前言
关于消息队列,笔者依稀记得多年前刚毕业实习的时候,由于业务上的需要,有过一段时间的研究,那时候研究的目的是要引入一个更好的消息队列中间件来解决公司门店数据与总部机房数据通讯的问题,只可惜那时候笔者经验尚浅,并没有对消息队列有更深入的理解。
不过出于开发的需要,最近又开始消息队列的学习,并将学习笔记整理成这篇文章,以备查验。
什么是队列
队列(Queue)是一种常见的数据结构,其最大的特性就是先进先出(Firist In First Out),作为最基础的数据结构,队列应用很广泛,比如我们熟知的Redis基础数据类型List,其底层数据结构就是队列。
什么是消息队列
消息队列(Messaeg Queue)是一种使用队列(Queue)作为底层存储数据结构,可用于解决不同进程与应用之间通讯的分布式消息容器,也称为消息中间件。
目前使用得比较多的消息队列有ActiveMQ,RabbitMQ,Kafka,RocketMQ等。 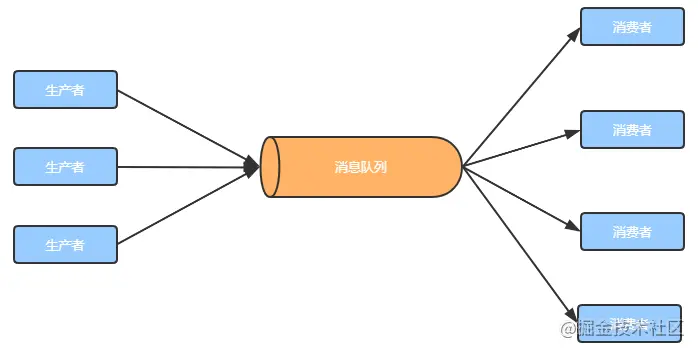
什么是RabbitMQ
RabbitMQ是用Erlang语言开发的一个实现了AMQP协议的消息队列服务器,相比其他同类型的消息队列,最大的特点在保证可观的单机吞吐量的同时,延时方面非常出色。
RabbitMQ支持多种客户端,比如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等。
AMQP,即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
消息队列的应用场景
消息队列使用广泛,其应用场景有很多,下面我们列举比较常见的五个场景。
消息通讯
消息队列最主要功能收发消息,其内部有高效的通讯机制,因此非常适合用于消息通讯。
我们可以基于消息队列开发点对点聊天系统
也可以开发广播系统,用于将消息广播给大量接收者。
异步处理
一般我们写的程序都是顺序执行(同步执行),比如一个用户注册函数,其执行顺序如下:
- 1.写入用户注册数据。
- 2.发送注册邮件。
- 3.发送注册成功的短信通知。
- 4.更新统计数据。

按照上面的执行顺序,要全部执行完毕,才能返回成功,但其实在第1步执行成功后,其他的步骤完全可以异步执行,我们可以将后面的逻辑发给消息队列,再由其他程序异步执行,如下所示: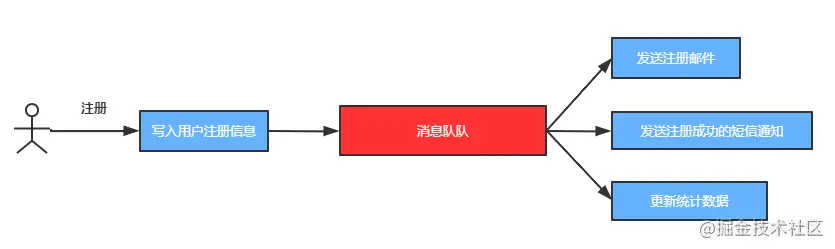
使用消息队列进行异步处理,可以更快地返回结果,加快服务器的响应速度,提升了服务器的性能。
服务解耦
