一. 简介
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,它建立在全文搜索引擎 Apache Lucene™ 的基础上. 当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
• 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
• 实时分析的分布式搜索引擎。
• 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{"name" : "John","sex" : "Male","age" : 25,"birthDate": "1990/05/01","about" : "I love to go rock climbing","interests": [ "sports", "music" ]}
用MySQL这样的数据库存储就会容易想到建立一张User表,有balabala的字段等,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引 ⇒ 类型 ⇒ 文档 ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。
Elasticsearch的交互,可以使用Java API,也可以直接使用HTTP的Restful API方式,比如我们打算插入一条记录,可以简单发送一个HTTP的请求:
{"name" : "John","sex" : "Male","age" : 25,"birthDate": "1990/05/01","about" : "I love to go rock climbing","interests": [ "sports", "music" ]}
更新,查询也是类似这样的操作,具体操作手册可以参见Elasticsearch权威指南
二. 核心概念
集群(Cluster):ES集群是一个或多个节点的集合,它们共同存储了整个数据集,并提供了联合索引以及可跨所有节点的搜索能力。多节点组成的集群拥有冗余能力,它可以在一个或几个节点出现故障时保证服务的整体可用性。集群靠其独有的名称进行标识,默认名称为“elasticsearch”。节点靠其集群名称来决定加入哪个ES集群,一个节点只能属一个集群。
节点(node):一个节点是一个逻辑上独立的服务,可以存储数据,并参与集群的索引和搜索功能, 一个节点也有唯一的名字,群集通过节点名称进行管理和通信.
master节点:主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。对于大型的生产集群来说,推荐使用一个专门的主节点来控制集群,该节点将不处理任何用户请求。
data节点:持有数据和倒排索引。
客户端节点:它既不能保持数据也不能成为主节点,该节点可以响应用户的情况,把相关操作发送到其他节点;客户端节点会将客户端请求路由到集群中合适的分片上。对于读请求来说,协调节点每次会选择不同的分片处理请求,以实现负载均衡。
部落节点:部落节点可以跨越多个集群,它可以接收每个集群的状态,然后合并成一个全局集群的状态,它可以读写所有节点上的数据。
索引(Index): ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。
文档类型(Type):类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”。
文档(Document):文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。相当于数据库的“记录”
Mapping: 相当于数据库中的schema,用来约束字段的类型,不过 Elasticsearch 的 mapping 可以自动根据数据创建。
ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。
分片(shard) :ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。
每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。
Shard有两种类型:primary和replica,即主shard及副本shard。
Primary shard用于文档存储,每个新的索引会自动创建5个Primary shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其Primary shard的数量将不可更改。
Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。
每个Primary shard默认配置了一个Replica shard,但也可以配置多个,且其数量可动态更改。ES会根据需要自动增加或减少这些Replica shard的数量。ES集群可由多个节点组成,各Shard分布式地存储于这些节点上。ES可自动在节点间按需要移动shard,例如增加节点或节点故障时。简而言之,分片实现了集群的分布式存储,而副本实现了其分布式处理及冗余功能。
三. 创建索引
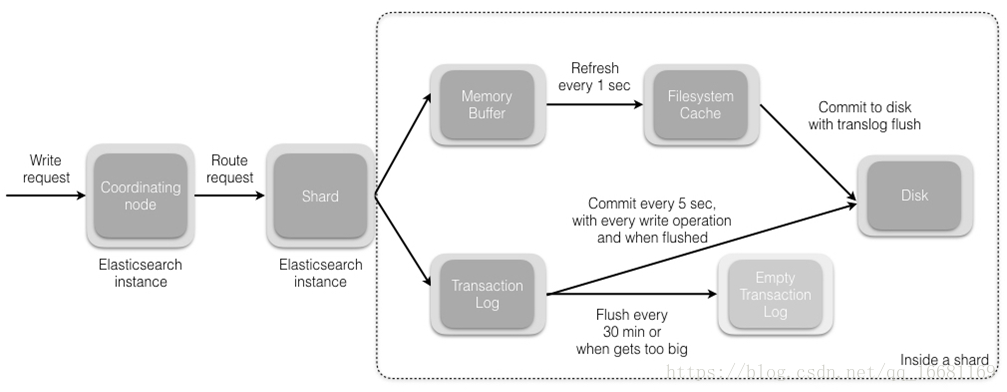
ES的写操作分为两类,一类是涉及到路由变更的索引创建和删除(简称为索引的写入),另一类是基于文档的创建、更新和删除(简称为文档的写入)。
下面单独来进行介绍:
索引的写入
无论是索引的创建还是删除,都必须在master上进行。因此,如果写入的请求是发到了非master节点,该节点会讲对应的创建或者删除的请求转发给master,master会创建并修改元数据和路由信息,并将对应的修改同步到其他的候选的master机器上,至少需要需要一半以上的候选master返回后才算写入成功。文档的写入
文档的写入的前提是所有的写入都必须先发送到主分片上,大致的步骤为:
a. 文档写入请求发送到任意的一个节点(如果没有指定路由/协调节点,请求的节点扮演路由节点的角色)
b. 节点根据shard = hash(routing) % number_of_primary_shards确定数据所在的分片以及根据元数据确认主分片是在哪台机器
c. 在主分片上执行写入操作和translog写入操作,并且将请求发送到副本上进行写入和translog写入
d. 当分片所在的节点接收到来自协调节点的请求后,会将请求写入到Memory Buffer,然后定时(默认是每隔1秒)写入到Filesystem Cache,这个从Momery Buffer到Filesystem Cache的过程就叫做refresh,内容将被写到文件系统缓存的一个新段(segment)上,虽然这个段并没有被同步(fsync),但它是开放的,内容可以被搜索到。默认是同步操作,必须主分片和副本分片都些成功才返回结果,节点3将向协调节点(节点1)报告成功,节点1向请求客户端报告写入成功。也可以人为调整为异步操作,不过会有数据安全性问题。
当然在某些情况下,存在Momery Buffer和Filesystem Cache的数据可能会丢失,ES是通过translog的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到translog中,当Filesystem cache中的数据写入到磁盘中时,才会清除掉,这个过程叫做flush;在flush过程中,内存中的缓冲将被清除,内容被写入一个新段,段的fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的translog将被删除并开始一个新的translog。
flush触发的时机是定时触发(默认30分钟)或者translog变得太大(默认为512M)时。
ES如何做到实时检索?
由于在buffer中的索引片先同步到文件系统缓存,再刷写到磁盘,因此在检索时可以直接检索文件系统缓存,保证了实时性。这一步刷到文件系统缓存的步骤,在 Elasticsearch 中,是默认设置为 1 秒间隔的,对于大多数应用来说,几乎就相当于是实时可搜索了。不过对于 ELK 的日志场景来说,并不需要如此高的实时性,而是需要更快的写入性能。我们可以通过 /_settings接口或者定制 template 的方式,加大 refresh_interval 参数。
当segment从文件系统缓存同步到磁盘时发生了错误怎么办? 数据会不会丢失?
由于Elasticsearch 在把数据写入到内存 buffer 的同时,其实还另外记录了一个 translog日志,如果在这期间故障发生时,Elasticsearch会从commit位置开始,恢复整个translog文件中的记录,保证数据的一致性。
等到真正把 segment 刷到磁盘,且 commit 文件进行更新的时候, translog 文件才清空。这一步,叫做flush。同样,Elasticsearch 也提供了 /_flush 接口。
索引数据的一致性通过 translog 保证,那么 translog 文件自己呢?
Elasticsearch 2.0 以后为了保证不丢失数据,每次 index、bulk、delete、update 完成的时候,一定触发刷新translog 到磁盘上,才给请求返回 200 OK。这个改变在提高数据安全性的同时当然也降低了一点性能.
