总结
比如jit即时编译中一个方法中定义了一个对象但是没有被其他地方引用,而栈中又放得下的话就会将这个对象放到栈里面
逃逸分析确定某个指针可以存储的所有地方,以及确定能否保证指针的生命周期只在当前进程或线程中。
简单来讲,JVM 中的逃逸分析**可以通过分析对象引用的使用范围(即动态作用域),来决定对象是否要在堆上分配内存,也可以做一些其他方面的优化。
正文
为了防止歧义,可以换个说法:
Java 对象实例和数组元素都是在堆上分配内存的吗?
答:不一定。满足特定条件时,它们可以在(虚拟机)栈上分配内存。
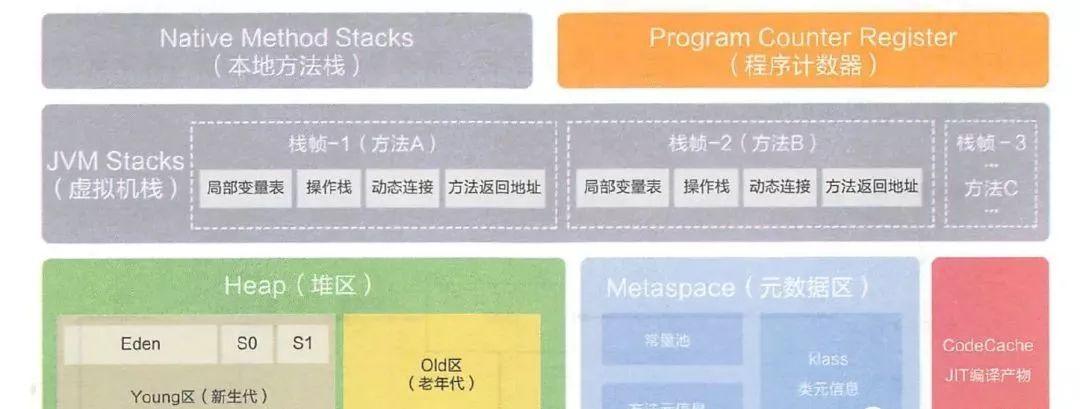
JVM 内存结构很重要,多多复习
这和我们平时的理解可能有些不同。虚拟机栈一般是用来存储基本数据类型、引用和返回地址的,怎么可以存储实例数据了呢?
这是因为 Java JIT(just-in-time)编译器进行的两项优化,分别称作逃逸分析(escape analysis)和标量替换(scalar replacement)。
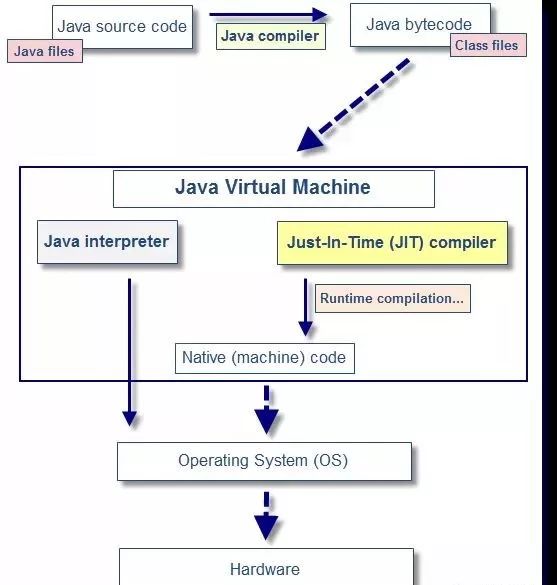
注意看一下 JIT 的位置
中文维基上对逃逸分析的描述基本准确,摘录如下:
在编译程序优化理论中,逃逸分析是一种确定指针动态范围的方法——分析在程序的哪些地方可以访问到指针。当一个变量(或对象)在子程序中被分配时,一个指向变量的指针可能逃逸到其它执行线程中,或是返回到调用者子程序。
如果一个子程序分配一个对象并返回一个该对象的指针,该对象可能在程序中被访问到的地方无法确定——这样指针就成功 “逃逸” 了。如果指针存储在全局变量或者其它数据结构中,因为全局变量是可以在当前子程序之外访问的,此时指针也发生了逃逸。
逃逸分析确定某个指针可以存储的所有地方,以及确定能否保证指针的生命周期只在当前进程或线程中。
简单来讲,JVM 中的逃逸分析可以通过分析对象引用的使用范围(即动态作用域),来决定对象是否要在堆上分配内存,也可以做一些其他方面的优化。
关于逃逸分析,以下的例子说明了一种对象逃逸的可能性。
static StringBuilder getStringBuilder1(String a, String b) {StringBuilder builder = new StringBuilder(a);builder.append(b);return builder; // builder通过方法返回值逃逸到外部}static String getStringBuilder2(String a, String b) {StringBuilder builder = new StringBuilder(a);builder.append(b);return builder.toString(); // builder范围维持在方法内部,未逃逸}
以 JDK 1.8 为例,可以通过设置 JVM 参数 - XX:+DoEscapeAnalysis、-XX:-DoEscapeAnalysis 来开启或关闭逃逸分析(默认当然是开启的)。
下面先写一个没有对象逃逸的例子。
public class EscapeAnalysisTest {public static void main(String[] args) throws Exception {long start = System.currentTimeMillis();for (int i = 0; i < 5000000; i++) {allocate();}System.out.println((System.currentTimeMillis() - start) + " ms");Thread.sleep(600000);}static void allocate() {MyObject myObject = new MyObject(2019, 2019.0);}static class MyObject {int a;double b;MyObject(int a, double b) {this.a = a;this.b = b;}}}
然后通过开启和关闭 DoEscapeAnalysis 开关观察不同。
关闭逃逸分析
