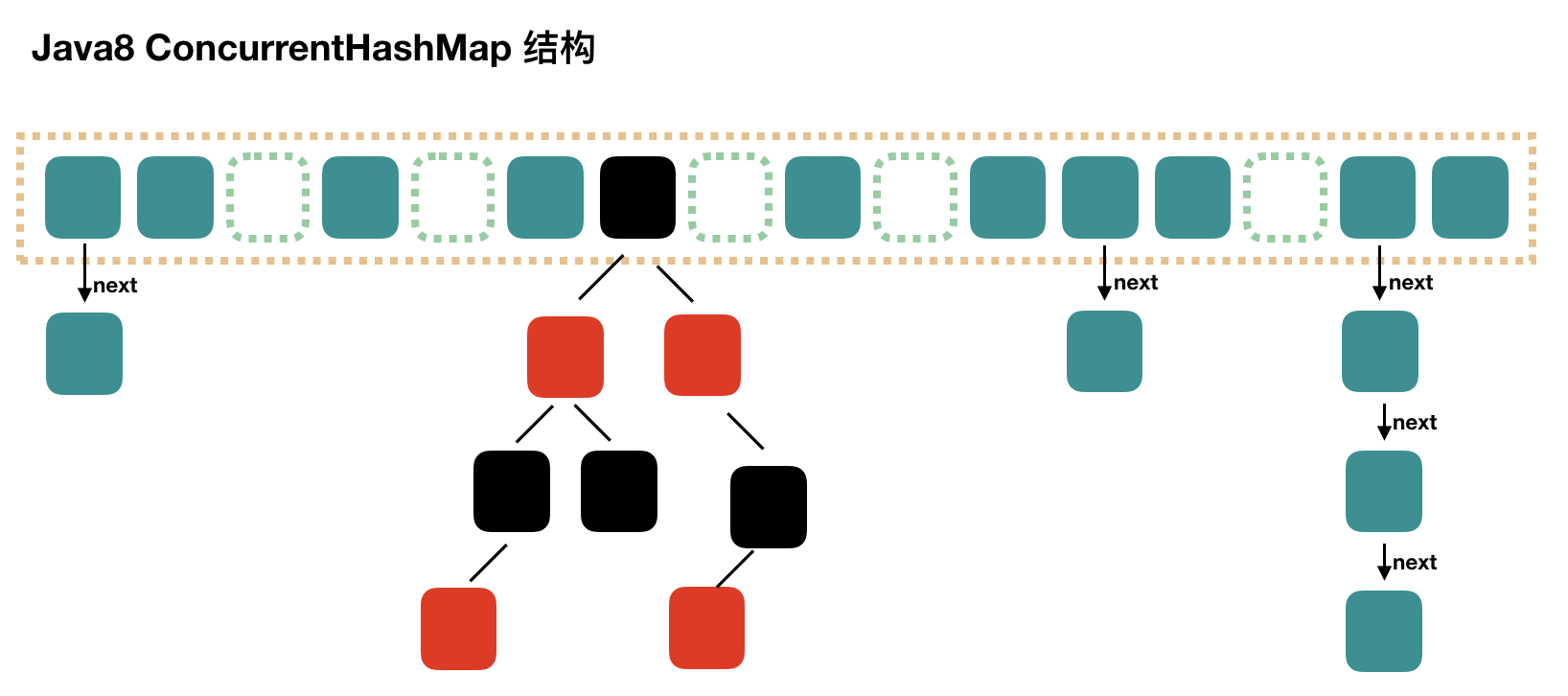
ConcurrentHashMap 在JDK8中进行了巨大改动,它摒弃了 Segment (锁段)的概念,而是利用 CAS 算法和 synchronized 关键字来实现。它沿用了与它同时期的 HashMap 版本的思想,底层依然由 数组+链表+红黑树的方式思想(JDK7与JDK8中 HashMap 的实现),但是为了做到并发,又增加了很多辅助的类,例如 TreeBin , Traverser 等对象内部类。
put 方法
源码
public V put(K key, V value) {return putVal(key, value, false);}final V putVal(K key, V value, boolean onlyIfAbsent) {// 不允许 key或value为nullif (key == null || value == null) throw new NullPointerException();// 计算hash值int hash = spread(key.hashCode());int binCount = 0;// 死循环 何时插入成功 何时跳出for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;//如果hash表为空的话,初始化hash表if (tab == null || (n = tab.length) == 0)tab = initTable();// /根据hash值计算出值在hash表里面的位置else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 如果这个位置没有值 ,直接放进去,不需要加锁if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}// 当遇到表连接点时,进行扩容else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;//结点上锁 这里的结点可以理解为hash值相同组成的链表的头结点synchronized (f) {if (tabAt(tab, i) == f) {// fh〉0 说明这个节点是一个链表的节点 不是树的节点if (fh >= 0) {binCount = 1;// 在这里遍历链表所有的结点for (Node<K,V> e = f;; ++binCount) {K ek;// 如果hash值和key值相同 则修改对应结点的value值if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;// 遍历到了最后一个结点,证明新的节点需要插入// 就把它插入在链表尾部if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}// 如果这个节点是树节点,就按照树的方式插入值else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {// 如果链表长度已经达到临界值8 就需要把链表转换为红黑树if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}
扩容
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {Node<K,V>[] nextTab; int sc;if (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {int rs = resizeStamp(tab.length);while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || transferIndex <= 0)break;if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {transfer(tab, nextTab);break;}}return nextTab;}return table;}
get 方法
步骤
- 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 就不满足那就按照链表的方式遍历获取值
源码
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;int h = spread(key.hashCode());if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {if ((eh = e.hash) == h) {if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}else if (eh < 0)return (p = e.find(h, key)) != null ? p.val : null;while ((e = e.next) != null) {if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;}
参考

若有收获,就点个赞吧
0 人点赞