在我们的系统中,应用与应用之间的通讯是很常见的,一般我们应用之间直接调用,比如说应用A调用应用B的接口,这时候应用之间的关系是强耦合的。
如果应用B处于不可用的状态,那么应用A也会受影响。
在应用A与应用B之间引入消息队列进行服务解耦,如果应用B挂掉,也不会影响应用A的使用。
流量削峰
对于高并发的系统来说,在访问高峰时,突发的流量就像洪水般向应用系统涌过来,尤其是一些高并发写操作,随时会导致数据库服务器瘫痪,无法继续提供服务。
而引入消息队列则可以减少突发流量对应用系统的冲击。消息队列就像“水库”一样,拦蓄上游的洪水,削减进入下游河道的洪峰流量,从而达到减免洪水灾害的目的。
这方面最常见的例子就是秒杀系统,一般秒杀活动瞬间流量很高,如果流量全部涌向秒杀系统,会压垮秒杀系统,通过引入消息队列,可以有效缓冲突发流量,达到“削峰填谷”的作用。
RabbitMQ安装与启动
RabbitMQ支持Linux、Windows,Unix、MacOS等多种操作系统,我们可以根据自己的操作系统来安装对应的版本,下面我们只讲解如何在Cnetos7上安装,和使用Docker进行安装。
更多安装详细信息,可查看官网
在Cnetos7上的安装
下面演示Erlang和RabbitMQ的安装,我们使用rpm的一键安装包,这种方式比较方便,比较适合初学者。
基础依赖安装
如果你的操作系统是Linux的最小安装包,那么应该有很多基础的依赖包没有安装,在安装RabbitMQ之前,需要安装好这些基础依赖包,可以运行如下命令:
$ sudo yum install openssql openssl-devel make gcc gcc-c++ kernel-devel
安装Socat
RabbitMQ依赖于Socat,因此在安装RabbitMQ前要安装Socat,如下:
$ sudo yum install -y socat
安装Erlang
因为RabbitMQ是用Erlang语言开发,所以在安装RabbitMQ前,要先安装Erlang运行环境,我们使用Erlang语言的rpm安装包。
# 下载
$ wget https://github.com/rabbitmq/erlang-rpm/releases/download/v22.3/erlang-22.3-1.el7.x86_64.rpm
# 安装
$ rpm -ivh erlang-22.3-1.el7.x86_64.rpm
安装RabbitMQ
上面所说的依赖安装完成后,最后我们可以运行下面的命令安装RabbitMQ:
# 下载
$ wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.3/rabbitmq-server-3.8.3-1.el7.noarch.rpm
