Mysql数据库表引擎与字符集
1.服务器处理客户端请求
其实不论客户端进程和服务器进程是采⽤哪种⽅式进⾏通信,最后实现的效果都是: 客户端进程向服务 器进程发送⼀段⽂本(MySQL语句),服务器进程处理后再向客户端进程发送⼀段⽂本(处理结果)。
那服务器进程对客户端进程发送的请求做了什么处理,才能产⽣最后的处理结果呢?客户端可以向服务 器发送增删改查各类请求,我们这⾥以⽐较复杂的查询请求为例来画个图展示⼀下⼤致的过程: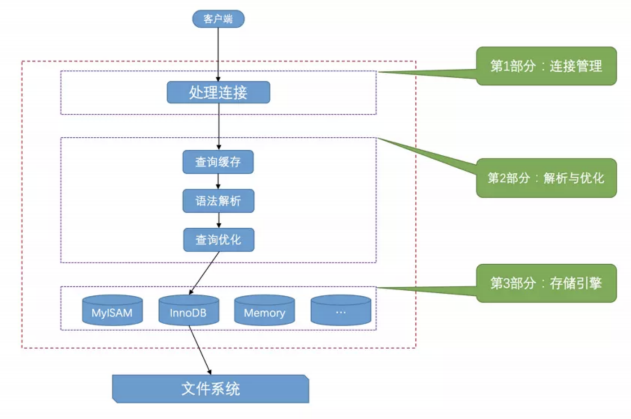
虽然查询缓存有时可以提升系统性能,但也不得不因维护这块缓存⽽造成⼀些开销,⽐如每次都 要去查询缓存中检索,查询请求处理完需要更新查询缓存,维护该查询缓存对应的内存区域。从 MySQL 5.7.20开始,不推荐使⽤查询缓存,并在MySQL 8.0中删除。
2.存储引擎
MySQL 服务器把数据的存储和提取操作都封装到了⼀个叫 存储引擎 的模块⾥。我们知道 表 是由⼀⾏⼀ ⾏的记录组成的,但这只是⼀个逻辑上的概念,物理上如何表示记录,怎么从表中读取数据,怎么把数 据写⼊具体的物理存储器上,这都是 存储引擎 负责的事情。为了实现不同的功能, MySQL 提供了各式 各样的 存储引擎 ,不同 存储引擎 管理的表具体的存储结构可能不同,采⽤的存取算法也可能不同。
存储引擎以前叫做 表处理器 ,它的功能就是接收上层传下来的指令,然后对表中的数据进⾏提取 或写⼊操作。
为了管理⽅便,⼈们把 连接管理 、 查询缓存 、 语法解析 、 查询优化 这些并不涉及真实数据存储的功能 划分为 MySQL server 的功能,把真实存取数据的功能划分为 存储引擎 的功能。各种不同的存储引擎 向上边的 MySQL server 层提供统⼀的调⽤接⼝(也就是存储引擎API),包含了⼏⼗个底层函数,
像”读取索引第⼀条内容” 、 “读取索引下⼀条内容” 、 “插⼊记录”等等。
所以在 MySQL server 完成了查询优化后,只需按照⽣成的执⾏计划调⽤底层存储引擎提供的API,获 取到数据后返回给客户端就好了。
MySQL ⽀持⾮常多种存储引擎:
| 存储引擎 | 描述 |
|---|---|
| ARCHIVE | ⽤于数据存档(⾏被插⼊后不能再修改) |
| BLACKHOLE | 丢弃写操作,读操作会返回空内容 |
| CSV | 在存储数据时,以逗号分隔各个数据项 |
| FEDERATED | ⽤来访问远程表 |
| InnoDB | 具备外键⽀持功能的事务存储引擎 |
| MEMORY | 置于内存的表 |
| MERGE | ⽤来管理多个MyISAM表构成的表集合 |
| MyISAM | 主要的⾮事务处理存储引擎 |
| NDB | MySQL集群专⽤存储引擎 |
3,MyISAM和InnoDB表引擎的区别
1) 事务⽀持
MyISAM不⽀持事务,⽽InnoDB⽀持。
事务:访问并更新数据库中数据的执⾏单元。事物操作中,要么都执⾏要么都不执⾏ .
2) 存储结构
MyISAM:每个MyISAM在磁盘上存储成三个⽂件。 .frm⽂件存储表结构。
.frm⽂件存储表结构。 .MYD⽂件存储数据。
.MYD⽂件存储数据。 .MYI⽂件存储索引。
.MYI⽂件存储索引。
InnoDB:主要分为两种⽂件进⾏存储 .frm 存储表结构
.frm 存储表结构 .ibd 存储数据和索引 (也可能是多个.ibd⽂件,或者是独⽴的表空间⽂件)
.ibd 存储数据和索引 (也可能是多个.ibd⽂件,或者是独⽴的表空间⽂件)
3) 表锁差异
MyISAM:只⽀持表级锁,⽤户在操作myisam表时, select, update, delete, insert语句都会给表⾃动加 锁,如果加锁以后的表满⾜insert并发的情况下,可以在表的尾部插⼊新的数据。 InnoDB:⽀持事务和 ⾏级锁,是innodb的最⼤特⾊。⾏锁⼤幅度提⾼了多⽤户并发操作的新能。但是InnoDB的⾏锁是基于索 引建⽴,如果索引失效或者没有使⽤索引,那么会由⾏锁升级为表锁。
4) 表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存⾏的地址。 InnoDB:如果没有设定主键或 者⾮空唯⼀索引,就会⾃动⽣成⼀个6字节的主键(⽤户不可⻅),数据是主索引的⼀部分,附加索引保存 的是主索引的值。 InnoDB的主键范围更⼤,最⼤是MyISAM的2倍。
5) 表的具体⾏数
MyISAM:保存有表的总⾏数,如果select count() from table;会直接取出出该值。 InnoDB:没有保存表的 总⾏数(只能遍历),如果使⽤select count()from table;就会遍历整个表,消耗相当⼤,但是在加了 wehre条件后, myisam和innodb处理的⽅式都⼀样。
6) CURD操作
MyISAM:如果执⾏⼤量的SELECT, MyISAM是更好的选择。 InnoDB:如果你的数据执⾏⼤量的INSERT或 UPDATE,出于性能⽅⾯的考虑,应该使⽤InnoDB表。 DELETE 从性能上InnoDB更优,但DELETE FROM table时, InnoDB不会重新建⽴表,⽽是⼀⾏⼀⾏的删除,在innodb上如果要清空保存有⼤量数据的表, 最好使⽤truncate table这个命令。
7) 外键
MyISAM:不⽀持 InnoDB:⽀持
8) 查询效率
MyISAM相对简单,所以在效率上要优于InnoDB,⼩型应⽤可以考虑使⽤MyISAM。
推荐考虑使⽤InnoDB来替代MyISAM引擎,原因是InnoDB⾃身很多良好的特点,⽐如事务⽀持、存储 过 程、视图、⾏级锁定等等,在并发很多的情况下,相信InnoDB的表现肯定要⽐MyISAM强很多。
另外,任何⼀种表都不是万能的,只⽤恰当的针对业务类型来选择合适的表类型,才能最⼤的发挥 MySQL的性能优势。如果不是很复杂的Web应⽤,⾮关键应⽤,还是可以继续考虑MyISAM的,这个具体 情况可以⾃⼰斟酌。
9) MyISAM和InnoDB两者的应⽤场景:
MyISAM管理⾮事务表。它提供⾼速存储和检索,以及全⽂搜索能⼒。如果应⽤中需要执⾏⼤量的 SELECT查询,那么MyISAM是更好的选择。 InnoDB⽤于事务处理应⽤程序,具有众多特性,包括ACID事 务⽀持。如果应⽤中需要执⾏⼤量的INSERT或UPDATE操作,则应该使⽤InnoDB,这样可以提⾼多⽤户 并发操作的性能。现在默认使⽤InnoDB。
4.了解⼀下字符集和乱码
字符集简介
我们知道在计算机中只能存储⼆进制数据,那该怎么存储字符串呢?当然是建⽴字符与⼆进制数 据的映射关系了,建⽴这个关系最起码要搞清楚两件事⼉:
1. 你要把哪些字符映射成⼆进制数据? 也就是界定清楚字符范围。
2. 怎么映射?
将⼀个字符映射成⼀个⼆进制数据的过程也叫做 编码 ,将⼀个⼆进制数据映射到⼀个字符的过程 叫做 解码 。
⼈们抽象出⼀个 字符集 的概念来描述某个字符范围的编码规则
我们看⼀下⼀些常⽤字符集的情况: ASCII 字符集
ASCII 字符集
共收录128个字符,包括空格、标点符号、数字、⼤⼩写字⺟和⼀些不可⻅字符。由于总共才128个 字符,所以可以使⽤1个字节来进⾏编码,我们看⼀些字符的编码⽅式:

