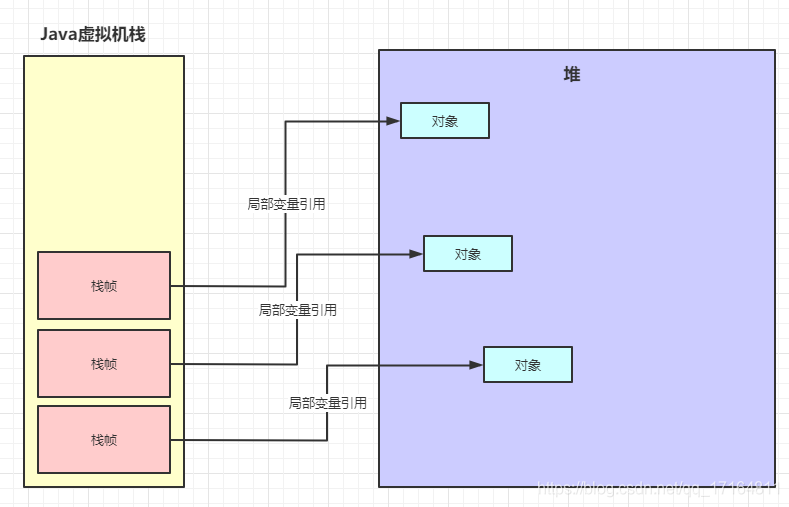
- 如果是使用ParNew + CMS 垃圾回收器的话,堆内存分年轻代和老年代是很明确的,不像G1
- 然后说一下ParNew垃圾回收器。
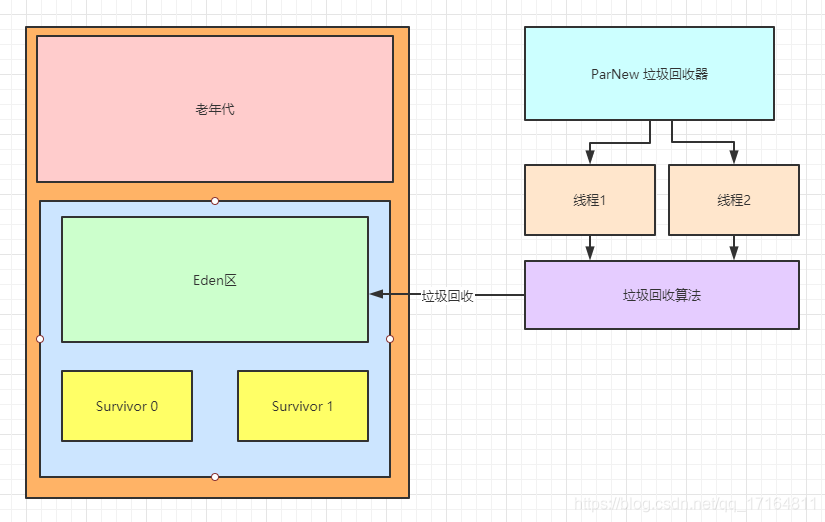
- 这个垃圾回收器是回收年轻代的,使用的是多线程回收,不像之前的Serial回收器使用单线程回收。
- 然后ParNew使用的是复制清除算法,把年轻代分为Eden区 和两个Survivor,JVM 参数默认的占比是 8:1:1,系统运行会把对象创建到Eden区,每次YoungGC 会标记存活对象,复制到Survivor0中,再次YoungGC时,再把存活对象复制到Survivor1中。系统运行期间会保证一直有一个Survivor是空着的。
- Eden区的占比有时是可以调优的,如果条件有限,没有大内存的机器,然后对象创建的还特别频繁,存活的对象比较多,那就建议把Eden区比例调低一些,让Survivor大一点,宁可Young GC多一些,也不要让Survivor触发了动态年龄审核或者放不下存活对象。如果放不下那就把这批对象扔到老年代了,Full GC是很慢的。如果是调低Eden,YoungGC会很频繁,但是YoungGC特别快,我通过jstat 看,回收100M垃圾大概也就1ms,所以,如果内存实在不够,降低Eden去比例也不是不可以。但是如果有条件的话最好的话还是加大新生代内存,毕竟YoungGC也是要Stop the World的。
- 这个垃圾回收器是回收年轻代的,使用的是多线程回收,不像之前的Serial回收器使用单线程回收。
- 然后继续说ParNew ,它非常适合回收年轻代内存。因为年轻代一般存活的对象是很少的,大多数都是刚创建出1毫秒就变成了垃圾,所以把极少数存活的对象标记出来,复制成本还是很低的,如果像老年代那样采用标记清除算法,那就太慢了
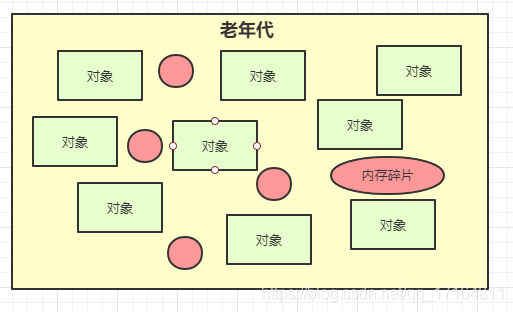
- 然后说一下老年代的垃圾回收器CMS,这个垃圾回收器是使用的 标记-清除 + 整理 算法,我们一般在JVM参数会指定这算法和整理的频率,JVM参数默认是,标记-清除,5次之后,才会去整理内存空间,让对象整齐排列。但是这个默认参数不太好,这样做会有大量的内存碎片,如果某一次从年轻代晋升一个大对象,老年代居然找不到一块连续的内存,就会触发Full GC,那就坑了。我们会把那个值调成0,就是每次CMS垃圾回收后,都会整理内存,虽然每次的回收时间会多一些,但是不会出现内存碎片。
- 然后再说一下ParNew + CMS 调优的问题吧。如果一个系统需要JVM调优,那其实说白了就是Stop the World 太久了,导致系统太卡了。我们说的调优,其实就是减少STW的时间,让系统没有明显的卡顿现象。
- 然后分析下,需要STW的有几个地方。YoungGC,和Old GC的两个阶段。但是YoungGC一般STW时间特别短,Old GC时间一般会是Young GC的几倍到几十倍,而且占用CPU资源严重。所以,我们优化的重点是让系统减少Old GC的次数。最好让系统只有YoungGC,没有Old GC,更没有Full GC
- 所以,优化的重点就是尽量不要让对象进入老年代。如果对象进不去老年代,想Full GC都难。这是JVM调优的重点,对象进入老年代的情况也有几种
