CMS和G1的区别
区别一: 使用范围不一样
CMS 收集器是老年代的收集器,可以配合新生代的 Serial 和 ParNew 收集器一起使用
G1 收集器收集范围是老年代和新生代。不需要结合其他收集器使用
区别二: STW 的时间
CMS 收集器以最小的停顿时间为目标的收集器。
G1 收集器可预测垃圾回收的停顿时间(建立可预测的停顿时间模型)
区别三: 垃圾碎片
CMS 收集器是使用 “标记 - 清除” 算法进行的垃圾回收,容易产生内存碎片
G1 收集器使用的是 “标记 - 整理” 算法,进行了空间整合,降低了内存空间碎片。
区别四: 垃圾回收的过程不一样

CMS 回收垃圾的 4 个阶段
初始标记阶段:会让线程全部停止,也就是 Stop the World 状态
并发标记阶段:对所有的对象进行追踪,这个阶段最耗费时。但这个阶段是和系统并发运行的,所以不会对系统运行造成影响
重新标记阶段:
由于第二阶段是并发执行的,一边标记垃圾对象,一边创建新对象,老对象会变成垃圾对象。 所以第三阶段也会进入 Stop the World 状态,并且重新标记,标记的是第二阶段中变动过的少数对象,所以运行速度很快
并发清理阶段: 这个阶段也是会耗费很多时间,但由于是并发运行的,所以对系统不会造成很大的影响
CMS 的总结和优缺点
CMS 采用 标记 - 清理 的算法,标记出垃圾对象,清除垃圾对象。算法是基于老年代执行的,因为新生代产生无法接受该算法产生的碎片垃圾。
优点:并发收集,低停顿
不足:
- 无法处理浮动垃圾,并发收集会造成内存碎片过多
- 由于并发标记和并发清理阶段都是并发执行,所以会额外消耗 CPU 资源
G1 回收器的特点
G1 的出现就是为了替换 jdk1.5 种出现的 CMS, 这一点已经在 jdk9 的时候实现了,jdk9 默认使用了 G1 回收器,移除了所有 CMS 相关的内容。G1 和 CMS 相比,有几个特点:
- 控制回收垃圾的时间:这个是 G1 的优势,可以控制回收垃圾的时间,还可以建立停顿的时间模型,选择一组合适的 Regions 作为回收目标,达到实时收集的目的
- 空间整理:和 CMS 一样采用标记 - 清理的算法,但是 G1 不会产生空间碎片,这样就有效的使用了连续空间,不会导致连续空间不足提前造成 GC 的触发
G1 把 Java 内存拆分成多等份,多个域(Region),逻辑上存在新生代和老年代的概念,但是没有严格区分
贴图感受一下:
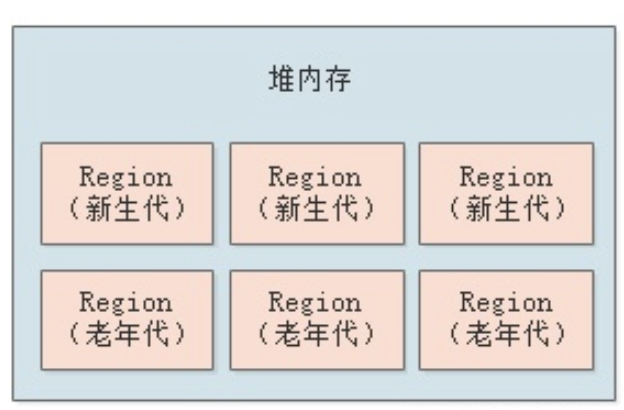
依旧存在新生代老年代的概念,但是没有严格区分。Region 最多分为 2048 个
大对象的处理
除了上面优点之外,还有一个优点,那就是对大对象的处理。在 CMS 内存中,如果一个对象过大,进入 S1、S2 区域的时候大于改分配的区域,对象会直接进入老年代。G1 处理大对象时会判断对象是否大于一个 Region 大小的 50%,如果大于 50% 就会横跨多个 Region 进行存放
G1 回收垃圾的 4 个阶段
初始标记: 标记 GC Roots 可以直接关联的对象,该阶段需要线程停顿但是耗时短
并发标记: 寻找存活的对象,可以与其他程序并发执行,耗时较长
最终标记: 并发标记期间用户程序会导致标记记录产生变动(好比一个阿姨一边清理垃圾,另一个人一边扔垃圾)虚拟机会将这段时间的变化记录在 Remembered Set Logs 中。最终标记阶段会向 Remembered Set 合并并发标记阶段的变化。这个阶段需要线程停顿,也可以并发执行
筛选回收: 对每个 Region 的回收成本进行排序,按照用户自定义的回收时间来制定回收计划
什么情况下应该考虑使用 G1
参考官方文档:
- 实时数据占用超过一半的堆空间
- 对象分配或者晋升的速度变化大
- 希望消除长时间的 GC 停顿(超过 0.5-1 秒)
G1 设置参数
控制 G1 回收垃圾的时间
-XX:MaxGCPauseMillis=200 (默认 200ms)
CMS 是老年代垃圾回收器?
初步印象是,但实际上不是。根据 CMS 的各个收集过程,它其实是一个涉及年轻代和老年代的综合性垃圾回收器。在很多文章和书籍的划分中,都将 CMS 划分为了老年代垃圾回收器,加上它主要作用于老年代,所以一般误认为是。

若有收获,就点个赞吧
0 人点赞