四. 检索文档
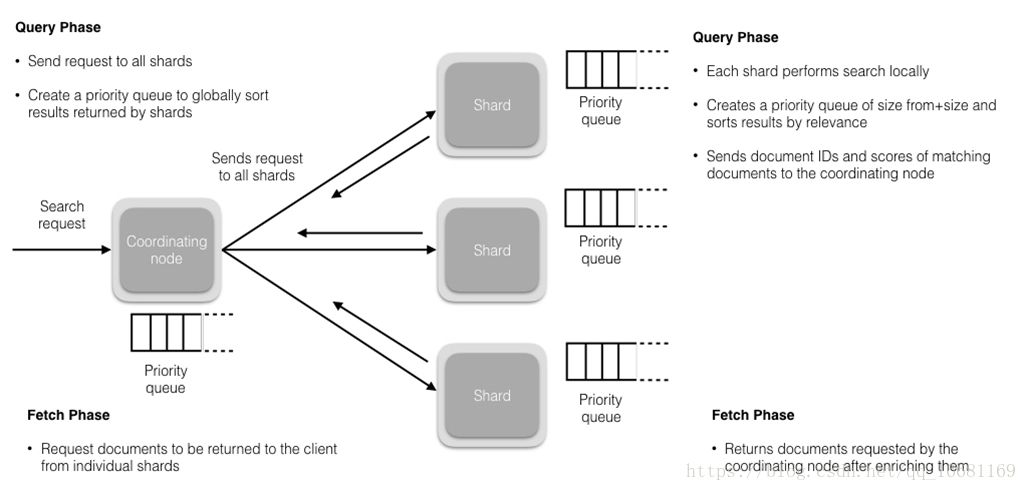
搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
query阶段的目的:定位到位置,但不取。
步骤拆解如下:
- 假设一个索引数据有5主+1副本 共10分片,一次请求会命中(主或者副本分片中)的一个。
- 每个分片在本地进行查询,结果返回到本地有序的优先队列中。
- 2步骤的结果发送到协调节点,协调节点产生一个全局的排序列表。
路由节点获取所有文档,返回给客户端。在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
fetch阶段的目的:取数据。
如果查询只涉及到1个分片,查询的分片所在的机器返回查询结果到初始请求的节点,初始请求节点再将数据返回给业务。而如果查询涉及到多个分片,初始节点就会将请发送给多个分片并发查询,此时查询的分片所在的机器返回查询结果到初始请求的节点后,初始节点还需要再进行结果的合并。初始节点将合并后的数据返回个业务。
补充:Query Then Fetch的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch增加了一个预查询的处理,询问Term和Document frequency,这个评分更准确,但是性能会变差。
搜索相关性
相关性是由搜索结果中Elasticsearch打给每个文档的得分决定的。默认使用的排序算法是tf/idf(词频/逆文档频率)。词频衡量了一个词项在文档中出现的次数 (频率越高 == 相关性越高),逆文档频率衡量了词项在全部索引中出现的频率,是一个索引中文档总数的百分比(频率越高 == 相关性越低)。最后的得分是tf-idf得分与其他因子比如(短语查询中的)词项接近度、(模糊查询中的)词项相似度等的组合
五. 更新删除索引
删除和更新也都是写操作。但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更。那么,该如何删除和更新文档呢?
磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并(我们将在本系列接下来的文章中讲到)时,在.del文件中被标记为删除的文档将不会被写入新段。
接下来我们看更新是如何工作的。在新的文档被创建时,Elasticsearch会为该文档指定一个版本号。当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
物理删除索引:当索引数据不断增长时,对应的segment也会不断的增多,查询性能可能就会下降。因此,Elasticsearch会触发segment合并的线程,把很多小的segment合并成更大的segment,然后删除小的segment,当这些标记为删除的segment不会被复制到新的索引段中。
六. Elasticseach查询
Elasticseach查询分为两种,结构化查询和全文查询。尽管统一称之为query DSL,事实上Elasticsearch中存在两种DSL:查询DSL(query DSL)和过滤DSL(filter DSL)。
查询子句和过滤子句的自然属性非常相近,但在使用目的上略有区别。简单来讲,当执行full-text查询或查询结果依赖于相关度分值时应该使用查询DSL,当执行精确值(extac-value)查询或查询结果仅有“yes”或“no”两种结果时应该使用过滤DSL。
Filter DSL计算及过滤速度较快,且适于缓存,因此可有效提升后续查询请求的执行速度。
而query DSL不仅要查找匹配的文档,还需要计算每个文件的相关度分值,因此为更重量级的查询,其查询结果不会被缓存。不过,得益于倒排索引,一个仅返回少量文档的简单query或许比一个跨数百万文档的filter执行起来并得显得更慢。
Elasticsearch支持许多的query和filter,但最常用的也不过几种:
Filter DSL中常见的有term Filter、terms Filter、range Filter、exists and missing Filters和bool Filter。
而Query DSL中常见的有match_all、match 、multi_match及bool Query。鉴于时间关系,这里不再细述,朋友们可参考官方文档学习。
Queries用于查询上下文,而filters用于过滤上下文,不过,Elasticsearch的API也支持此二者合并运行。组合查询可用于合并查询子句,组合过滤用于合并过滤子句,然而,Elasticsearch的使用习惯中,也常会把filter用于query上进行过滤。不过,很少有机会需要把query用于filter上的。
结构化搜索