- 第一种,对象经过15次YoungGC,依然是存活的,那晋升老年代
- 这个其实我们是可以优化一下的,因为如果系统1分钟或者30秒一次YoungGC,那没必要非得让对象存活十几分钟才进入老年代,一般存活个两三分钟,这个对象大概率就是要存活很久的了。所以,我们当时是调低了这个参数的,设置了5。不然这个对象一直存活,然后在两个Survivor里来回复制,如果这个对象小一点还好,如果这个对象挺大的,那容易触发Survivor的动态年龄审核机制,让一大批对象进入老年代。所以,该进入老年代的对象,就让他赶紧进去。
- 这个其实我们是可以优化一下的,因为如果系统1分钟或者30秒一次YoungGC,那没必要非得让对象存活十几分钟才进入老年代,一般存活个两三分钟,这个对象大概率就是要存活很久的了。所以,我们当时是调低了这个参数的,设置了5。不然这个对象一直存活,然后在两个Survivor里来回复制,如果这个对象小一点还好,如果这个对象挺大的,那容易触发Survivor的动态年龄审核机制,让一大批对象进入老年代。所以,该进入老年代的对象,就让他赶紧进去。
- 第二种,Young GC后存活的对象大小超过Survivor 的50%,那就会触发动态年龄审核机制,如:1岁、2岁、3岁、4岁的对象加起来大于Survivor 的50%,那大于等于4岁的对象全部进入老年代。
- 第三种,Young GC后存活的对象大于Survivor的大小,那这一批对象直接全部进入老年代,特别坑。
- 第四种,大对象直接进入老年代,这个JVM参数里是可以设置的,一般我们都设置1M,大于1M的对象进入老年代,一般很少有1M的对象,一般都是个大数组,或者map。
- 第一种,对象经过15次YoungGC,依然是存活的,那晋升老年代
- 第一种情况和第四种情况,一般是可控的。所以想要优化的话,主要是要在Survivor的大小这块下功夫。我们要避免动态年龄审核和Survivor放不下的情况。要想保证这点,我们就要知道,我们系统的高峰时期,JVM中每秒有多少对象新增,每次YoungGC存活了多少对象。这就需要用 jstat 了。
- 首先要使用 jstat -gc PID 1000 1000
- 找到JVM的PID,然后每秒打印一次JVM的内存情况,如果系统访问量比较小,每秒的增长不是很明显,那就把每次的间隔时间调大一点,比如一分钟打印一次
- 通过这行命令,我们可以看到当时的内存使用情况,有几个列比较重要的数据
- S0C:Survivor0 的大小
- S1C:Survivor1 的大小
- S0U:Survivor0 使用了多少
- S1U:Survivor1 使用了多少
- EC:Eden 区的大小
- EU:Eden 区使用了多少
- OC:老年代的大小
- OU:老年代使用了多少
- MC:永久代的大小
- MU:永久代使用了多少
- YGC:YoungGC次数
- YGCT:YoungGC的总耗时
- FGC:Full GC次数
- FGCT:Full GC的总耗时
- 找到JVM的PID,然后每秒打印一次JVM的内存情况,如果系统访问量比较小,每秒的增长不是很明显,那就把每次的间隔时间调大一点,比如一分钟打印一次
- 一般使用 jstat 优化,重点观察这几个指标
- Eden 区对象的增长速度
- 上面的几列,通过一行数据是看不出来Eden 区每秒增长多少数据的,所以我们才每秒打印一次,通过上一秒和下一秒EU的数据就可以推断出每秒增长了多少。这个数据进来多打印几行,取个平均值。