~ java -XX:-DoEscapeAnalysis EscapeAnalysisTest76 ms~ jmap -histo 26031num #instances #bytes class name----------------------------------------------1: 5000000 120000000 me.lmagics.EscapeAnalysisTest$MyObject2: 636 12026792 [I3: 3097 1524856 [B4: 5088 759960 [C5: 3067 73608 java.lang.String6: 623 71016 java.lang.Class7: 727 43248 [Ljava.lang.Object;8: 532 17024 java.io.File9: 225 14400 java.net.URL10: 334 13360 java.lang.ref.Finalizer# ......
开启逃逸分析
~ java -XX:+DoEscapeAnalysis EscapeAnalysisTest4 ms~ jmap -histo 26655num #instances #bytes class name----------------------------------------------1: 592 11273384 [I2: 90871 2180904 me.lmagics.EscapeAnalysisTest$MyObject3: 3097 1524856 [B4: 5088 759952 [C5: 3067 73608 java.lang.String6: 623 71016 java.lang.Class7: 727 43248 [Ljava.lang.Object;8: 532 17024 java.io.File9: 225 14400 java.net.URL10: 334 13360 java.lang.ref.Finalizer# ......
可见,关闭逃逸分析之后,堆上有 5000000 个 MyObject 实例,而开启逃逸分析之后,就只剩下 90871 个实例了,不管是实例数还是内存占用都只有原来的 2% 不到。
另外,如果把堆内存限制得小一点(比如加上 - Xms10m -Xmx10m),并且打印 GC 日志(-XX:+PrintGCDetails)的话,关闭逃逸分析还会造成频繁的 GC,开启逃逸分析就没有这种情况。这说明逃逸分析确实降低了堆内存的压力。
但是,逃逸分析只是栈上内存分配的前提,接下来还需要进行标量替换才能真正实现。
所谓标量,就是指 JVM 中无法再细分的数据,比如 int、long、reference 等。相对地,能够再细分的数据叫做聚合量。
仍然考虑上面的例子,MyObject 就是一个聚合量,因为它由两个标量 a、b 组成。通过逃逸分析,JVM 会发现 myObject 没有逃逸出 allocate() 方法的作用域,标量替换过程就会将 myObject 直接拆解成 a 和 b,也就是变成了:
static void allocate() {int a = 2019;double b = 2019.0;}
可见,对象的分配完全被消灭了,而 int、double 都是基本数据类型,直接在栈上分配就可以了。所以,在对象不逃逸出作用域并且能够分解为纯标量表示时,对象就可以在栈上分配。
JVM 提供了参数 - XX:+EliminateAllocations 来开启标量替换,默认仍然是开启的。显然,如果把它关掉的话,就相当于禁止了栈上内存分配,只有逃逸分析是无法发挥作用的。
在 Debug 版 JVM 中,还可以通过参数 - XX:+PrintEliminateAllocations 来查看标量替换的具体情况。
除了标量替换之外,通过逃逸分析还能实现同步消除
(synchronization elision),当然它与本文的主题无关了。
举个例子:
private void someMethod() {Object lockObject = new Object();synchronized (lockObject) {System.out.println(lockObject.hashCode());}}
lockObject 这个锁对象的生命期只在 someMethod() 方法中,并不存在多线程访问的问题,所以 synchronized 块并无意义,会被优化掉:
private void someMethod() {Object lockObject = new Object();System.out.println(lockObject.hashCode());}
原文

若有收获,就点个赞吧
0 人点赞