结构化搜索是指查询包含内部结构的数据。日期,时间,和数字都是结构化的:它们有明确的格式给你执行逻辑操作。一般包括比较数字或日期的范围,或确定两个值哪个大。文本也可以被结构化。一包蜡笔有不同的颜色:红色,绿色,蓝色。一篇博客可能被打上 分布式 和 搜索的标签。电子商务产品有商品统一代码(UPCs) 或其他有着严格格式的标识。
通过结构化搜索,你的查询结果始终是 是或非;是否应该属于集合。结构化搜索不关心文档的相关性或分数,它只是简单的包含或排除文档。
这必须是有意义的逻辑,一个数字不能比同一个范围中的其他数字 更多。它只能包含在一个范围中 —— 或不在其中。类似的,对于结构化文本,一个值必须相等或不等。这里没有 更匹配 的概念。
全文搜索
所谓的全文搜索查询通常是指在给定的文本域内部搜索指定的关键字,但搜索操作该需要真正理解查询者的目的,例如:
(1) 搜索“UK”应该返回包含“United Kingdom”的相关文档;
(2) 搜索“jump”应该返回包含“JUMP”、“jumped”、“jumps”、“jumping”甚至是“leap”的文档;
为了完成此类全文搜域的搜索,ES必须首先分析文本并将其构建成为倒排索引(inverted index),倒排索引由各文档中出现的单词列表组成,列表中的各单词不能重复且需要指向其所在的各文档。
因此,为了创建倒排索引,需要先将各文档中域的值切分为独立的单词(也称为term或token),而后将之创建为一个无重复的有序单词列表。这个过程称之为“分词(tokenization)”。
其次,为了完成此类full-text域的搜索,倒排索引中的数据还需进行“正规化(normalization)”为标准格式,才能评估其与用户搜索请求字符串的相似度。
这里的“分词”及“正规化”操作也称为“分析(analysis)”。
Analysis过程由两个步骤的操作组成:首先将文本切分为terms(词项)以适合构建倒排索引,其次将各terms正规化为标准形式以提升其“可搜索度”。这两个步骤由分析器(analyzers)完成。
一个分析器通常需要由三个组件构成:字符过滤器(Character filters)、分词器(Tokenizer)和分词过滤器(Token filters)组成。
字符过滤器:在文本被切割之前进行清理操作,例如移除HTML标签,将&替换为字符等;
分词器:将文本切分为独立的词项;简单的分词器通常是根据空白及标点符号进行切分;
分词过滤器:转换字符(如将大写转为小写)、移除词项(如移除a、an、of及the等)或者添加词项(例如,添加同义词);
Elasticsearch内置了许多字符过滤器、分词器和分词过滤器,用户可按需将它们组合成“自定义”的分析器。
七. 索引的优化原理
Elasticsearch最关键的就是提供强大的索引能力了, Elasticsearch索引的精髓:
一切设计都是为了提高搜索的性能。另一层意思:为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新。前面看到往Elasticsearch里插入一条记录,其实就是直接PUT一个json的对象,这个对象有多个fields,比如上面例子中的name, sex, age, about, interests,那么在插入这些数据到Elasticsearch的同时,Elasticsearch还默默1的为这些字段建立索引–倒排索引,因为Elasticsearch最核心功能是搜索。Elasticsearch全文检索主要用的是倒排索引。
什么是倒排索引?
继续上面的例子,假设有这么几条数据(为了简单,去掉about, interests这两个field):
| ID | Name | Age | Sex |
|---|---|---|---|
| 1 | Kate | 24 | Female |
| 2 | John | 24 | Male |
| 3 | Bill | 29 | Mal |
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name:
| Term | Posting List |
|---|---|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Age:
| Term | Posting List |
|---|---|
| 24 | [1,2] |
| 29 | 3 |
Sex:
| Term | Posting List |
|---|---|
| Female | 1 |
| Male | [2,3] |
Posting List
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
通过posting list这种索引方式似乎可以很快进行查找,比如要找age=24的同学,爱回答问题的小明马上就举手回答:我知道,id是1,2的同学。但是,如果这里有上千万的记录呢?如果是想通过name来查找呢?