- 上面的几列,通过一行数据是看不出来Eden 区每秒增长多少数据的,所以我们才每秒打印一次,通过上一秒和下一秒EU的数据就可以推断出每秒增长了多少。这个数据进来多打印几行,取个平均值。
- Young GC 频率
- 我们我们知道系统启动时间,用YGC的大小除也能算,但是谁没事记得系统什么时候启动的。而且如果我想看高峰时期某一段时间的呢,就看不了了。看几十天的平均值也没什么意义。所以这个高峰时段YoungGC的频率是通过,Eden的大小,除以Eden区对象的增长速度来算的,Eden区对象增长速度,我们已经知道了。
- 我们我们知道系统启动时间,用YGC的大小除也能算,但是谁没事记得系统什么时候启动的。而且如果我想看高峰时期某一段时间的呢,就看不了了。看几十天的平均值也没什么意义。所以这个高峰时段YoungGC的频率是通过,Eden的大小,除以Eden区对象的增长速度来算的,Eden区对象增长速度,我们已经知道了。
- Young GC 耗时
- 这个YoungGC耗时,我们取平均值就行,用YGCT除以YCG,时间除以次数就是每次的耗时。如果说就像看高峰时段的,因为CPU等使用率比较高,可能会影响回收时间,也可以单独看几次的YoungGC,算出时间。
- 这个YoungGC耗时,我们取平均值就行,用YGCT除以YCG,时间除以次数就是每次的耗时。如果说就像看高峰时段的,因为CPU等使用率比较高,可能会影响回收时间,也可以单独看几次的YoungGC,算出时间。
- Young GC 后多少对象存活
- 这个指标还是比较重要的,我们要确定每次存活的对象Survovir到底能不能放得下。我们要保证每次存活的对象要小于Survivor的50%,否则就会触发动态年龄审核机制。
- 这个指标还是比较重要的,我们要确定每次存活的对象Survovir到底能不能放得下。我们要保证每次存活的对象要小于Survivor的50%,否则就会触发动态年龄审核机制。
- 老年代对象增量速度
- 老年代对象增长速度,决定了Old GC的频率。发生Old GC后,FGC那一列也会增长,FGC那一列其实是FullGC 和Old GC的总和。经过优化后的JVM,每次YoungGC不应该进入太多的对象,不进入或者每次进入几兆是比较好的。这个指标我们也要分多次观察,因为只看一次YoungGC晋升的大小是片面的。我们现在已经知道了YoungGC的频率,如果是3分钟一次,那我们就3分钟打印一次内存情况。jstat -gc PID 180000 100,取多次晋升大小的平均值就行。如果晋升的对象特别多,我们需要分析这些对象为什么会进入老年代,上面我说了有四种情况会晋升老年代,到底是哪种情况。是Survivor不够大,还是大对象太多了,或者有内存泄漏导致对象回收不掉,进入了老年代。这个还要具体分析一下的。如果是Survivor太小,我们很轻易就能看出来,如果每次Young GC后S区都是0,那说明存活的对象太多,S区放不下,都进入了老年代。如果S区不是0,有一部分,但是每次回收进入老年代都很多,就有可能是触发动态年龄审核,这个最好再通过GC日志看一下,通过JVM参数可以让系统打印每次GC的日志。如果出现内存泄漏,数据一般是这样的,发现每次FGC次数加1后,老年代并没有多少数据被回收掉,占用了很多。这就大概率是内存泄漏,导致老年代回收不掉。如果是大对象,数据会这样显示,发现及时没有Young GC,OU也会一直在涨,因为大对象是不用经过年轻代的直接进入老年代。如果内存泄漏和大对象的情况,我们可以用 jmap 打印一份内存快照,用MAT工具分析一下到底是什么对象特别大,通过分析出来的堆栈信息就可以定位到代码的位置。