# 安装
$ rpm -ivh rabbitmq-server-3.8.3-1.el7.noarch.rpm
启动与关闭
安装完成之后,可以使用rabbitmq-server命令启动服务器,如下:
# 直接启动
$ sudo rabbitmq-server
-detached为可选参数,表示后台开启
-detached为可选参数,表示后台开启
$ sudo rabbitmq-server -detached
启动成功,输出如下: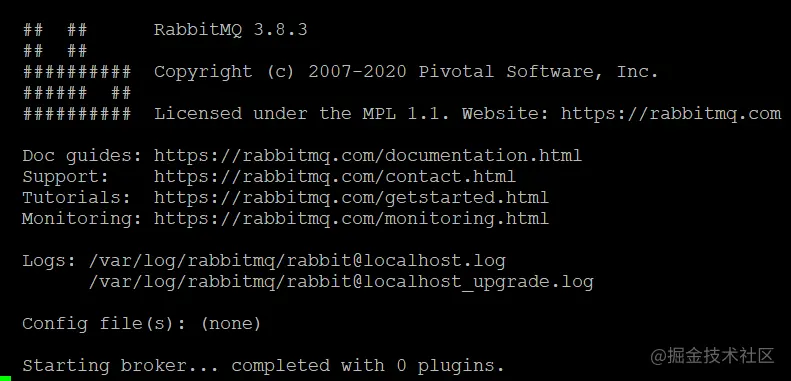
如果要关闭,则可以使用下面的命令:
#关闭RabbitMQ服务:
$ sudo rabbitmqctl stop
插件管理
上面我们使用rabbitmq-server启动服务器,也可以使用rabbitmqctl命令管理服务器,包括创建交换机、队列、用户管理等操作,除了命令管理工具,RabbitMQ还提供了Web管理工具,而Web管理工具作为RabbitMQ的插件,如果要开启,可以使用下面的命令 :
rabbitmq-plugins是RabbitMQ管理插件的命令。
$ sudo rabbitmq-plugins enable rabbitmq_management
启动插件后,我们再启动服务器,最后一行显示运行了3个插件,如下: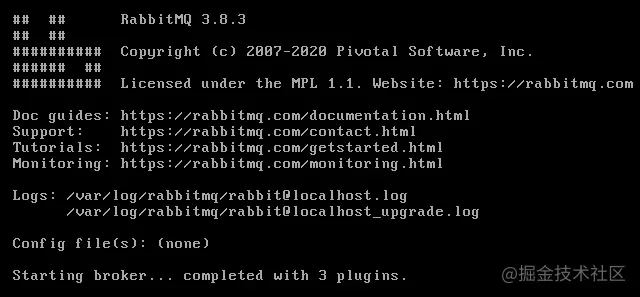
重新启动服务器后,可以打开浏览器访问RabbitMQ的Web管理界面
Web管理程序的端口号是15672,在浏览器中输入http://localhost:15672,即可以访问。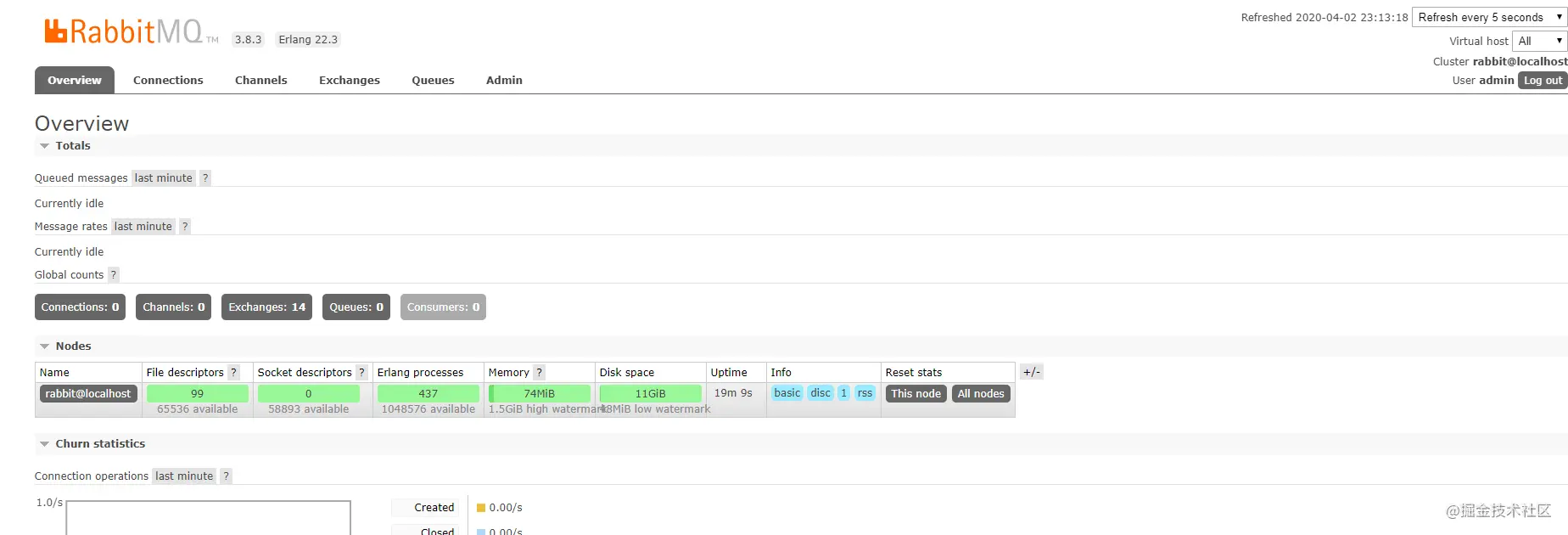
Docker上的安装
上面演示的是直接在操作系统上安装RabbitMQ的过程,如果你本地有安装Docker运行环境,那么可以下载RabbitMQ的Docker镜像进行安装,这种方式很方便,也不需要自己安装RabbitMQ依赖。
可以Docker Hub上查询我们需要的RabbitMQ镜像包,如下:
我们选择以tag带management后缀的镜像, 这表示该版本带有Web管理界面。
# 拉取镜像包
docker pull rabbitmq:3.8.3-management
