 O(n),但是由于一般对象的 field数量都不太多。所以使用 zipmap 也是很快的,也就是说添加删除平均还是 O(1)。如果 field或者 value 的大小超出一定限制后,redis 会在内部自动将 zipmap 替换成正常的 hash 实现. 这个限制可以在配置文件中指定。
hash-max-zipmap-entries 64 #配置字段最多 64 个
hash-max-zipmap-value 512 #配置 value 最大为 512 字节
是一个string类型的field和value的映射表,hash特适合用于存储对象。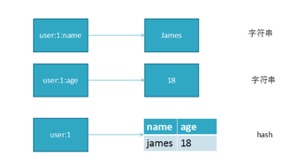
以上图的指令分别为:
set user:1:name james
set user:1:age 18
不难发现,用字符串类型可以存储,但会过多占用KEY,浪费内存;
可以使用hash类型存储; hmset user:1 name james age 18;
操作
- 添加、获取、移除单个键值对获取所有键值对
- 检查某个键是否存
应用场景
在结构化的数据,比如一个对象,缓解 key 数量增多产生的频繁rehash。
hash类型的(key, field, value)的结构与对象的(对象id, 属性, 值)的结构相似,所以hash特别适合用于存储对象。 比如我们可以Hash数据结构来存储用户信息,商品信息等等。
比如将关系型数据表转成redis存储: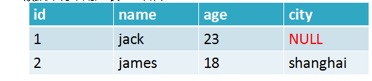
使用hash后的存储方式为:
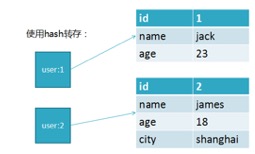
HASH类型是稀疏,每个键可以有不同的filed, 若用redis模拟做关系复杂查询开发因难,维护成本高
三种方案实现用户信息存储优缺点:
1.原生:set user:1:name james;
set user:1:age 23;
set user:1:sex boy;
优点:简单直观,每个键对应一个值
缺点:键数过多,占用内存多,用户信息过于分散,不用于生产环境
2.将对象序列化存入redis
set user:1 serialize(userInfo);
优点:编程简单,若使用序列化合理内存使用率高
缺点:序列化与反序列化有一定开销,更新属性时需要把userInfo全取出来进行反序列化,更新后再序列化到redis
3.使用hash类型:
hmset user:1 name james age 23 sex boy
优点:简单直观,使用合理可减少内存空间消耗
缺点:要控制ziplist与hashtable两种编码转换,且hashtable会消耗更多内存
单点登录,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
04.列表List类型
概念
list 是一个链表结构,可以理解为一个每个子元素都是 string 类型的双向链表。主要功
能是 push、pop、获取一个范围的所有值等。操作中 key 理解为链表的名字。
List 类型类似Java 的LinkedList ,通过链表来完成,向其添加元素速度非常快,,但按照索引方式获取元素比较慢,因此List 结构适合那种大数据量,要求插入速度极快的场景。
用来存储多个有序的字符串,一个列表最多可存2的32次方减1个元素
因为有序,可以通过索引下标获取元素或某个范围内元素列表,列表元素可以重复
可以存储的值
操作
- 从两端压入或者弹出元素
- 对单个或者多个元素进行修剪,只保留一个范围内的元素
使用场景
- 分布式栈
2. 分布式队列 / 阻塞队列
3. 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的热点数据
可以截取list最后面的数据,就是热点数据.