- 老年代对象增长速度,决定了Old GC的频率。发生Old GC后,FGC那一列也会增长,FGC那一列其实是FullGC 和Old GC的总和。经过优化后的JVM,每次YoungGC不应该进入太多的对象,不进入或者每次进入几兆是比较好的。这个指标我们也要分多次观察,因为只看一次YoungGC晋升的大小是片面的。我们现在已经知道了YoungGC的频率,如果是3分钟一次,那我们就3分钟打印一次内存情况。jstat -gc PID 180000 100,取多次晋升大小的平均值就行。如果晋升的对象特别多,我们需要分析这些对象为什么会进入老年代,上面我说了有四种情况会晋升老年代,到底是哪种情况。是Survivor不够大,还是大对象太多了,或者有内存泄漏导致对象回收不掉,进入了老年代。这个还要具体分析一下的。如果是Survivor太小,我们很轻易就能看出来,如果每次Young GC后S区都是0,那说明存活的对象太多,S区放不下,都进入了老年代。如果S区不是0,有一部分,但是每次回收进入老年代都很多,就有可能是触发动态年龄审核,这个最好再通过GC日志看一下,通过JVM参数可以让系统打印每次GC的日志。如果出现内存泄漏,数据一般是这样的,发现每次FGC次数加1后,老年代并没有多少数据被回收掉,占用了很多。这就大概率是内存泄漏,导致老年代回收不掉。如果是大对象,数据会这样显示,发现及时没有Young GC,OU也会一直在涨,因为大对象是不用经过年轻代的直接进入老年代。如果内存泄漏和大对象的情况,我们可以用 jmap 打印一份内存快照,用MAT工具分析一下到底是什么对象特别大,通过分析出来的堆栈信息就可以定位到代码的位置。
- Full GC 频率多高
- 看这个频率和看YoungGC的频率是一样的,可以看高峰时期某几次的平均值。这个Full GC是很耗时的,Full GC的频率我们最好控制在一天1次或者几天一次的范围。特别是对时效性要求比较高的系统,一定要减少Full GC次数。
- 看这个频率和看YoungGC的频率是一样的,可以看高峰时期某几次的平均值。这个Full GC是很耗时的,Full GC的频率我们最好控制在一天1次或者几天一次的范围。特别是对时效性要求比较高的系统,一定要减少Full GC次数。
- 一次Full GC 的耗时
- 这个可以取平均值,也可以取某一段的。我们会发现这个Full GC的耗时是YoungGC的好多倍
- 这个可以取平均值,也可以取某一段的。我们会发现这个Full GC的耗时是YoungGC的好多倍
- Eden 区对象的增长速度
- ParNew + CMS 的原理和优化大概就是这么样的,下面我说一下现在比较流行的G1回收器
- 有人说G1比ParNew +CMS好,可以全面取代,没必要用ParNew和CMS了,我觉得不是这样的。G1有G1的优点,但是也有缺点。我们选择垃圾回收器还是要根据系统的实际情况来看。但是ParNew+CMS的确有不足的地方,如果某些系统使用的机器是大内存,16G、32G,那每次GC都要等Eden区放满了才执行垃圾回收,一次回收好几G的垃圾,那太慢了,可能停顿时间几十上百毫秒,Full GC甚至要几秒。那就太坑了,不可以接收。这个时候就必须用G1了。
- 那什么情况下用ParNew+CMS呢,它又什么优点
