开启慢查询日志
相关参数说明
- slow_query_log 慢查询开启状态
- slow_query_log_file 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)
- long_query_time 查询超过多少秒才记录
参数设置查看
```bash mysql> show variables like ‘long_query_time’; +————————-+—————+ | Variable_name | Value | +————————-+—————+ | long_query_time | 2.000000 | +————————-+—————+ 1 row in set (0.02 sec)
mysql> show variables like ‘slow_query%’; +——————————-+———————————————-+ | Variable_name | Value | +——————————-+———————————————-+ | slow_query_log | ON | | slow_query_log_file | /var/lib/mysql/mysql-slow.log | +——————————-+———————————————-+ 2 rows in set (0.02 sec)
<a name="RkMUR"></a>### 配置文件设置```bash[mysqld]slow_query_log=1slow_query_log_file=/var/lib/mysql/mysql-slow.loglong_query_time=2
查看慢查询日志
慢查询日志详情
# Time: 2019-12-27T01:36:49.950245Z# User@Host: root[root] @ [10.244.2.170] Id: 32796# Query_time: 2.243889 Lock_time: 0.000838 Rows_sent: 83 Rows_examined: 251SET timestamp=1577410607;SELECTTABLE_SCHEMA,TABLE_NAME,TABLE_TYPE,ifnull(ENGINE, 'NONE') as ENGINE,ifnull(VERSION, '0') as VERSION,ifnull(ROW_FORMAT, 'NONE') as ROW_FORMAT,ifnull(TABLE_ROWS, '0') as TABLE_ROWS,ifnull(DATA_LENGTH, '0') as DATA_LENGTH,ifnull(INDEX_LENGTH, '0') as INDEX_LENGTH,ifnull(DATA_FREE, '0') as DATA_FREE,ifnull(CREATE_OPTIONS, 'NONE') as CREATE_OPTIONSFROM information_schema.tablesWHERE TABLE_SCHEMA = 'test';
日志相关字段说明
- Time:执行查询的日期时间
- User@Host:执行查询的用户和客户端IP
- Id:是执行查询的线程Id
- Query_time:SQL执行所消耗的时间
- Lock_time:执行查询对记录锁定的时间
- Rows_sent:查询返回的行数
- Rows_examined:为了返回查询的数据所读取的行数
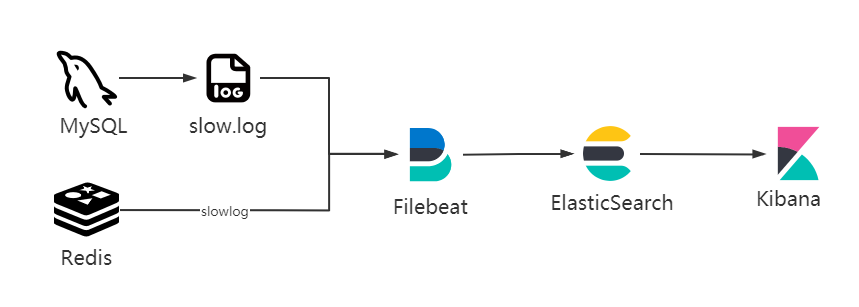
EFK数据采集
日志采集架构图
Kibana查看和统计
通过Kibana的网页客户端,选择对应的索引模式加上筛选条件,我们就看到慢查询日志的相关信息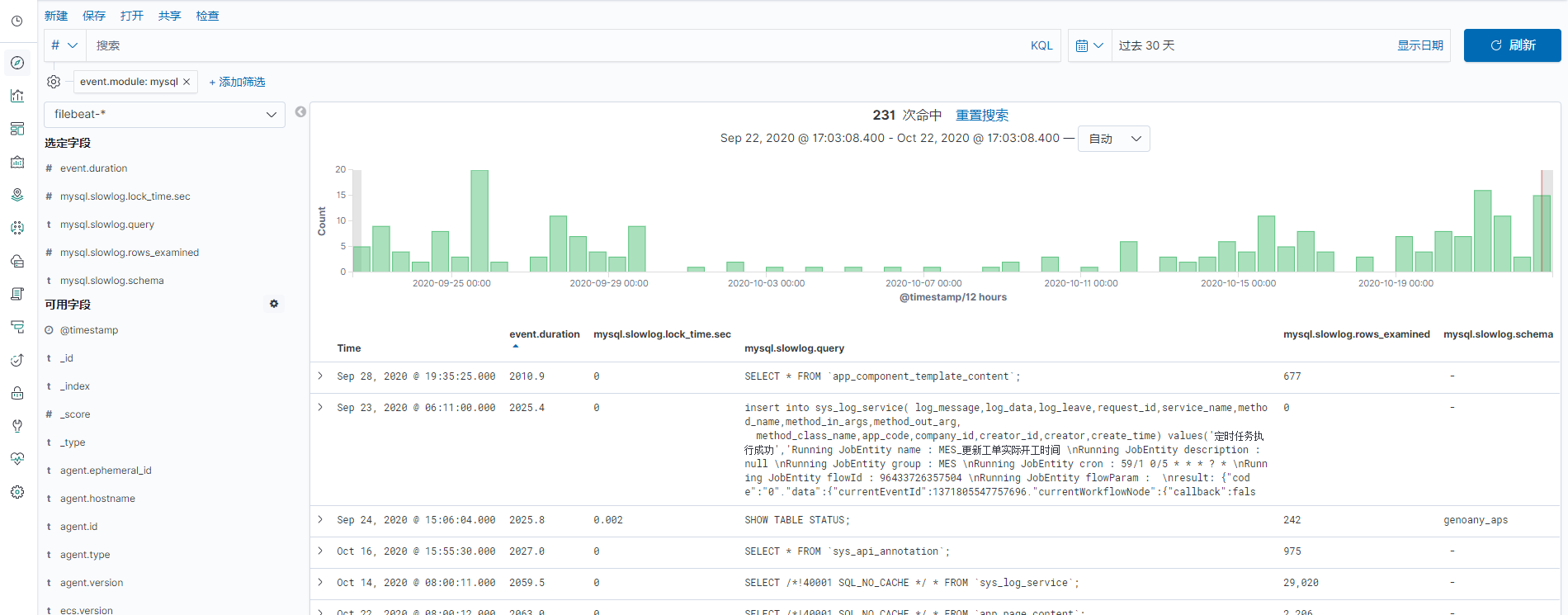
分析慢查询SQL
Explain
+----+-------------+----------------+------------+--------+-----------------------+-----------------------+---------+-------------------------------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+----------------+------------+--------+-----------------------+-----------------------+---------+-------------------------------------------+------+----------+-------------+| 1 | SIMPLE | a | NULL | ALL | NULL | NULL | NULL | NULL | 4933 | 100.00 | NULL || 1 | SIMPLE | process_config | NULL | ref | index_process_flow_id | index_process_flow_id | 9 | const | 6 | 100.00 | Using where || 1 | SIMPLE | c | NULL | eq_ref | PRIMARY | PRIMARY | 8 | genoany_product.process_config.process_id | 1 | 100.00 | Using where |+----+-------------+----------------+------------+--------+-----------------------+-----------------------+---------+-------------------------------------------+------+----------+-------------+3 rows in set (0.03 sec)
