JAVA内存区域
1、什么是JVM?
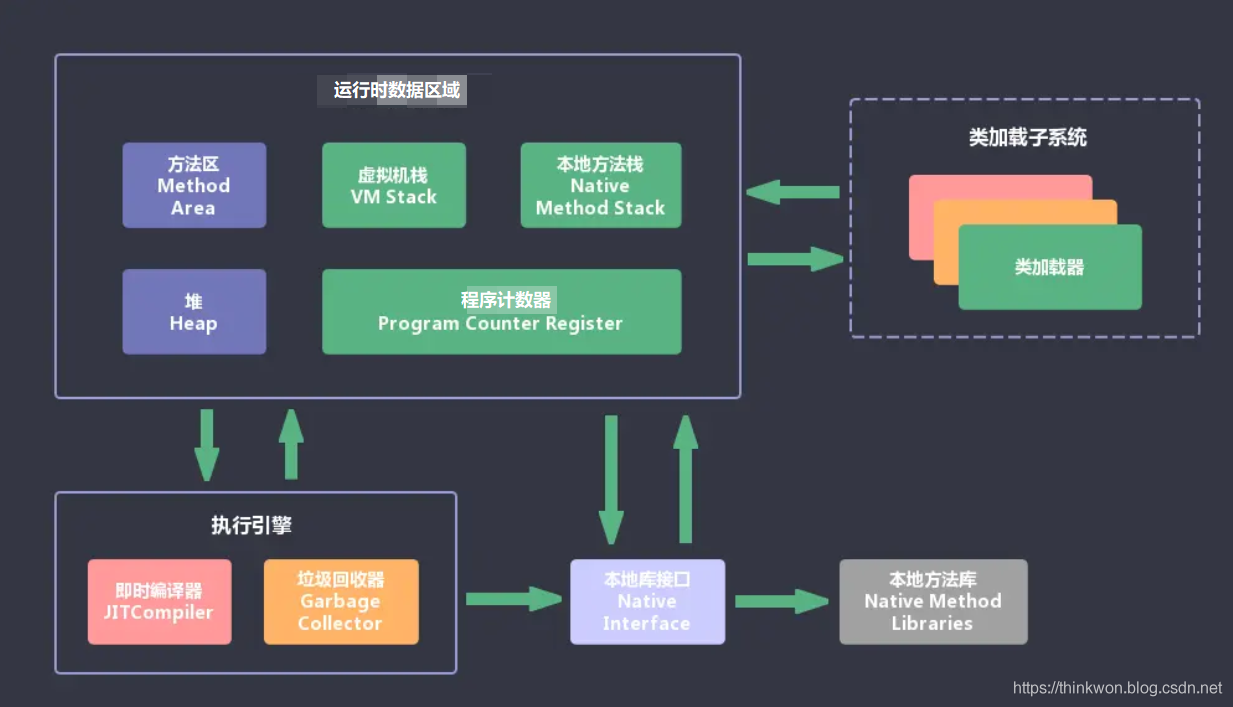
- JVM包含两个子系统和两个组件,两个子系统为Class loader(类装载)、Execution engine(执行引擎);两个组件为Runtime data area(运行时数据区)、Native Interface(本地接口)。
- Class loader(类装载):根据给定的全限定名类名(如:java.lang.Object)来装载class文件到Runtime data area中的method area(方法区)。
- Execution engine(执行引擎):执行classes中的指令。
- Native Interface(本地接口):与native method libraries交互,是与其它编程语言交互的接口(调用其他语言编写的代码/直接)。
- Runtime data area(运行时数据区域):这就是我们常说的JVM的内存。
作用:
JAVA程序运行步骤
- 首先利用IDE集成开发工具编写Java源代码,源文件的后缀为.java;
- 再利用编译器(javac命令)将源代码编译成字节码文件,字节码文件的后缀名为.class;
- 运行字节码的工作是由解释器(java命令)来完成的。
- 总结: java文件通过编译器变成了.class文件,接下来类加载器又将这些.class文件加载到JVM中。
简单说明:
Java 虚拟机在执行 Java 程序的过程中会把它所管理的内存区域划分为若干个不同的数据区域
- 线程共享数据区:
- 方法区(Methed Area):用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据。
- JAVA堆 (Java Heap ): Java 虚拟机中内存最大的一块,是被所有线程共享的,几乎所有的对象实例都在这里分配内存;
- 线程隔离数据区:
- 线程共享数据区:
浅拷贝(shallowCopy):增加了一个指针指向已存在的内存地址
- 深拷贝(deepCopy):增加了一个指针并且申请了一个新的内存,使这个增加的指针指向这个新的内存- 使用深拷贝的情况下,释放内存的时候不会因为出现浅拷贝时释放同一个内存的错误。
- 浅复制:仅仅是指向被复制的内存地址,如果原地址发生改变,那么浅复制出来的对象也会相应的改变。
-
6、堆栈的区别
物理地址