# 启动镜像
docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 -v pwd/data:/var/lib/rabbitmq --hostname myRabbit -e RABBITMQ_DEFAULT_VHOST=my_vhost -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin rabbitmq3.8.3-management
核心概念
RabbitMQ有属于自己的一套核心概念,对这些概念的理解很重要,只有理解了这些核心概念,才有可能建立对RabbitMQ的全面理解。
Broker
Broker概念比较简单,我们可以把Broker理解为一个RabitMQ Server。
Producer与Consumer
生产者与消费者相对于RabbitMQ服务器来说,都是RabbitMQ服务器的客户端。
- 生产者(Producer):连到RabbitMQ服务器,将消息发送到RabbitMQ服务器的队列,是消息的发送方。
- 消费者(Consumer):连接到RabbitMQ则是为了消费队列中的消息,是消息的接收方。
Connection
Connection是RabbitMQ内部对象之一,用于管理每个到RabbitMQ的TCP网络连接。
Channel
Channel是我们与RabbitMQ打交道的最重要的一个接口,我们大部分的业务操作是在Channel这个接口中完成的,包括定义Queue、定义Exchange、绑定Queue与Exchange、发布消息等
Exchnage
消息交换机,作用是接收来自生产者的消息,并根据路由键转发消息到所绑定的队列。
生产者发送上的消息,就是先通过Exchnage按照绑定(binding)规则转发到队列的。
交换机类型(Exchange Type)有四种:fanout、direct、topic,headers,其中headers并不常用。
- fanout:这种类型不处理路由键(RoutingKey),很像子网广播,每台子网内的主机都获得了一份复制的消息,发布/订阅模式就是指使用fanout交换机类型,fanout类型交换机转发消息是最快的。
- direct:模式处理路由键,需要路由键完全匹配的队列才能收到消息,路由模式使用的是direct类型的交换机。
- topic:将路由键和某模式进行匹配。主题模式使用的是topic类型的交换机。
路由模式,发布订阅模式,主题模式,这些工作模式我们下面会讲。
Queue
Queue,即队列,RabbitMQ内部用于存储消息的对象,是真正用存储消息的结构,在生产端,生产者的消息最终发送到指定队列,而消费者也是通过订阅某个队列,达到获取消息的目的。
Binding