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树: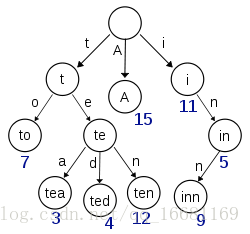
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。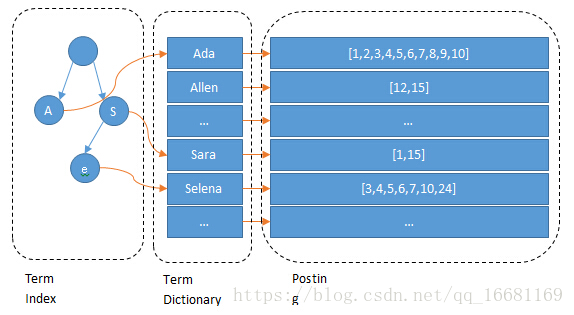
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。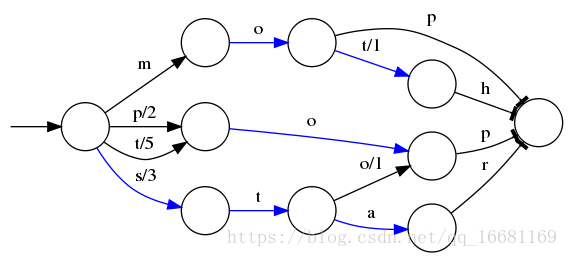
⭕️表示一种状态,–>表示状态的变化过程,上面的字母/数字表示状态变化和权重
将单词分成单个字母通过⭕️和–>表示出来,0权重不显示。如果⭕️后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。
FST以字节的方式存储所有的term,这种压缩方式可以有效的缩减存储空间,使得term index足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。
压缩技巧
Elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧。 小明喝完咖啡又举手了:”posting list不是已经只存储文档id了吗?还需要压缩?”
嗯,我们再看回最开始的例子,如果Elasticsearch需要对同学的性别进行索引(这时传统关系型数据库已经哭晕在厕所……),会怎样?如果有上千万个同学,而世界上只有男/女这样两个性别,每个posting list都会有至少百万个文档id。 Elasticsearch是如何有效的对这些文档id压缩的呢?
Frame Of Reference
增量编码压缩,将大数变小数,按字节存储
首先,Elasticsearch要求posting list是有序的(为了提高搜索的性能,再任性的要求也得满足),这样做的一个好处是方便压缩,看下面这个图例: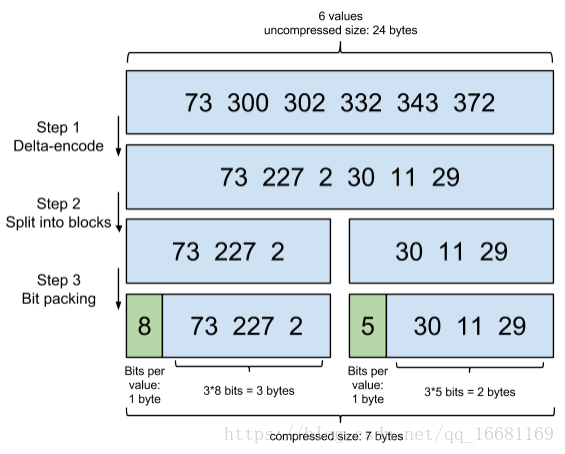
还是比较容易看出来这种压缩技巧的。原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储,而不是大大咧咧的尽管是2也是用int(4个字节)来存储。使用的是Roaring bitmaps原理。
说到Roaring bitmaps,就必须先从bitmap说起。Bitmap是一种数据结构,假设有某个posting list:
[1,3,4,7,10]
对应的bitmap就是:
[1,0,1,1,0,0,1,0,0,1]
非常直观,用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。
Bitmap的缺点是存储空间随着文档个数线性增长,Roaring bitmaps需要打破这个魔咒就一定要用到某些指数特性:
将posting list按照65535为界限分块,比如第一块所包含的文档id范围在065535之间,第二块的id范围是65536131071,以此类推。再用<商,余数>的组合表示每一组id,这样每组里的id范围都在0~65535内了,剩下的就好办了,既然每组id不会变得无限大,那么我们就可以通过最有效的方式对这里的id存储。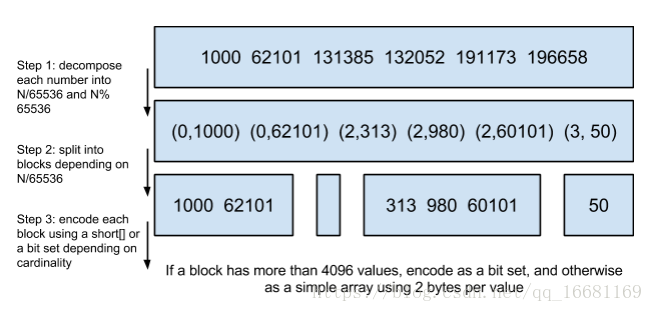
为什么是以65535为界限?程序员的世界里除了1024外,65535也是一个经典值,因为它=2^16-1,正好是用2个字节能表示的最大数,一个short的存储单位,注意到上图里的最后一行“If a block has more than 4096 values, encode as a bit set, and otherwise as a simple array using 2 bytes per value”,如果是大块,用节省点用bitset存,小块就豪爽点,2个字节我也不计较了,用一个short[]存着方便。
那为什么用4096来区分采用数组还是bitmap的阀值呢?
