排序的基本概念
排序概念
简单来说,排序就是将无序的记录序列按照关键字调整为有序记录序列的一种操作。在排序问题中,通常将数据元素称为记录,显然我们输入的是一个无序的记录集合,输出的是一个有序的记录集合。所以说,可以将排序看成是线性表的一种操作。上面提到的关键字可以不止一个,但是多个关键字的排序最终都是可以转化为单个关键字的排序。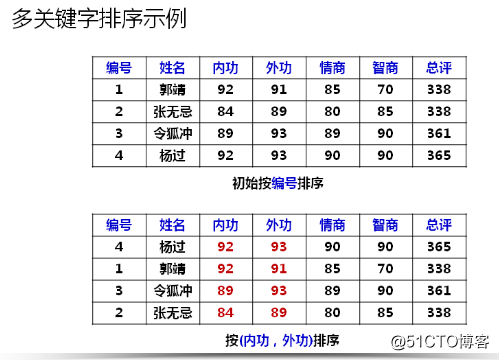
排序的稳定性
由于排序不仅是针对主关键字,那么对于次关键字,因为待排序的记录序列中可能存在两个或者两个以上的关键字相等的记录,排序结果可能会存在不唯一的情况,所以我们给出了稳定与不稳定排序的定义。假设Ki = Kj(1<=i<=n, 1<=j<=n, i != j),且在排序前的序列中 Ri 领先于 Rj (即i < j)。如果在排序后仍然领先,则称所用的排序方法是稳定的;反之,若可能使得排序后的序列中 Rj 领先于 Ri,则称使用的排序方法是不稳定的。
比如排序前张三在赵六前面,稳定排序后,张三还是要在赵六前面,而经过不稳定排序后,赵六居然排在了张三的前面。
排序的分类
内排序和外排序
根据在排序过程中待排序的记录是否全部被放置在内存中,排序分为:内排序和外排序。内排序是在排序整个过程中,待排序的所有记录全部被放置在内存中。外排序是由于排序的记录个数太多导致不能同时放置在内存,整个排序过程需要在内外存之间多次交换数据才能进行。我们主要讨论的是内排序,对于内排序,排序算法的性能主要受到3个方面的影响:
- 时间性能:在内排序中,主要进行两种操作:比较和移动。比较指关键字之间的比较,这是要做排序最起码的操作。移动指记录从一个位置移动到另一个位置,事实上,移动可以通过改变记录的储存方式来予以避免。总之,高效率的内排序算法应该具有尽可能少的关键字比较次数和尽可能少的记录移动次数。
- 辅助空间:评价排序算法的另一个主要标准是执行算法所需要的辅助储存空间。辅助储存空间是在执行算法过程中除了存放待排序所占用的储存空间之外所需要的其他储存空间。
- 算法的复杂性:这里指的是算法本身的复杂度(数学上的复杂性),而不是指算法的时间复杂度。显然算法过于复杂也会影响排序的性能。
内排序分类
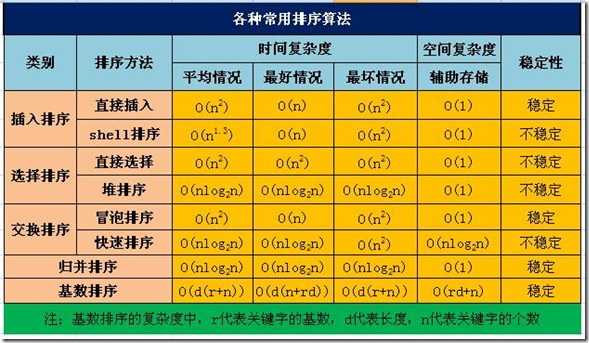
根据排序过程所用到的策略不同,可以将内排序分为5类:交换排序、选择排序、插入排序、归并排序、基数排序。交换排序
交换排序是对无序区中记录的关键字两两进行比较,若逆序则交换,直到关键字之间不存在逆序为止。交换排序的两个经典算法代表就是:冒泡排序和快速排序。选择排序
选择排序是在无序区中选出关键字最小的记录,置于有序区的最后,直到全部记录有序。选择排序的两个经典算法:直接选择排序和堆排序。插入排序
插入排序是将无序区中的一个记录插入到有序区,使得有序区的长度加1,直到全部记录有序,插入排序的两个经典算法:直接插入排序和希尔排序。归并排序
归并排序是不断将两个或两个以上有序区合并成一个有序区,直到全部记录有序。基数排序
基数排序(Radix Sort)属于分配式排序,又称”桶子法”(Bucket Sort或Bin Sort),将要排序的元素分配到某些”桶”中,以达到排序的作用。基数排序属于稳定的排序,其时间复杂度为nlog(r)m (其中r为的采取的基数,m为堆数),基数排序的效率有时候高于其它比较性排序。
约定排序要用到的结构和函数
为了方便后面的讲解,我们先提供一个用于排序的顺序表结构,此结构也将用于之后我们要讲的所有排序算法:
#define MAXSIZE 10 //用于要排序数组个数的最大值,可自行更改大小typedef struct {int r[MAXSIZE + 1]; //用于存储要排序数组,r[0]用作临时变量int length; //被排序的顺序表的长度}SqList;
另外最常用的就是交换了,我们也写成一个函数,方便使用:
void swap(SqList *L, int i, int j){int temp = L->r[i];L->r[i] = L->r[j];L->r[j] = temp;}

若有收获,就点个赞吧
0 人点赞
