1、RNN来作为这里的controller,然后用policy gradient来最大化controller
实现:https://github.com/wallarm/nascell-automl
- auto-regressive :未来和历史序列相关
- space:
- 策略:
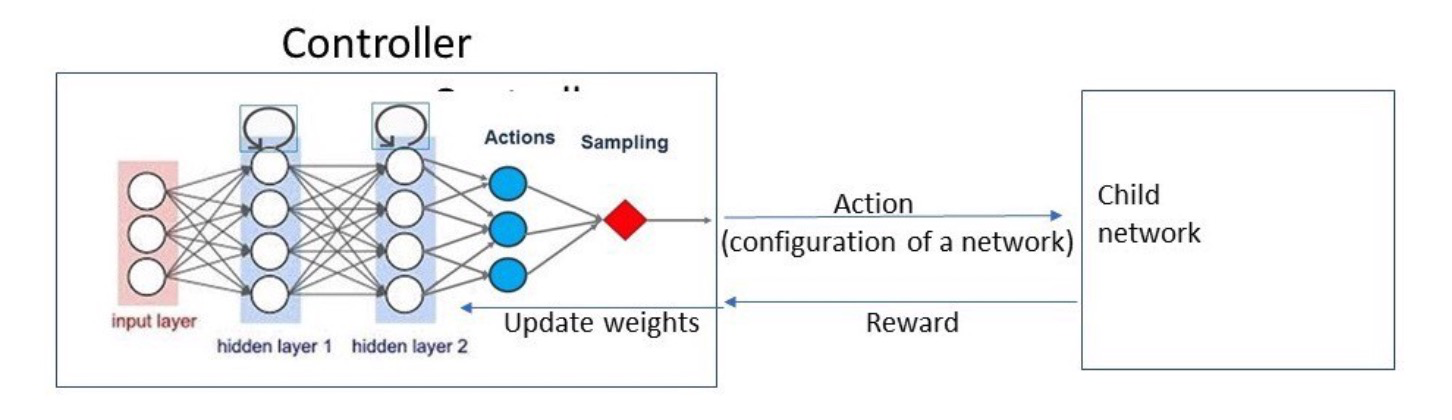
Example:
Input:
“layers:[1,3,5,7]”,”activation_functions=[tanh,sigmoid,relu,leaky relu]”,”output_activation=[sotmax]”,”optimizer=[Adam,RMS Prop,SGD]”
Output:
“layers:5,”activation_functions=relu”,”output_activation=softmax”,”optimizer=Adam”
https://medium.com/@abinesh.mba13/neural-architecture-search-nas-the-future-of-deep-learning-4b35ca473b9

若有收获,就点个赞吧
0 人点赞