Binding是一种操作,其作用是建立消息从Exchange转发到Queue的规则,在进行Exchange与Queue的绑定时,需要指定一个BindingKey,Binding操作一般用于RabbitMQ的路由工作模式和主题工作模式。
BindingKey的概念,我们下面在讲RabbitMQ的工作模式会详细讲解。
Virtual Host
Virutal host也叫虚拟主机,一个VirtualHost下面有一组不同Exchnage与Queue,不同的Virtual host的Exchnage与Queue之间互相不影响。
应用隔离与权限划分,Virtual host是RabbitMQ中最小颗粒的权限单位划分。
如果要类比的话,我们可以把Virtual host比作MySQL中的数据库,通常我们在使用MySQL时,会为不同的项目指定不同的数据库,同样的,在使用RabbitMQ时,我们可以为不同的应用程序指定不同的Virtual host。
上面我们一一列举了RabbitMQ的核心概念,通过下面的示意图,我们可以更清晰地了解它们之间的关系。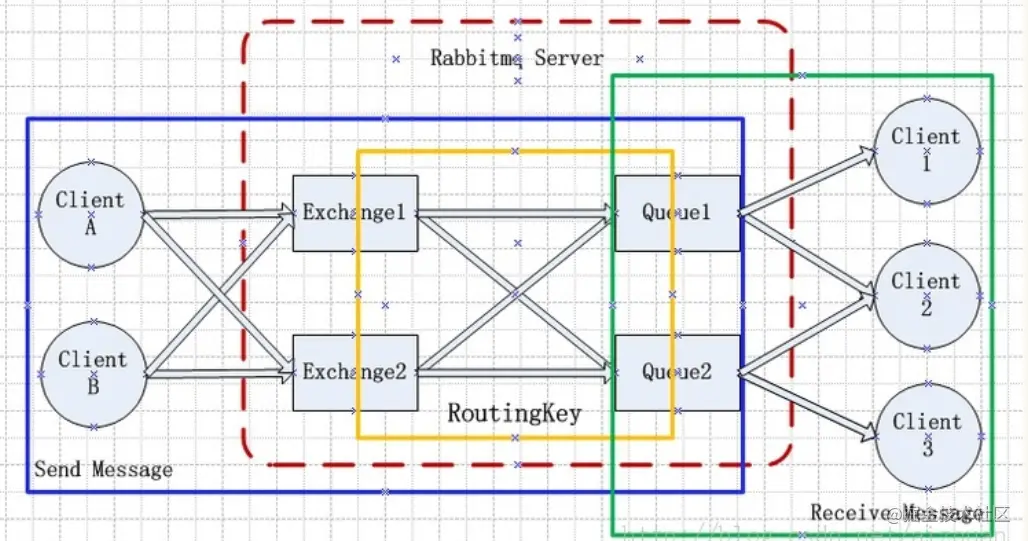
工作模式
RabbitMQ一共有六种工作模式,分别为简单模式、工作队列模式、发布/订阅模式、路由模式、主题模式和RPC模式,RPC模式并不常用,因此我们下面只讲前面五种工作模式。
简单(simple)模式
simple模式,是RabbitMQ几种模式中最简单的一种模式,其结构如下图所示: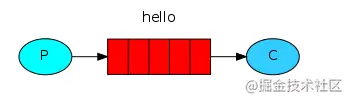
从上面的示意图,我们可以看出simple模式有以下几个特征:
- 只有一个生产者、一个消费者和一个队列。
生产者和消费者在发送和接收消息时,只需要指定队列名,而不需要指定发送到哪个Exchange,RabbitMQ服务器会自动使用Virtual host的默认的Exchange,默认Exchange的type为direct。
工作(work)模式
在simple模式下只有一个生产者和消费者,当生产者生产消息的速度大于消费者的消费速度时,我们可以添加一个或多个消费者来加快消费速度,这种在simple模式下增加消费者的模式,称为work模式,如下图所示:
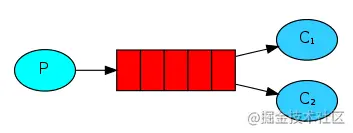
work模式有以下两个特征:可以有多个消费者,但一条消息只能被一个消费者获取。
-
发布/订阅(pub/sub)模式
work模式可以将消息转到多个消费者,但每条消息只能由一个消费者获取,如果我们想一条消息可以同时给多个消费者消费呢?
