最小生成树的概念
- 连通图:在无向图中,若任意两个顶点 Vi 与 Vj 都有路径相通,则称该无向图为连通图
- 强连通图:在有向图中,若任意两个顶点 Vi 与 Vj 都有路径相通,则称该有向图为强连通图
- 连通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权,权代表着连接连个顶点的代价,二这种连通图叫做连通网
- 生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环
- 最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树

求最小生成树有两个著名的算法:Prim算法和Kruskal算法。前者以“最小点”求最小生成树,后者以“最小边”求最小生成树,后续会详细介绍。
参考文章: https://blog.csdn.net/luoshixian099/article/details/51908175
Prim算法
此算法可以称为“加点法”,每次迭代选择代价最小的边对应的点,加入到最小生成树中。算法从某一个顶点s开始,逐渐长大覆盖整个连通网的所有顶点。其算法实现思路如下:
- 图的所有顶点集合为V,选择图中某一个顶点s,初始令集合u={ s },v=V−u
- 在两个集合 u,v 能够组成的边中,选择一条代价最小的边(u0,v0),加入到最小生成树中,并把v0并入到集合u中
- 重复上述步骤,直到最小生成树有n-1条边或者n个顶点为止
由于不断向集合u中加点,所以最小代价边必须同步更新;需要建立一个辅助数组closedge,用来维护集合v中每个顶点与集合u中最小代价边信息:
struct{char vertexData //表示u中顶点信息UINT lowestcost //最小代价}closedge[vexCounts]

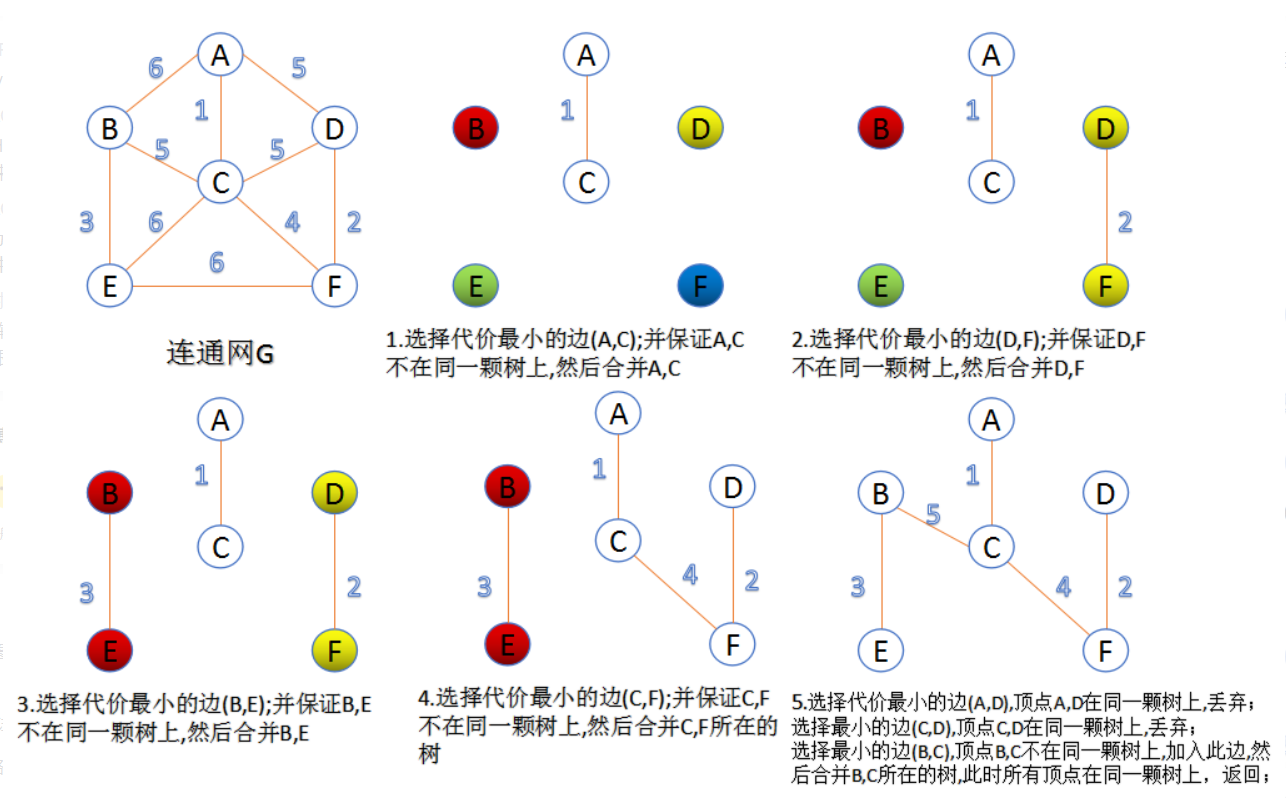
Kruskal算法
此算法可以称为“加边法”,初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里。其算法思路如下:
- 把图中的所有边按代价从小到大排序
- 把图中的n个顶点看成独立的n棵树组成的森林
- 按权值从小到大选择边,所选的边连接的两个顶点ui和vi应属于两颗不同的树,则成为最小生成树的一条边,并将这两颗树合并作为一颗树
- 重复(3),直到所有顶点都在一颗树内或者有n-1条边为止
Prim和Kruskal算法的对比
Prim算法是依赖于点的算法,它的基本原理是从当前点寻找一个离自己(集合)最近的点然后把这个点拉到自己家来,同时输出一条边,并且刷新到其他点的路径长度,俗称刷表。根据Prim算法的特性可以得知,它很适合于点密集的图。通常在教材中,对Prim算法进行介绍的标程都采用了邻接矩阵的储存结构。这种储存方法空间复杂度N^2,时间复杂度N^2。对于稍微稀疏一点的图,其实我们更适合采用邻接表的储存方式,可以节省空间,并在一定条件下节省时间。
Kruskal算法是依赖边的算法,基本原理是将边集数组排序,然后通过维护一个并查集来分清楚并进来的点和没并进来的点,依次按从小到大的顺序遍历边集数组,如果这条边对应的两个顶点不在一个集合内,就输出这条边,并合并这两个点。根据Kruskal算法的特性可得,在边越少的情况下,Kruskal算法相对Prim算法的优势就越大。同时,因为边集数组便于维护,所以Kruskal在数据维护方面也较为简单,不像邻接表那样复杂。从一定意义上来说,Kruskal算法的速度与点数无关,因此对于稀疏图可以采用Kruskal算法。
[

若有收获,就点个赞吧
0 人点赞