- 堆的物理地址分配对对象是不连续的。因此性能慢些。在GC的时候也要考虑到不连续的分配,所以有各种算法。比如,标记-消除,复制,标记-压缩,分代(即新生代使用复制算法,老年代使用标记——压缩)
- 栈使用的是数据结构中的栈,先进后出的原则,物理地址分配是连续的。所以性能快。
- 内存分别
- 堆因为是不连续的,所以分配的内存是在运行期确认的,因此大小不固定。一般堆大小远远大于栈。
- 栈是连续的,所以分配的内存大小要在编译期就确认,大小是固定的。
- 存放的内容
- 堆存放的是对象的实例和数组。因此该区更关注的是数据的存储
- 栈存放:局部变量,操作数栈,返回结果。该区更关注的是程序方法的执行。
程度的可见性
共同点:
- 队列和栈都是被用来预存储数据的。
- 区别点:
- 操作的名称不同。队列的插入称为入队,队列的删除称为出队。栈的插入称为进栈,栈的删除称为出栈。
- 可操作的方式不同。队列是在队尾入队,队头出队,即两边都可操作。而栈的进栈和出栈都是在栈顶进行的,无法对栈底直接进行操作。
- 操作的方法不同。队列是先进先出(FIFO),即队列的修改是依先进先出的原则进行的。新来的成员总是加入队尾(不能从中间插入),每次离开的成员总是队列头上(不允许中途离队)。而栈为后进先出(LIFO),即每次删除(出栈)的总是当前栈中最新的元素,即最后插入(进栈)的元素,而最先插入的被放在栈的底部,要到最后才能删除。
HotSpot虚拟机对象探秘
1、对象的创建
- Java中提供的几种对象创建方式: | Header | 解释 | | —- | —- | | 使用new关键字 | 调用了构造函数 | | 使用Class的newInstance方法 | 调用了构造函数 | | 使用Constructor类的newInstance方法 | 调用了构造函数 | | 使用clone方法 | 没有调用构造函数 | | 使用反序列化 | 没有调用构造函数 |
学习地址:https://www.cnblogs.com/wxd0108/p/5685817.html
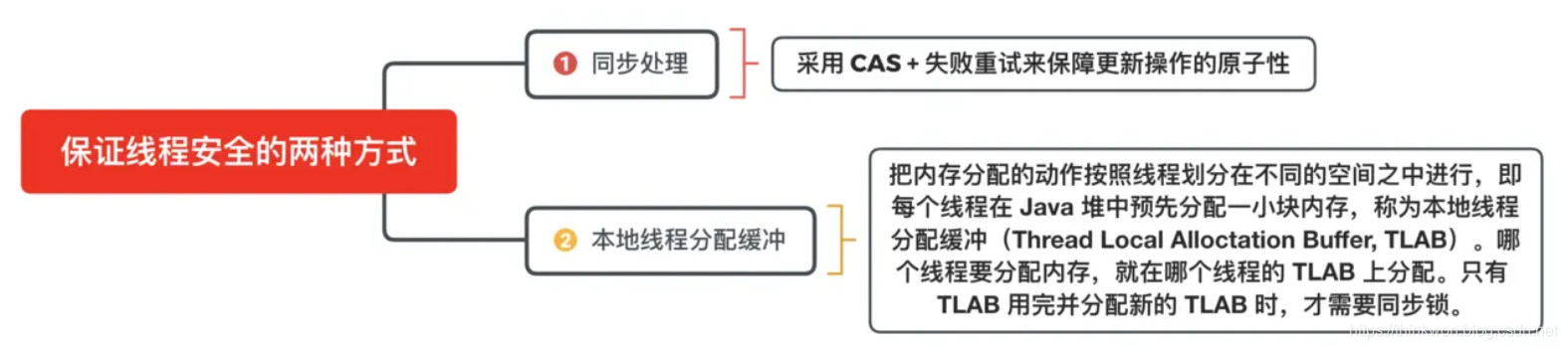
2、对象创建的主要流程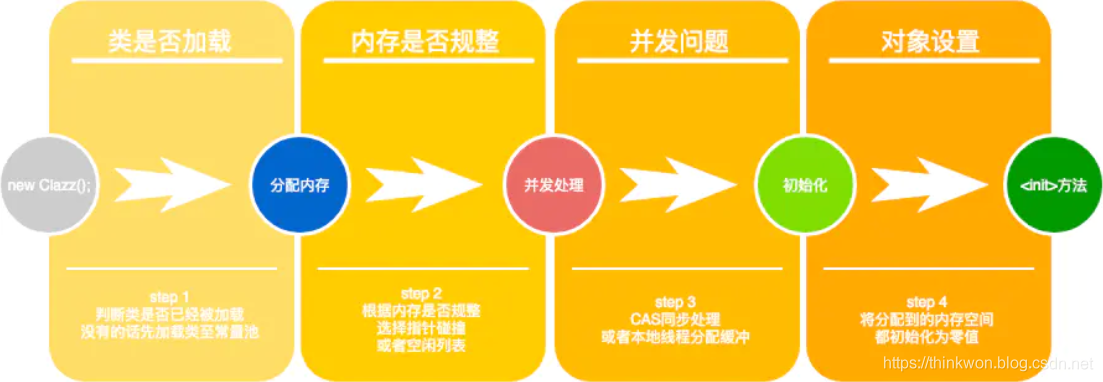 虚拟机遇到一条new指令时,先检查常量池是否已经加载相应的类,如果没有,必须先执行相应的类加载。类加载通过后,接下来分配内存。若Java堆中内存是绝对规整的,使用“指针碰撞“方式分配内存;如果不是规整的,就从空闲列表中分配,叫做”空闲列表“方式。划分内存时还需要考虑一个问题-并发,也有两种方式: CAS同步处理,或者本地线程分配缓冲(Thread Local Allocation Buffer, TLAB)。然后内存空间初始化操作,接着是做一些必要的对象设置(元信息、哈希码…),最后执行