list类型是简单的字符串列表,按照插入顺序排序。每个列表最多可以存储 232 - 1 个元素(40多亿) ,
list就是链表,Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如微博的关注列表,粉丝列表,最新消息排行等功能都可以用Redis的list结构来实现。 Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
list类型主要有以下应用场景:
1. 消息队列
list类型的lpop和rpush(或者反过来,lpush和rpop)能实现队列的功能,故而可以用Redis的list类型实现简单的点对点的消息队列。不过我不推荐在实战中这么使用,因为现在已经有Kafka、NSQ、RabbitMQ等成熟的消息队列了,它们的功能已经很完善了,除非是为了更深入地理解消息队列,不然我觉得没必要去重复造轮子。
- 排行榜
list类型的lrange命令可以分页查看队列中的数据。可将每隔一段时间计算一次的排行榜存储在list类型中,如京东每日的手机销量排行、学校每次月考学生的成绩排名、斗鱼年终盛典主播排名等,下图是酷狗音乐“K歌擂台赛”的昨日打擂金曲排行榜,每日计算一次,存储在list类型中,接口访问时,通过page和size分页获取打擂金曲。(打个小广告,酷狗音乐“K歌擂台赛”每天都能产生一批优质翻唱作品,对普通人优质歌声有兴趣的朋友不妨来听听)。
但是,并不是所有的排行榜都能用list类型实现,只有定时计算的排行榜才适合使用list类型存储,与定时计算的排行榜相对应的是实时计算的排行榜,list类型不能支持实时计算的排行榜,之后在介绍有序集合sorted set的应用场景时会详细介绍实时计算的排行榜的实现。
- 最新列表
list类型的lpush命令和lrange命令能实现最新列表的功能,每次通过lpush命令往列表里插入新的元素,然后通过lrange命令读取最新的元素列表,如朋友圈的点赞列表、评论列表。
但是,并不是所有的最新列表都能用list类型实现,因为对于频繁更新的列表,list类型的分页可能导致列表元素重复或漏掉,举个例子,当前列表里由表头到表尾依次有(E,D,C,B,A)五个元素,每页获取3个元素,用户第一次获取到(E,D,C)三个元素,然后表头新增了一个元素F,列表变成了(F,E,D,C,B,A),此时用户取第二页拿到(C,B,A),元素C重复了。只有不需要分页(比如每次都只取列表的前5个元素)或者更新频率低(比如每天凌晨更新一次)的列表才适合用list类型实现。对于需要分页并且会频繁更新的列表,需用使用有序集合sorted set类型实现。另外,需要通过时间范围查找的最新列表,list类型也实现不了,也需要通过有序集合sorted set类型实现,如以成交时间范围作为条件来查询的订单列表。之后在介绍有序集合sorted set类型的应用场景时会详细介绍sorted set类型如何实现最新列表。
那么问题来了,对于排行榜和最新列表两种应用场景,list类型能做到的sorted set类型都能做到,list类型做不到的sorted set类型也能做到,那为什么还要使用list类型去实现排行榜或最新列表呢,直接用sorted set类型不是更好吗?原因是sorted set类型占用的内存容量是list类型的数倍之多(之后会在容量章节详细介绍),对于列表数量不多的情况,可以用sorted set类型来实现,比如上文中举例的打擂金曲排行榜,每天全国只有一份,两种数据类型的内存容量差距可以忽略不计,但是如果要实现某首歌曲的翻唱作品地区排行榜,数百万的歌曲,300多个地区,会产生数量庞大的榜单,或者数量更加庞大的朋友圈点赞列表,就需要慎重地考虑容量的问题了。
05.无序集合Set类型
set类型是string类型的集合,其特点是集合元素无序且不重复,每个集合最多可以存储 2的32次方 - 1 个元素(40多亿
set 是无序集合,最大可以包含(2 的 32 次方-1)个元素。set 的是通过 hash table 实现的,所以添加,删除,查找的复杂度都是 O(1)。hash table 会随着添加或者删除自动的调整大小。
需要注意的是调整 hash table 大小时候需要同步(获取写锁)会阻塞其他读写操作。可能不久后就会改用跳表(skip list)来实现。跳表已经在 sorted sets 中使用了。关于 set 集合类型除了基本的添加删除操作,其它有用的操作还包含集合的取并集(union),交集(intersection),差集(difference)。通过这些操作可以很容易的实现 SNS 中的好友推荐和 blog 的 tag 功能。
Set与java中的java.util.Set类似,代表元素不能重复的集合,Redis的Set处理元素的添加和删除操作,还包含了集合的并集,交集等功能,可以用于统计访问网站所有的IP,或者统计网站作者共同点粉丝等应用.