这个是从内存大小考虑的,当block块里元素超过4096后,用bitmap更剩空间: 采用bitmap需要的空间是恒定的: 65536/8 = 8192bytes 而如果采用short[],所需的空间是: 2*N(N为数组元素个数) N=4096刚好是边界:
联合索引
上面说了半天都是单field索引,如果多个field索引的联合查询,倒排索引如何满足快速查询的要求呢?
• 利用跳表(Skip list)的数据结构快速做“与”运算,或者
• 利用上面提到的bitset按位“与”
先看看跳表的数据结构: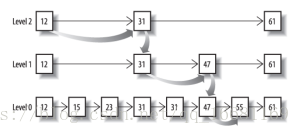
将一个有序链表level0,挑出其中几个元素到level1及level2,每个level越往上,选出来的指针元素越少,查找时依次从高level往低查找,比如55,先找到level2的31,再找到level1的47,最后找到55,一共3次查找,查找效率和2叉树的效率相当,但也是用了一定的空间冗余来换取的。
假设有下面三个posting list需要联合索引: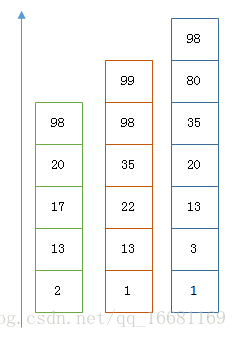
如果使用跳表,对最短的posting list中的每个id,逐个在另外两个posting list中查找看是否存在,最后得到交集的结果。
如果使用bitset,就很直观了,直接按位与,得到的结果就是最后的交集。
Elasticsearch的索引思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种高级的压缩算法,用及其苛刻的态度使用内存。
所以,对于使用Elasticsearch进行索引时需要注意:
• 不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
• 同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的
• 选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询
关于最后一点,个人认为有多个因素:
其中一个(也许不是最重要的)因素: 上面看到的压缩算法,都是对Posting list里的大量ID进行压缩的,那如果ID是顺序的,或者是有公共前缀等具有一定规律性的ID,压缩比会比较高;
另外一个因素: 可能是最影响查询性能的,应该是最后通过Posting list里的ID到磁盘中查找Document信息的那步,因为Elasticsearch是分Segment存储的,根据ID这个大范围的Term定位到Segment的效率直接影响了最后查询的性能,如果ID是有规律的,可以快速跳过不包含该ID的Segment,从而减少不必要的磁盘读次数
八. ES的容灾
ES有很完善的容灾机制,候选master一般有多个,data节点也有多个,因此节点异常的时候通过将访问切换到别的节点来容灾。具体流程包含如下几个流程:
1.故障发现
故障发现如下图所示: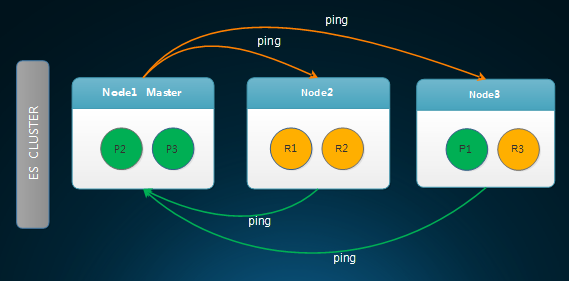
从上图中可以看出,Master会去ping各个其他的节点,图中只画了datanode节点。而其他的节点也会去ping master节点,确认master节点是否正常。默认ping规则如下:
Discovery.zen.fd.ping_interval=1s 默认每隔1秒探测1次
