遍历二叉树是指从二叉树的根结点出发,按照某种次序访问二叉树的所有结点,使得每个结点被且仅被访问一次。这里说的访问可以是结点的输出、比较、更新、查看,由实际应用来决定。
递归遍历
先序递归遍历
先序遍历是指按照“根节点->左子树->右子树”的次序遍历(根左右)二叉树,可以采用递归来实现先序遍历:
Status PreOrderTraverse(BiTree T){if(T==NULL) return OK;//visit函数是定义的访问二叉树结点函数,比如打印访问的结点的数据域visit(T);PreOrderTraverse(T->lchild);PreOrderTraverse(T->rchild);}
中序递归遍历
中序遍历是指按照“左子树->根子树->右子树”的次序遍历(左根右)二叉树,可以采用递归来实现遍历:
Status MidOrderTraverse(BiTree T){if(T==NULL) return OK;MidOrderTraverse(T->lchild);//visit函数是定义的访问二叉树结点函数,比如打印访问的结点的数据域visit(T);MidOrderTraverse(T->rchild);}
后序递归遍历
后序遍历是指按照“左子树->右子树->根子树”的次序遍历(左右根)二叉树,可以采用递归来实现遍历:
Status PostOrderTraverse(BiTree T){if(T==NULL) return OK;PostOrderTraverse(T->lchild);PostOrderTraverse(T->rchild);//visit函数是定义的访问二叉树结点函数,比如打印访问的结点的数据域visit(T);}
三者对比
可以看到,上面三种递归遍历方法除了访问当前根结点的次序不一样,这三种遍历算法其实是完全相同的。
先序:遍历到一个结点,立即访问该结点,然后继续遍历其左右子树。
中序:遍历到一个结点,先将其暂存,先访问左子树再访问该结点,最后访问右子树。
后序:遍历到一个结点,先将其缓存,先后访问左右子树,最后再访问该结点。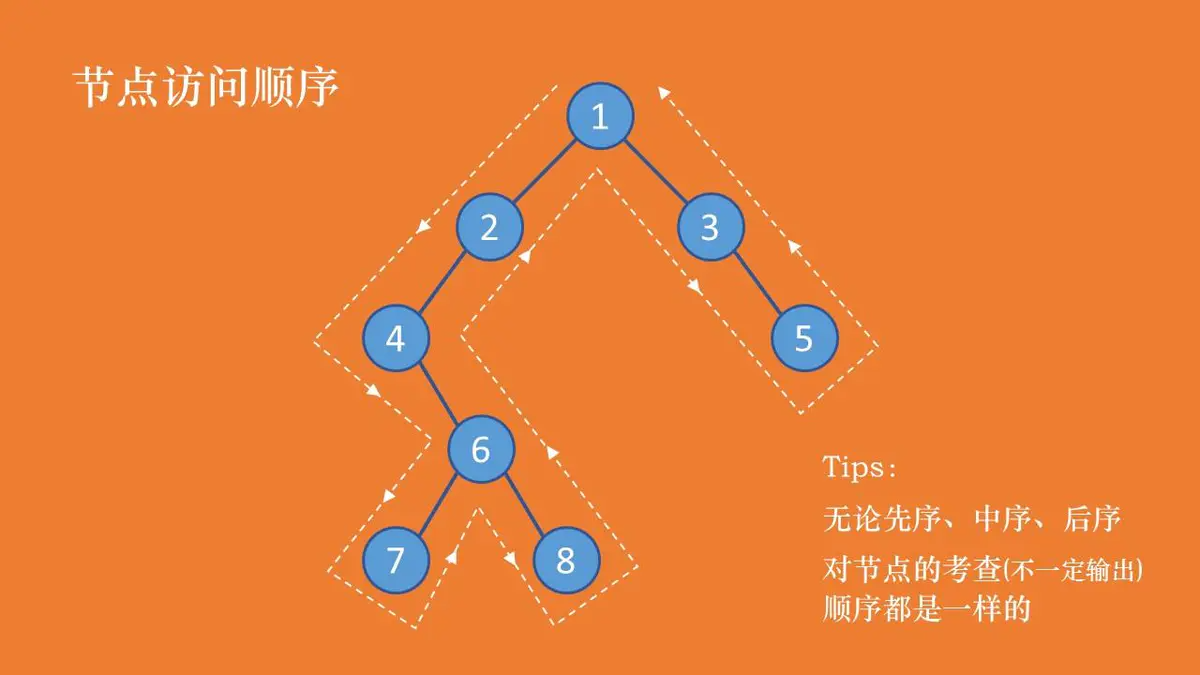
先序:1 2 4 6 7 8 3 5
中序:4 7 6 8 2 1 3 5
后序:7 8 6 4 2 5 3 1