- 它的优点就是我们可以优化到极致,极致到没有Full GC只有YoungGC。但是G1不行,我们对G1的优化只能是尽可能的优化预定的停顿时间,其他的我们没法参与太多,因为它什么时候YoungGC我们都不确定。
- G1的内存使用率是没有ParNew +CMS高的,G1有这么一个机制,如果G1的某一个Region存活对象达到了85%,那就不会去回收这个Region,但是那15%呢。如果是垃圾也回收不掉了。
- G1的掌控性没有ParNew + CMS好,说白了就是心里没底。我们使用ParNew + CMS可以很确定多久YoungGC,对象增长速度等等等等吧,我们都能看到。但是G1什么时候垃圾回收我们都不知道,如果出现了内存泄漏,如果不是几个G的内存泄漏,我们也很难察觉出来。使用ParNew + CMS可以放心一些,不用搞个活动心惊胆战的。
- 它的优点就是我们可以优化到极致,极致到没有Full GC只有YoungGC。但是G1不行,我们对G1的优化只能是尽可能的优化预定的停顿时间,其他的我们没法参与太多,因为它什么时候YoungGC我们都不确定。
- 所以总结来说,如果是4核8G的机器,尽量还是用ParNew + CMS垃圾回收器,如果是大内存机器,就是用G1。
- 然后说一下G1的原理吧,G1把堆内存平均分成了多个大小相同的Region,我们首先要设置堆内存的大小,然后G1会根据堆大小除以2048,分成2048个大小相同的Region。G1也是有年轻代、老年代的概念,但是只是概念。没有ParNew+CMS分的那么清楚。G1里的年轻代和老年代都是基于Region的,某些Region属于年轻代,某些Region属于老年代,由G1动态控制。但是现在属于年轻代的Region并不永远都是年轻代,如果年轻代的Region被回收了,下次这个Region可能就存放老年代的数据了。所以,G1的年轻代和老年代都是动态的,但是也有个上限。系统刚开始运行时,会给年轻代分配5%的Region来存放对象,年轻代最多可以占用60%的Region,这60%可以通过JVM参数指定,默认是60%,不过这个一般默认就好,如果达到了目标值,就会强制触发YoungGC
- G1的年轻代也是分Eden和Survivor的,因为G1整体使用的都是复制回收算法。只是某些Region属于Eden,某些Region属于Survivor,系统新创建的对象会被分配到属于Eden的Region,如果垃圾回收就把存活对象复制到Survivor中。
- G1的一个特点就是我们可以设置一个预期的停顿时间,也就是STW的时间,比如,某个系统的时效性要就特别高,每次GC我只允许STW的5ms,那我们就可以通过JVM参数设置成5ms的停顿,这样G1在垃圾回收时,就会把时间控制在5ms以内。
- G1的垃圾回收不一定是年轻代满了,或者老年代满了才去回收。如果是那样,就和ParNew+CMS没区别了,大内存机器也要STW好久。G1是基于每个Region的性价比去回收的,比如,Region1里有20M对象,回收2ms,Region2里有50兆对象回收要4ms。如果我们设置系统停顿时间为5ms,那G1会在要求的时间内,尽可能回收更多的对象,它会选择Region2,因为性价比更高。所以,我们系统运行,一直往Eden放对象,如果G1觉得,此时回收一下垃圾,差不多要5ms,那可能G1就回去回收,不会等到年轻代占用60%才去回收。
- G1中年轻代的对象什么情况下会进入老年代