Discovery.zen.fd.ping_timeout=30s 默认ping探测的超时时间为30秒
Discovery.zen.fd.ping_retry=3 默认重试3次
#备注,以上参数可以根据自己的网络情况和业务需求进行调整。
2.节点切换
master节点切换
当其他节点探测到master异常并达到重试次数后,候选节点会进行竞争,选master的具体规则如下:
a. 每次选举每个节点会把自己所知道的候选master节点根据nodeid进行一次排序,然后选出第1个节点,暂且认为它是master节点;
b. 如果对某个节点的投票数达到 候选master数/2+1 个并且该节点也选举自己为master,那么这个节点即为master。否则重新选举;
备注:之所以节点的投票数需要达到候选master数/2+1,是为了防止脑裂的问题发生。
data节点切换
当master节点检测到某个data节点有异常的时候,做的操作大致如下:
a. master剔除该data节点,如果ES数据配置了1份副本保存,此时不存在数据丢失的风险,集群状态为yelllow。如果数据没有配置副本保存,则存在数据丢失,集群状态为red。
b. master对找出异常的data节点对应的所有的数据分片,如果是主分片,则将其他节点上的副本分片提升为主分片,全部主分片恢复后,异常data节点涉及的数据读写都恢复正常。
c. 业务恢复正常以后,master会将异常节点的数据迁移到正常的节点
d. 全部数据迁移完成后,集群状态恢复为green
九. ES的扩容
ES设计成能让你灵活地扩缩容模型,当你添加或者减少data节点的时候,ES会自动的对数据进行均衡。如下几个简图能让你几秒钟了解ES的扩容问题,下面几个图的索引设置为number_of_shards=3 && number_of_replicas=1,即索引为3个分片并且每个分片有1个副本。
1.一个节点的ES Cluster
从上图中可以看到虽然设置了1个副本,但是datanode1只分配了3个主分片。这是因为ES认为如果副本和主分片在1台机器上和没有副本的效果一样,当那台机器异常的时候,数据一样丢失。因此ES没有在那台机器上分配副本分片。
2.扩容一个节点后的ES Cluster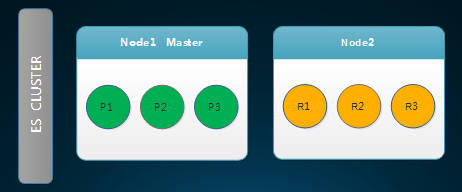
从上图中,可以看到添加1个节点后,data节点2分配了2个副本。
3.再扩容一个节点后的ES Cluster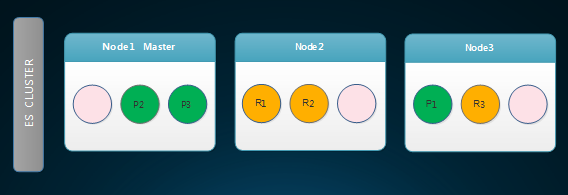
从上图中可以看到,data节点1上的P1被移动到了data节点3,data节点2上的R3被移动到了data节点3,这是因为添加节点后,ES会自动均衡数据。
十. ES的其它功能
1.ES的GROUP功能
ES的group功能和HBase的group功能类似,可以将某些节点放到某一个GROUP中,从而实现业务之间的隔离。比如想讲重点业务和普通业务隔离开来,就可以将重点业务放到指定的某个组,这个组不存在过保的设备,负载也比较低。而将普通业务放到普通的组中,这各组的设备由于比较老,故障率会比较搞,组内的机器负载也会高一些。
比如有两个组,分别是GroupA和GroupB,其中GroupA中保存这某些索引,GroupB中也保存着某些分片。ES有专门的参数控制索引可以存储在某个Group或则节点,具体的参数如下:
cluster.routing.allocation.awareness.attributes
cluster.routing.allocation.include