输出列说明
| 列名 | 说明 |
|---|---|
| id | 执行编号,标识select所属的行。如果在语句中没子查询或关联查询,只有唯一的select,每行都将显示1。否则,内层的select语句一般会顺序编号,对应于其在原始语句中的位置 |
| select_type | 显示本行是简单或复杂select。如果查询有任何复杂的子查询,则最外层标记为PRIMARY(DERIVED、UNION、UNION RESUlT) |
| table | 访问引用哪个表(引用某个查询,如“derived3”) |
| partitions | 该列显示的为分区表命中的分区情况。非分区表该字段为空(null) |
| type | 数据访问/读取操作类型(ALL、index、range、ref、eq_ref、const/system、NULL) |
| possible_keys | 揭示哪一些索引可能有利于高效的查找 |
| key | 显示mysql决定采用哪个索引来优化查询 |
| key_len | 显示mysql在索引里使用的字节数 |
| ref | 显示了之前的表在key列记录的索引中查找值所用的列或常量 |
| rows | 为了找到所需的行而需要读取的行数,估算值,不精确。通过把所有rows列值相乘,可粗略估算整个查询会检查的行数 |
| filtered | 这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。 |
| Extra | 额外信息,如using index、filesort等 |
select_type
查询中每个select子句的类型
类型说明:
(1) SIMPLE(简单SELECT,不使用UNION或子查询等)
(2) PRIMARY(查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
(3) UNION(UNION中的第二个或后面的SELECT语句)
(4) DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
(5) UNION RESULT(UNION的结果)
(6) SUBQUERY(子查询中的第一个SELECT)
(7) DEPENDENT SUBQUERY(子查询中的第一个SELECT,取决于外面的查询)
(8) DERIVED(派生表的SELECT, FROM子句的子查询)
(9) UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
table
显示这一行的数据是关于哪张表的,有时不是真实的表名字。
情况如下:
- 实际的表名 如select * from t1;
- 表的别名 如 select * from t2 as tmp;
- derived 如from型子查询时(来自于子查询的派生表);
- null 直接计算得结果,不用走表,例如select 1+2;
type
表示MySQL在表中找到所需行的方式,又称“访问类型”。是分析”查数据过程”的重要依据。
| 参数值(性能↓) | 说明 |
|---|---|
| system | 表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index |
| const | 使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描 |
| eq_ref | 出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref |
| ref | 不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。 |
| fulltext | 全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引 |
| ref_or_null | 与ref方法类似,只是增加了null值的比较。实际用的不多。 |
| index_merge | 表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所有索引,性能可能大部分时间都不如range |
| unique_subquery | 用于where中的in形式子查询,子查询返回不重复值唯一值 |
| index_subquery | 用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。 |
| range | 索引范围扫描,常见于使用 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN()或者like等运算符的查询中。 |
| index | 索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。 |
| all | 全表扫描数据匹配,未使用任何索引。 |
Extra
Extra是EXPLAIN输出中另外一个很重要的列,该列显示MySQL在查询过程中的一些详细信息,MySQL查询优化器执行查询的过程中对查询计划的重要补充信息。
| 类型 | 说明 |
|---|---|
| Using filesort | MySQL有两种方式可以生成有序的结果,通过排序操作或者使用索引,当Extra中出现了Using filesort 说明MySQL使用了后者,但注意虽然叫filesort但并不是说明就是用了文件来进行排序,只要可能排序都是在内存里完成的。大部分情况下利用索引排序更快,所以一般这时也要考虑优化查询了。使用文件完成排序操作,这是可能是ordery by,group by语句的结果,这可能是一个CPU密集型的过程,可以通过选择合适的索引来改进性能,用索引来为查询结果排序。 |