虚拟机遇到一条new指令时,先检查常量池是否已经加载相应的类,如果没有,必须先执行相应的类加载。类加载通过后,接下来分配内存。若Java堆中内存是绝对规整的,使用“指针碰撞“方式分配内存;如果不是规整的,就从空闲列表中分配,叫做”空闲列表“方式。划分内存时还需要考虑一个问题-并发,也有两种方式: CAS同步处理,或者本地线程分配缓冲(Thread Local Allocation Buffer, TLAB)。然后内存空间初始化操作,接着是做一些必要的对象设置(元信息、哈希码…),最后执行
2、为对象分配内存
- 类加载完成后,接着会在Java堆中划分一块内存分配给对象。内存分配根据Java堆是否规整,有两种方式:
- 指针碰撞:如果Java堆的内存是规整,即所有用过的内存放在一边,而空闲的的放在另一边。分配内存时将位于中间的指针指示器向空闲的内存移动一段与对象大小相等的距离,这样便完成分配内存工作。
- 空闲列表:如果Java堆的内存不是规整的,则需要由虚拟机维护一个列表来记录那些内存是可用的,这样在分配的时候可以从列表中查询到足够大的内存分配给对象,并在分配后更新列表记录。
3、对象的访问定位
Java程序需要通过 JVM 栈上的引用访问堆中的具体对象。对象的访问方式取决于 JVM 虚拟机的实现。目前主流的访问方式有 句柄 和 直接指针 两种方式。
指针: 指向对象,代表一个对象在内存中的起始地址。
句柄: 可以理解为指向指针的指针,维护着对象的指针。句柄不直接指向对象,而是指向对象的指针(句柄不发生变化,指向固定内存地址),再由对象的指针指向对象的真实内存地址。
todo
内存溢出异常
1、Java会存在内存泄漏吗?请简单描述
内存泄漏是指不再被使用的对象或者变量一直被占据在内存中。理论上来说,Java是有GC垃圾回收机制的,也就是说,不再被使用的对象,会被GC自动回收掉,自动从内存中清除。
但是,即使这样,Java也还是存在着内存泄漏的情况,java导致内存泄露的原因很明确:长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄露,尽管短生命周期对象已经不再需要,但是因为长生命周期对象持有它的引用而导致不能被回收,这就是java中内存泄露的发生场景。
*垃圾收集器

若有收获,就点个赞吧
0 人点赞