cluster.routing.allocation.require
cluster.routing.allocation.exclude
2.ES部落节点功能
ES从1.0版本开始支持使用部落节点(tribe node),所谓的部落节点,就是作为联合客户端提供访问多个ElasticSearch集群的能力。业务只需要访问部落节点,就可以获取多个ES集群的数据。并且可以通过部落节点写入数据,写入数据的时候部落节点会将写入请求转发到后端的集群节点进行数据写入。但是不支持创建索引的操作。注意:如果部落节点对应后端的ES集群含有相同的索引名称就会出现莫名其妙的问题,因为ES的默认行为是从中选择一个。也就是说如果后端2个集群含有相同的索引名字,那么知会有一个索引会被访问到。
3.ES的IO流控功能
ES还有个比较好的功能就是IO流控的功能,这个功能对于分布式存储是非常必要的,比如可以限制文件合并的时候的IO,从而使系统更平稳地运行。ES主要有节点级和索引级两个限流机制。分别介绍如下:
节点级别限流
Indices.store.throttle.type(none/merge/all)
Indices.store.throttle.max_bytes_per_sec
索引级别限流
Index.store.throttle.type(none/merge/all/node)
Index.store.throttle.max_bytes_per_sec
none/merge/all三个值,意义分别如下:
none 为不流控
merge 为对合并做IO流控
all 为对所有的操作做IO流控
4.ES的慢日志功能
ES有类似于MySql的慢查询功能,可以记录下慢的操作,从而让运维人员能通过慢的操作找到问题所在。默认情况下,慢日志是不开启的,有三种动作可以定义,分别是query、fetch、index三类,如下是一个query的慢日志定义:
PUT /my_index/_settings
{
"index.search.slowlog.threshold.query.warn" : "10s",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.indexing.slowlog.threshold.index.info": "5s"
}
上面设置的意思如下:
查询慢于 10 秒输出一个 WARN 日志
获取慢于 500 毫秒输出一个 DEBUG 日志
索引慢于 5 秒输出一个 INFO 日志
5. ES的发现热点功能
ES有个查询集群热点线程的功能,这个功能在集群突然变慢的场景下特别有用,它将帮助你找到消耗资源最多的线程。热点线程的使用方法如下:
curl ‘http://localhost:9200/_nodes/hot_threads’
返回的结果中含有线程所在的节点信息、线程消耗资源的情况、线程名称以及相关的堆栈信息,如下图所示: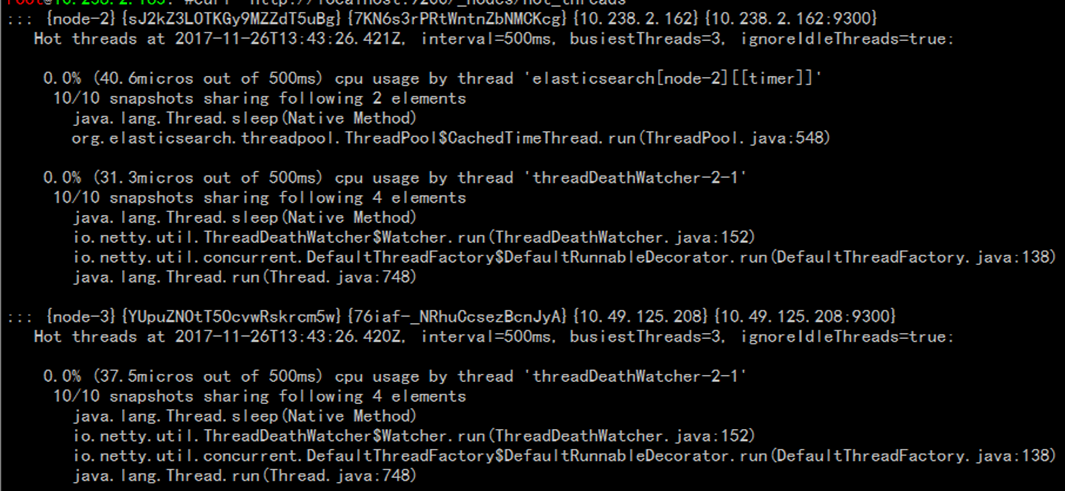
参考文献
Elasticsearch索引原理
这也许是你看到过的最通俗易懂的ElasticSearch文章了(理论篇)
————————————————
版权声明:本文为CSDN博主「zxcodestudy」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_16681169/article/details/81811244

若有收获,就点个赞吧
0 人点赞