‘L’ -> 01001100 (⼗六进制: 0x4C,⼗进制: 76) ‘M’ -> 01001101 (⼗六进制: 0x4D,⼗进制: 77) ISO 8859-1 字符集
ISO 8859-1 字符集
共收录256个字符,是在 ASCII 字符集的基础上⼜扩充了128个⻄欧常⽤字符(包括德法两国的字 ⺟),也可以使⽤1个字节来进⾏编码。这个字符集也有⼀个别名 latin1 。 GB2312 字符集
GB2312 字符集
收录了汉字以及拉丁字⺟、希腊字⺟、⽇⽂平假名及⽚假名字⺟、俄语⻄⾥尔字⺟。其中收录汉字 6763个,其他⽂字符号682个。同时这种字符集⼜兼容 ASCII 字符集,所以在编码⽅式上显得有些 奇怪:
如果该字符在 ASCII 字符集中,则采⽤1字节编码。
否则采⽤2字节编码。
这种表示⼀个字符需要的字节数可能不同的编码⽅式称为 变⻓编码⽅式 。⽐⽅说字符串 ‘爱u’ , 其中 ‘爱 ‘ 需要⽤2个字节进⾏编码,编码后的⼗六进制表示为 0xCED2, ‘u’ 需要⽤1个字节进⾏ 编码,编码后的⼗六进制表示为 0x75 ,所以拼合起来就是 0xCED275 。
⼩贴⼠: 我们怎么区分某个字节代表⼀个单独的字符还是代表某个字符的⼀部分呢?别忘 了 ASCII 字符集只收录128个字符,使⽤0~127就可以表示全部字符,所以如果某个字节是 在0~127之内的,就意味着⼀个字节代表⼀个单独的字符,否则就是两个字节代表⼀个单独 的字符。 GBK 字符集
GBK 字符集
GBK 字符集只是在收录字符范围上对 GB2312 字符集作了扩充,编码⽅式上兼容 GB2312 。 Unicode 字符集
Unicode 字符集
收录地球上能想到的所有字符,⽽且还在不断扩充。这种字符集兼容 ASCII 字符集,采⽤变⻓编 码⽅式,编码⼀个字符需要使⽤1~4个字节,⽐⽅说这样:

‘L’ -> 01001100 (⼗六进制: 0x4C)
‘啊’ -> 111001011001010110001010 (⼗六进制: 0xE5958A)
⼩贴⼠: 其实准确的说, utf8只是Unicode字符集的⼀种编码⽅案, Unicode字符集可以采⽤ utf8 、 utf16 、 utf32这⼏种编码⽅案, utf8使⽤1~4个字节编码⼀个字符, utf16使⽤2个或4个 字节编码⼀个字符, utf32使⽤4个字节编码⼀个字符。更详细的Unicode和其编码⽅案的知识 不是本书的重点,⼤家上⽹查查哈~ MySQL中并不区分字符集和编码⽅案的概念,所以后边 唠叨的时候把utf8 、 utf16 、 utf32都当作⼀种字符集对待。
对于同⼀个字符,不同字符集也可能有不同的编码⽅式。⽐如对于汉字 ‘我’ 来说, ASCII 字符集中根
本没有收录这个字符, utf8 和 gb2312 字符集对汉字 我 的编码⽅式如下:

utf8编码: 111001101000100010010001 (3个字节,⼗六进制表示是: 0xE68891)
gb2312编码: 1100111011010010 (2个字节,⼗六进制表示是: 0xCED2)
5.MySQL中的utf8和utf8mb4
我们上边说 utf8 字符集表示⼀个字符需要使⽤1~4个字节,但是我们常⽤的⼀些字符使⽤1~3个字节 就可以表示了。⽽在 MySQL 中字符集表示⼀个字符所⽤最⼤字节⻓度在某些⽅⾯会影响系统的存储和 性能,所以设计 MySQL 的⼤叔偷偷的定义了两个概念:
utf8mb3 :阉割过的 utf8 字符集,只使⽤1~3个字节表示字符。
utf8mb4 :正宗的 utf8 字符集,使⽤1~4个字节表示字符。
有⼀点需要⼤家⼗分的注意,在 MySQL 中 utf8 是 utf8mb3 的别名,所以之后在 MySQL 中提到 utf8 就意味着使⽤1~3个字节来表示⼀个字符,如果⼤家有使⽤4字节编码⼀个字符的情况,⽐如存储⼀些 emoji表情啥的,那请使⽤ utf8mb4 。
字符集的查看
MySQL ⽀持好多好多种字符集,查看当前 MySQL 中⽀持的字符集可以⽤下边这个语句:

show charset ;

若有收获,就点个赞吧
0 人点赞
