1.概述
HDFS即Hadoop分布式文件系统,以流式数据访问模式来存储超大文件,运行于商用硬件集群上,是管理网络中跨多台计算机存储的文件系统。不适用于用作要求低时间延迟数据访问的应用,存储大量的小文件,多用户写入,任意修改文件。
在HDFS上的文件被分为多块,作为独立的存储单元,称为数据块,64M(1.X),128M(2.X)
使用数据块的好处:
a. 一个文件的大小可以大于网络中任意一个磁盘的容量。文件的所有块不需要存储在同一个磁盘上,因此它们可以利用集群上的任意一个磁盘进行存储。
b. 简化了存储子系统的设计,将存储子系统控制单元设置为块,可简化存储管理,同时元数据就不需要和块一同存储,用一个单独的系统就可以管理这些块的元数据。
c. 数据块适合用于数据备份进而提供数据容错能力和提高可用性。
2.写数据
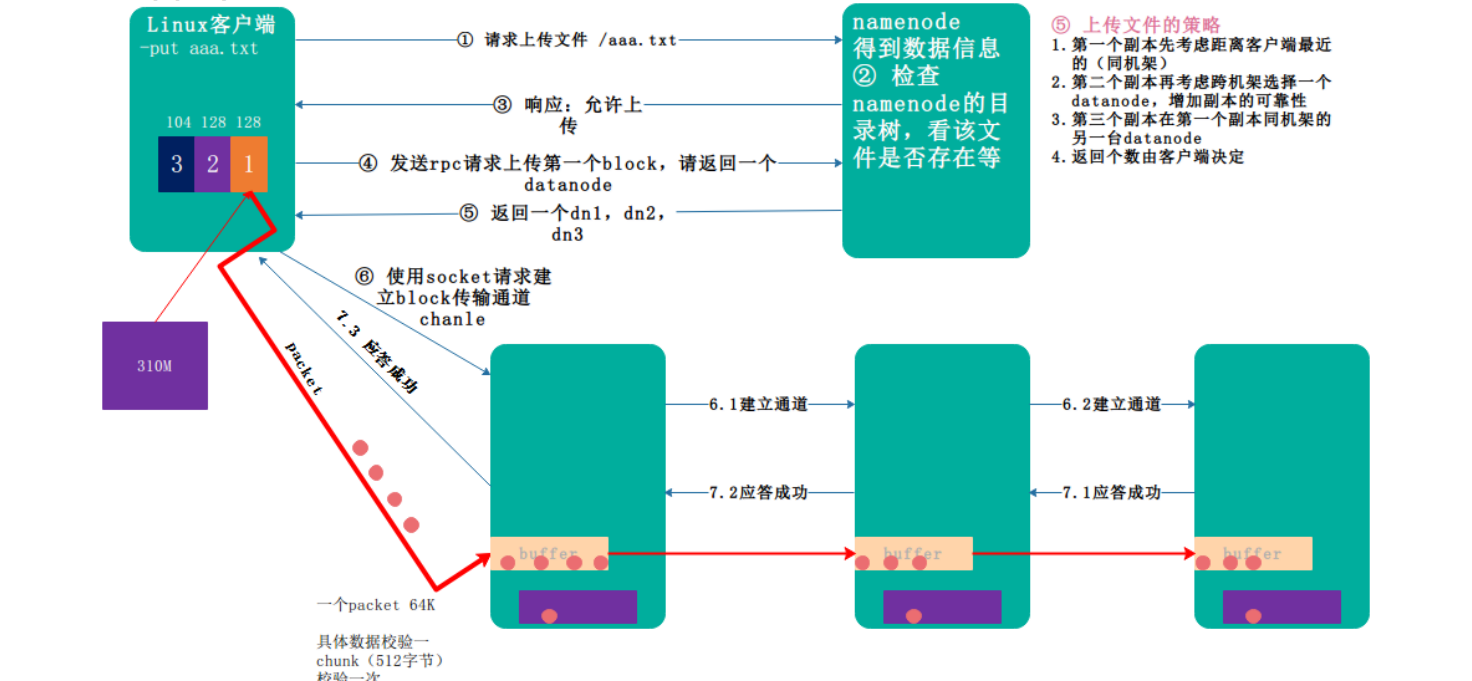
a. 根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在.
b. namenode返回是否可以上传.
c. client请求第一个 block该传输到哪些datanode服务器上.
d. namenode返回3个datanode服务器ABC.
e. client请求3台dn中的一台A上传数据(建立pipeline),A收到请求会继续调用B,然后B调用C,将一个pipeline建立完成,逐级返回客户端.
f. client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答.
g. 当一个block传输完成之后,client再次请求namenode上传第二个block的服务器.
