论文地址:https://arxiv.org/pdf/1801.02294.pdf
背景
召回/匹配是排序的天花板,本质上是要从全量候选集中挑选TopK集合,性能与准确度的权衡
相关技术
第一代:统计的启发式规则方法
方案:
- 统计方法(协同过滤)得到i2i,相似拉链
- 构建用户历史行为的item set
- 为item Set中item根据i2i得到相似item的候选列表
- 优点:有效可计算;优于规则
-
第二代:基于内积模型的向量检索方法
方案
- 基于各种方案得到用户和item的向量
- 向量可以通过聚类的方案,提升搜索效率
- 直接使用用户的向量搜索相似的item(内积比较小的)
问题:
目标
- 搜索范围:限定候选->全量候选
- 搜索精度:内积->任意先进模型
方案
简述
- 树(最大堆树)是用来检索用户最优的topK个item的,用户和树上的每个节点(包括叶子和非叶子)都有embedding,使用层次检索算法和计算分数的模型可以获得结果
- 树结构:使用随机/现有的兴趣体系初始化,然后根据迭代的embeding,聚类构建树
打分模型:可以灵活开发,比如下图左边的网络使用attention机制,训练时放在右边的树中,使用负采样来训练。以下是细节
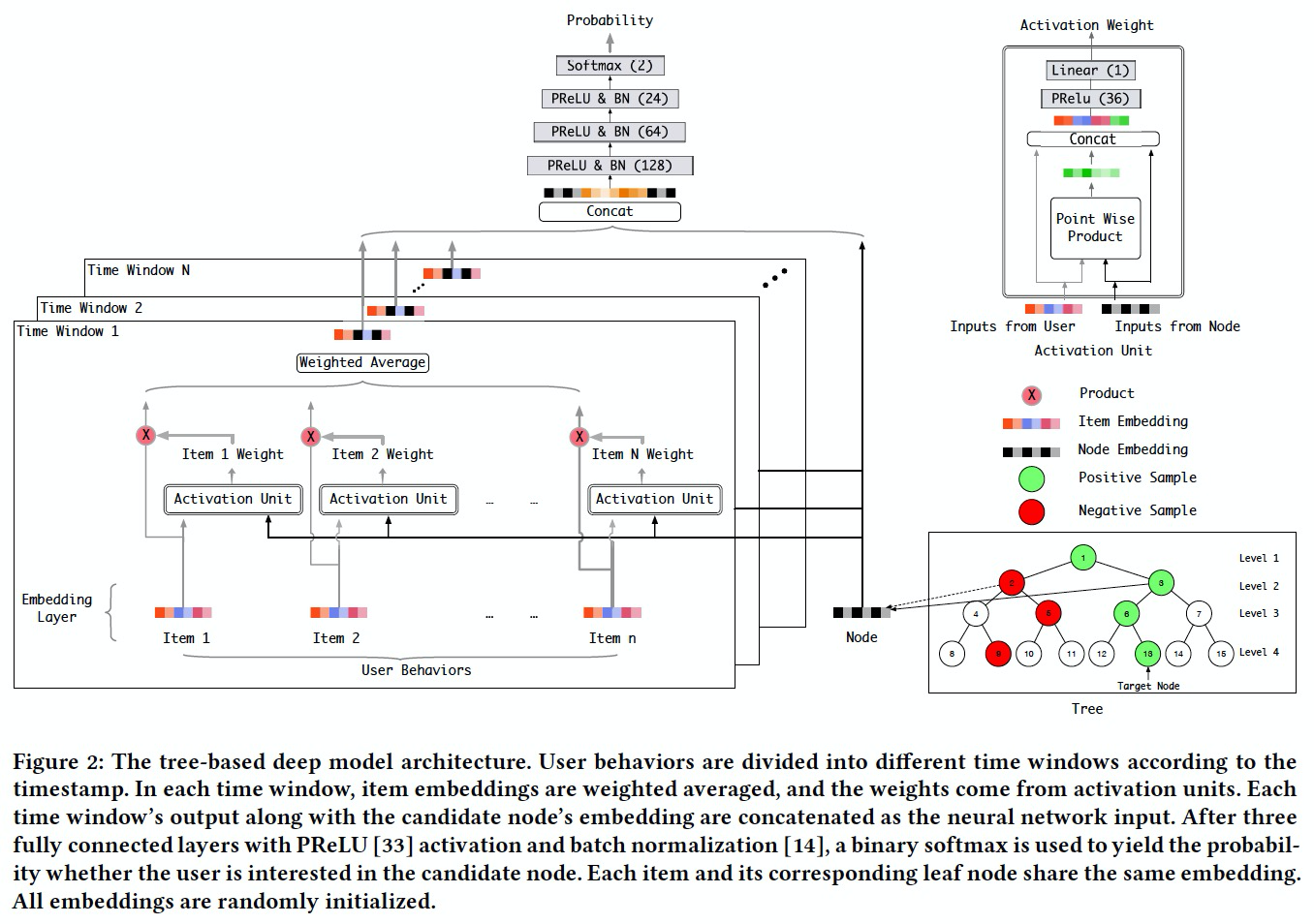
层次检索算法(预测)
- 从根节点开始,
- repeat
- 计算与user的打分,选出topK
- topK中如果是叶子节点,放在集合A中
- topK中如果是非叶子节点,取出他的子节点替换自己放在集合Q中
- 计算与user的打分,选出topK
- 直到Q为空,为A排序取topK为最终结果
- 树参数模型训练
- 树联合训练
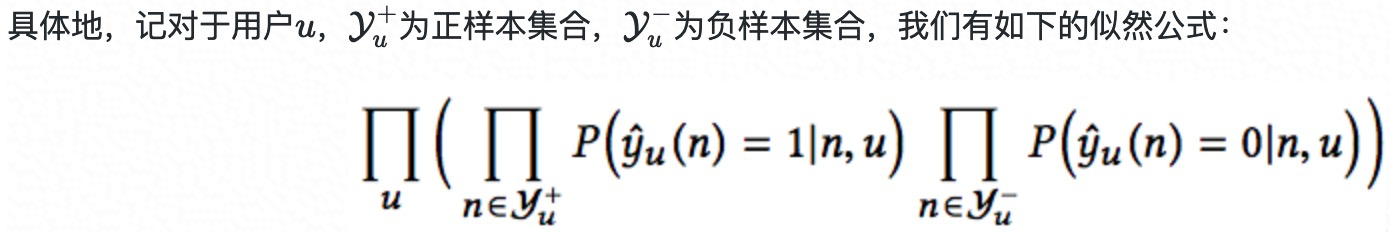
1)依托淘宝商品体系构造初始化的兴趣层次树T0;
2)基于T0构造样本,训练得到TDM模型M1;
3)根据M1学得的节点Embedding,通过KMeans聚类重建新树T1;
4)基于T1重新构造样本,训练得到TDM新模型M2;
5)继续步骤3)和4)直至模型测试指标稳定,得到最终模型Mf。

若有收获,就点个赞吧
0 人点赞