非递归遍历
借助栈
先序非递归遍历
先序非递归遍历的实现思路和先序递归遍历的思路是一样的:我们只需要在遍历完左子树之后,找到根结点即可,然后继续遍历右子树。递归遍历是在遍历完左子树后会返回根节点的地址,然后继续遍历右子树;而非递归遍历则可以借助栈的先进后出的特点来存储根节点的地址,访问到一个根结点就把这个根结点的地址入栈,遍历完这个根结点的左右子树后再出栈。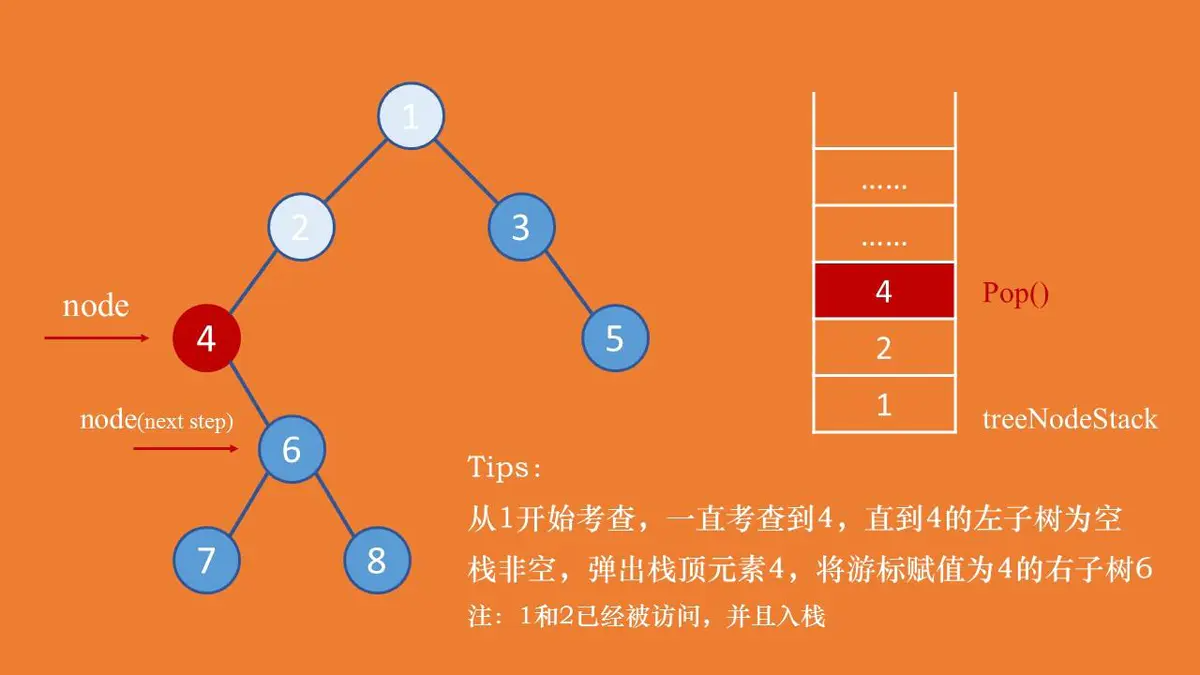
算法实现:
Status PreOrderTraverse(BiTree T,SqStack &S){if(T==NULL) return OK;BiTree node=T;//只要当前结点不是null或者栈不为null,满足其一即可进入循环while(node!=NULL || isNotEmpy(S)){//只要node不可null,则一直访问其左子树while(node!=NULL){//visit函数是定义的访问二叉树结点函数,比如打印访问的结点的数据域visit(node);//将根节点(当前子树的根节点)压入栈顶push(S,node);//node指向当前node的左孩子node=node->lchild;}//如果S不是空栈if(isNotEmpy(S)){//取出栈顶元素,赋值给nodenode=pop(S);//node指向当前node的右孩子node=node->rchild;}}}
中序非递归遍历
中序非递归遍历和前面的先序遍历的思路都是一样的,只是访问到当前结点时,不直接访问,而是等该结点出栈的时候再访问,其余过程完全一样,实现算法如下:
Status MidOrderTraverse(BiTree T,SqStack &S){if(T==NULL) return OK;BiTree node=T;//只要当前结点不是null或者栈不为null,满足其一即可进入循环while(node!=NULL || isNotEmpy(S)){//只要node不可null,则一直访问其左子树while(node!=NULL){//将根节点T压入栈顶push(S,node);//node指向当前node的左孩子node=node->lchild;}//如果S不是空栈if(isNotEmpy(S)){//取出栈顶元素,赋值给nodenode=pop(S);//visit函数是定义访问二叉树结点的函数,如打印访问的结点的数据域visit(node);//node指向当前node的右孩子node=node->rchild;}}}