3.读数据
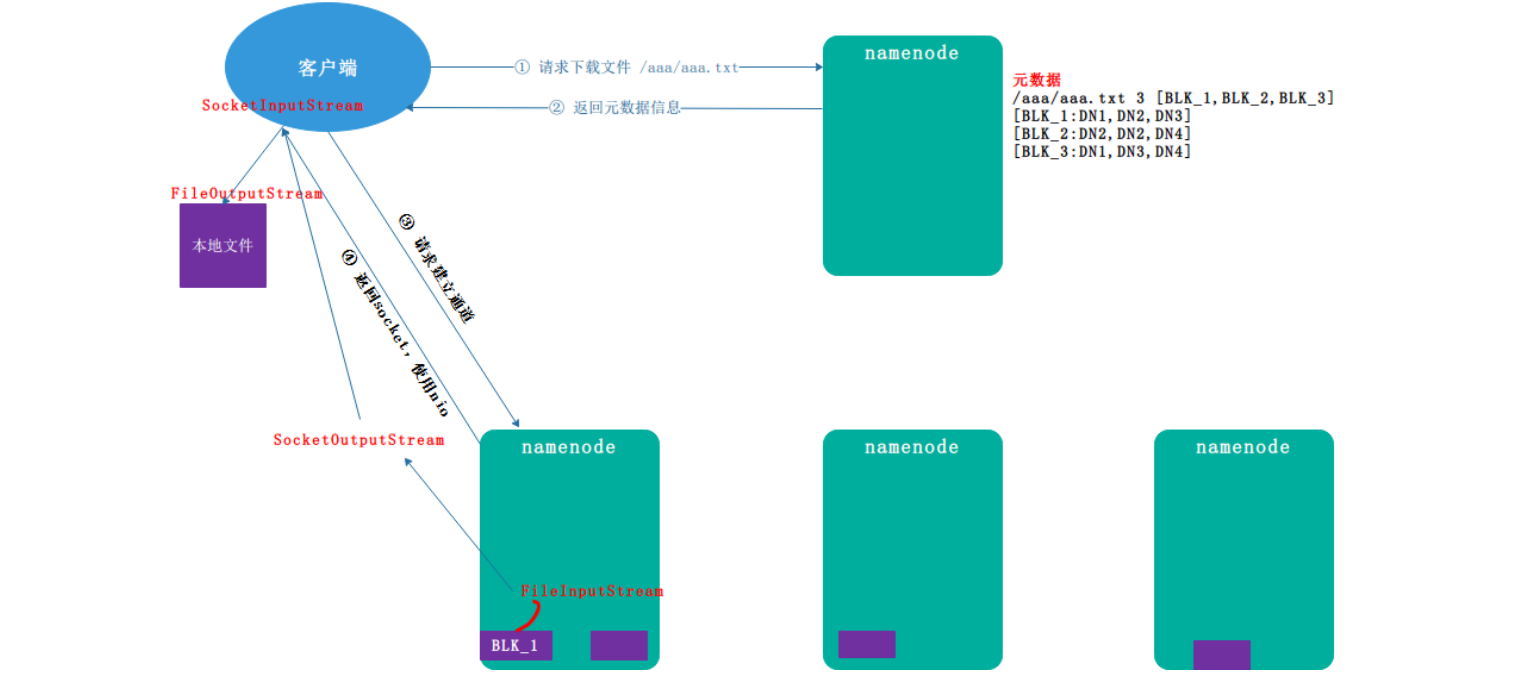
a. 客户端通过 Distributed FileSystem 向 namenode 请求下载文件, 跟 namenode 通信查询元数据,找到文件块所在的datanode服务器.
b. 挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流.
c. datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验).
d. 客户端以packet为单位接收,现在本地缓存,然后写入目标文件.
4.HDFS的三个节点
a. NameNode:HDFS的守护进程,用来管理文件系统的命名空间,负责记录文件是如何分割数据块,以及这些数据块分别被存储到那些数据节点上,他的主要功能时对内存及IO进行集中管理。
b. DataNode:文件系统的工作节点,根据需要存储和检索数据块,并且定期向NameNode发送他们所存储的块的列表。
c. SecondaryNameNode:辅助后台程序,与NameNode进行通信,以便定期保存HDFS元数据的快照。
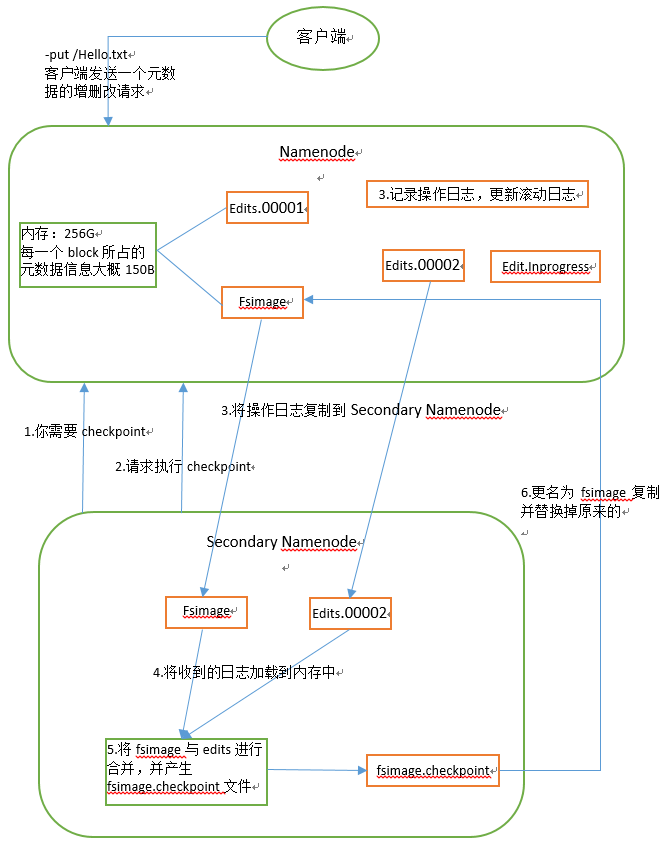
5.NameNode和SecondaryNameNode原理

若有收获,就点个赞吧
0 人点赞