- 其实和ParNew + CMS整体上是差不多的,只有大对象的处理不一样
- 1、YoungGC存活的对象Survivor放不下
- 2、YoungGC存活的对象达到Survivor的50%,触发动态年龄审核
- 3、对象到达了15岁,进入老年代
- G1中大对象不会进入老年代,而是专门有一部分Region存放大对象用。如果一个Region放不下大对象,那就会横跨几个Region来存放。
- 其实和ParNew + CMS整体上是差不多的,只有大对象的处理不一样
- G1的Old G也不是我们能控制的,G1会根据自己的判断觉得该回收的时候就会回收,不过也是基于复制算法的
- G1的混合回收,如果老年代占比45%,就会触发混合回收,回收整个堆内存,但是混合回收也是会控制在我们设置的停顿时间的范围内的,如果时间不够,就会分多次回收。混合回收有点和CMS的回收类似
- 第一步,初始标记
- 初始标记需要STW,这一步只标记GC Root直接应用的对象,速度很快
- 初始标记需要STW,这一步只标记GC Root直接应用的对象,速度很快
- 第二步,并发标记
- 和系统并行,深入的追踪GC Root,标记所有存活的对象,此时系统新创建的对象会被JVM记录,这一步不需要STW
- 和系统并行,深入的追踪GC Root,标记所有存活的对象,此时系统新创建的对象会被JVM记录,这一步不需要STW
- 第三步,重新标记,重新标记第二步有改动的对象,要STW。因为只有一小部分改动,速度很快
- 第四步,混合回收,只有这一步和CMS不一样,CMS这里的回收时和系统并行的。但是G1的混合回收需要STW。混合回收不仅会回收老年代,还会回收新生代和大对象。如果一次性全回收掉,那时间就太久了,可能达不到我们设置的预期停顿时间,所以G1这里是分几批来回收的,回收一次,系统运行一会,然后再回收一次。JVM参数可以设置这个值,分几次去回收,默认值是8次,分8次回收。混合回收还有一个参数我们可以设置,就是空闲的Region达到百分之多少,停止回收,默认是5%。
- 第一步,初始标记
- G1何时会触发Full GC,其实G1的混合回收就相当于ParNew + CMS的Full GC了,因为回收了所有的区域,只不过回收时间可以控制在我们指定的范围内。但是G1的Full GC就没法控制了,可能要卡顿特别久才能回收完。什么情况下会出现呢,因为G1的整体是基于复制算法的,如果回收的过程中,发现存活对象找不到可以复制的Region,放不下了。那就Full GC,开始单线程标记、清理、整理空闲出一批Region,这个过程很慢。
- 然后说一下G1的优化,G1比较智能,我们可以参与优化的点很少,我们只能合理的设置停顿时间,不要太小也不要太大,太小GC会太频繁,每秒都在GC。太大的话,停顿时间太久了也不好。
- 平时我们选择垃圾回收器要根据不同的场景具体去分析,该使用那个。没有绝对的好坏。优化也没有一个统一的标准。比如YoungGC和Full GC多久一次好,YoungGC、Full GC耗时多久比较好。这个还是看系统的,只要不影响系统使用,没有卡顿感,我觉得都是好的。而且有些系统内部使用的,即使卡顿一会也无所谓,如果优化的话,用大内存机器成本也在那呢,不用做没必要的优化。
原文地址:
本文链接:https://blog.csdn.net/qq_17164811/article/details/107141112

若有收获,就点个赞吧
0 人点赞