操作
- 添加、获取、移除单个元素检查一个元素是否存在于集合中
2. 计算交集、并集、差集
3. 从集合里面随机获取元素
使用场景
- 两人的好友集合求交集,可以求两个人的共同好友
2. 两人的好友差集,可以做可能认识的好友推荐。
3.并集去重可以做统计类的需求
应用:可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
1. 好友/关注/粉丝/感兴趣的人集合
set类型唯一的特点使得其适合用于存储好友/关注/粉丝/感兴趣的人集合,集合中的元素数量可能很多,每次全部取出来成本不小,set类型提供了一些很实用的命令用于直接操作这些集合,如
a. sinter命令可以获得A和B两个用户的共同好友
b. sismember命令可以判断A是否是B的好友
c. scard命令可以获取好友数量
c. 关注时,smove命令可以将B从A的粉丝集合转移到A的好友集合
需要注意的是,如果你用的是Redis Cluster集群,对于sinter、smove这种操作多个key的命令,要求这两个key必须存储在同一个slot(槽位)中,否则会报出 (error) CROSSSLOT Keys in request don’t hash to the same slot 错误。Redis Cluster一共有16384个slot,每个key都是通过哈希算法CRC16(key)获取数值哈希,再模16384来定位slot的。要使得两个key处于同一slot,除了两个key一模一样,还有没有别的方法呢?答案是肯定的,Redis提供了一种Hash Tag的功能,在key中使用{}括起key中的一部分,在进行 CRC16(key) mod 16384 的过程中,只会对{}内的字符串计算,例如friend_set:{123456}和fans_set:{123456},分别表示用户123456的好友集合和粉丝集合,在定位slot时,只对{}内的123456进行计算,所以这两个集合肯定是在同一个slot内的,当用户123456关注某个粉丝时,就可以通过smove命令将这个粉丝从用户123456的粉丝集合移动到好友集合。相比于通过srem命令先将这个粉丝从粉丝集合中删除,再通过sadd命令将这个粉丝加到好友集合,smove命令的优势是它是原子性的,不会出现这个粉丝从粉丝集合中被删除,却没有加到好友集合的情况。然而,对于通过sinter获取共同好友而言,Hash Tag则无能为力,例如,要用sinter去获取用户123456和456789两个用户的共同好友,除非我们将key定义为{friend_set}:123456和{friend_set}:456789,否则不能保证两个key会处于同一个slot,但是如果真这样做的话,所有用户的好友集合都会堆积在同一个slot中,数据分布会严重不均匀,不可取,所以,在实战中使用Redis Cluster时,sinter这个命令其实是不适合作用于两个不同用户对应的集合的(同理其它操作多个key的命令)。
- 随机展示
通常,app首页的展示区域有限,但是又不能总是展示固定的内容,一种做法是先确定一批需要展示的内容,再从中随机获取。如下图所示,酷狗音乐K歌擂台赛当日的打擂歌曲共29首,首页随机展示5首;昨日打擂金曲共200首,首页随机展示30首。
set类型适合存放所有需要展示的内容,而srandmember命令则可以从中随机获取几个。
3. 黑名单/白名单
经常有业务出于安全性方面的考虑,需要设置用户黑名单、ip黑名单、设备黑名单等,set类型适合存储这些黑名单数据,sismember命令可用于判断用户、ip、设备是否处于黑名单之中。
用户标签,社交,查询有共同兴趣爱好的人,智能推荐
保存多元素,与列表不一样的是不允许有重复元素,且集合是无序,一个集合最多可存2的32次方减1个元素,除了支持增删改查,还支持集合交集、并集、差集;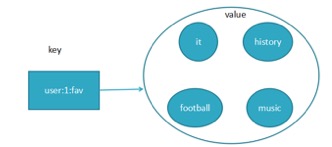
使用场景:
set数据类型可以当成分布式HashSet来用
set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的。 当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。 在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis可以非常方便的实现如共同关注、共同喜好、二度好友等功能。
标签,社交,查询有共同兴趣爱好的人,智能推荐
使用方式:
给用户添加标签:
sadd user:1:fav basball fball pq
sadd user:2:fav basball fball
…………
或给标签添加用户
sadd basball:users user:1 user:3
sadd fball:users user:1 user:2 user:3
……..
计算出共同感兴趣的人:
sinter user:1:fav user2:fav
规则:sadd (常用于标签) spop/srandmember(随机,比如抽奖)
sadd+sinter (用于社交,查询共同爱好的人,匹配)
06.有序集合SortSet
概念
sorted set 是有序集合,它在 set 的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,会自动重新按新的值调整顺序。可以理解了有两列的mysql 表,一列存 value,一列存顺序。操作中 key 理解为 sorted set 的名字。
操作
- 添加、获取、删除元素
- 根据分值范围或者成员来获取元素
- 计算一个键的排名
使用场景
- 排行榜需求
2. 延迟队列
3. 限速器
可以做排行榜应用,取TOP N操作。
常用于排行榜,如视频网站需要对用户上传视频做排行榜,或点赞数
与集合有联系,不能有重复的成员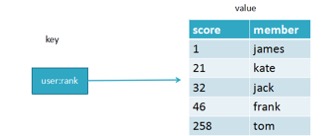
与LIST SET 对比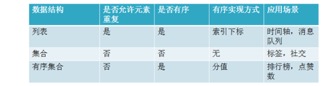

若有收获,就点个赞吧
0 人点赞