后序非递归遍历
后续的非递归遍历的实现思路和前序、后续不太一样,前序是遍历到节点访问之后入栈,中序是遍历到结点入栈,当出栈的时候在访问,两者都无需管右子树是否已经访问(因为右子树是一定未被访问的)。但是后序非递归遍历的访问取决于其左右子树是否已经都已经访问过了,左子树好确定是否已被访问,棘手的是怎么确定右子树的访问情况。因此我们需要设置一个游标lastVisit来确定当前结点(由栈弹出)的右子树是否已经被访问,如果右子树被访问了,那么一定有node->rchild=lastVisit,这时就可以访问该节点了。当然如果当前结点没有右子树,即node->rchild=null,那么可以直接访问当前结点。
实现思路: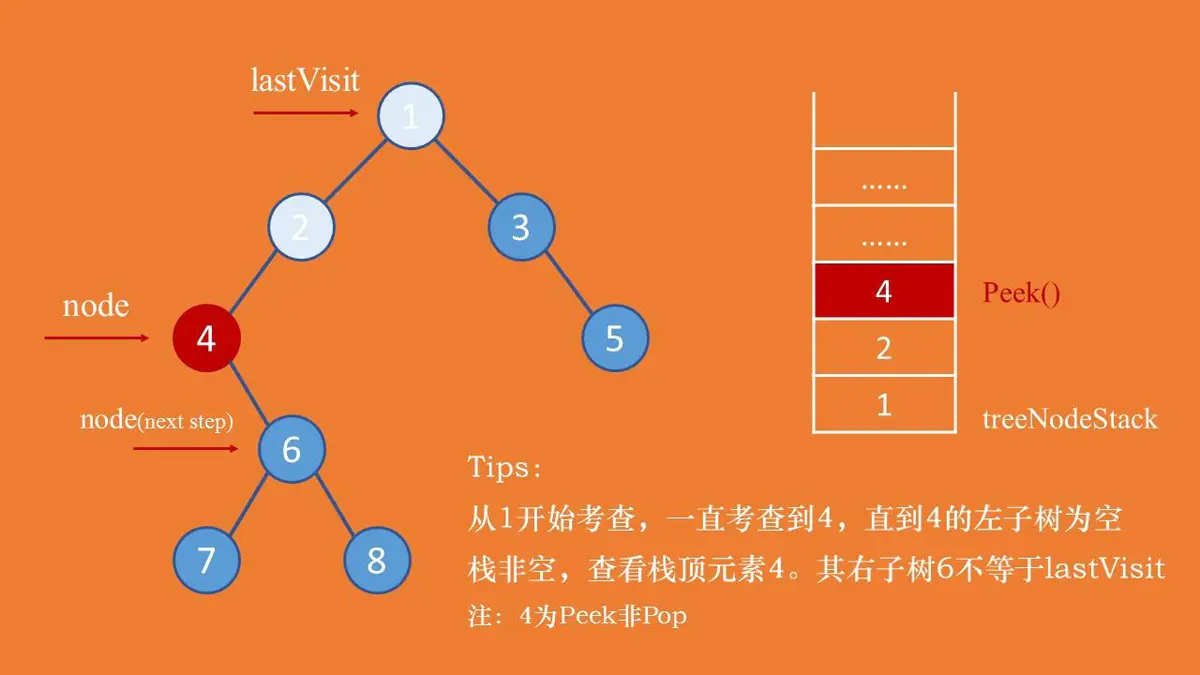
从结点1开始(但不能访问)考查,根据后序遍历的思想,会一直考察到结点4,其中1,2,4会被依次入栈,然后发现结点4的左子树为null,那就开始遍历4的右子树。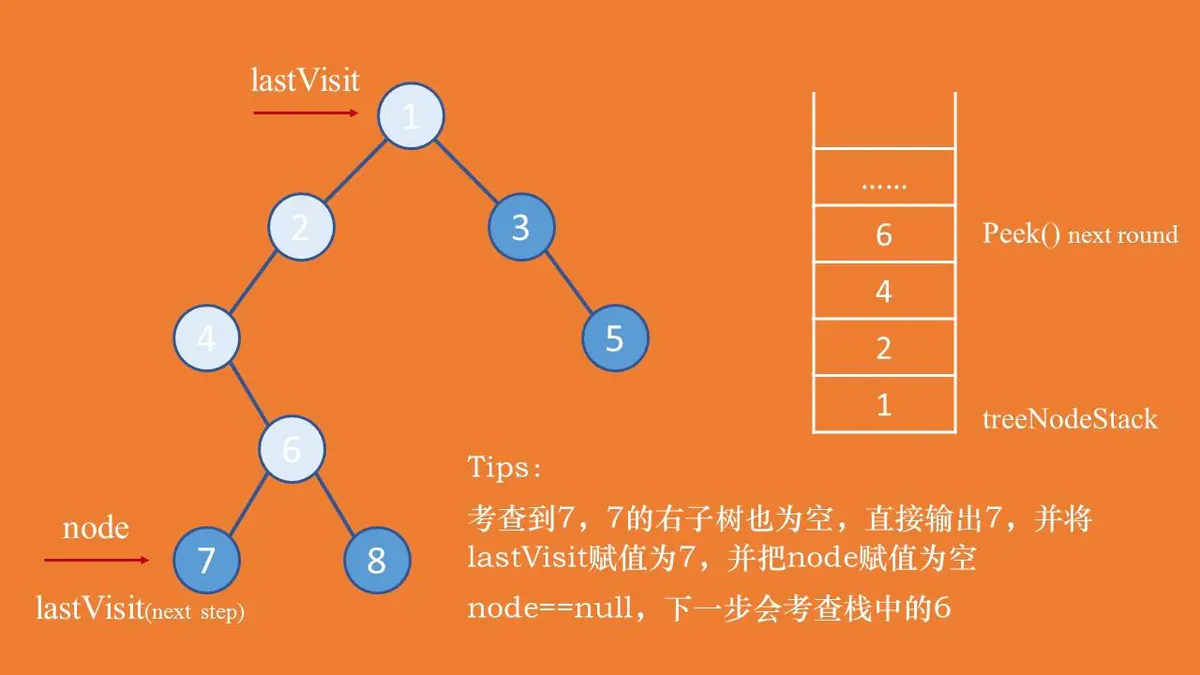
接着6被压入栈,之后考察6的左子树结点7,发现结点7的左右子树都是null,那么可以直接访问结点7了,lastVisit标记为结点7,并且node置为null。 接着就是需要考察6的右子树结点8(由于node=null且栈不为空,就需要取出栈顶元素,即结点6,注意是取出而不是出栈,发现此时的node->rchild!=lastVisit并且node->rchild!=null,那么就必须考察结点node->rchild),结点8的左右子树都是null,可以直接访问,访问之后lastVisit紧接着标记为8。此时node=null,那须node就需要从栈顶取出元素,即此时的结点6,但是发现6->rchild=lastVisit,也就是说结点6的左右子树已经全部访问完成,现在就可以访问结点6了,然后lastVisit就标记为6。依次类推,就可以后序遍历整个二叉树了,其算法实现如下:
接着就是需要考察6的右子树结点8(由于node=null且栈不为空,就需要取出栈顶元素,即结点6,注意是取出而不是出栈,发现此时的node->rchild!=lastVisit并且node->rchild!=null,那么就必须考察结点node->rchild),结点8的左右子树都是null,可以直接访问,访问之后lastVisit紧接着标记为8。此时node=null,那须node就需要从栈顶取出元素,即此时的结点6,但是发现6->rchild=lastVisit,也就是说结点6的左右子树已经全部访问完成,现在就可以访问结点6了,然后lastVisit就标记为6。依次类推,就可以后序遍历整个二叉树了,其算法实现如下:
Status PostOrderTraverse(BiTree T,SqStack &S){if(T==NULL) return OK;BiTree node=T;//游标,代表上一个被访问的结点BiTree lastVisit;//只要当前结点不是null或者栈不为null,满足其一即可进入循环while(node!=NULL || isNotEmpy(S)){while(node!=NULL){//把未访问的node入栈push(S,node);node=node->lchild;}//如果没有左子树了(此时node=null),就开始考察右子树node=getFirstElem(S); //获取栈顶元素,并非出栈//如果右子树为空或lastVisit等于右子树的结点,说明该节点已经可以访问了if(node->rchild==null || node->rchild==lastVitit){//访问nodevisit(node);//刷新lastVisitlastVisit=node;//弹出栈顶元素pop(s);//node置为null,避免再次考察node的左子树(前面已经考察过了)node=null;}else{//如果还不能访问当前结点就继续考察其右子树node=node->rchild;}}}
借助队列
二叉树的遍历还可以借助队列来遍历,这种访问方式也叫做二叉树的层次遍历,即按照层次从小到大且每层从左到右的顺序依次访问结点。如果二叉树采用顺序存储结构,由于底层数组就是按照层次从小到大、每层从左到右的顺序存储结点的,因此顺序访问数组的每一个就是层次遍历二叉树了。但是对于采用链式存储结构的二叉树,就没有这么简单了,这时我们就需要借助队列先进先出的特点来辅助我们层次遍历二叉树,其算法思路:
- 将根结点入队并访问
- 当队头不为空时,重复执行这些操作:队头元素出队->若出队元素有左孩子,则访问其左孩子并且入队->若出队元素有右孩子,则访问其右孩子并且入队
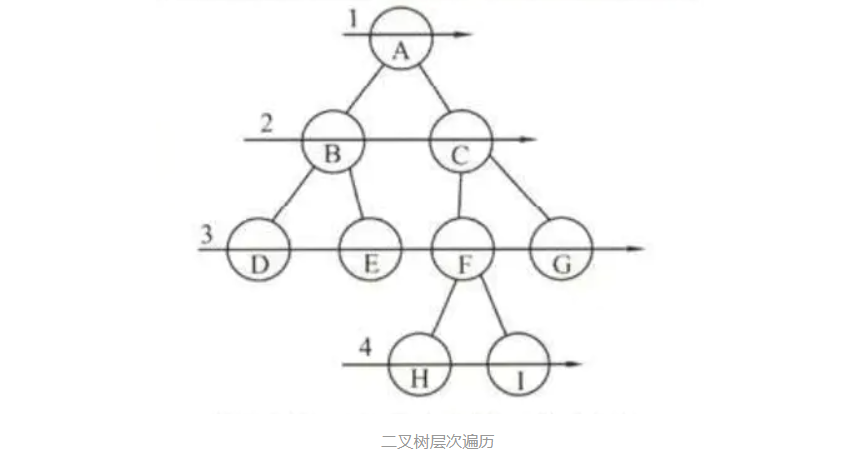
实现算法如下:
Status LevelOrderTraverse(BiTree T,SqQueue &S){if(T==NULL) return OK;//根结点入队并访问enSqQueue(S,T);visit(T);//只要队列存在队头元素就进入循环while(isNotEmpy(S)){//队首元素出队BiTress node=pop(S);//如果出队元素的左孩子不为空if(node->lchild){//访问出队元素的左孩子visit(node->lchild);//出队元素的左孩子入队enSqQueue(S,node->lchild);}//如果出对元素的右孩子不为空if(node->rchild){//访问出队元素的左孩子visit(node->rchild);//出队元素的左孩子入队enSqQueue(S,node->rchild);}}}
二叉树遍历的应用
销毁二叉树
二叉树的销毁必须逐个释放所有结点,因此必须遍历整个二叉树。在二叉树的四种遍历方式中(先序、中序、后序、层序),后序遍历是可以达到释放所有结点的目的,其它三种方法不行的原因是当根释放的时候,它的子树还没有完全释放。根结点释放后,如果子树还没有释放,那么这些子树明显是不能再被释放了。算法实现如下:
void DestroyBiTree(BiTree &T){if(T!=NULL){//销毁左子树DestroyBiTree(T->lchild);//销毁右子树DestroyBiTree(T->rchild);free(T);}}
求二叉树深度
根结点独占一层,那么我们只需要计算出左右子树深度的值,然后把二者的最大值加上1即可。在遍历二叉树的时候,我们不知道有多少层,但是我们可以应用逆向思维,把最后一层看成第一层,这样就可以利用递归中回溯的原理求出深度了。算法实现如下:
int BiTreeDepth(BiTree &T){if(T==NULL) return 0;//左子树深度depthLeft=BiTreeDepth(T->lchild);//右子树深度depthRight=BiTreeDepth(T->rchild);//返回左子树/右子树中的最大值再加上1return depthLeft>depehRight?(depthLeft+1):(depehRight+1);}
求二叉树的叶子结点数
叶子结点就是没有子树的(即度数为0)的结点,其实就是再遍历二叉树的过程中判断当前结点的度数是否为0,有则计数器加1,没有则计数器不变。算法实现如下:
//传入的是count的内存地址,因此可以在函数里面直接修改count的值void CountLeaf(BiTree,int &count){if(T==NULL) count=0;if(T->lchild==NULL&&T->rchild->rchild==NULL) count++;CountLeaf(T->lchild,count);CountLeaf(T->rchild,count);}
构造二叉树
二叉树的构造应当选用二叉树的先序(或层序)遍历思想,从根结点开始构造,然后依次构造左右子树。数组array代表二叉树的子树,如果标号为”#”表示为空子树,构造一个如图所示的二叉树,算法实现如下: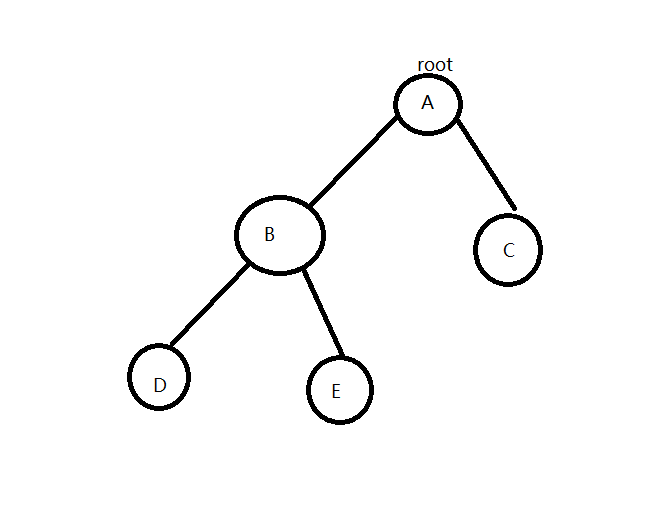
首先需要确定先序构造的顺序,根据先序遍历的实现思路确定访问(即构造)次序如下,其中“#”代表空子树:
char array[]={A,B,D,#,#,E,#,#,C,#,#};
确定构造次序之后,就可以开始构造二叉树了:
//其中array[]是构造次序,i是次序位标,递归调用的第0层必须传0BiTree CreateBiTree(char *array[],int &i){BiTree T;char ch=array[i++];//空树if('#'==ch) T=NULL;//MakeBiTree是用于构造二叉树结点的函数,指针域赋值为空,在后面代码指定了指针域T=MakeBiTree(ch,NULL,NULL);//构造左子树T->lchild=CreateBiTree(array,i);//构造右子树T->rchild=CreateBiTree(array,i);}

若有收获,就点个赞吧
0 人点赞