| Using temporary | 用临时表保存中间结果,常用于GROUP BY 和 ORDER BY操作中,一般看到它说明查询需要优化了,就算避免不了临时表的使用也要尽量避免硬盘临时表的使用。 |
| Not exists | MYSQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行, 就不再搜索了。 |
| Using index | 说明查询是覆盖了索引的,不需要读取数据文件,从索引树(索引文件)中即可获得信息。如果同时出现using where,表明索引被用来执行索引键值的查找,没有using where,表明索引用来读取数据而非执行查找动作。这是MySQL服务层完成的,但无需再回表查询记录。 |
| Using index condition | “索引条件推送”。简单说一点就是MySQL原来在索引上是不能执行如like这样的操作的,但是现在可以了,这样减少了不必要的IO操作,但是只能用在二级索引上。 |
| Using where | 使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。注意:Extra列出现Using where表示MySQL服务器将存储引擎返回服务层以后再应用WHERE条件过滤。 |
| Using join buffer | 使用了连接缓存:Block Nested Loop,连接算法是块嵌套循环连接;Batched Key Access,连接算法是批量索引连接 |
| impossible where | where子句的值总是false,不能用来获取任何元组 |
| select tables optimized away | 在没有GROUP BY子句的情况下,基于索引优化MIN/MAX操作,或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。 |
| distinct | 优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作 |
索引
索引是存储引擎用于快速找到记录的一种数据结构.
索引目的
索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的,如果我想找到m开头的单词呢?或者ze开头的单词呢?是不是觉得如果没有索引,这个事情根本无法完成?
索引的好处
- 减少查询需要扫描的数据量(加快了查询速度)
- 减少服务器的排序操作和创建临时表的操作(加快了groupby和orderby等操作)
- 将服务器的随机IO变为顺序IO(加快查询速度).
索引的缺点
- 索引占用磁盘或者内存空间
- 减慢了插入更新操作的速度
索引的类型
- 普通索引—最基本的索引,它没有任何限制。
- 唯一索引—索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
- 主键索引—是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引。
- 组合索引—指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。
- 全文索引—主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。
建索引的原则
- 最左前缀匹配原则。这是非常重要、非常重要、非常重要(重要的事情说三遍)的原则,MySQL会一直向右匹配直到遇到范围查询(>,<,BETWEEN,LIKE)就停止匹配,比如: a = 1 AND b = 2 AND c > 3 AND d = 4,如果建立 (a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引,则都可以用到,a,b,d的顺序可以任意调整。
- 等于(=)和in 可以乱序。比如,a = 1 AND b = 2 AND c = 3 建立(a,b,c)索引可以任意顺序,MySQL的查询优化器会帮你优化成索引可以识别的模式。
- 尽量选择区分度高的列作为索引,区分度的公式是 COUNT(DISTINCT col) / COUNT(*)。表示字段不重复的比率,比率越大我们扫描的记录数就越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度是0。可能有人会问,这个比率有什么经验么?使用场景不同,这个值也很难确定,一般需要JOIN的字段我们要求在0.1以上,即平均1条扫描10条记录。
- 索引列不能参与计算,尽量保持列“干净”。比如,FROM_UNIXTIME(create_time) = ‘2016-06-06’ 就不能使用索引,原因很简单,B+树中存储的都是数据表中的字段值,但是进行检索时,需要把所有元素都应用函数才能比较,显然这样的代价太大。所以语句要写成 : create_time = UNIX_TIMESTAMP(‘2016-06-06’)。
- 尽可能的扩展索引,不要新建立索引。比如表中已经有了a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
- 单个多列组合索引和多个单列索引的检索查询效果不同,因为在执行SQL时,MySQL只能使用一个索引,会从多个单列索引中选择一个限制最为严格的索引。
参考
https://tech.meituan.com/2014/06/30/mysql-index.html
https://zhuanlan.zhihu.com/p/25648377
https://www.jianshu.com/p/38cbb5426bee
https://blog.csdn.net/mysteryhaohao/article/details/51719871

若有收获,就点个赞吧
0 人点赞