这时候就需要发布/订阅模式,其示意图如下所示: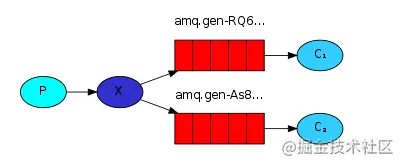
从上面的示意图我们可以看出来,在发布/订阅模式下,需要指定发送到哪个Exchange中,上面图中的X表示Exchange。 发布/订阅模式中,Echange的type为fanout。
- 生产者发送消息时,不需要指定具体的队列名,Exchange会将收到的消息转发到所绑定的队列。
消息被Exchange转到多个队列,一条消息可以被多个消费者获取。
路由(routing)模式
前面几种模式,消息的目标队列无法由生产者指定,而在路由模式下,消息的目标队列,可以由生产者指定,其示意图如下所示:
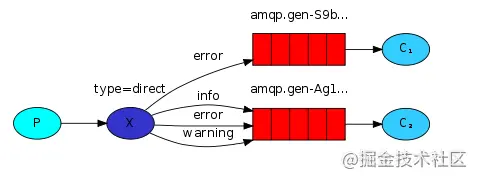
从上面示意图,我们可以看出路由模式有以下特征:路由模式下Exchange的type为direct。
- 消息的目标队列可以由生产者按照routingKey规则指定。
- 消费者通过BindingKey绑定自己所关心的队列。
- 一条消息队可以被多个消息者获取。
- 只有RoutingKey与BidingKey相匹配的队列才会收到消息。
RoutingKey用于生产者指定Exchange最终将消息路由到哪个队列,BindingKey用于消费者绑定到某个队列。
主题(topic)模式
主题模式是在路由模式的基础上,将路由键和某模式进行匹配。其中#表示匹配多个词,*表示匹配一个词,消费者可以通过某种模式的BindKey来达到订阅某个主题消息的目的,如示意图如下所示: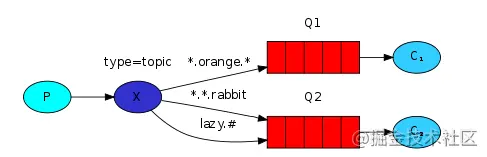
- 主题模式Exchange的type取值为topic。
- 一条消息可以被多个消费者获取。
几种常见消息队列的对比
除了RabbitMQ之外,还有其他比较常见的消息队列中间件,如Kafka,RocketMQ,ActiveMQ等,下面的表格中列举了这几种消息队列的差异:
| 消息队列 | RabbitMQ | ActiveMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 所属公司/社区 | Mozilla Public License | Apache | Ali | Apache |
| 成熟度 | 成熟 | 成熟 | 比较成熟 | 成熟 |
| 授权方式 | 开源 | 开源 | 开源 | 开源 |
| 开发语言 | Erlang | Java | Java | Scala & Java |
| 客户端支持语言 | 官方支持Erlang,java,Ruby等,社区产出多种语言API,几乎支持所有常用语言 | JAVA,C++,pyhton,php,perl,net等 | java,c++ | 官方支持java,开源社区有多种语言版本,如PHP,python,go,c/c++,ruby,node.js等语言 |
| 协议支持 | 多协议支持AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP/AMOP | 自定义的一套 | 自定义协议 |
| 消息批量操作 | 不支持 | 支持 | 支持 | 支持 |
| 消息推拉模式 | 多协议,pull/push均有支持 | 多协议pull/push均有支持 | 多协议,pull/push均有支持 | pull |
| HA | master/slave模式 | 基于zookeeper+LevelDB的master-slave | 支持多master模式,多master多slave模式,异步复制模式 | 支持replica机制,leader宕掉后,备份自动顶替,并重新选择leader |
| 数据可靠性 | 可以保证数据不丢,有slave备份 | master/slave | 支持异步实时刷盘,同步刷盘,同步复制,民步复制 | 数据可靠,并且有replica机制,有容错容灾能力 |
| 单机吞吐量 | 其次(万级) | 最差(万级) | 最高(十万级) | 次之(十万级) |
| 消息延迟 | 微秒级 | \ | 比Kafka快 | 毫秒级 |
| 持久化能力 | 内存、文件、支持数据堆积,但数据堆积反过来影响生产速率 | 内存、文件、数据库 碰盘文件 | 磁盘文件 | 磁盘文件,只要磁盘容量够,可以做到无限消息堆积 |
| 是否有序 | 若想有序,只能使用一个client | 可以支持有序 | 有序 | 多client保证有序 |
| 事务 | 支持 | 支持 | 支持 | 不支持 |
| 集群 | 支持 | 支持 | 支持 | 支持 |
| 负载均衡 | 支持 | 支持 | 支持 | 支持 |
| 管理界面 | 较好 | 一般 | 命令行界面 | 官方只提供了命令行版 |
| 部署方式 | 独立 | 独立 | 独立 | 独立 |
小结
本文讲解了队列与RabbitMQ的概念、如何安装RabbitMQ、RabbitMQ的核心概念以及几种工作模式,由于涉及到RabbitMQ的大部分知识点,因此鉴于笔者水平有限,文章中讲解不对或不足的地方,欢迎指出,不胜感激!
作者:程序员读书
链接:https://juejin.cn/post/6844904113788944397
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
