- 普通hash函数
- 作用:散列—— 将一系列在形式上具有相似性质的数据,打散成随机的、均匀分布的数据
- 存在问题:不难发现,这样的Hash只要集群的数量N发生变化,之前的所有Hash映射就会全部失效。 如果集群中的每个机器提供的服务没有差别,倒不会产生什么影响,但对于分布式缓存这样的系统而言,映射全部失效就意味着之前的缓存全部失效,后果将会是灾难性的。
- 解决方案:一致性Hash通过构建环状的Hash空间代替线性Hash空间的方法解决了这个问题。
- 良好的分布式cahce系统中的一致性hash算法应该满足以下几个方面:
- 平衡性(Balance)
- 平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
- 单调性(Monotonicity)
- 单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
- 分散性(Spread)
- 在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
- 负载(Load)
- 负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
- 平滑性(Smoothness)
- 平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
- 平衡性(Balance)
- 一致性Hash算法原理
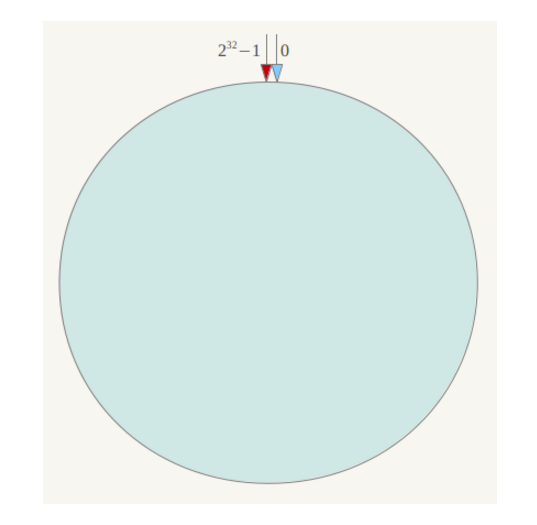
- 简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-232-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:整个空间按顺时针方向组织。0和232-1在零点中方向重合。
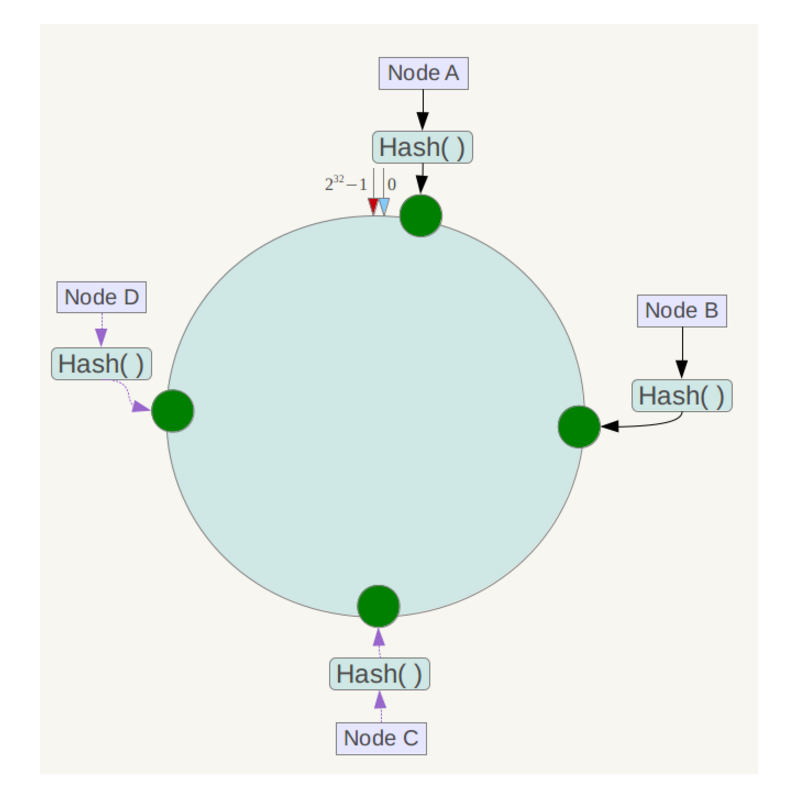
- 一步将各个服务器使用Hash进行一次哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下
- 简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-232-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:整个空间按顺时针方向组织。0和232-1在零点中方向重合。
- 一致性哈希算法的容错性和可扩展性
- 容错性: 现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
- 可拓展性: 此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
- 总结:一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
- 代码实现
| public class ConsistentHash {
``` /**- 节点的复制因子,实际节点个数 numberOfReplicas = 虚拟节点个数 / private final int numberOfReplicas; /**
- 存储虚拟节点的hash值到真实节点的映射
*/
private final SortedMap
public ConsistentHash(int numberOfReplicas, Collection
public void add(T node) { for (int i = 0; i < numberOfReplicas; i++) { // 对于一个实际机器节点 node, 对应 numberOfReplicas 个虚拟节点 /*
* 不同的虚拟节点(i不同)有不同的hash值,但都对应同一个实际机器node* 虚拟node一般是均衡分布在环上的,数据存储在顺时针方向的虚拟node上*/String nodestr = node.toString() + i;int hashcode = nodestr.hashCode();System.out.println("hashcode:" + hashcode);circle.put(hashcode, node);}
}
public void remove(T node) { for (int i = 0; i < numberOfReplicas; i++) { circle.remove((node.toString() + i).hashCode()); } }
/**
- 获得一个最近的顺时针节点,根据给定的key 取Hash
- 然后再取得顺时针方向上最近的一个虚拟节点对应的实际节点
- 再从实际节点中取得 数据 *
- @param key
- @return
*/
public T get(Object key) {
if (circle.isEmpty()) {
} // node 用String来表示,获得node在哈希环中的hashCode int hash = key.hashCode(); System.out.println(“hashcode——->:” + hash); //数据映射在两台虚拟机器所在环之间,就需要按顺时针方向寻找机器 if (!circle.containsKey(hash)) {return null;
} return circle.get(hash); }SortedMap<Integer, T> tailMap = circle.tailMap(hash);hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
public long getSize() { return circle.size(); }
/**
查看表示整个哈希环中各个虚拟节点位置 */ public void testBalance() { //获得TreeMap中所有的Key Set
sets = circle.keySet(); //将获得的Key集合排序 SortedSet sortedSets = new TreeSet (sets); for (Integer hashCode : sortedSets) { System.out.println(hashCode);
}
System.out.println(“——each location ‘s distance are follows: ——“); /*
- 查看相邻两个hashCode的差值
*/
Iterator
it = sortedSets.iterator(); Iterator it2 = sortedSets.iterator(); if (it2.hasNext()) { it2.next(); } long keyPre, keyAfter; while (it.hasNext() && it2.hasNext()) { keyPre = it.next(); keyAfter = it2.next(); System.out.println(keyAfter - keyPre); } }
public static void main(String[] args) {
Set
ConsistentHash<String> consistentHash = new ConsistentHash<String>(2, nodes);consistentHash.add("D");System.out.println("hash circle size: " + consistentHash.getSize());System.out.println("location of each node are follows: ");consistentHash.testBalance();String node = consistentHash.get("apple");System.out.println("node----------->:" + node);
}
```
} |
| —- |

若有收获,就点个赞吧
0 人点赞
